Si vous voulez tout savoir sur Hadoop MapReduce, vous êtes au bon endroit. Ce didacticiel MapReduce vous fournit le guide complet sur tout et n'importe quoi dans Hadoop MapReduce.
Dans cette introduction à MapReduce, vous explorerez ce qu'est Hadoop MapReduce, comment fonctionne le framework MapReduce. L'article couvre également MapReduce DataFlow, différentes phases dans MapReduce, Mapper, Reducer, Partitioner, Cominer, Shuffling, Sorting, Data Locality, et bien d'autres.
Nous avons également fait appel aux avantages du framework MapReduce.
Voyons d'abord pourquoi nous avons besoin de Hadoop MapReduce.
Pourquoi MapReduce ?
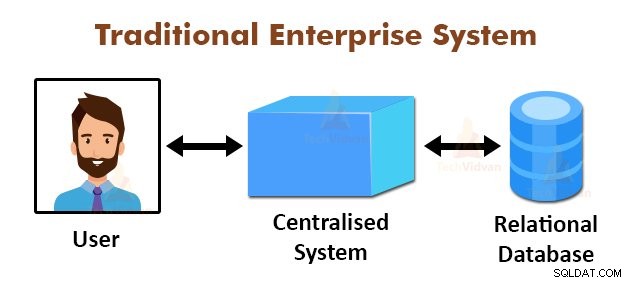
La figure ci-dessus représente la vue schématique des systèmes d'entreprise traditionnels. Les systèmes traditionnels disposent normalement d'un serveur centralisé pour le stockage et le traitement des données. Ce modèle n'est pas adapté au traitement d'énormes quantités de données évolutives.
De plus, ce modèle ne pouvait pas être pris en charge par les serveurs de base de données standard. De plus, le système centralisé crée trop de goulots d'étranglement lors du traitement simultané de plusieurs fichiers.
En utilisant l'algorithme MapReduce, Google a résolu ce problème de goulot d'étranglement. Le framework MapReduce divise la tâche en petites parties et attribue des tâches à de nombreux ordinateurs.
Plus tard, les résultats sont collectés dans un lieu commun et sont ensuite intégrés pour former l'ensemble de données de résultats.
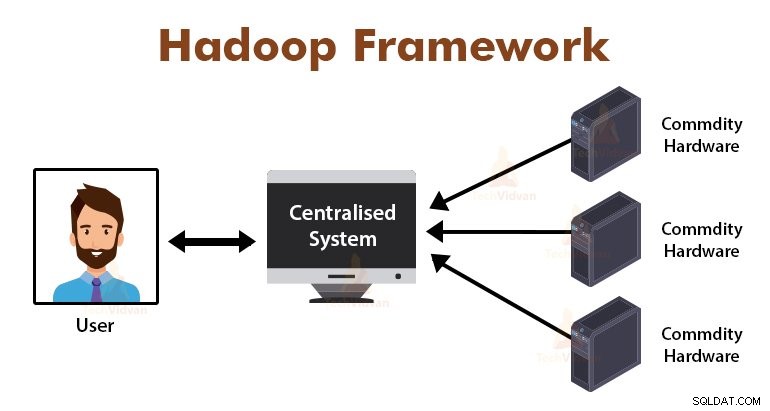
Introduction au cadre MapReduce
MapReduce est la couche de traitement dans Hadoop. Il s'agit d'un cadre logiciel conçu pour traiter d'énormes volumes de données en parallèle en divisant la tâche en un ensemble de tâches indépendantes.
Nous avons juste besoin de mettre la logique métier dans le fonctionnement de MapReduce, et le framework s'occupera du reste. Le framework MapReduce fonctionne en divisant le travail en petites tâches et assigne ces tâches aux esclaves.
Les programmes MapReduce sont écrits dans un style particulier influencé par les constructions de programmation fonctionnelle, des idiomes spécifiques pour le traitement des listes de données.
Dans MapReduce, les entrées se présentent sous la forme d'une liste et la sortie du framework se présente également sous la forme d'une liste. MapReduce est le cœur de Hadoop. L'efficacité et la puissance de Hadoop sont dues au traitement parallèle du framework MapReduce.
Voyons maintenant comment fonctionne Hadoop MapReduce.
Comment fonctionne Hadoop MapReduce ?
Le framework Hadoop MapReduce fonctionne en divisant un travail en tâches indépendantes et en exécutant ces tâches sur des machines esclaves. Le travail MapReduce est exécuté en deux étapes qui sont la phase de mappage et la phase de réduction.
L'entrée et la sortie des deux phases sont des paires clé, valeur. Le framework MapReduce est basé sur le principe de localité des données (discuté plus tard), ce qui signifie qu'il envoie le calcul aux nœuds où résident les données.
- Phase de carte − Dans la phase Carte, la fonction de carte définie par l'utilisateur traite les données d'entrée. Dans la fonction map, l'utilisateur met la logique métier. La sortie de la phase Map est la sortie intermédiaire et est stockée sur le disque local.
- Réduire la phase – Cette phase est la combinaison de la phase de mélange et de la phase de réduction. Dans la phase Reduce, la sortie de l'étape Map est transmise au Reducer où elle est agrégée. La sortie de la phase Reduce est la sortie finale. Dans la phase de réduction, la fonction de réduction définie par l'utilisateur traite la sortie des mappeurs et génère les résultats finaux.
Pendant la tâche MapReduce, le framework Hadoop envoie les tâches Map et les tâches Reduce aux machines appropriées du cluster.
Le framework lui-même gère tous les détails du transfert de données, tels que l'émission de tâches, la vérification de l'achèvement des tâches et la copie de données entre les nœuds autour du cluster. Les tâches ont lieu sur les nœuds où résident les données afin de réduire le trafic réseau.
Flux de données MapReduce
Vous voudrez peut-être tous savoir comment ces paires clé-valeur sont générées et comment MapReduce traite les données d'entrée. Cette section répond à toutes ces questions.
Voyons comment les données doivent découler de différentes phases dans Hadoop MapReduce pour gérer les données à venir de manière parallèle et distribuée.
1. Fichiers d'entrée
L'ensemble de données d'entrée, qui doit être traité par le programme MapReduce, est stocké dans InputFile. L'InputFile est stocké dans le système de fichiers distribué Hadoop.
2. Fractionnement d'entrée
L'enregistrement dans InputFiles est divisé dans le modèle logique. La taille de fractionnement est généralement égale à la taille de bloc HDFS. Chaque division est traitée par le mappeur individuel.
3. Format d'entrée
InputFormat spécifie la spécification d'entrée du fichier. Il définit le chemin vers le RecordReader dans lequel l'enregistrement de InputFile est converti en paires clé, valeur.
4. Lecteur d'enregistrements
RecordReader lit les données de l'InputSplit et convertit les enregistrements en paires clé-valeur et les présente aux mappeurs.
5. Mappeurs
Les mappeurs prennent les paires clé-valeur en entrée du RecordReader et les traitent en implémentant la fonction de mappage définie par l'utilisateur. Dans chaque Mapper, à la fois, un seul split est traité.
Le développeur a mis la logique métier dans la fonction map. La sortie de tous les mappeurs est la sortie intermédiaire, qui se présente également sous la forme de paires clé-valeur.
6. Mélanger et trier
La sortie intermédiaire générée par les Mappers est triée avant de passer au Reducer afin de réduire la congestion du réseau. Les sorties intermédiaires triées sont ensuite mélangées au réducteur sur le réseau.
7. Réducteur
Le réducteur traite et agrège les sorties du mappeur en implémentant une fonction de réduction définie par l'utilisateur. La sortie des réducteurs est la sortie finale et est stockée dans le système de fichiers distribués Hadoop (HDFS).
Étudions maintenant quelques terminologies et concepts avancés du framework Hadoop MapReduce.
Paires clé-valeur dans MapReduce
Le framework MapReduce fonctionne sur les paires clé, valeur car il traite le schéma non statique. Il prend des données sous la forme d'une clé, d'une paire de valeurs, et la sortie générée est également sous la forme d'une clé, de paires de valeurs.
La paire clé-valeur MapReduce est une entité d'enregistrement qui est reçue par le travail MapReduce pour l'exécution. Dans une paire clé-valeur :
- La clé est le décalage de ligne depuis le début de la ligne dans le fichier.
- La valeur est le contenu de la ligne, à l'exclusion des fins de ligne.
Partitionneur MapReduce
Hadoop MapReduce Partitioner partitionne l'espace de clés. Le partitionnement de l'espace de clés dans MapReduce spécifie que toutes les valeurs de chaque clé ont été regroupées et garantit que toutes les valeurs de la clé unique doivent aller au même réducteur.
Ce partitionnement permet une distribution uniforme de la sortie du mappeur sur le réducteur en garantissant que la bonne clé va au bon réducteur.
Le partitionneur MapReducer par défaut est le partitionneur de hachage, qui partitionne les espaces de clés sur la base de la valeur de hachage.
MapReduce Combiner
Le MapReduce Combiner est également connu sous le nom de "Semi-Reducer". Il joue un rôle majeur dans la réduction de la congestion du réseau. Le framework MapReduce fournit la fonctionnalité pour définir le Combiner, qui combine la sortie intermédiaire des Mappers avant de les transmettre à Reducer.
L'agrégation des sorties de Mapper avant de passer à Reducer aide le framework à mélanger de petites quantités de données, ce qui réduit la congestion du réseau.
La fonction principale du Combiner est de résumer la sortie des Mappers avec la même clé et de la transmettre au Reducer. La classe Combiner est utilisée entre la classe Mapper et la classe Reducer.
Localité des données dans MapReduce
La localité des données fait référence à "Rapprocher le calcul des données plutôt que de déplacer les données vers le calcul." C'est beaucoup plus efficace si le calcul demandé par l'application est exécuté sur la machine où résident les données demandées.
Ceci est très vrai dans le cas où la taille des données est énorme. C'est parce qu'il minimise la congestion du réseau et augmente le débit global du système.
La seule hypothèse sous-jacente est qu'il est préférable de rapprocher le calcul de la machine sur laquelle les données sont présentes au lieu de déplacer les données vers la machine sur laquelle l'application est en cours d'exécution.
Apache Hadoop fonctionne sur un énorme volume de données, il n'est donc pas efficace de déplacer des données aussi volumineuses sur le réseau. Par conséquent, le cadre a proposé le principe le plus innovant qui est la localité des données, qui déplace la logique de calcul vers les données au lieu de déplacer les données vers les algorithmes de calcul. C'est ce qu'on appelle la localité des données.
Avantages de MapReduce
Utilisation de MapReduce
Chaque fois qu'une page Web est trouvée dans le journal, une paire clé-valeur est transmise au réducteur où la clé est la page Web et la valeur est "1". Après avoir émis une paire clé-valeur au Réducteur, les Réducteurs agrègent le nombre de pour certaines pages Web.
Le résultat final sera le nombre total de visites pour chaque page Web.
3. Google utilise MapReduce pour calculer son Pagerank.
La fonction reduce concatène ensuite la liste de toutes les URL source associées à l'URL cible donnée et renvoie la cible et la liste des sources.
Résumé
Il s'agit du didacticiel Hadoop MapReduce. Le framework traite d'énormes volumes de données en parallèle sur le cluster de matériel de base. Il divise le travail en tâches indépendantes et les exécute en parallèle sur différents nœuds du cluster.
MapReduce surmonte le goulot d'étranglement du système d'entreprise traditionnel. Le framework fonctionne sur les paires clé, valeur. L'utilisateur définit les deux fonctions que sont la fonction map et la fonction reduce.
La logique métier est placée dans la fonction map. L'article avait expliqué divers concepts avancés du framework MapReduce.



