La maintenance est quelque chose qu'une équipe d'exploitation ne peut pas éviter. Les serveurs doivent suivre les derniers logiciels, matériels et technologies pour s'assurer que les systèmes sont stables et fonctionnent avec le moins de risques possible, tout en utilisant de nouvelles fonctionnalités pour améliorer les performances globales.
Sans aucun doute, il existe une longue liste de tâches de maintenance qui doivent être effectuées par les administrateurs système, en particulier lorsqu'il s'agit de systèmes critiques. Certaines des tâches doivent être effectuées à intervalles réguliers, comme quotidiennement, hebdomadairement, mensuellement et annuellement. Certaines sont à faire tout de suite, en urgence. Néanmoins, toute opération de maintenance ne doit pas entraîner un autre problème plus important, et toute maintenance doit être traitée avec un soin particulier pour éviter toute interruption de l'activité.
L'obtention d'un état douteux et de fausses alarmes est courante pendant la maintenance. Ceci est normal car pendant la période de maintenance, le serveur ne fonctionnera pas comme il se doit tant que la tâche de maintenance n'est pas terminée. ClusterControl, la plate-forme de gestion et de surveillance tout compris pour vos bases de données open source, peut être configurée pour comprendre ces circonstances afin de simplifier vos routines de maintenance, sans sacrifier les fonctionnalités de surveillance et d'automatisation qu'elle offre.
Mode d'entretien
ClusterControl a introduit le mode de maintenance dans la version 1.4.0, où vous pouvez mettre un nœud individuel en maintenance, ce qui empêche ClusterControl de déclencher des alarmes et d'envoyer des notifications pendant la durée spécifiée. Le mode de maintenance peut être configuré à partir de l'interface utilisateur de ClusterControl et également à l'aide de l'outil CLI de ClusterControl appelé "s9s". Depuis l'interface utilisateur, accédez simplement à Nœuds -> choisissez un nœud -> Actions de nœud -> Planifier le mode de maintenance :
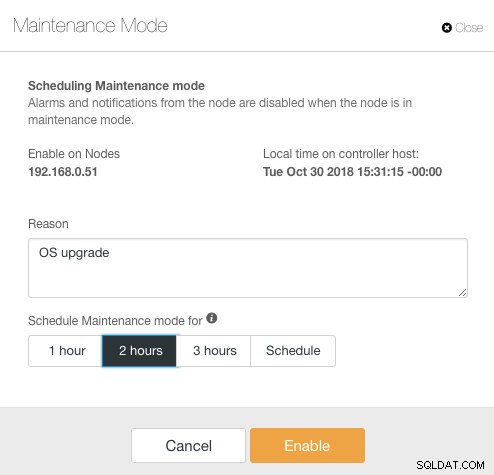
Ici, on peut définir la période de maintenance pour une durée prédéfinie ou la programmer en conséquence. Vous pouvez également noter la raison de la planification de la mise à niveau, utile à des fins d'audit. Vous devriez voir la notification suivante lorsque le mode maintenance est actif :
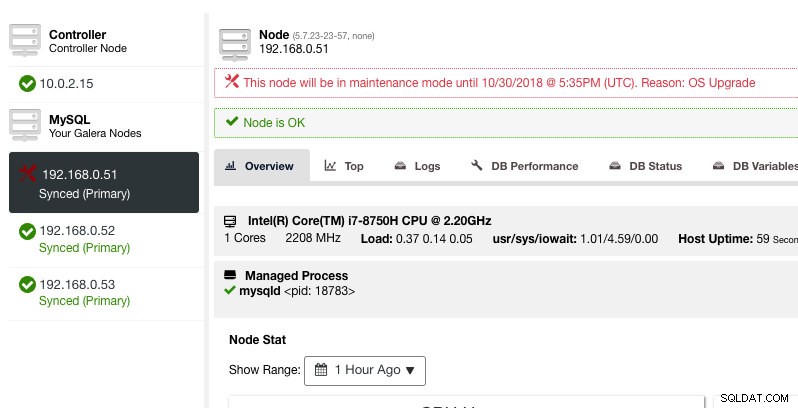
ClusterControl ne dégradera pas le nœud, par conséquent, l'état du nœud reste tel quel, sauf si vous effectuez une action qui modifie l'état. Les alarmes et les notifications pour ce nœud seront réactivées une fois la période de maintenance terminée, ou l'opérateur le désactivera explicitement en allant dans Actions du nœud -> Désactiver le mode de maintenance .
Notez que si la récupération automatique des nœuds est activée, ClusterControl récupérera toujours un nœud quel que soit l'état du mode de maintenance. N'oubliez pas de désactiver la récupération de nœud pour éviter que ClusterControl n'interfère avec vos tâches de maintenance, cela peut être fait à partir de la barre de résumé supérieure.
Le mode de maintenance peut également être configuré via ClusterControl CLI ou "s9s". Vous pouvez utiliser la commande "s9s maintenance" pour répertorier et manipuler les périodes de maintenance. La ligne de commande suivante planifie une fenêtre de maintenance d'une heure pour le nœud 192.168.1.121 demain :
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."Pour plus de détails et d'exemples, consultez la documentation de maintenance s9s.
Mode de maintenance à l'échelle du cluster
Au moment d'écrire ces lignes, la configuration du mode de maintenance doit être configurée par nœud géré. Pour la maintenance à l'échelle du cluster, il faut répéter le processus de planification pour chaque nœud géré du cluster. Cela peut s'avérer peu pratique si vous avez un grand nombre de nœuds dans votre cluster, ou si l'intervalle de maintenance est très court entre deux tâches.
Heureusement, ClusterControl CLI (alias s9s) peut être utilisé comme solution de contournement pour surmonter cette limitation. Vous pouvez utiliser des "nœuds s9s" pour répertorier et manipuler les nœuds gérés dans un cluster. Cette liste peut être itérée pour planifier un mode de maintenance à l'échelle du cluster à un moment donné à l'aide de la commande "s9s maintenance".
Prenons un exemple pour mieux comprendre cela. Considérez le cluster Percona XtraDB à trois nœuds suivant :
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4Le cluster a un total de 4 nœuds - 3 nœuds de base de données avec un nœud ClusterControl. La première colonne, STAT, indique le rôle et l'état du nœud. Le premier caractère est le rôle du nœud - "c" signifie contrôleur et "g" signifie nœud de base de données Galera. Supposons que nous voulions planifier uniquement les nœuds de la base de données pour la maintenance, nous pouvons filtrer la sortie pour obtenir le nom d'hôte ou l'adresse IP où le STAT signalé a "g" au début :
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53Avec une simple itération, nous pouvons alors planifier une fenêtre de maintenance à l'échelle du cluster pour chaque nœud du cluster. La commande suivante itère la création de la maintenance en fonction de toutes les adresses IP trouvées dans le cluster à l'aide d'une boucle for, où nous prévoyons de démarrer l'opération de maintenance à la même heure demain et de terminer une heure plus tard :
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bVous devriez voir une impression de 3 UUID, la chaîne unique qui identifie chaque période de maintenance. On peut alors vérifier avec la commande suivante :
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3À partir de la sortie ci-dessus, nous avons obtenu une liste des heures de maintenance planifiées pour chaque nœud de base de données. Pendant l'heure programmée, ClusterControl ne déclenchera pas d'alarmes ni n'enverra de notification s'il détecte des irrégularités dans le cluster.
Itération du mode de maintenance
Certaines routines de maintenance doivent être effectuées à intervalles réguliers, par exemple, les sauvegardes, les tâches d'entretien ménager et de nettoyage. Pendant la période de maintenance, nous nous attendrions à ce que le serveur se comporte différemment. Cependant, toute panne de service, inaccessibilité temporaire ou charge élevée causerait sûrement des ravages à notre système de surveillance. Pour les créneaux de maintenance fréquents et à intervalles courts, cela peut s'avérer très ennuyeux et ignorer les fausses alarmes déclenchées peut vous permettre de mieux dormir pendant la nuit.
Cependant, l'activation du mode de maintenance peut également exposer le serveur à un risque plus important, car une surveillance stricte est ignorée pendant cette période. Par conséquent, il est probablement judicieux de comprendre la nature de l'opération de maintenance que nous souhaitons effectuer avant d'activer le mode maintenance. La liste de contrôle suivante devrait nous aider à déterminer notre politique de mode de maintenance :
- Nœuds concernés – Quels nœuds sont concernés par la maintenance ?
- Conséquences :qu'advient-il du nœud lorsque l'opération de maintenance est en cours ? Sera-t-il inaccessible, chargé ou redémarré ?
- Durée :combien de temps l'opération de maintenance prend-elle pour se terminer ?
- Fréquence :à quelle fréquence l'opération de maintenance doit-elle être exécutée ?
Mettons-le dans un cas d'utilisation. Considérons que nous avons un cluster Percona XtraDB à trois nœuds avec un nœud ClusterControl. Supposons que nos serveurs fonctionnent tous sur des machines virtuelles et que la politique de sauvegarde des machines virtuelles exige que toutes les machines virtuelles soient sauvegardées tous les jours à partir de 1h00 du matin, un nœud à la fois. Pendant cette opération de sauvegarde, le nœud sera gelé pendant environ 10 minutes maximum et le nœud qui est géré et surveillé par ClusterControl sera inaccessible jusqu'à la fin de la sauvegarde. Du point de vue du cluster Galera, cette opération ne met pas tout le cluster hors service, car le cluster reste en quorum et le composant principal n'est pas affecté.
En fonction de la nature de la tâche de maintenance, nous pouvons la résumer comme suit :
- Nœuds concernés :tous les nœuds pour l'ID de cluster 1 (3 nœuds de base de données et 1 nœud ClusterControl).
- Conséquence :la VM en cours de sauvegarde sera inaccessible jusqu'à la fin.
- Durée :chaque opération de sauvegarde de VM prend environ 5 à 10 minutes.
- Fréquence :la sauvegarde de la VM est planifiée pour s'exécuter quotidiennement, à partir de 1 h 00 sur le premier nœud.
Nous pouvons alors proposer un plan d'exécution pour programmer notre mode maintenance :
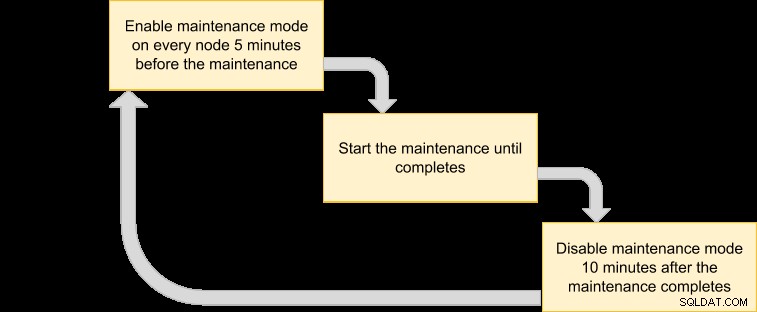
Étant donné que nous voulons que tous les nœuds du cluster soient sauvegardés par le gestionnaire de VM, répertoriez simplement les nœuds pour l'ID de cluster correspondant :
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53La sortie ci-dessus peut être utilisée pour planifier la maintenance sur l'ensemble du cluster. Par exemple, si vous exécutez la commande suivante, ClusterControl activera le mode de maintenance pour tous les nœuds sous l'ID de cluster 1 d'ici les 50 prochaines minutes :
$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; doneEn utilisant la commande ci-dessus, nous pouvons le convertir en un fichier d'exécution en le plaçant dans un script. Créer un fichier :
$ vim /usr/local/bin/enable_maintenance_modeEt ajoutez les lignes suivantes :
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneEnregistrez-le et assurez-vous que l'autorisation du fichier est exécutable :
$ chmod 755 /usr/local/bin/enable_maintenance_modeUtilisez ensuite cron pour planifier l'exécution du script de 5 minutes à 1 h 00 tous les jours, juste avant le début de l'opération de sauvegarde de la VM à 1 h 00 :
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeRechargez le démon cron pour vous assurer que notre script est mis en file d'attente :
$ systemctl reload crond # or service crond reloadC'est ça. Nous pouvons désormais effectuer notre opération de maintenance quotidienne sans être dérangés par de fausses alarmes et des notifications par e-mail jusqu'à ce que la maintenance soit terminée.
Fonctionnalité de maintenance bonus – Ignorer la récupération de nœud
Lorsque la récupération automatique est activée, ClusterControl est suffisamment intelligent pour détecter une panne de nœud et tentera de récupérer un nœud défaillant après une période de grâce de 30 secondes, quel que soit l'état du mode de maintenance. Saviez-vous que ClusterControl peut être configuré pour ignorer délibérément la récupération de nœud pour un nœud particulier ? Cela peut être très utile lorsque vous devez effectuer une maintenance urgente sans connaître la durée et le résultat de la maintenance.
Par exemple, imaginez qu'une corruption du système de fichiers se soit produite et qu'une vérification et une réparation du système de fichiers soient nécessaires après un redémarrage brutal. Il est difficile de déterminer à l'avance combien de temps il faudrait pour mener à bien cette opération. Ainsi, nous pouvons simplement utiliser un fichier d'indicateur pour signaler à ClusterControl d'ignorer la récupération du nœud.
Tout d'abord, ajoutez la ligne suivante dans le fichier /etc/cmon.d/cmon_X.cnf (où X est l'ID du cluster) sur le nœud ClusterControl :
node_recovery_lock_file=/root/do_not_recoverEnsuite, redémarrez le service cmon pour charger la modification :
$ systemctl restart cmon # service cmon restartEnfin, assurez-vous que le fichier spécifié est présent sur le nœud que nous voulons ignorer pour la récupération de ClusterControl :
$ touch /root/do_not_recoverQuel que soit l'état du mode de récupération et de maintenance automatique, ClusterControl ne récupère le nœud que lorsque ce fichier d'indicateur n'existe pas. L'administrateur est alors chargé de créer et de supprimer le fichier sur le nœud de la base de données.
C'est tout, les amis. Bonne maintenance !



