Ce billet de blog est la suite de la partie 1 précédente, où nous avons couvert les bases de l'intégration SNMP avec ClusterControl.
Dans cet article de blog, nous allons nous concentrer sur les interruptions SNMP et les alertes. Les interruptions SNMP sont les messages d'alerte les plus fréquemment utilisés, envoyés d'un appareil distant compatible SNMP (un agent) à un collecteur central, le « gestionnaire SNMP ». Dans le cas de ClusterControl, un trap peut être une alerte après que l'alarme critique d'un cluster n'est pas 0, indiquant que quelque chose de grave se passe.
Comme indiqué dans le billet de blog précédent, dans le cadre de cette preuve de concept, nous avons deux définitions de notifications d'interruption SNMP :
criticalAlarmNotification NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification if critical alarm is not 0"
::= { alarmNotification 1 }
criticalAlarmNotificationEnded NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification ended - Critical alarm is 0"
::= { alarmNotification 2 }Les notifications (ou traps) sont CriticalAlarmNotification et CriticalAlarmNotificationEnded. Les deux événements de notification peuvent être utilisés pour signaler à notre service Nagios, que le cluster ait activement des alarmes critiques ou non. Dans Nagios, le terme pour cela est contrôle passif, par lequel Nagios n'essaye pas de déterminer si un hôte/service est DOWN ou UNREACHABLE. Nous allons également configurer les vérifications actives, où les vérifications sont initiées par la logique de vérification dans le démon Nagios en utilisant la définition de service pour surveiller également les alarmes critiques/avertissement signalées par notre cluster.
Notez que cet article de blog nécessite la configuration correcte de l'agent MIB et SNMP de Manynines, comme indiqué dans la première partie de cette série de blogs.
Installer Nagios Core
Nagios Core est la version gratuite de la suite de surveillance Nagios. Tout d'abord, nous devons l'installer ainsi que tous les packages nécessaires, suivis des plugins Nagios, snmptrapd et snmptt. Notez que les instructions de cet article de blog supposent que tous les nœuds s'exécutent sur CentOS 7.
Installez les packages nécessaires pour exécuter Nagios :
$ yum -y install httpd php gcc glibc glibc-common wget perl gd gd-devel unzip zip sendmail net-snmp-utils net-snmp-perlCréez un utilisateur nagios et un groupe nagcmd pour permettre aux commandes externes d'être exécutées via l'interface Web, ajoutez les utilisateurs nagios et apache pour faire partie du groupe nagcmd :
$ useradd nagios
$ groupadd nagcmd
$ usermod -a -G nagcmd nagios
$ usermod -a -G nagcmd apacheTéléchargez la dernière version de Nagios Core à partir d'ici, compilez-la et installez-la :
$ cd ~
$ wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.6.tar.gz
$ tar -zxvf nagios-4.4.6.tar.gz
$ cd nagios-4.4.6
$ ./configure --with-nagios-group=nagios --with-command-group=nagcmd
$ make all
$ make install
$ make install-init
$ make install-config
$ make install-commandmodeInstallez la configuration Web de Nagios :
$ make install-webconfEn option, installez le thème d'exfoliation Nagios (ou vous pouvez vous en tenir au thème par défaut) :
$ make install-exfoliationCréez un compte utilisateur (nagiosadmin) pour vous connecter à l'interface Web de Nagios. N'oubliez pas le mot de passe que vous avez attribué à cet utilisateur :
$ htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminRedémarrez le serveur Web Apache pour que les nouveaux paramètres prennent effet :
$ systemctl restart httpd
$ systemctl enable httpdTéléchargez les plugins Nagios à partir d'ici, compilez-les et installez-les :
$ cd ~
$ wget https://nagios-plugins.org/download/nagios-plugins-2.3.3.tar.gz
$ tar -zxvf nagios-plugins-2.3.3.tar.gz
$ cd nagios-plugins-2.3.3
$ ./configure --with-nagios-user=nagios --with-nagios-group=nagios
$ make
$ make installVérifiez les fichiers de configuration par défaut de Nagios :
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Nagios Core 4.4.6
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 2020-04-28
License: GPL
Website: https://www.nagios.org
Reading configuration data...
Read main config file okay...
Read object config files okay...
Running pre-flight check on configuration data...
Checking objects...
Checked 8 services.
Checked 1 hosts.
Checked 1 host groups.
Checked 0 service groups.
Checked 1 contacts.
Checked 1 contact groups.
Checked 24 commands.
Checked 5 time periods.
Checked 0 host escalations.
Checked 0 service escalations.
Checking for circular paths...
Checked 1 hosts
Checked 0 service dependencies
Checked 0 host dependencies
Checked 5 timeperiods
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
If everything looks okay, start Nagios and configure it to start on boot:
$ systemctl start nagios
$ systemctl enable nagiosOuvrez le navigateur et allez sur https://{IPaddress}/nagios et vous devriez voir apparaître une authentification de base HTTP où vous devez spécifier le nom d'utilisateur comme nagiosadmin avec votre mot de passe choisi créé précédemment.
Ajout du serveur ClusterControl dans Nagios
Créez un fichier de définition d'hôte Nagios pour ClusterControl :
$ vim /usr/local/nagios/etc/objects/clustercontrol.cfgEt ajoutez les lignes suivantes :
define host {
use linux-server
host_name clustercontrol.local
alias clustercontrol.mydomain.org
address 192.168.10.50
}
define service {
use generic-service
host_name clustercontrol.local
service_description Critical alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.2 -c0
}
define service {
use generic-service
host_name clustercontrol.local
service_description Warning alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.3 -w0
}
define service {
use snmp_trap_template
host_name clustercontrol.local
service_description Critical alarm traps
check_interval 60 ; Don't clear for 1 hour
}
Quelques explications :
-
Dans la première section, nous définissons notre hôte, avec le nom d'hôte et l'adresse du serveur ClusterControl.
-
Les sections de service où nous mettons nos définitions de service à surveiller par Nagios. Les deux premiers indiquent essentiellement au service de vérifier la sortie SNMP pour un ID d'objet particulier. Le premier service concerne l'alarme critique, nous ajoutons donc -c0 dans la commande check_snmp pour indiquer qu'il doit s'agir d'une alerte critique dans Nagios si la valeur dépasse 0. Alors que pour les alarmes d'avertissement, nous l'indiquerons avec un avertissement si la valeur est 1 et plus.
-
La dernière définition de service concerne les interruptions SNMP que nous attendrions du serveur ClusterControl si l'alarme critique soulevé est supérieur à 0. Cette section utilisera la définition snmp_trap_template, comme indiqué à l'étape suivante.
Configurez le snmp_trap_template en ajoutant les lignes suivantes dans /usr/local/nagios/etc/objects/templates.cfg :
define service {
name snmp_trap_template
service_description SNMP Trap Template
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized
process_perf_data 0
obsess_over_service 0 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
check_command check-host-alive ; This will be used to reset the service to "OK"
is_volatile 1
check_period 24x7
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
notification_interval 60
notification_period 24x7
notification_options w,u,c,r
contact_groups admins ; Modify this to match your Nagios contactgroup definitions
register 0
}
Incluez le fichier de configuration de ClusterControl dans Nagios, en ajoutant la ligne suivante à l'intérieur
/usr/local/nagios/etc/nagios.cfg:
cfg_file=/usr/local/nagios/etc/objects/clustercontrol.cfgExécutez une vérification de la configuration avant le vol :
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgAssurez-vous d'obtenir la ligne suivante à la fin de la sortie :
"Things look okay - No serious problems were detected during the pre-flight check"Redémarrez Nagios pour charger la modification :
$ systemctl restart nagiosMaintenant, si nous regardons la page Nagios sous la section Service (menu de gauche), nous verrions quelque chose comme ceci :
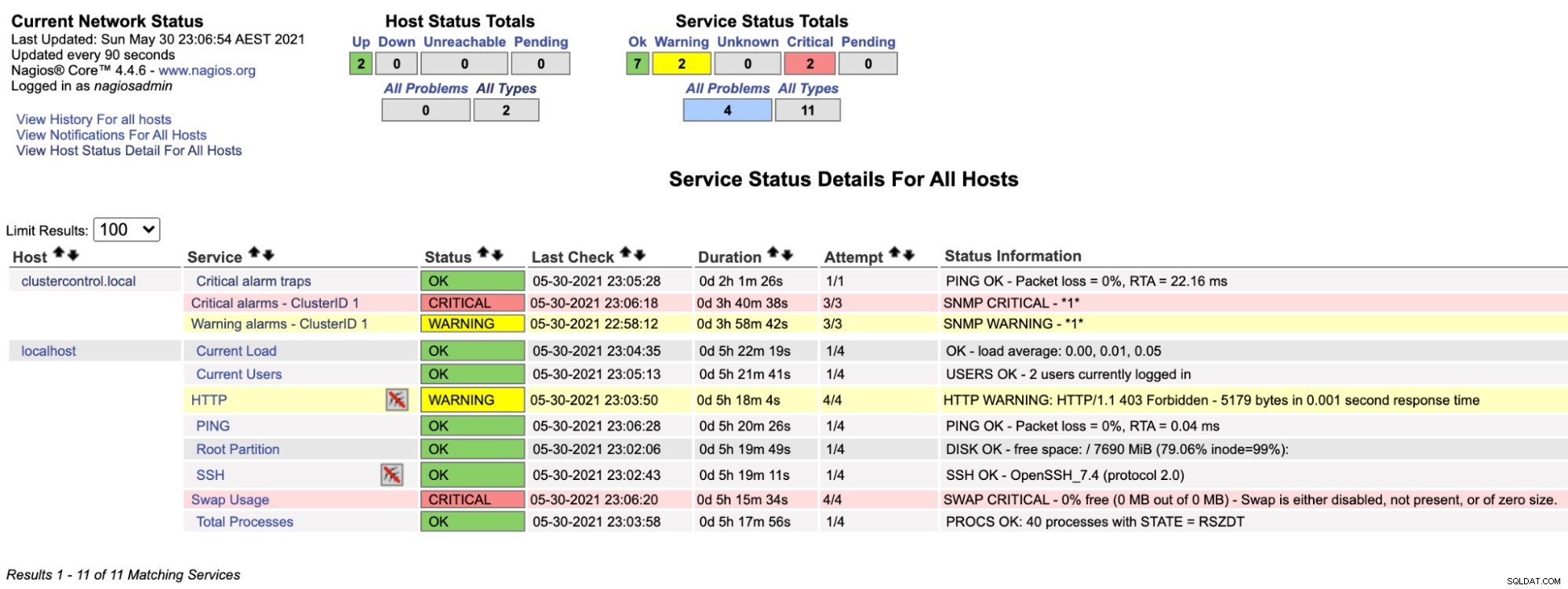
Notez que la ligne "Alarmes critiques - ClusterID 1" devient rouge si la valeur d'alarme critique signalée par ClusterControl est supérieure à 0, tandis que la ligne "Alarmes d'avertissement - ClusterID 1" est jaune, indiquant qu'une alarme d'avertissement est déclenchée. Au cas où rien d'intéressant ne se passerait, vous verriez que tout est vert pour clustercontrol.local.
Configurer Nagios pour recevoir un piège
Les traps sont envoyés par des appareils distants au serveur Nagios, c'est ce qu'on appelle une vérification passive. Idéalement, nous ne savons pas quand un trap sera envoyé car cela dépend de l'appareil émetteur qui décide d'envoyer un trap. Par exemple avec un onduleur (batterie de secours), dès que l'appareil perd de l'alimentation, il enverra un trap pour dire "hé, j'ai perdu de l'alimentation". De cette façon, Nagios est immédiatement informé.
Afin de recevoir des traps SNMP, nous devons configurer le serveur Nagios avec les éléments suivants :
-
snmptrapd (démon récepteur d'interruptions SNMP)
-
snmptt (traducteur d'interruptions SNMP, le démon de gestion des interruptions)
Après que snmptrapd reçoive un trap, il le transmettra à snmptt où nous le configurerons pour mettre à jour le système Nagios, puis Nagios enverra l'alerte en fonction de la configuration du groupe de contact.
Installez le référentiel EPEL, suivi des packages nécessaires :
$ yum -y install epel-release
$ yum -y install net-snmp snmptt net-snmp-perl perl-Sys-SyslogConfigurez le démon d'interruption SNMP dans /etc/snmp/snmptrapd.conf et définissez les lignes suivantes :
disableAuthorization yes
traphandle default /usr/sbin/snmptthandlerCe qui précède signifie simplement que les interruptions reçues par le démon snmptrapd seront transmises à /usr/sbin/snmptthandler.
Ajoutez le fichier SEVERALNINES-CLUSTERCONTROL-MIB.txt dans /usr/share/snmp/mibs en créant /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt :
$ ll /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt
-rw-r--r-- 1 root root 4029 May 30 20:08 /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txtCréez /etc/snmp/snmp.conf (notice sans le "d") et ajoutez-y notre MIB personnalisée :
mibs +SEVERALNINES-CLUSTERCONTROL-MIBDémarrez le service snmptrapd :
$ systemctl start snmptrapd
$ systemctl enable snmptrapdEnsuite, nous devons configurer les lignes de configuration suivantes dans /etc/snmp/snmptt.ini :
net_snmp_perl_enable = 1
snmptt_conf_files = <<END
/etc/snmp/snmptt.conf
/etc/snmp/snmptt-cc.conf
ENDNotez que nous avons activé le module net_snmp_perl et avons ajouté un autre chemin de configuration, /etc/snmp/snmptt-cc.conf dans snmptt.ini. Nous devons définir ici les événements snmptt de ClusterControl afin qu'ils puissent être transmis à Nagios. Créez un nouveau fichier dans /etc/snmp/snmptt-cc.conf et ajoutez les lignes suivantes :
MIB: SEVERALNINES-CLUSTERCONTROL-MIB (file:/usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt) converted on Sun May 30 19:17:33 2021 using snmpttconvertmib v1.4.2
EVENT criticalAlarmNotification .1.3.6.1.4.1.57397.1.1.3.1 "Status Events" Critical
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 2 "Critical - Critical alarm is $1 for cluster ID $2"
SDESC
Notification if critical alarm is not 0
Variables:
1: totalCritical
2: clusterId
EDESC
EVENT criticalAlarmNotificationEnded .1.3.6.1.4.1.57397.1.1.3.2 "Status Events" Normal
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 0 "Normal - Critical alarm is $1 for cluster ID $2"
SDESC
Notification ended - critical alarm is 0
Variables:
1: totalCritical
2: clusterId
EDESCQuelques explications :
-
Nous avons défini deux interruptions :CriticalAlarmNotification et CriticalAlarmNotificationEnded.
-
CriticalAlarmNotification déclenche simplement une alerte critique et la transmet au service "Critical alarm traps" défini dans Nagios. Le $aA signifie renvoyer l'adresse IP de l'agent de déroutement. La valeur 2 est la valeur du résultat de la vérification qui dans ce cas est critique (0=OK, 1=AVERTISSEMENT, 2=CRITIQUE, 3=INCONNU).
-
CriticalAlarmNotificationEnded déclenche simplement une alerte OK et la transmet au service "Critical alarm traps", pour annuler la piège précédent après que tout redevienne normal. Le $aA signifie renvoyer l'adresse IP de l'agent de déroutement. La valeur 0 est la valeur du résultat de la vérification qui, dans ce cas, est OK. Pour plus de détails sur les substitutions de chaînes reconnues par snmptt, consultez cet article dans la section "FORMAT".
-
Vous pouvez utiliser snmpttconvertmib pour générer un fichier de gestionnaire d'événements snmptt pour une MIB particulière.
Notez que par défaut, le chemin des gestionnaires d'événements n'est pas fourni par Nagios Core. Par conséquent, nous devons copier ce répertoire eventhandlers depuis la source Nagios sous le répertoire contrib, comme indiqué ci-dessous :
$ cp -Rf nagios-4.4.6/contrib/eventhandlers /usr/local/nagios/share/
$ chown -Rf nagios:nagios /usr/local/nagios/share/eventhandlersNous devons également affecter le groupe snmptt dans le cadre du groupe nagcmd, afin qu'il puisse exécuter nagios.cmd dans le script submit_check_result :
$ usermod -a -G nagcmd snmpttDémarrez le service snmptt :
$ systemctl start snmptt
$ systemctl enable snmpttLe gestionnaire SNMP (serveur Nagios) est maintenant prêt à accepter et à traiter nos traps SNMP entrants.
Envoi d'un trap depuis le serveur ClusterControl
Supposons que l'on veuille envoyer un trap SNMP au gestionnaire SNMP, 192.168.10.11 (serveur Nagios) parce que le nombre total d'alarmes critiques a atteint 2 pour le cluster ID 1, on exécuterait la commande suivante sur le serveur ClusterControl (côté client), 192.168.10.50 :
$ snmptrap -v2c -c private 192.168.10.11 '' SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification \
SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical i 2 \
SEVERALNINES-CLUSTERCONTROL-MIB::clusterId i 1Ou, au format OID (recommandé) :
$ snmptrap -v2c -c private 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.1 \
.1.3.6.1.4.1.57397.1.1.1.2 i 2 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Où, .1.3.6.1.4.1.57397.1.1.3.1 est égal à l'événement d'interruption CriticalAlarmNotification, et les OID suivants sont des représentations du nombre total d'alarmes critiques actuelles et de l'ID de cluster, respectivement .
Sur le serveur Nagios, vous devriez remarquer que le service trap est devenu rouge :
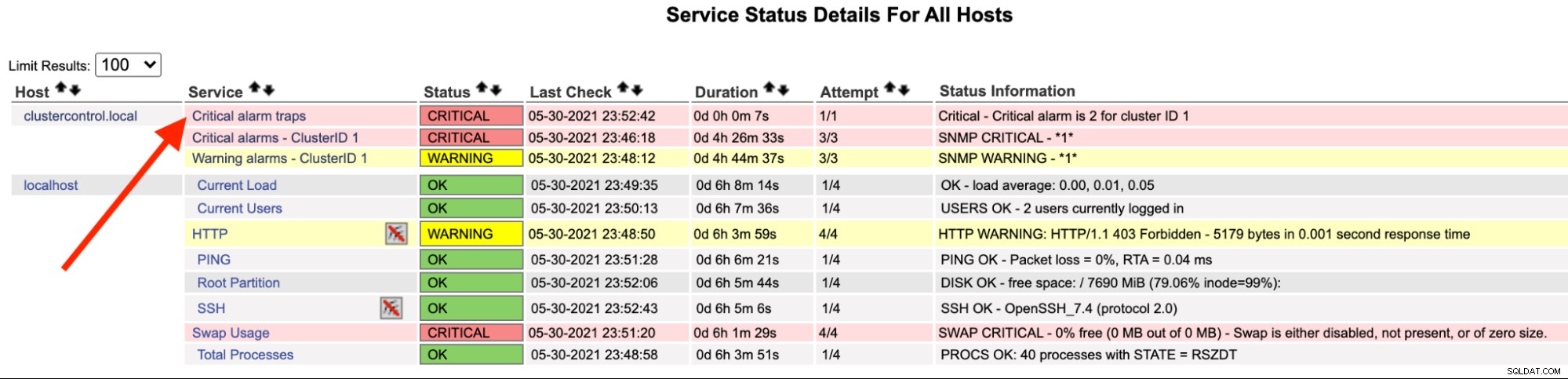
Vous pouvez également le voir dans le /var/log/messages de la ligne suivante :
May 30 23:52:39 ip-10-15-2-148 snmptrapd[27080]: 2021-05-30 23:52:39 UDP: [192.168.10.50]:33151->[192.168.10.11]:162 [UDP: [192.168.10.50]:33151->[192.168.10.11]:162]:#012DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (2423020) 6:43:50.20#011SNMPv2-MIB::snmpTrapOID.0 = OID: SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification#011SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical = INTEGER: 2#011SEVERALNINES-CLUSTERCONTROL-MIB::clusterId = INTEGER: 1
May 30 23:52:42 nagios.local snmptt[29557]: .1.3.6.1.4.1.57397.1.1.3.1 Critical "Status Events" UDP192.168.10.5033151-192.168.10.11162 - Notification if critical alarm is not 0
May 30 23:52:42 nagios.local nagios: EXTERNAL COMMAND: PROCESS_SERVICE_CHECK_RESULT;192.168.10.50;Critical alarm traps;2;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: PASSIVE SERVICE CHECK: clustercontrol.local;Critical alarm traps;0;PING OK - Packet loss = 0%, RTA = 22.16 ms
May 30 23:52:42 nagios.local nagios: SERVICE NOTIFICATION: nagiosadmin;clustercontrol.local;Critical alarm traps;CRITICAL;notify-service-by-email;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: SERVICE ALERT: clustercontrol.local;Critical alarm traps;CRITICAL;HARD;1;Critical - Critical alarm is 2 for cluster ID 1Une fois l'alarme résolue, pour envoyer un trap normal, nous pouvons exécuter la commande suivante :
$ snmptrap -c private -v2c 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.2 \
.1.3.6.1.4.1.57397.1.1.1.2 i 0 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Où, .1.3.6.1.4.1.57397.1.1.3.2 est égal à l'événement CriticalAlarmNotificationEnded, et les OID suivants sont des représentations du nombre total d'alarmes critiques actuelles (devrait être 0 dans ce cas ) et l'ID de cluster, respectivement.
Sur le serveur Nagios, vous devriez remarquer que le service trap est redevenu vert :
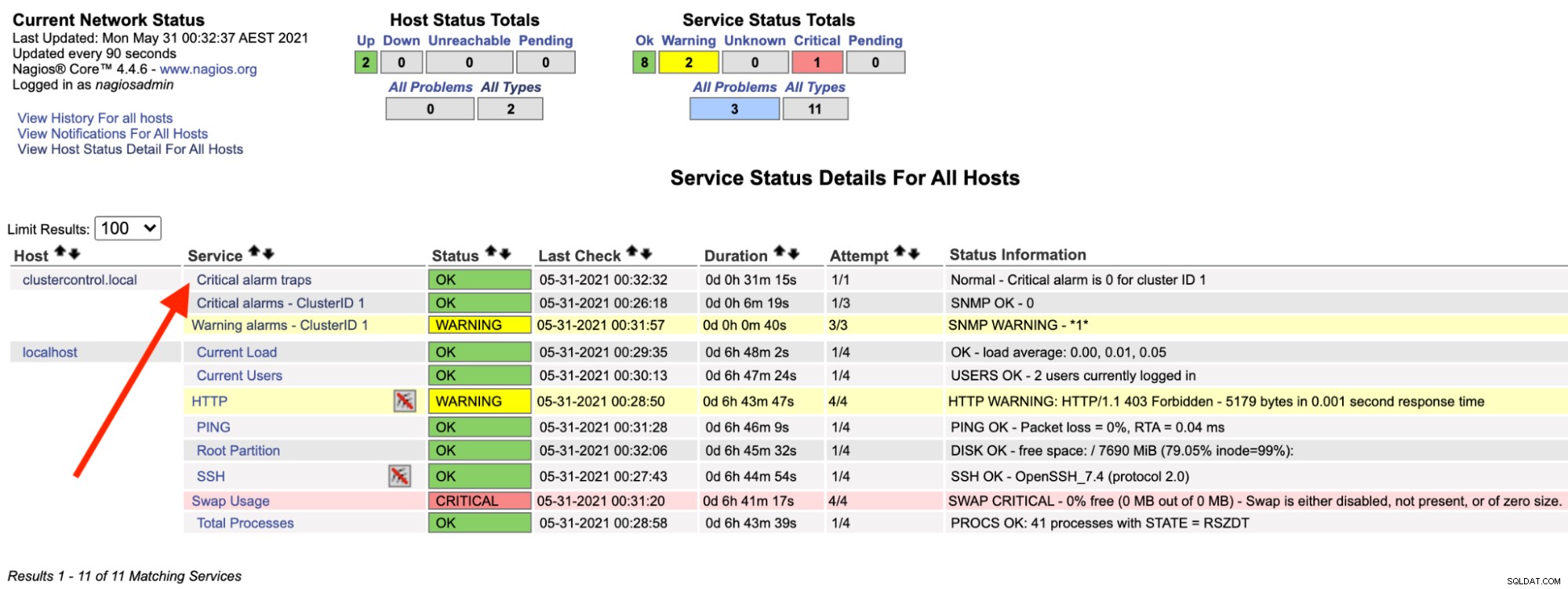
Ce qui précède peut être automatisé avec un simple script bash :
#!/bin/bash
# alarmtrapper.bash - SNMP trapper for ClusterControl alarms
CLUSTER_ID=1
SNMP_MANAGER=192.168.10.11
INTERVAL=10
send_critical_snmp_trap() {
# send critical trap
local val=$1
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.1 .1.3.6.1.4.1.57397.1.1.1.1 i ${val} .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
send_zero_critical_snmp_trap() {
# send OK trap
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.2 .1.3.6.1.4.1.57397.1.1.1.1 i 0 .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
while true; do
count=$(s9s alarm --list --long --cluster-id=${CLUSTER_ID} --batch | grep CRITICAL | wc -l)
[ $count -ne 0 ] && send_critical_snmp_trap $count || send_zero_critical_snmp_trap
sleep $INTERVAL
donePour exécuter le script en arrière-plan, faites simplement :
$ bash alarmtrapper.bash &À ce stade, nous devrions être en mesure de voir le service "Critical alarm traps" de Nagios en action s'il y a automatiquement une panne dans notre cluster.
Réflexions finales
Dans cette série de blogs, nous avons montré une preuve de concept sur la manière dont ClusterControl peut être configuré pour la surveillance, la génération/le traitement des traps et les alertes à l'aide du protocole SNMP. Cela marque également le début de notre voyage pour incorporer SNMP dans nos futures versions. Restez à l'écoute, car nous apporterons d'autres mises à jour sur cette fonctionnalité intéressante.



