Dans ce tutoriel Hadoop Big Data , nous allons vous fournir une description détaillée du bloc de données Hadoop HDFS. Tout d'abord, nous verrons ce qu'est un bloc de données dans Hadoop, quelle est leur importance, pourquoi la taille des blocs de données HDFS est de 128 Mo.
Nous aborderons également l'exemple des blocs de données dans hadoop et divers avantages de HDFS dans Hadoop.
Introduction au bloc de données HDFS
Hadoop HDFS diviser les fichiers volumineux en petits morceaux appelés blocs . Le bloc est la représentation physique des données. Il contient un minimum de données pouvant être lues ou écrites. HDFS stocke chaque fichier sous forme de blocs. Le client HDFS n'a aucun contrôle sur le bloc comme l'emplacement du bloc, Namenode décide de toutes ces choses.
Par défaut, la taille de bloc HDFS est de 128 Mo que vous pouvez modifier selon vos besoins. Tous les blocs HDFS ont la même taille, sauf le dernier bloc, qui peut être de la même taille ou plus petit.
Le framework Hadoop divise les fichiers en blocs de 128 Mo, puis les stocke dans le système de fichiers Hadoop. L'application Apache Hadoop est responsable de la distribution du bloc de données sur plusieurs nœuds.
Exemple-
Supposons que la taille du fichier soit de 513 Mo et que nous utilisions la configuration par défaut de la taille de bloc de 128 Mo. Ensuite, le framework Hadoop créera 5 blocs, les quatre premiers blocs de 128 Mo, mais le dernier bloc sera de 1 Mo seulement.
Par conséquent, à partir de l'exemple, il est clair qu'il n'est pas nécessaire que dans HDFS chaque fichier stocké soit un multiple exact de la taille de bloc configurée 128 Mo, 256 Mo, etc. Par conséquent, le bloc final pour le fichier utilise uniquement l'espace nécessaire.
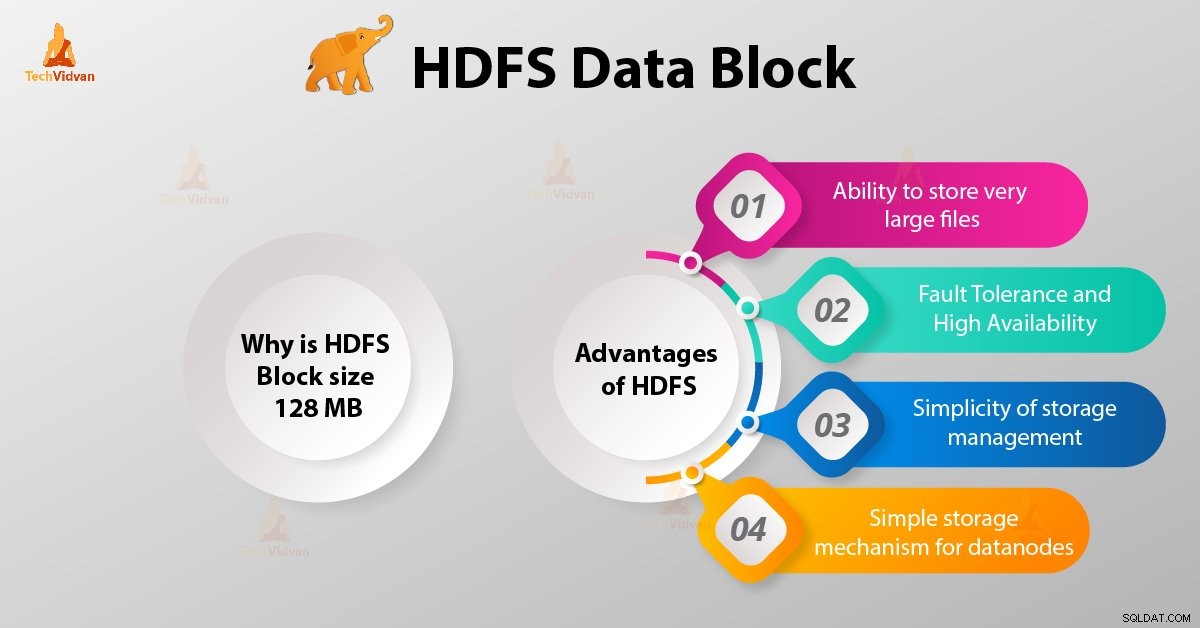
Pourquoi la taille du bloc HDFS est-elle de 128 Mo ?
HDFS stocke des téraoctets et des pétaoctets de données. Si la taille du bloc HDFS est de 4 Ko comme le système de fichiers Linux, nous aurons trop de blocs de données dans Hadoop HDFS, donc trop de métadonnées.
Ainsi, maintenir et gérer ce grand nombre de blocs et de métadonnées créera une surcharge et un trafic énormes, ce que nous ne voulons pas.
La taille des blocs ne peut pas être si grande que le système attend très longtemps qu'une dernière unité de traitement de données termine son travail.
Avantages de HDFS
Après avoir appris ce qu'est HDFS Data Block, discutons maintenant des avantages de Hadoop HDFS.
1. Possibilité de stocker des fichiers très volumineux
Hadoop HDFS stocke des fichiers très volumineux qui sont encore plus volumineux que la taille d'un seul disque, car le framework Hadoop divise le fichier en blocs et le distribue sur différents nœuds.
2. Tolérance aux pannes et haute disponibilité de HDFS
Le framework Hadoop peut facilement répliquer des blocs entre les nœuds de données. Fournissez ainsi une tolérance aux pannes et une haute disponibilité HDFS.
3. Simplicité de gestion du stockage
Comme HDFS a une taille de bloc fixe (128 Mo), il est donc très facile de calculer le nombre de blocs pouvant être stockés sur le disque.
4. Mécanisme de stockage simple pour les nœuds de données
Block in HDFS simplifie le stockage des Datanodes . Nom de nœud conserve les métadonnées de tous les blocs. HDFS Datanode n'a pas besoin de se soucier des métadonnées de bloc telles que les autorisations de fichiers, etc.
Conclusion
Par conséquent, le bloc de données HDFS est la plus petite unité de données dans un système de fichiers. La taille par défaut du bloc HDFS est de 128 Mo, que vous pouvez configurer selon vos besoins. Les blocs HDFS sont faciles à répliquer entre les nœuds de données. Par conséquent, fournissez une tolérance aux pannes et une haute disponibilité de HDFS.
Pour toute question ou suggestion concernant les blocs de données Hadoop HDFS, faites-le nous savoir en laissant un commentaire dans une section ci-dessous.



