Votre question est vraiment imprécis. S'il vous plaît, suivez les suggestions de @RiggsFolly et lisez les références sur la façon de poser une bonne question.
De plus, comme suggéré par @DuduMarkovitz, vous devriez commencer par simplifier le problème et nettoyer vos données. Quelques ressources pour vous aider à démarrer :
- Tutoriel de traitement de texte de base par Matt Deny
- Manipulation et traitement des chaînes dans R par Gaston Sanchez
Une fois que vous êtes satisfait des résultats, vous pouvez alors procéder à l'identification d'un groupe pour chaque Var1 entrée (cela vous aidera sur la route à effectuer d'autres analyses/manipulations sur des entrées similaires) Cela pourrait être fait de différentes manières, mais comme mentionné par @GordonLinoff, une possibilité est la distance de Levenshtein.
Remarque :pour 50 000 entrées, le résultat ne sera pas précis à 100 % car il ne sera pas toujours catégorisez les termes dans le groupe approprié, mais cela devrait considérablement réduire les efforts manuels.
Dans R, vous pouvez le faire en utilisant adist()
À l'aide de vos données d'exemple :
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
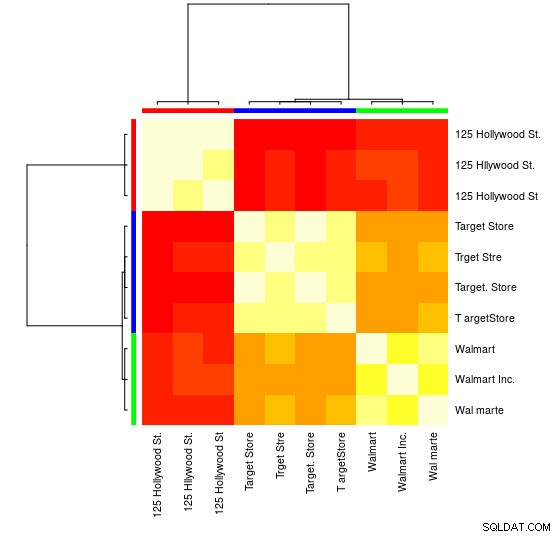
Pour ce petit échantillon, vous pouvez voir les 3 groupes distincts (les clusters de faibles valeurs de distance de Levensthein) et pouvez facilement les affecter manuellement, mais pour des ensembles plus grands, vous aurez probablement besoin d'un algorithme de clustering.
Je vous ai déjà signalé dans les commentaires l'un de mes réponse précédente
montrant comment faire cela en utilisant hclust() et la méthode de la variance minimale de Ward, mais je pense qu'ici vous feriez mieux d'utiliser d'autres techniques (l'une de mes ressources préférées sur le sujet pour un aperçu rapide de certaines des méthodes les plus largement utilisées dans R est celle-ci réponse détaillée
)
Voici un exemple utilisant le clustering de propagation d'affinité :
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
Vous trouverez dans l'objet APResult d_ap les éléments associés à chaque cluster et le nombre optimal de clusters, dans ce cas :3.
> example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
Vous pouvez également voir une représentation visuelle :
> heatmap(d_ap, margins = c(10, 10))
Ensuite, vous pouvez effectuer d'autres manipulations pour chaque groupe. Comme exemple, ici j'utilise hunspell pour rechercher chaque mot séparé de Var1 dans un dictionnaire en_US pour les fautes d'orthographe et essayez de trouver, dans chaque group , dont id n'a pas de fautes d'orthographe (potential_id )
library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
Ce qui donne :
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
Remarque :Ici comme nous n'avons effectué aucun traitement de texte, les résultats ne sont pas très concluants, mais vous voyez l'idée.
Données
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)