Tout le monde a donné un large éventail d'opinions, mais je ne pense pas que quiconque ait vraiment mis le doigt sur la tête.
Lorsqu'il s'agit de stocker des données, la quantité de données, le taux d'accès et plusieurs autres facteurs déterminent tous quelle est la meilleure plate-forme de stockage.
Certaines personnes ont suggéré d'utiliser memcached. Bien que ce soit une réponse valide (vous pouvez utilisez-le), je ne pense pas que ce soit une bonne idée, uniquement sur la base du fait que memcached stocke les données dans la mémoire de votre serveur.
Votre mémoire n'est pas destinée au stockage de données, mais à l'utilisation des applications réelles, du système d'exploitation, des bibliothèques partagées, etc.
Le stockage de données dans la mémoire peut causer de nombreux problèmes avec d'autres applications en cours d'exécution. Si vous stockez trop de données dans votre RAM, vos applications ne pourront pas effectuer les opérations qui leur sont assignées.
Bien que ce soit plus rapide qu'une plate-forme de stockage sur disque telle que MySQL, ce n'est pas aussi fiable.
Personnellement, j'utiliserais MySQL comme moteur de stockage côté serveur. Cela réduirait le nombre de problèmes que vous rencontreriez et rendrait également les données très gérables.
Pour accélérer les réponses à vos clients, j'envisagerais d'exécuter node sur votre serveur.
En effet, il est piloté par les événements et non bloquant.
Qu'est-ce que cela signifie ?
Eh bien, lorsque le client A demande des données stockées sur le disque dur, PHP peut traditionnellement dire au C++, récupérez-moi ce bloc de données stocké sur ce secteur du disque dur. C++ dirait "ok pas de problème", et pendant qu'il va chercher les informations, PHP attendra que les données soient lues et renvoyées avant de continuer ses opérations, bloquant tous les autres clients en attendant.
Avec node, c'est un peu différent. Node dira au noyau, "allez me chercher ce bloc d'informations et quand vous aurez terminé, appelez-moi", puis il continuera à accepter les requêtes d'autres clients qui n'ont peut-être pas besoin d'accéder au disque.
Alors du coup parce qu'on a assigné un callback au noyau, on n'a pas à attendre :), des jours heureux.
Jetez un oeil à cette image: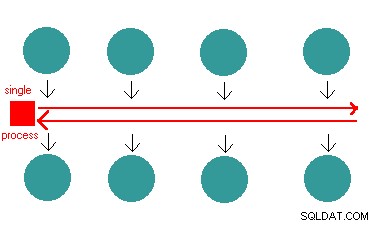
Cela pourrait vraiment être la réponse que vous recherchez, veuillez consulter ce qui suit pour des informations plus descriptives et détaillées sur la façon dont node pourrait être le bon choix pour vous :