Vous avez peut-être entendu parler du terme « basculement » dans le contexte de la réplication MySQL. Vous vous êtes peut-être demandé de quoi il s'agissait alors que vous débutiez votre aventure avec les bases de données. Vous savez peut-être de quoi il s'agit, mais vous n'êtes pas sûr des problèmes potentiels qui y sont liés et de la manière dont ils peuvent être résolus ?
Dans cet article de blog, nous essaierons de vous donner une introduction à la gestion du basculement dans MySQL et MariaDB.
Nous discuterons de ce qu'est le basculement, pourquoi il est inévitable, quelle est la différence entre le basculement et le basculement. Nous aborderons le processus de basculement sous sa forme la plus générique. Nous aborderons également un peu les différents problèmes auxquels vous devrez faire face en relation avec le processus de basculement.
Que signifie "basculement" ?
La réplication MySQL est un collectif de nœuds, chacun d'eux pouvant jouer un rôle à la fois. Il peut devenir un maître ou une réplique. Il n'y a qu'un seul nœud maître à un instant donné. Ce nœud reçoit le trafic d'écriture et réplique les écritures sur ses répliques.
Comme vous pouvez l'imaginer, étant un point d'entrée unique pour les données dans le cluster de réplication, le nœud maître est assez important. Que se passerait-il s'il échouait et devenait indisponible ?
Il s'agit d'une condition assez sérieuse pour un cluster de réplication. Il ne peut accepter aucune écriture à un instant donné. Comme vous vous en doutez, l'une des répliques devra prendre en charge les tâches du maître et commencer à accepter les écritures. Le reste de la topologie de réplication peut également devoir changer - les répliques restantes doivent changer leur maître de l'ancien nœud défaillant vers le nouveau choisi. Ce processus de "promotion" d'une réplique pour qu'elle devienne maître après l'échec de l'ancien maître est appelé "basculement".
D'autre part, le "basculement" se produit lorsque l'utilisateur déclenche la promotion de la réplique. Un nouveau maître est promu à partir d'une réplique pointée par l'utilisateur et l'ancien maître devient généralement une réplique du nouveau maître.
La différence la plus importante entre « basculement » et « basculement » est l'état de l'ancien maître. Lorsqu'un basculement est effectué, l'ancien maître est, d'une certaine manière, inaccessible. Il a peut-être planté, il a peut-être subi un partitionnement réseau. Il ne peut pas être utilisé à un moment donné et son état est, généralement, inconnu.
En revanche, lorsqu'un basculement est effectué, l'ancien maître est bel et bien vivant. Cela a de graves conséquences. Si un maître est inaccessible, cela peut signifier que certaines données n'ont pas encore été envoyées aux esclaves (sauf si la réplication semi-synchrone a été utilisée). Certaines des données peuvent avoir été corrompues ou envoyées partiellement.
Il existe des mécanismes en place pour éviter de propager de telles corruptions sur les esclaves, mais le fait est que certaines données peuvent être perdues au cours du processus. D'autre part, lors d'un basculement, l'ancien maître est disponible et la cohérence des données est conservée.
Processus de basculement
Passons un peu de temps à discuter à quoi ressemble exactement le processus de basculement.
Crash principal détecté
Pour commencer, un maître doit tomber en panne avant que le basculement ne soit effectué. Lorsqu'il n'est pas disponible, un basculement est déclenché. Jusqu'à présent, cela semble simple, mais la vérité est que nous sommes déjà sur un terrain glissant.
Tout d'abord, comment la santé du maître est-elle testée ? Est-il testé à partir d'un seul endroit ou les tests sont-ils distribués ? Le logiciel de gestion du basculement tente-t-il simplement de se connecter au maître ou met-il en œuvre des vérifications plus avancées avant que la défaillance du maître ne soit déclarée ?
Imaginons la topologie suivante :
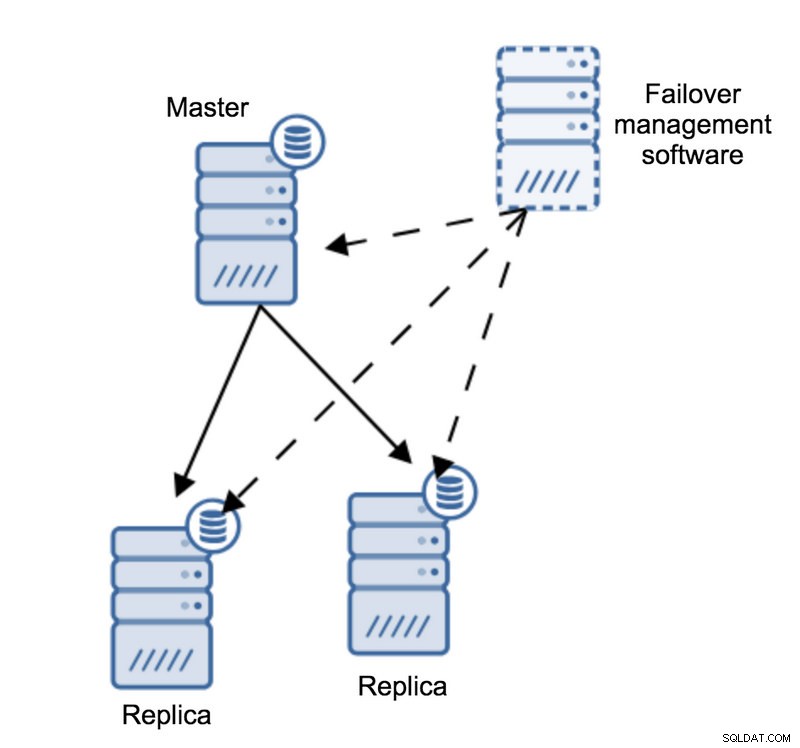
Nous avons un maître et deux répliques. Nous avons également un logiciel de gestion de basculement situé sur un hôte externe. Que se passerait-il si une connexion réseau entre l'hôte avec le logiciel de basculement et le maître échouait ?
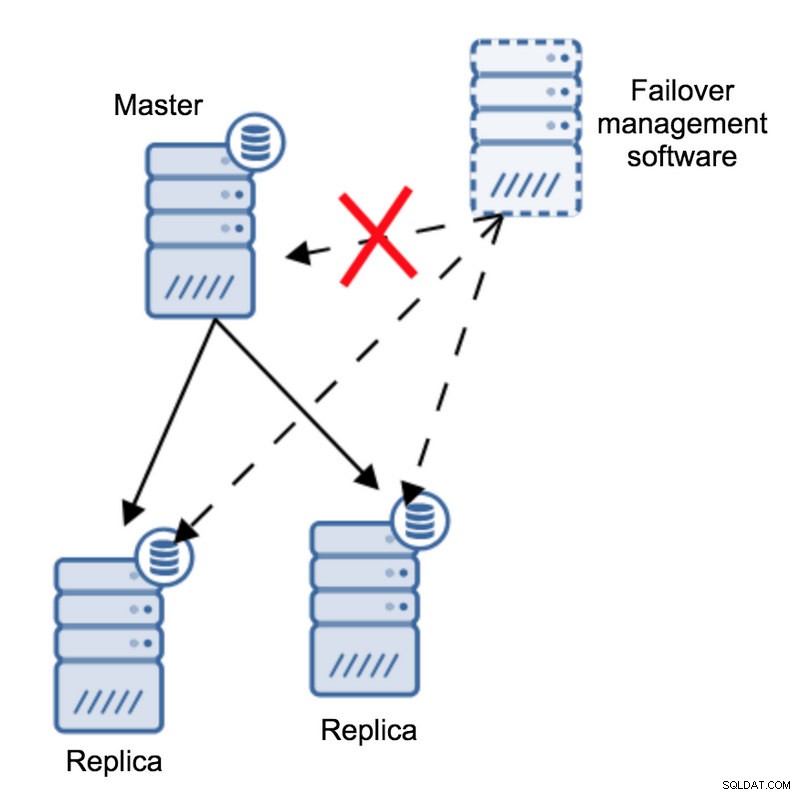
Selon le logiciel de gestion du basculement, le maître est tombé en panne - il n'y a pas de connectivité. Pourtant, la réplication elle-même fonctionne très bien. Ce qui devrait arriver ici, c'est que le logiciel de gestion du basculement essaie de se connecter aux répliques et de voir quel est leur point de vue.
Se plaignent-ils d'une réplication cassée ou se reproduisent-ils avec plaisir ?
Les choses peuvent devenir encore plus complexes. Et si nous ajoutions un proxy (ou un ensemble de proxys) ? Il sera utilisé pour acheminer le trafic - les écritures sur le maître et les lectures sur les répliques. Que se passe-t-il si un proxy ne peut pas accéder au maître ? Que se passe-t-il si aucun des proxys ne peut accéder au maître ?
Cela signifie que l'application ne peut pas fonctionner dans ces conditions. Le basculement (en fait, il s'agirait plutôt d'un basculement car le maître est techniquement actif) doit être déclenché ?
Techniquement, le maître est vivant mais il ne peut pas être utilisé par l'application. Ici, la logique métier doit entrer en jeu et une décision doit être prise.
Empêcher l'ancien maître de courir
Peu importe comment et pourquoi, s'il est décidé de promouvoir l'une des répliques pour devenir un nouveau maître, l'ancien maître doit être arrêté et, idéalement, il ne devrait pas pouvoir recommencer.
La manière dont cela peut être réalisé dépend des détails de l'environnement particulier; par conséquent, cette partie du processus de basculement est généralement renforcée par des scripts externes intégrés au processus de basculement via différents hooks.
Ces scripts peuvent être conçus pour utiliser les outils disponibles dans l'environnement particulier pour arrêter l'ancien maître. Il peut s'agir d'un appel CLI ou API qui arrêtera une VM ; il peut s'agir d'un code shell qui exécute des commandes via une sorte de dispositif de "gestion des lumières éteintes" ; il peut s'agir d'un script qui envoie des interruptions SNMP à l'unité de distribution d'alimentation qui désactive les prises de courant utilisées par l'ancien maître (sans alimentation électrique, nous pouvons être sûrs qu'il ne redémarrera pas).
Si un logiciel de gestion de basculement fait partie d'un produit plus complexe, qui gère également la récupération des nœuds (comme c'est le cas pour ClusterControl), l'ancien maître peut être marqué comme exclu des routines de récupération.
Vous vous demandez peut-être pourquoi il est si important d'empêcher que l'ancien master ne redevienne disponible ?
Le principal problème est que dans les configurations de réplication, un seul nœud peut être utilisé pour les écritures. En règle générale, vous vous en assurez en activant une variable read_only (et super_read_only, le cas échéant) sur toutes les répliques et en la gardant désactivée uniquement sur le maître.
Une fois qu'un nouveau maître est promu, il aura read_only désactivé. Le problème est que, si l'ancien maître n'est pas disponible, nous ne pouvons pas le remettre en lecture seule =1. Si MySQL ou un hôte tombe en panne, ce n'est pas vraiment un problème car les bonnes pratiques consistent à configurer my.cnf avec ce paramètre. Ainsi, une fois que MySQL démarre, il démarre toujours en mode lecture seule.
Le problème apparaît lorsqu'il ne s'agit pas d'un plantage mais d'un problème de réseau. L'ancien maître est toujours en cours d'exécution avec read_only désactivé, il n'est tout simplement pas disponible. Lorsque les réseaux convergent, vous vous retrouverez avec deux nœuds inscriptibles. Cela peut ou non être un problème. Certains des proxys utilisent le paramètre read_only comme indicateur si un nœud est un maître ou une réplique. Deux maîtres apparaissant à un moment donné peuvent entraîner un énorme problème car les données sont écrites sur les deux hôtes, mais les répliques ne reçoivent que la moitié du trafic d'écriture (la partie qui atteint le nouveau maître).
Parfois, il s'agit de paramètres codés en dur dans certains des scripts qui sont configurés pour se connecter uniquement à un hôte donné. Normalement, ils échoueraient et quelqu'un remarquerait que le maître a changé.
L'ancien maître étant disponible, ils s'y connecteront avec plaisir et une divergence de données surviendra. Comme vous pouvez le voir, s'assurer que l'ancien maître ne démarre pas est un élément assez prioritaire.
Décidez d'un candidat à la maîtrise
L'ancien maître est tombé et il ne reviendra pas de sa tombe, il est maintenant temps de décider quel hôte nous devrions utiliser comme nouveau maître. Habituellement, il y a plus d'une réplique à choisir, donc une décision doit être prise. Il existe de nombreuses raisons pour lesquelles une réplique peut être choisie plutôt qu'une autre, des vérifications doivent donc être effectuées.
Listes blanches et listes noires
Pour commencer, une équipe qui gère des bases de données peut avoir ses raisons de choisir une réplique plutôt qu'une autre lorsqu'elle décide d'un candidat maître. Peut-être qu'il utilise un matériel plus faible ou qu'il a un travail particulier qui lui est assigné (cette réplique exécute la sauvegarde, les requêtes analytiques, les développeurs y ont accès et exécutent des requêtes personnalisées et faites à la main). Il s'agit peut-être d'une réplique de test où une nouvelle version subit des tests d'acceptation avant de procéder à la mise à niveau. La plupart des logiciels de gestion de basculement prennent en charge les listes blanches et noires, qui peuvent être utilisées pour définir avec précision les répliques qui doivent ou ne peuvent pas être utilisées comme candidats maîtres.
Réplication semi-synchrone
Une configuration de réplication peut être un mélange de répliques asynchrones et semi-synchrones. Il y a une énorme différence entre eux - la réplique semi-synchrone est garantie de contenir tous les événements du maître. Un réplica asynchrone peut ne pas avoir reçu toutes les données. Le basculement vers celui-ci peut donc entraîner une perte de données. Nous préférerions voir des répliques semi-synchrones être promues.
Délai de réplication
Même si une réplique semi-synchrone contient tous les événements, ces événements peuvent toujours résider uniquement dans les journaux de relais. Avec un trafic important, toutes les répliques, qu'elles soient semi-synchronisées ou asynchrones, peuvent être en retard.
Le problème avec le décalage de réplication est que, lorsque vous promouvez une réplique, vous devez réinitialiser les paramètres de réplication afin qu'elle ne tente pas de se connecter à l'ancien maître. Cela supprimera également tous les journaux de relais, même s'ils ne sont pas encore appliqués, ce qui entraîne une perte de données.
Même si vous ne réinitialisez pas les paramètres de réplication, vous ne pouvez toujours pas ouvrir un nouveau maître aux connexions s'il n'a pas appliqué tous les événements de son journal de relais. Sinon, vous risquez que les nouvelles requêtes affectent les transactions du journal de relais, déclenchant toutes sortes de problèmes (par exemple, une application peut supprimer certaines lignes auxquelles accèdent les transactions du journal de relais).
Compte tenu de tout cela, la seule option sûre consiste à attendre que le journal de relais soit appliqué. Néanmoins, cela peut prendre un certain temps si la réplique était fortement en retard. Des décisions doivent être prises pour déterminer quelle réplique constituerait un meilleur maître - asynchrone, mais avec un petit décalage ou semi-synchrone, mais avec un décalage qui nécessiterait beaucoup de temps pour s'appliquer.
Transactions erronées
Même si les répliques ne doivent pas être écrites, il peut toujours arriver que quelqu'un (ou quelque chose) y ait écrit.
Il se peut qu'il n'y ait eu qu'une seule transaction dans le passé, mais cela peut toujours avoir un effet sérieux sur la capacité à effectuer un basculement. Le problème est strictement lié au Global Transaction ID (GTID), une fonctionnalité qui attribue un ID distinct à chaque transaction exécutée sur un nœud MySQL donné.
De nos jours, c'est une configuration assez populaire car elle apporte de grands niveaux de flexibilité et permet de meilleures performances (avec des répliques multithreads).
Le problème est que, lors du ré-asservissement sur un nouveau maître, la réplication GTID nécessite que tous les événements de ce maître (qui n'ont pas été exécutés sur la réplique) soient répliqués sur la réplique.
Considérons le scénario suivant :à un moment donné dans le passé, une écriture s'est produite sur une réplique. C'était il y a longtemps et cet événement a été purgé des journaux binaires de la réplique. À un moment donné, un maître a échoué et la réplique a été désignée comme nouveau maître. Toutes les répliques restantes seront esclaves du nouveau maître. Ils poseront des questions sur les transactions exécutées sur le nouveau maître. Il répondra avec une liste de GTID provenant de l'ancien maître et le seul GTID lié à cette ancienne écriture. Les GTID de l'ancien maître ne posent pas de problème car toutes les répliques restantes en contiennent au moins la majorité (sinon la totalité) et tous les événements manquants doivent être suffisamment récents pour être disponibles dans les journaux binaires du nouveau maître.
Dans le pire des cas, certains événements manquants seront lus à partir des journaux binaires et transférés vers des répliques. Le problème est avec cette ancienne écriture - cela s'est produit uniquement sur un nouveau maître, alors qu'il s'agissait encore d'une réplique, il n'existe donc pas sur les hôtes restants. Il s'agit d'un ancien événement, il n'y a donc aucun moyen de le récupérer à partir des journaux binaires. Par conséquent, aucune des répliques ne pourra asservir le nouveau maître. La seule solution ici est de prendre une action manuelle et d'injecter un événement vide avec ce GTID problématique sur toutes les répliques. Cela signifie également que, selon ce qui s'est passé, les répliques peuvent ne pas être synchronisées avec le nouveau maître.
Comme vous pouvez le voir, il est très important de suivre les transactions errantes et de déterminer s'il est sûr de promouvoir une réplique donnée pour devenir un nouveau maître. S'il contient des transactions errantes, ce n'est peut-être pas la meilleure option.
Gestion du basculement pour l'application
Il est crucial de garder à l'esprit que l'interrupteur principal, forcé ou non, a un effet sur l'ensemble de la topologie. Les écritures doivent être redirigées vers un nouveau nœud. Cela peut être fait de plusieurs façons et il est essentiel de s'assurer que ce changement est aussi transparent que possible pour l'application. Dans cette section, nous examinerons quelques exemples de la manière dont le basculement peut être rendu transparent pour l'application.
DNS
L'une des manières dont une application peut être pointée vers un maître consiste à utiliser des entrées DNS. Avec un TTL faible, il est possible de modifier l'adresse IP vers laquelle pointe une entrée DNS telle que "master.dc1.example.com". Un tel changement peut être effectué via des scripts externes exécutés pendant le processus de basculement.
Découverte de services
Des outils comme Consul ou etc.d peuvent également être utilisés pour diriger le trafic vers un emplacement correct. Ces outils peuvent contenir des informations indiquant que l'adresse IP du maître actuel est définie sur une certaine valeur. Certains d'entre eux donnent également la possibilité d'utiliser des recherches de nom d'hôte pour pointer vers une adresse IP correcte. Encore une fois, les entrées dans les outils de découverte de service doivent être conservées et l'une des façons d'y parvenir est d'apporter ces modifications pendant le processus de basculement, en utilisant des crochets exécutés à différentes étapes du basculement.
Procuration
Les proxys peuvent également être utilisés comme source de vérité sur la topologie. D'une manière générale, quelle que soit la manière dont ils découvrent la topologie (cela peut être soit un processus automatique, soit le proxy doit être reconfiguré lorsque la topologie change), ils doivent contenir l'état actuel de la chaîne de réplication, sinon ils ne pourraient pas acheminer correctement les requêtes.
L'approche consistant à utiliser un proxy comme source de vérité peut être assez courante en conjonction avec l'approche consistant à colocaliser des proxys sur des hôtes d'application. Il existe de nombreux avantages à colocaliser des serveurs proxy et Web :une communication rapide et sécurisée à l'aide d'un socket Unix, le maintien d'une couche de mise en cache (car certains proxys, comme ProxySQL, peuvent également faire la mise en cache) à proximité de l'application. Dans un tel cas, il est logique que l'application se connecte simplement au proxy et suppose qu'elle acheminera correctement les requêtes.
Basculement dans ClusterControl
ClusterControl applique les meilleures pratiques de l'industrie pour s'assurer que le processus de basculement est effectué correctement. Cela garantit également que le processus sera sûr - les paramètres par défaut sont destinés à abandonner le basculement si d'éventuels problèmes sont détectés. Ces paramètres peuvent être remplacés par l'utilisateur s'il souhaite donner la priorité au basculement sur la sécurité des données.
Une fois qu'une panne de maître a été détectée par ClusterControl, un processus de basculement est lancé et un premier hook de basculement est immédiatement exécuté :

Ensuite, la disponibilité principale est testée.

ClusterControl effectue des tests approfondis pour s'assurer que le maître est bien indisponible. Ce comportement est activé par défaut et il est géré par la variable suivante :
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.Dans l'étape suivante, ClusterControl s'assure que l'ancien maître est en panne et si ce n'est pas le cas, que ClusterControl n'essaiera pas de le récupérer :

L'étape suivante consiste à déterminer quel hôte peut être utilisé comme candidat maître. ClusterControl vérifie si une liste blanche ou une liste noire est définie.
Vous pouvez le faire en utilisant les variables suivantes dans le fichier de configuration cmon :
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.Il est également possible de configurer ClusterControl pour rechercher les différences dans les filtres de journaux binaires sur toutes les répliques. Cela peut être fait en utilisant la variable replication_check_binlog_filtration_bf_failover. Par défaut, ces vérifications sont désactivées. ClusterControl vérifie également qu'il n'y a pas de transactions errantes en place, ce qui pourrait causer des problèmes.

Vous pouvez également demander à ClusterControl de reconstruire automatiquement les répliques qui ne peuvent pas être répliquées à partir du nouveau maître en utilisant le paramètre suivant dans le fichier de configuration cmon :
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
Ensuite, un second script est exécuté :il est défini dans le paramètre replication_pre_failover_script. Ensuite, un candidat subit un processus de préparation.


ClusterControl attend que les journaux redo soient appliqués (en s'assurant que la perte de données est minimale). Il vérifie également s'il existe d'autres transactions disponibles sur les répliques restantes, qui n'ont pas été appliquées au candidat maître. Les deux comportements peuvent être contrôlés par l'utilisateur, en utilisant les paramètres suivants dans le fichier de configuration cmon :
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.Comme vous pouvez le constater, vous pouvez forcer un basculement même si tous les événements de journalisation n'ont pas été appliqués. Cela permet à l'utilisateur de décider ce qui a la priorité la plus élevée :la cohérence des données ou la vitesse de basculement.


Enfin, le maître est élu et le dernier script est exécuté (un script qui peut être défini comme replication_post_failover_script.
Si vous n'avez pas encore essayé ClusterControl, je vous encourage à le télécharger (c'est gratuit) et à essayer.
Détection principale dans ClusterControl
ClusterControl vous permet de déployer une pile haute disponibilité complète, y compris des couches de base de données et de proxy. La découverte de maîtres est toujours l'un des problèmes à traiter.
Comment ça marche dans ClusterControl ?
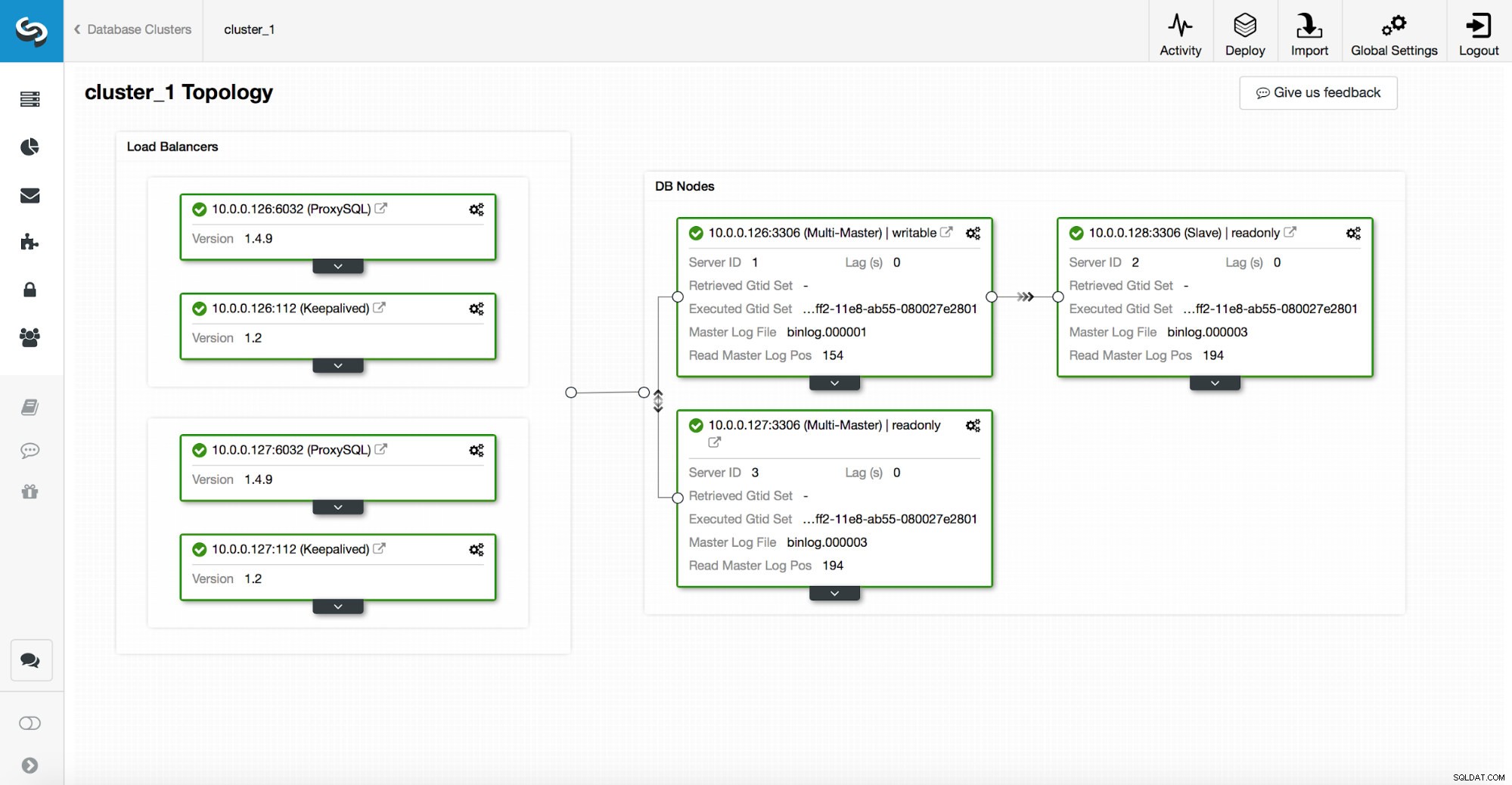
Une pile haute disponibilité, déployée via ClusterControl, se compose de trois éléments :
- couche de base de données
- couche proxy qui peut être HAProxy ou ProxySQL
- couche keepalive, qui, avec l'utilisation de l'adresse IP virtuelle, garantit une haute disponibilité de la couche proxy
Les proxys s'appuient sur des variables en lecture seule sur les nœuds.
Comme vous pouvez le voir dans la capture d'écran ci-dessus, un seul nœud de la topologie est marqué comme "inscriptible". C'est le maître et c'est le seul nœud qui recevra les écritures.
Un proxy (dans cet exemple, ProxySQL) surveillera cette variable et se reconfigurera automatiquement.
De l'autre côté de cette équation, ClusterControl s'occupe des changements de topologie :basculements et basculements. Il apportera les modifications nécessaires à la valeur read_only pour refléter l'état de la topologie après la modification. Si un nouveau maître est promu, il deviendra le seul nœud accessible en écriture. Si un maître est élu après le basculement, il aura read_only désactivé.
Au-dessus de la couche proxy, keepalived est déployé. Il déploie un VIP et surveille l'état des nœuds proxy sous-jacents. VIP pointe vers un nœud proxy à un moment donné. Si ce nœud tombe en panne, l'adresse IP virtuelle est redirigée vers un autre nœud, garantissant que le trafic dirigé vers VIP atteindra un nœud proxy sain.
Pour résumer, une application se connecte à la base de données en utilisant une adresse IP virtuelle. Cette IP pointe vers l'un des proxys. Les proxys redirigent le trafic en fonction de la structure topologique. Les informations sur la topologie sont dérivées de l'état read_only. Cette variable est gérée par ClusterControl et est définie en fonction des modifications de topologie demandées par l'utilisateur ou de ClusterControl effectuées automatiquement.