La réplication maître-esclave MySQL est assez facile et simple à configurer. C'est la principale raison pour laquelle les gens choisissent cette technologie comme première étape pour obtenir une meilleure disponibilité de la base de données. Cependant, cela se fait au prix d'une complexité de gestion et de maintenance; il appartient à l'administrateur de maintenir l'intégrité des données, en particulier lors du basculement, du rétablissement, de la maintenance, de la mise à niveau, etc.
Il existe de nombreux articles décrivant comment effectuer une opération de basculement pour la configuration de la réplication. Nous avons également abordé ce sujet dans cet article de blog, Introduction au basculement pour la réplication MySQL - le blog 101. Dans cet article de blog, nous allons couvrir les tâches post-catastrophe lors de la restauration de la topologie d'origine - en effectuant une opération de restauration.
Pourquoi avons-nous besoin d'une restauration ?
Le leader de la réplication (maître) est le nœud le plus critique dans une configuration de réplication. Il nécessite de bonnes spécifications matérielles pour s'assurer qu'il peut traiter les écritures, générer des événements de réplication, traiter les lectures critiques, etc. de manière stable. Lorsqu'un basculement est requis pendant la reprise après sinistre ou la maintenance, il n'est pas rare de nous trouver en train de promouvoir un nouveau leader avec un matériel de qualité inférieure. Cette situation peut être acceptable temporairement, mais à long terme, le maître désigné doit être ramené pour diriger la réplication une fois qu'il est jugé sain.
Contrairement au basculement, l'opération de restauration automatique se produit généralement dans un environnement contrôlé par basculement, elle se produit rarement en mode panique. Cela donne à l'équipe d'exploitation le temps de planifier soigneusement et de répéter l'exercice pour une transition en douceur. L'objectif principal est simplement de ramener le bon vieux maître à son état le plus récent et de restaurer la configuration de réplication dans sa topologie d'origine. Cependant, il existe certains cas où la restauration est critique, par exemple lorsque le maître nouvellement promu n'a pas fonctionné comme prévu et a affecté le service de base de données global.
Comment effectuer un rétablissement en toute sécurité ?
Une fois le basculement effectué, l'ancien maître serait hors de la chaîne de réplication pour la maintenance ou la récupération. Pour effectuer le basculement, il faut procéder comme suit :
- Mettre à disposition l'ancien maître dans l'état correct, en en faisant l'esclave le plus à jour.
- Arrêtez l'application.
- Vérifiez que tous les esclaves sont rattrapés.
- Promouvoir l'ancien maître en tant que nouveau leader.
- Repointez tous les esclaves vers le nouveau maître.
- Démarrez l'application en écrivant au nouveau maître.
Considérez la configuration de réplication suivante :
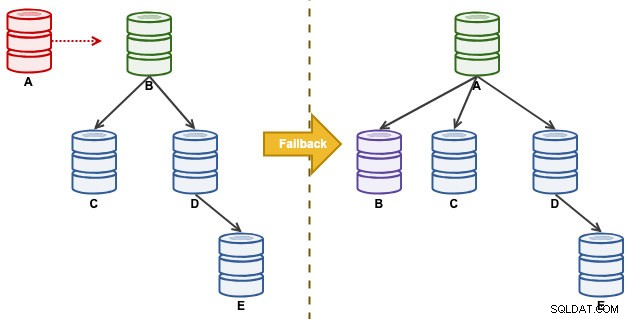
"A" était un maître jusqu'à ce qu'un événement de disque plein cause des ravages dans la chaîne de réplication. Après un événement de basculement, notre topologie de réplication était dirigée par B et se réplique sur C jusqu'à E. L'exercice de restauration ramènera A en tant que leader et restaurera la topologie d'origine avant le sinistre. Notez que tous les nœuds s'exécutent sur MySQL 8.0.15 avec GTID activé. Différentes versions majeures peuvent utiliser différentes commandes et étapes.
Bien que voici à quoi ressemble notre architecture maintenant après le basculement (tiré de la vue Topologie de ClusterControl) :
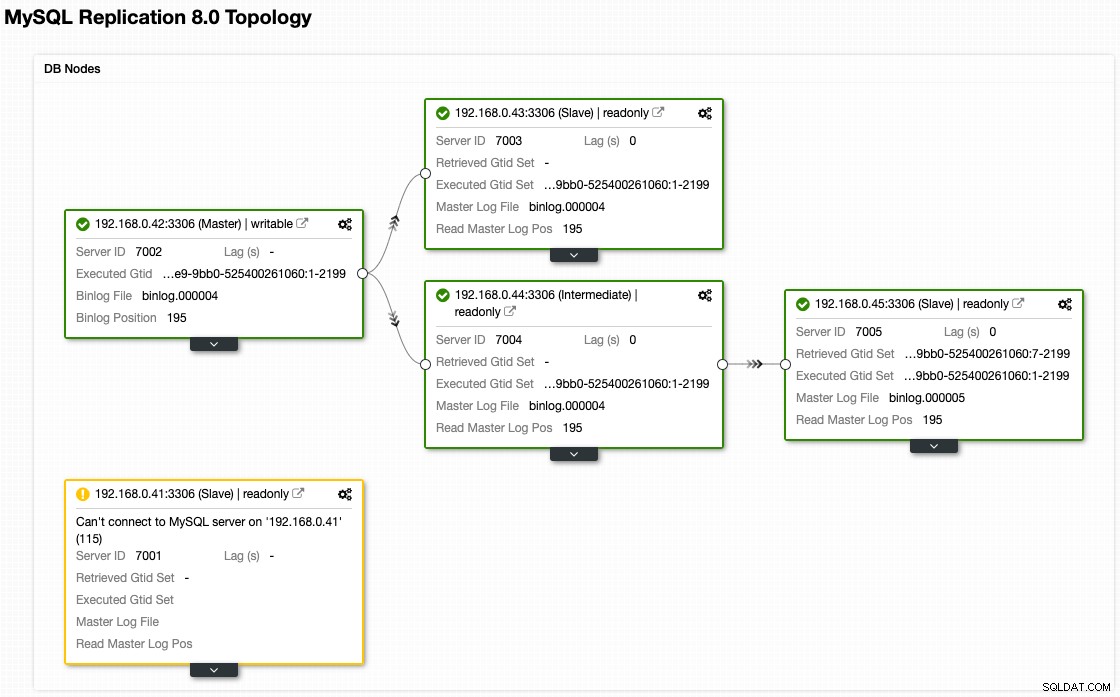
Provisionnement de nœud
Avant que A puisse être un maître, il doit être mis à jour avec l'état actuel de la base de données. La meilleure façon de le faire est de transformer A en esclave du maître actif, B. Puisque tous les nœuds sont configurés avec log_slave_updates=ON (cela signifie qu'un esclave produit également des journaux binaires), nous pouvons en fait choisir d'autres esclaves comme C et D comme la source de vérité pour la synchronisation initiale. Cependant, plus le maître actif est proche, mieux c'est. Gardez à l'esprit la charge supplémentaire que cela pourrait entraîner lors de la sauvegarde. Cette partie prend la plupart des heures de rétablissement. En fonction de l'état du nœud et de la taille de l'ensemble de données, la synchronisation de l'ancien maître peut prendre un certain temps (il peut s'agir d'heures et de jours).
Une fois que le problème sur "A" est résolu et prêt à rejoindre la chaîne de réplication, la meilleure première étape consiste à tenter de répliquer à partir de "B" (192.168.0.42) avec l'instruction CHANGE MASTER :
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Si la réplication fonctionne, vous devriez voir ce qui suit dans l'état de la réplication :
Slave_IO_Running: Yes
Slave_SQL_Running: YesSi la réplication échoue, examinez Last_IO_Error ou Last_SQL_Error à partir de la sortie de l'état de l'esclave. Par exemple, si vous voyez l'erreur suivante :
Last_IO_Error: error connecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 2Ensuite, nous devons créer l'utilisateur de réplication sur le maître actif actuel, B :
mysql> CREATE USER example@sqldat.com IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com;Redémarrez ensuite l'esclave sur A pour relancer la réplication :
mysql> STOP SLAVE;
mysql> START SLAVE;Une autre erreur courante que vous verriez est cette ligne :
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...Cela signifie probablement que l'esclave a des problèmes pour lire le fichier journal binaire du maître actuel. Dans certains cas, l'esclave peut être très en retard, les événements binaires requis pour démarrer la réplication étant absents du maître actuel, ou le binaire sur le maître a été purgé pendant le basculement, etc. Dans ce cas, le meilleur moyen est d'effectuer une synchronisation complète en effectuant une sauvegarde complète sur B et en la restaurant sur A. Sur B, vous pouvez utiliser mysqldump ou Percona Xtrabackup pour effectuer une sauvegarde complète :
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupTransférez le fichier de sauvegarde vers A, réinitialisez l'installation MySQL existante pour un nettoyage correct et effectuez une restauration de la base de données :
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER example@sqldat.com IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root passwordUne fois restauré, configurez le lien de réplication vers le maître actif B (192.168.0.42) et activez la lecture seule. Sur A, exécutez les instructions suivantes :
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Pour Percona Xtrabackup, veuillez vous référer à la page de documentation sur la façon de restaurer vers A. Cela implique une étape préalable pour préparer la sauvegarde avant de remplacer le répertoire de données MySQL.
Une fois que A a commencé à se répliquer correctement, surveillez le Seconds_Behind_Master dans le statut d'esclave. Cela vous donnera une idée de la distance parcourue par l'esclave et du temps qu'il vous faudra attendre avant qu'il ne vous rattrape. À ce stade, notre architecture ressemble à ceci :
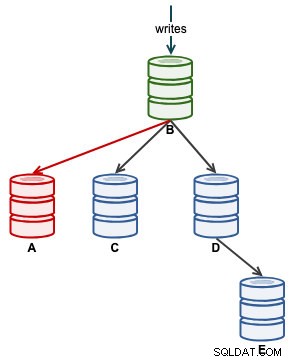
Une fois que Seconds_Behind_Master retombe à 0, c'est le moment où A est devenu un esclave à jour.
Si vous utilisez ClusterControl, vous avez la possibilité de resynchroniser le nœud en restaurant à partir d'une sauvegarde existante ou de créer et diffuser la sauvegarde directement à partir du nœud maître actif :
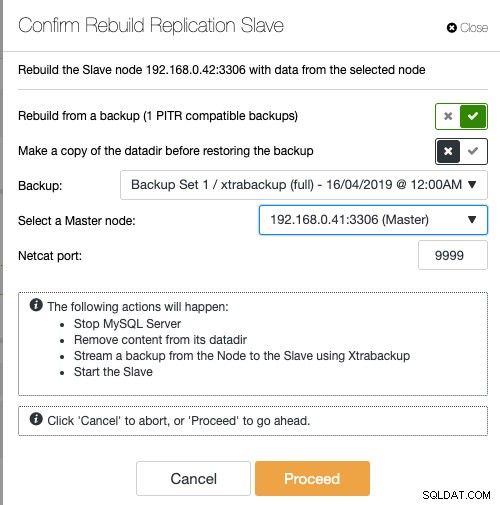
La mise en scène de l'esclave avec une sauvegarde existante est la méthode recommandée pour construire l'esclave, car cela n'a aucun impact sur le serveur maître actif lors de la préparation du nœud.
Promouvoir le Vieux Maître
Avant de promouvoir A en tant que nouveau maître, le moyen le plus sûr est d'arrêter toutes les opérations d'écriture sur B. Si cela n'est pas possible, forcez simplement B à fonctionner en mode lecture seule :
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';Ensuite, sur A, exécutez SHOW SLAVE STATUS et vérifiez l'état de réplication suivant :
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesLa valeur de Read_Master_Log_Pos et Exec_Master_Log_Pos doit être identique, tandis que Seconds_Behind_Master est 0 et l'état doit être 'L'esclave a lu tous les journaux de relais'. Assurez-vous que tous les esclaves ont traité toutes les déclarations dans leur journal de relais, sinon vous risquez que les nouvelles requêtes affectent les transactions du journal de relais, déclenchant toutes sortes de problèmes (par exemple, une application peut supprimer certaines lignes auxquelles accèdent les transactions du journal de relais).
Sur A, arrêtez la réplication et utilisez l'instruction RESET SLAVE ALL pour supprimer toute la configuration liée à la réplication et désactiver la lecture seule :
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';À ce stade, A est prêt à accepter des écritures (read_only=OFF), mais aucun esclave ne lui est connecté, comme illustré ci-dessous :
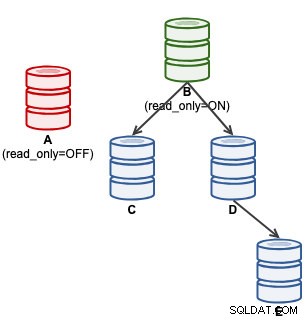
Pour les utilisateurs de ClusterControl, la promotion de A peut être effectuée à l'aide de la fonction "Promouvoir l'esclave" sous Actions de nœud. ClusterControl rétrogradera automatiquement le maître actif B, promouvra l'esclave A en tant que maître et redirigera C et D pour répliquer à partir de A. B sera mis de côté et l'utilisateur devra choisir explicitement "Changer le maître de réplication" pour rejoindre B répliquant à partir de A à un stade ultérieur .
Repointage d'esclaves
Il est désormais possible de modifier en toute sécurité le maître sur les esclaves associés pour répliquer à partir de A (192.168.0.41). Sur tous les esclaves sauf E, configurez les éléments suivants :
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Si vous êtes un utilisateur de ClusterControl, vous pouvez ignorer cette étape car le repointage est effectué automatiquement lorsque vous avez décidé de promouvoir A précédemment.
Nous pouvons alors démarrer notre application pour écrire sur A. À ce stade, notre architecture ressemble à ceci :
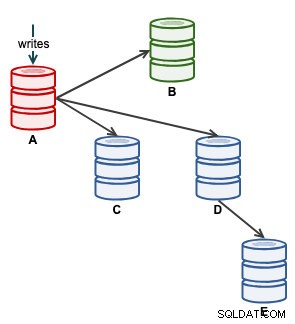
À partir de la vue topologique de ClusterControl, nous avons restauré notre cluster de réplication à son architecture d'origine qui ressemble à ceci :
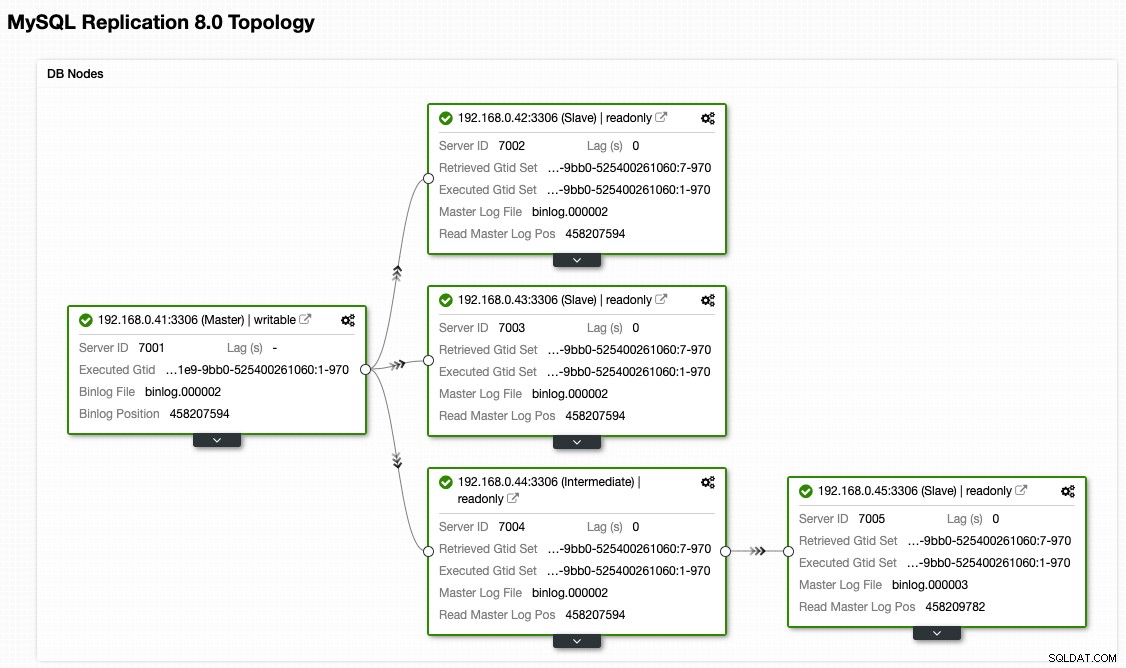
Notez que l'exercice de rétablissement est beaucoup moins risqué par rapport au basculement. Il est important de programmer cet exercice pendant les heures creuses afin de minimiser l'impact sur votre entreprise.
Réflexions finales
Les opérations de basculement et de restauration doivent être effectuées avec soin. L'opération est assez simple si vous avez un petit nombre de nœuds, mais pour plusieurs nœuds avec une chaîne de réplication complexe, cela pourrait être un exercice risqué et sujet aux erreurs. Nous avons également montré comment ClusterControl peut être utilisé pour simplifier des opérations complexes en les exécutant via l'interface utilisateur, et la vue de la topologie est visualisée en temps réel afin que vous compreniez la topologie de réplication que vous souhaitez créer.