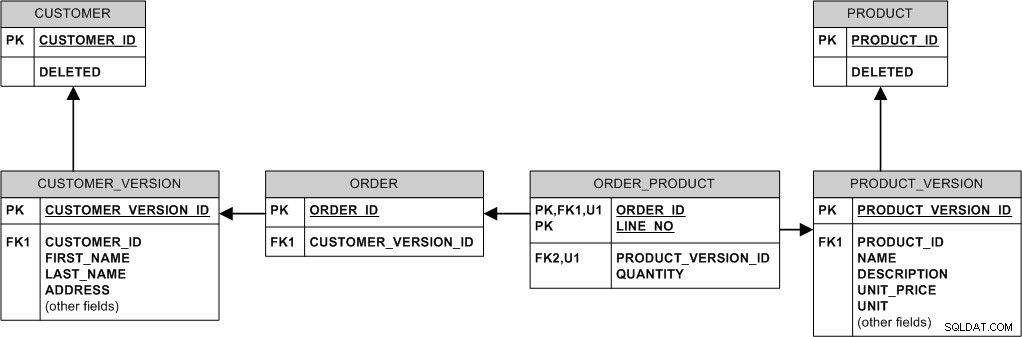
Voici une façon de procéder :
Essentiellement, nous ne modifions ni ne supprimons jamais les données existantes. Nous le "modifions" en créant une nouvelle version. Nous le "supprimons" en définissant le drapeau DELETED.
Par exemple :
- Si le prix du produit change, nous insérons une nouvelle ligne dans PRODUCT_VERSION tandis que les anciennes commandes restent connectées à l'ancien PRODUCT_VERSION et à l'ancien prix.
- Lorsque l'acheteur modifie l'adresse, nous insérons simplement une nouvelle ligne dans CUSTOMER_VERSION et lions les nouvelles commandes à celle-ci, tout en conservant les anciennes commandes liées à l'ancienne version.
- Si un produit est supprimé, nous ne le supprimons pas vraiment :nous définissons simplement l'indicateur PRODUCT.DELETED, de sorte que toutes les commandes passées pour ce produit dans l'historique restent dans la base de données.
- Si le client est supprimé (par exemple parce qu'il a demandé à être désinscrit), définissez l'indicateur CUSTOMER.DELETED.
Mises en garde :
- Si le nom du produit doit être unique, cela ne peut pas être appliqué de manière déclarative dans le modèle ci-dessus. Vous devrez soit "promouvoir" le NAME de PRODUCT_VERSION à PRODUCT, en faire une clé et renoncer à la possibilité de "faire évoluer" le nom du produit, soit imposer l'unicité uniquement sur le dernier PRODUCT_VER (probablement via des déclencheurs).
- Il existe un problème potentiel avec la confidentialité du client. Si un client est supprimé du système, il peut être souhaitable de supprimer physiquement ses données de la base de données et le simple fait de définir CUSTOMER.DELETED ne le fera pas. Si c'est un problème, effacez les données sensibles à la confidentialité dans toutes les versions du client, ou bien déconnectez les commandes existantes du vrai client et reconnectez-les à un client "anonyme" spécial, puis supprimez physiquement toutes les versions du client.
Ce modèle utilise beaucoup de relations d'identification. Cela conduit à des clés étrangères "grosses" et pourrait être un peu un problème de stockage puisque MySQL ne prend pas en charge la compression d'index de pointe (contrairement, disons, à Oracle), mais d'un autre côté InnoDB toujours regroupe les données sur PK et ce regroupement peut être bénéfique pour les performances. De plus, les JOIN sont moins nécessaires.
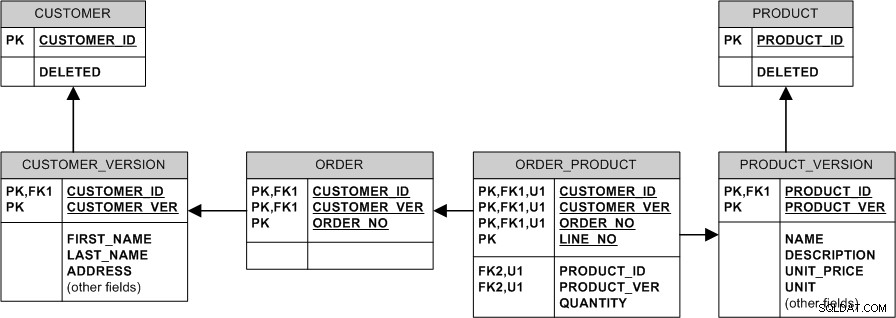
Un modèle équivalent avec des relations non identifiantes et des clés de substitution ressemblerait à ceci :