Amazon a lancé S3 au début de 2006 et le premier outil permettant aux scripts de sauvegarde PostgreSQL de télécharger des données dans le cloud — s3cmd — est né un peu moins d'un an plus tard. En 2010 (d'après mes compétences de recherche sur Google), Open BI blogs à ce sujet. Il est donc prudent de dire que certains des DBA PostgreSQL sauvegardent des données sur AWS S3 depuis 9 ans. Mais comment? Et qu'est-ce qui a changé pendant ce temps ? Bien que s3cmd soit toujours référencé par certains dans le contexte des outils de sauvegarde PostgreSQL connus, les méthodes ont subi des modifications permettant une meilleure intégration avec le système de fichiers ou les options de sauvegarde native PostgreSQL afin d'atteindre les objectifs de récupération RTO et RPO souhaités.
Pourquoi Amazon S3
Comme souligné tout au long de la documentation Amazon S3 (la FAQ S3 étant un très bon point de départ), les avantages de l'utilisation du service S3 sont :
- Durabilité de 99,999999999 (onze neuf)
- stockage de données illimité
- faibles coûts (encore plus bas lorsqu'ils sont combinés avec BitTorrent)
- trafic réseau entrant gratuit
- Seul le trafic réseau sortant est facturable
Aucuns pièges de la CLI AWS S3
La boîte à outils AWS S3 CLI fournit tous les outils nécessaires pour transférer des données vers et depuis le stockage S3, alors pourquoi ne pas utiliser ces outils ? La réponse réside dans les détails de mise en œuvre d'Amazon S3 qui incluent des mesures pour gérer les limitations et les contraintes liées au stockage d'objets :
- Taille maximale de 5 To par objet stocké
- Taille maximale d'un objet PUT de 5 Go
- téléchargement en plusieurs parties recommandé pour les objets de plus de 100 Mo
- choisir une classe de stockage appropriée conformément au diagramme de performances S3
- profiter du cycle de vie S3
- Modèle de cohérence des données S3
À titre d'exemple, reportez-vous à la page d'aide aws s3 cp :
--expected-size (string) Cet argument spécifie la taille attendue d'un flux en termes d'octets. Notez que cet argument n'est nécessaire que lorsqu'un flux est téléchargé sur s3 et que la taille est supérieure à 5 Go. Si vous n'incluez pas cet argument dans ces conditions, l'importation risque d'échouer en raison d'un trop grand nombre de parties dans l'importation.
Éviter ces pièges nécessite une connaissance approfondie de l'écosystème S3, ce que les outils de sauvegarde PostgreSQL et S3 spécialement conçus tentent d'atteindre.
Outils de sauvegarde natifs PostgreSQL avec prise en charge d'Amazon S3
L'intégration S3 est fournie par certains des outils de sauvegarde bien connus, implémentant les fonctionnalités de sauvegarde natives de PostgreSQL.
BarmanS3
BarmanS3 est implémenté en tant que Barman Hook Scripts. Il s'appuie sur l'AWS CLI, sans tenir compte des recommandations et des limitations répertoriées ci-dessus. La configuration simple en fait un bon candidat pour les petites installations. Le développement est quelque peu au point mort, dernière mise à jour il y a environ un an, faisant de ce produit un choix pour ceux qui utilisent déjà Barman dans leurs environnements.
Dumps S3
S3dumps est un projet actif, implémenté à l'aide de la bibliothèque Python Boto3 d'Amazon. L'installation s'effectue facilement via pip. Bien que s'appuyant sur le SDK Python d'Amazon S3, une recherche dans le code source des mots-clés regex tels que multi.*part ou storage.*class ne révèle aucune des fonctionnalités S3 avancées, telles que les transferts multipart.
pgBackRest
pgBackRest implémente S3 en tant qu'option de référentiel. Il s'agit de l'un des outils de sauvegarde PostgreSQL bien connus, offrant un ensemble riche en fonctionnalités d'options de sauvegarde telles que la sauvegarde et la restauration parallèles, le chiffrement et la prise en charge des espaces de table. Il s'agit principalement de code C, qui fournit la vitesse et le débit que nous recherchons, cependant, lorsqu'il s'agit d'interagir avec l'API AWS S3, cela se fait au prix du travail supplémentaire requis pour la mise en œuvre des fonctionnalités de stockage S3. La version récente implémente le téléchargement en plusieurs parties S3.
WAL-G
WAL-G annoncé il y a 2 ans est activement maintenu. Cet outil de sauvegarde PostgreSQL à toute épreuve implémente des classes de stockage, mais pas de téléchargement en plusieurs parties (la recherche du code pour CreateMultipartUpload n'a trouvé aucune occurrence).
PGHoard
pghoard est sorti il y a environ 3 ans. Il s'agit d'un outil de sauvegarde PostgreSQL performant et riche en fonctionnalités prenant en charge les transferts en plusieurs parties S3. Il n'offre aucune des autres fonctionnalités S3 telles que la classe de stockage et la gestion du cycle de vie des objets.
S3 en tant que système de fichiers local
Pouvoir accéder au stockage S3 en tant que système de fichiers local est une fonctionnalité très souhaitée car elle ouvre la possibilité d'utiliser les outils de sauvegarde natifs PostgreSQL.
Pour les environnements Linux, Amazon propose deux options :NFS et iSCSI. Ils tirent parti d'AWS Storage Gateway.
NFS
Un partage NFS monté localement est fourni par le service AWS Storage Gateway File. Selon le lien, nous devons créer une passerelle de fichiers.
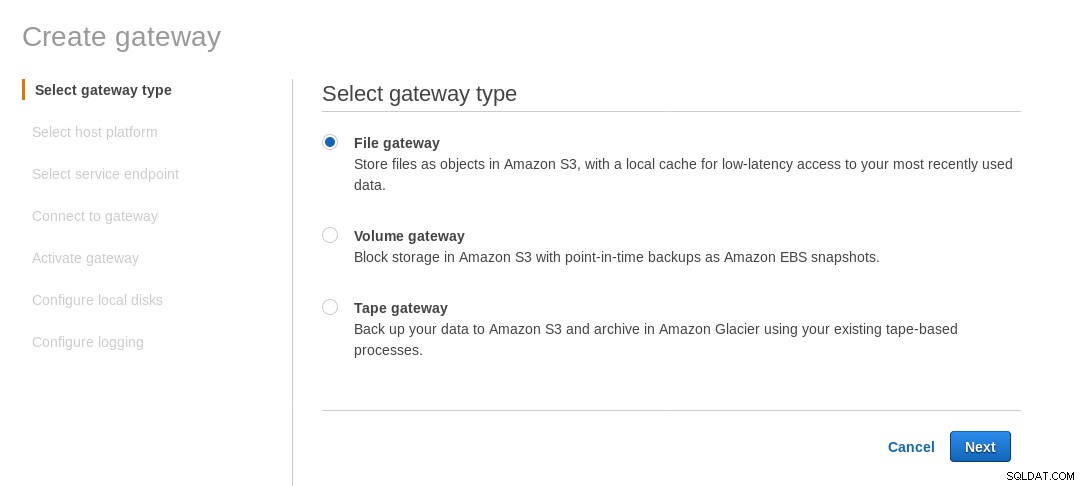
Sur l'écran Sélectionner la plateforme hôte, sélectionnez Amazon EC2 et cliquez sur le bouton Lancer l'instance pour lancer l'assistant EC2 de création de l'instance.
Maintenant, juste par curiosité de cet administrateur système, examinons l'AMI utilisée par l'assistant car elle nous donne une perspective intéressante sur certaines des pièces internes d'AWS. Avec l'ID d'image connu ami-0bab9d6dffb52fef5, regardons les détails :
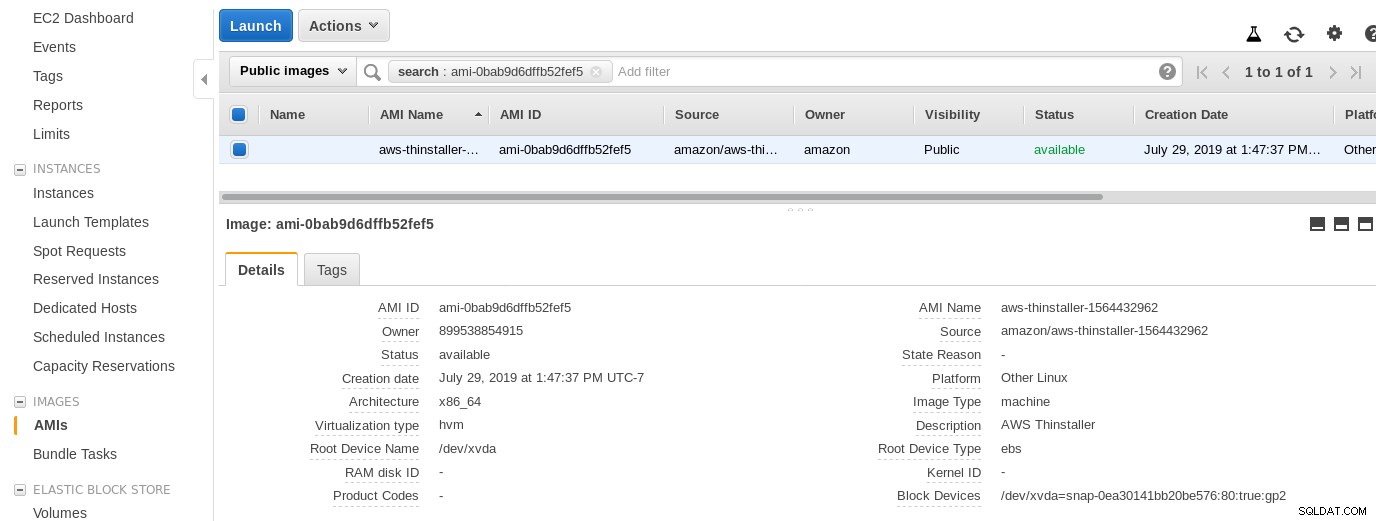
Comme indiqué ci-dessus, le nom de l'AMI est aws-thinstaller. un « installateur » ? Les recherches sur Internet révèlent que Thinstaller est un outil de gestion de configuration logicielle IBM Lenovo pour les produits Microsoft et est référencé en premier dans ce blog de 2008, et plus tard dans ce message du forum Lenovo et cette demande de service du district scolaire. Je n'avais aucun moyen de le savoir, car mon travail d'administrateur système Windows s'est terminé 3 ans plus tôt. Cette AMI a donc été construite avec le produit Thinstaller. Pour rendre les choses encore plus confuses, le système d'exploitation AMI est répertorié comme "Autre Linux", ce qui peut être confirmé par SSH-ing dans le système en tant qu'administrateur.
Un assistant a eu un problème :malgré les instructions de configuration du pare-feu EC2, mon navigateur a expiré lors de la connexion à la passerelle de stockage. L'autorisation du port 80 est documentée dans Port Requirements - nous pourrions dire que l'assistant doit soit répertorier tous les ports requis, soit créer un lien vers la documentation, mais dans l'esprit du cloud, la réponse est "automatiser" avec des outils tels que CloudFormation.
L'assistant suggère également de commencer avec une instance de taille xlarge.
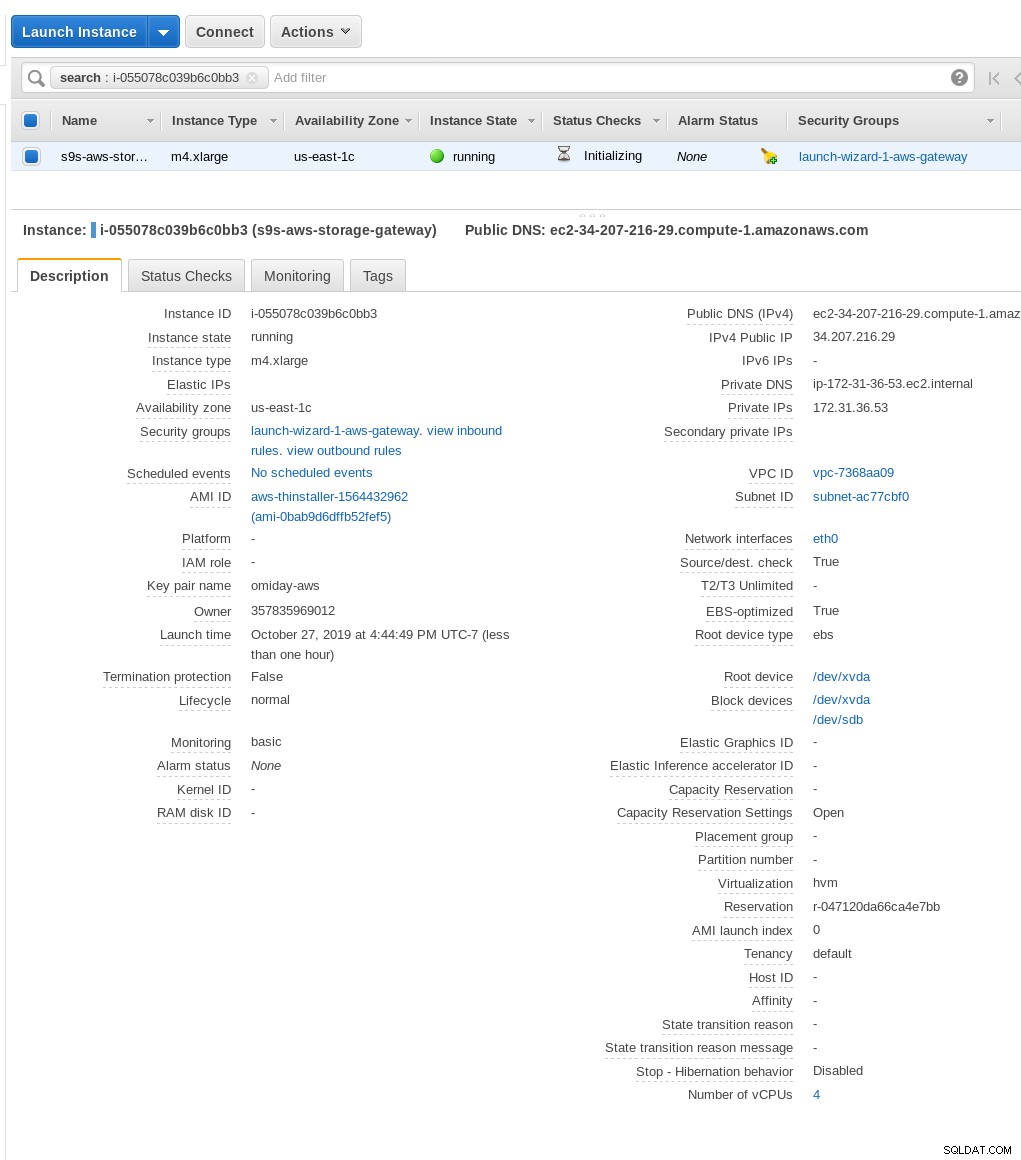
Une fois la passerelle de stockage prête, configurez le partage NFS en cliquant sur le bouton Créer bouton de partage de fichiers dans le menu Passerelle :
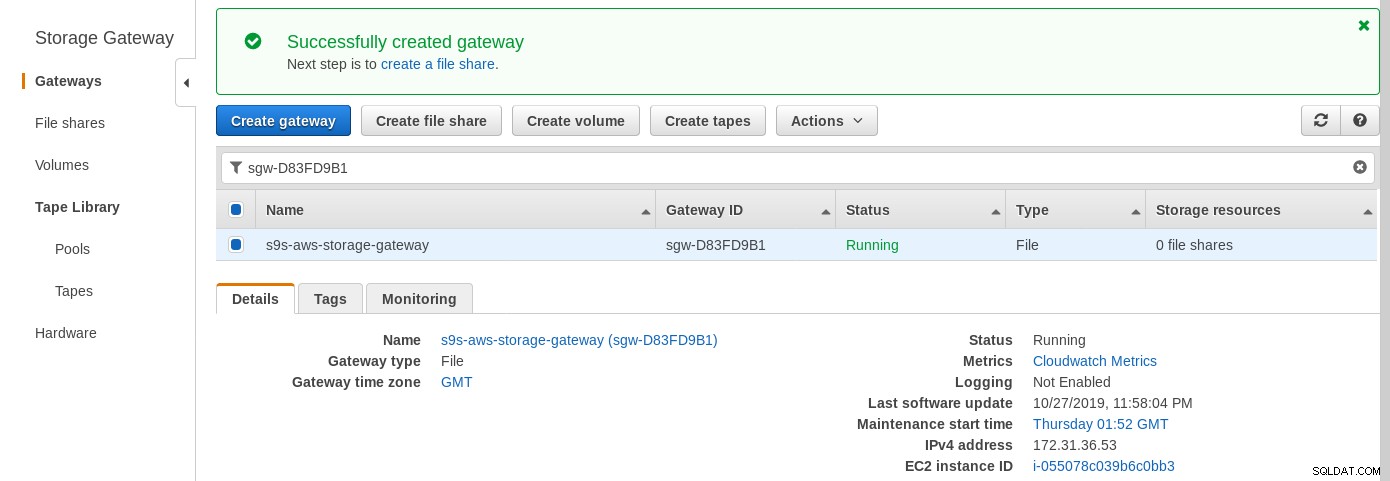
Une fois le partage NFS prêt, suivez les instructions pour monter le système de fichiers :
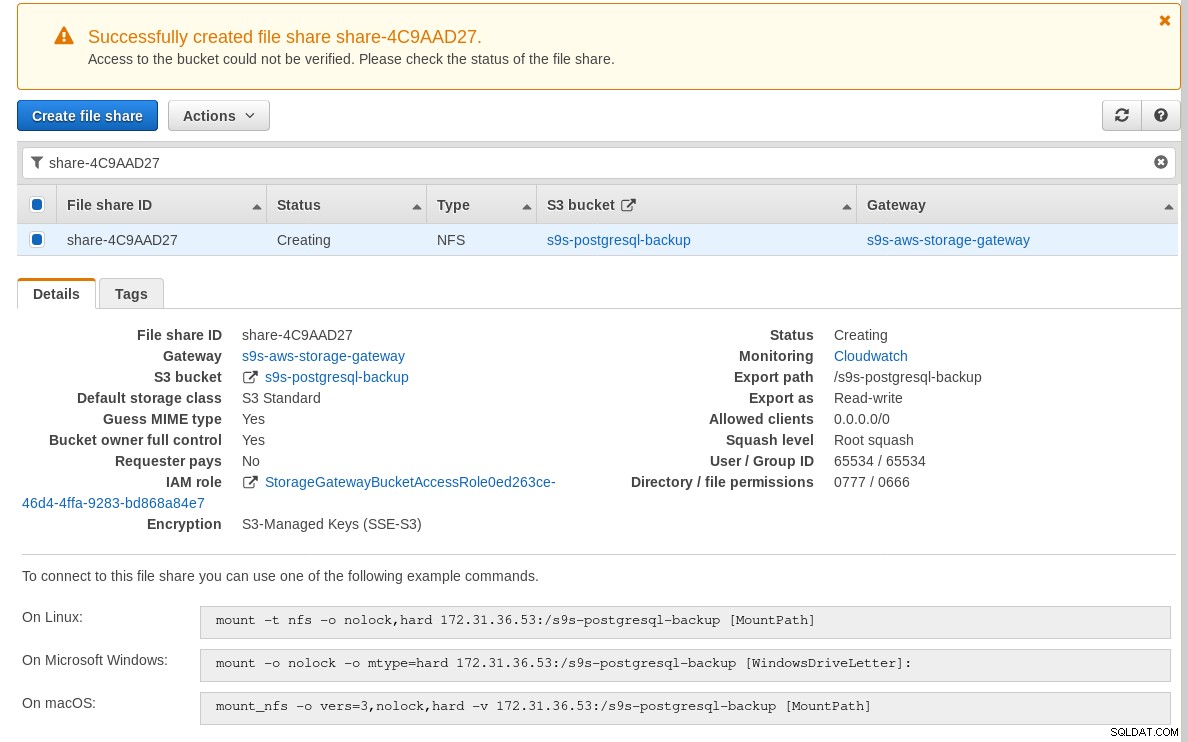
Dans la capture d'écran ci-dessus, notez que la commande mount fait référence à l'adresse IP privée de l'instance adresse. Pour monter à partir d'un hôte public, utilisez simplement l'adresse publique de l'instance comme indiqué dans les détails de l'instance EC2 ci-dessus.
L'assistant ne bloquera pas si le compartiment S3 n'existe pas au moment de la création du partage de fichiers, cependant, une fois le compartiment S3 créé, nous devons redémarrer l'instance, sinon, la commande mount échoue avec :
[example@sqldat.com ~]# mount -t nfs -o nolock,hard 34.207.216.29:/s9s-postgresql-backup /mnt
mount.nfs: mounting 34.207.216.29:/s9s-postgresql-backup failed, reason given by server: No such file or directoryVérifiez que le partage est disponible :
[example@sqldat.com ~]# df -h /mnt
Filesystem Size Used Avail Use% Mounted on
34.207.216.29:/s9s-postgresql-backup 8.0E 0 8.0E 0% /mntEffectuons maintenant un test rapide :
example@sqldat.com[local]:54311 postgres# \l+ test
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
test | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 2763 MB | pg_default |
(1 row)
[example@sqldat.com ~]# date ; time pg_dump -d test | gzip -c >/mnt/test.pg_dump.gz ; date
Sun 27 Oct 2019 06:06:24 PM PDT
real 0m29.807s
user 0m15.909s
sys 0m2.040s
Sun 27 Oct 2019 06:06:54 PM PDTNotez que l'horodatage de la dernière modification sur le compartiment S3 est d'environ une minute plus tard, ce qui, comme mentionné précédemment, dépend du modèle de cohérence des données Amazon S3.
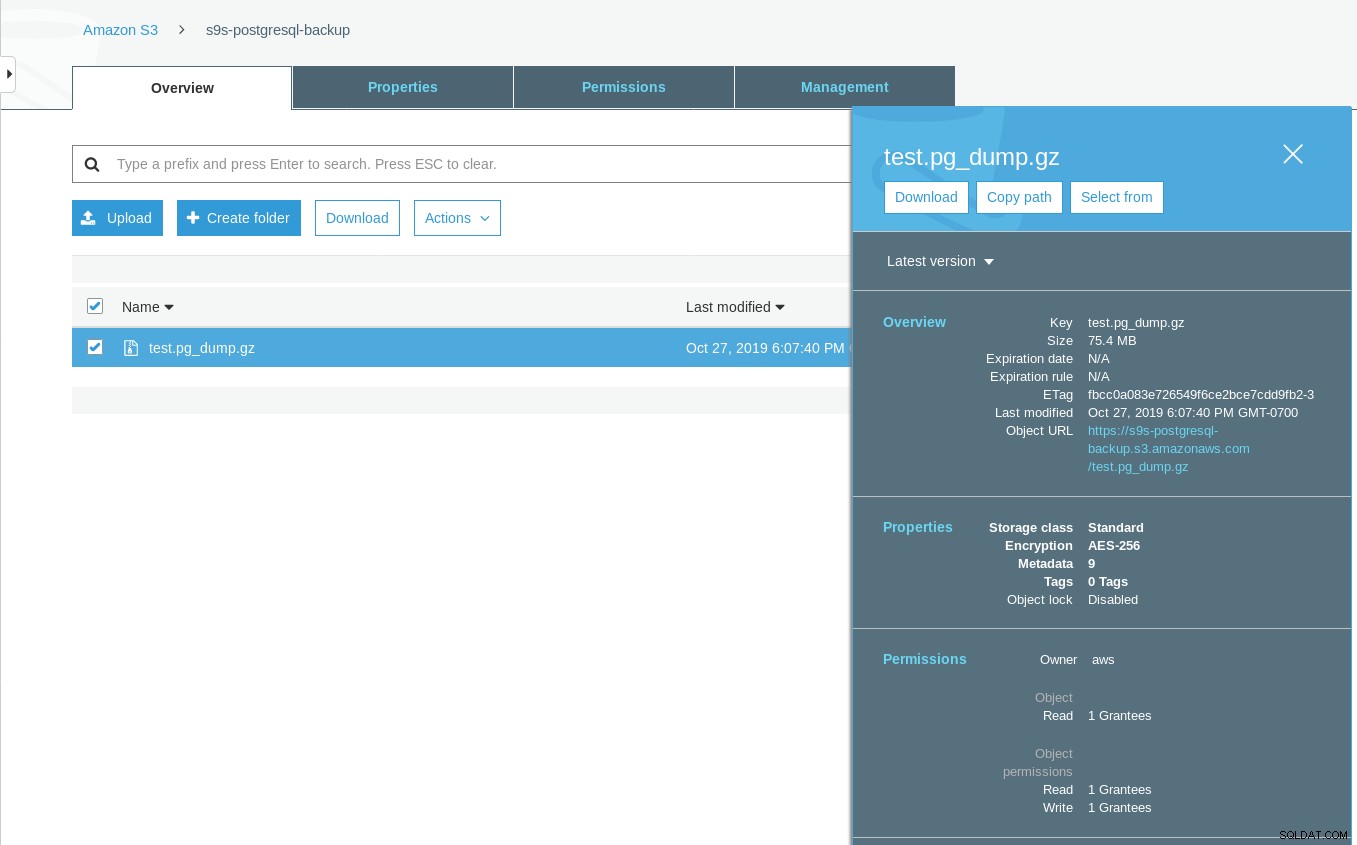
Voici un test plus exhaustif :
~ $ for q in {0..20} ; do touch /mnt/touched-at-$(date +%Y%m%d%H%M%S) ;
sleep 1 ; done
~ $ aws s3 ls s3://s9s-postgresql-backup | nl
1 2019-10-27 19:50:40 0 touched-at-20191027194957
2 2019-10-27 19:50:40 0 touched-at-20191027194958
3 2019-10-27 19:50:40 0 touched-at-20191027195000
4 2019-10-27 19:50:40 0 touched-at-20191027195001
5 2019-10-27 19:50:40 0 touched-at-20191027195002
6 2019-10-27 19:50:40 0 touched-at-20191027195004
7 2019-10-27 19:50:40 0 touched-at-20191027195005
8 2019-10-27 19:50:40 0 touched-at-20191027195007
9 2019-10-27 19:50:40 0 touched-at-20191027195008
10 2019-10-27 19:51:10 0 touched-at-20191027195009
11 2019-10-27 19:51:10 0 touched-at-20191027195011
12 2019-10-27 19:51:10 0 touched-at-20191027195012
13 2019-10-27 19:51:10 0 touched-at-20191027195013
14 2019-10-27 19:51:10 0 touched-at-20191027195014
15 2019-10-27 19:51:10 0 touched-at-20191027195016
16 2019-10-27 19:51:10 0 touched-at-20191027195017
17 2019-10-27 19:51:10 0 touched-at-20191027195018
18 2019-10-27 19:51:10 0 touched-at-20191027195020
19 2019-10-27 19:51:10 0 touched-at-20191027195021
20 2019-10-27 19:51:10 0 touched-at-20191027195022
21 2019-10-27 19:51:10 0 touched-at-20191027195024Un autre problème mérite d'être mentionné :après avoir joué avec diverses configurations, créé et détruit des passerelles et des partages, à un moment donné lors de la tentative d'activation d'une passerelle de fichiers, j'ai reçu une erreur interne :
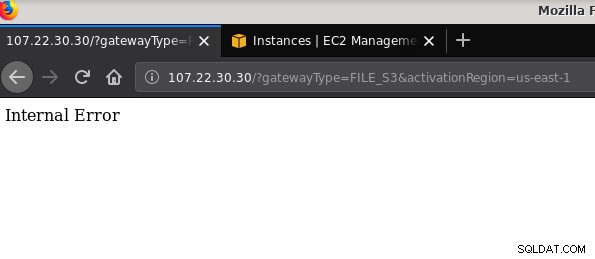
La ligne de commande donne plus de détails, bien qu'elle ne signale aucun problème :
~$ curl -sv "https://107.22.30.30/?gatewayType=FILE_S3&activationRegion=us-east-1"
* Trying 107.22.30.30:80...
* TCP_NODELAY set
* Connected to 107.22.30.30 (107.22.30.30) port 80 (#0)
> GET /?gatewayType=FILE_S3&activationRegion=us-east-1 HTTP/1.1
> Host: 107.22.30.30
> User-Agent: curl/7.65.3
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 500 Internal Server Error
< Date: Mon, 28 Oct 2019 06:33:30 GMT
< Content-type: text/html
< Content-length: 14
<
* Connection #0 to host 107.22.30.30 left intact
Internal Error~ $Ce message du forum a souligné que mon problème pouvait avoir quelque chose à voir avec le point de terminaison VPC que j'avais créé. Mon correctif supprimait le point de terminaison VPC que j'avais configuré lors de diverses exécutions d'essais et d'erreurs iSCSI.
Alors que S3 chiffre les données au repos, le trafic filaire NFS est en texte brut. À savoir, voici un vidage de paquet tcpdump :
23:47:12.225273 IP 192.168.0.11.936 > 107.22.30.30.2049: Flags [P.], seq 2665:3377, ack 2929, win 501, options [nop,nop,TS val 1899459538 ecr 38013066], length 712: NFS request xid 3511704119 708 getattr fh 0,2/53
example@sqldat.com@.......k....... ...c..............
q7s..D.......PZ7...........................4........omiday.can.local...................................................5.......]...........!....................C...
..............&...........]....................# inittab is no longer used.
#
# ADDING CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.
#
# Ctrl-Alt-Delete is handled by /usr/lib/systemd/system/ctrl-alt-del.target
#
# systemd uses 'targets' instead of runlevels. By default, there are two main targets:
#
# multi-user.target: analogous to runlevel 3
# graphical.target: analogous to runlevel 5
#
# To view current default target, run:
# systemctl get-default
#
# To set a default target, run:
# systemctl set-default TARGET.target
..... .........0..
23:47:12.331592 IP 107.22.30.30.2049 > 192.168.0.11.936: Flags [P.], seq 2929:3109, ack 3377, win 514, options [nop,nop,TS val 38013174 ecr 1899459538], length 180: NFS reply xid 3511704119 reply ok 176 getattr NON 4 ids 0/33554432 sz -2138196387Jusqu'à ce que ce brouillon IEE soit approuvé, la seule option sécurisée pour se connecter depuis l'extérieur d'AWS consiste à utiliser un tunnel VPN. Cela complique la configuration, rendant l'option NFS sur site moins attrayante que les outils basés sur FUSE dont je parlerai un peu plus tard.
iSCSI
Cette option est fournie par le service AWS Storage Gateway Volume. Une fois le service configuré, dirigez-vous vers la section de configuration du client Linux iSCSI.
L'avantage d'utiliser iSCSI sur NFS consiste en la possibilité de tirer parti des services de sauvegarde, de clonage et d'instantané natifs du cloud d'Amazon. Pour plus de détails et des instructions étape par étape, suivez les liens vers AWS Backup, Volume Cloning et EBS Snapshots
Bien qu'il y ait de nombreux avantages, il existe une restriction importante qui va probablement décourager de nombreux utilisateurs :il n'est pas possible d'accéder à la passerelle via son adresse IP publique. Ainsi, tout comme l'option NFS, cette exigence ajoute de la complexité à la configuration.
Malgré la limitation claire et convaincu que je ne pourrai pas terminer cette configuration, je voulais quand même avoir une idée de la façon dont c'est fait. L'assistant redirige vers un écran de configuration AWS Marketplace.
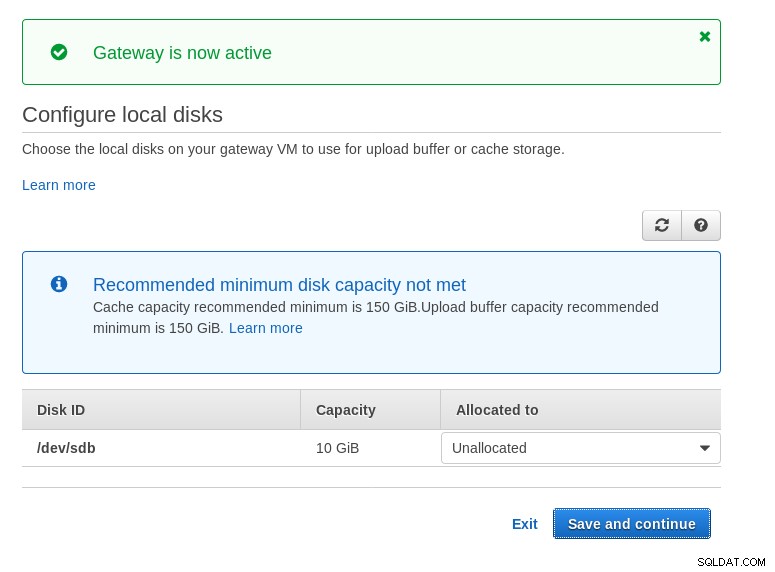
Notez que l'assistant Marketplace crée un disque secondaire, mais pas assez grand dans taille, et nous devons donc encore ajouter les deux volumes requis comme indiqué par les instructions de configuration de l'hôte. Si les exigences de stockage ne sont pas remplies, l'assistant se bloquera sur l'écran de configuration des disques locaux :
Voici un aperçu de l'écran de configuration d'Amazon Marketplace :
Il existe une interface texte accessible via SSH (connectez-vous en tant qu'utilisateur sguser) qui fournit des outils de dépannage réseau de base et d'autres options de configuration qui ne peuvent pas être effectuées via l'interface graphique Web :
~ $ ssh example@sqldat.com
Warning: Permanently added 'ec2-3-231-96-109.compute-1.amazonaws.com,3.231.96.109' (ECDSA) to the list of known hosts.
'screen.xterm-256color': unknown terminal type.
AWS Storage Gateway Configuration
#######################################################################
## Currently connected network adapters:
##
## eth0: 172.31.1.185
#######################################################################
1: SOCKS Proxy Configuration
2: Test Network Connectivity
3: Gateway Console
4: View System Resource Check (0 Errors)
0: Stop AWS Storage Gateway
Press "x" to exit session
Enter command:Et quelques autres points importants :
- Contrairement à la configuration NFS, il n'y a pas d'accès direct au stockage S3, comme indiqué dans la section FAQ de la passerelle de volume.
- La documentation AWS insiste sur la personnalisation des paramètres iSCSI afin d'améliorer les performances et la sécurité de la connexion.
FUSIBLE
Dans cette catégorie, j'ai répertorié les outils basés sur FUSE qui offrent une compatibilité S3 plus complète par rapport aux outils de sauvegarde PostgreSQL, et contrairement à Amazon Storage Gateway, permettent les transferts de données depuis un hôte sur site à Amazon S3 sans configuration supplémentaire. Une telle configuration pourrait fournir le stockage S3 en tant que système de fichiers local que les outils de sauvegarde PostgreSQL peuvent utiliser afin de tirer parti de fonctionnalités telles que pg_dump parallèle.
fusible s3fs
s3fs-fuse est écrit en C++, un langage pris en charge par la boîte à outils SDK Amazon S3, et en tant que tel est bien adapté à la mise en œuvre de fonctionnalités S3 avancées telles que les téléchargements partitionnés, la mise en cache, la classe de stockage S3, le serveur- cryptage latéral et sélection de la région. Il est également hautement compatible POSIX.
L'application est incluse avec mon Fedora 30, ce qui facilite l'installation.
Pour tester :
~/mnt/s9s $ time pg_dump -d test | gzip -c >test.pg_dump-$(date +%Y%m%d-%H%M%S).gz
real 0m35.761s
user 0m16.122s
sys 0m2.228s
~/mnt/s9s $ aws s3 ls s3://s9s-postgresql-backup
2019-10-28 03:16:03 79110010 test.pg_dump-20191028-031535.gzNotez que la vitesse est un peu plus lente que l'utilisation d'Amazon Storage Gateway avec l'option NFS. Il compense les performances inférieures en fournissant un système de fichiers hautement compatible POSIX.
S3QL
S3QL fournit des fonctionnalités S3 telles que la classe de stockage et le chiffrement côté serveur. Les nombreuses fonctionnalités sont décrites dans la documentation S3QL exhaustive, cependant, si vous recherchez un téléchargement en plusieurs parties, cela n'est mentionné nulle part. En effet, S3QL implémente son propre algorithme de fractionnement de fichiers afin de fournir la fonction de déduplication. Tous les fichiers sont divisés en blocs de 10 Mo.
L'installation sur un système basé sur Red Hat est simple :installez les dépendances RPM requises via yum :
sqlite-devel-3.7.17-8.14.amzn1.x86_64
fuse-devel-2.9.4-1.18.amzn1.x86_64
fuse-2.9.4-1.18.amzn1.x86_64
system-rpm-config-9.0.3-42.28.amzn1.noarch
python36-devel-3.6.8-1.14.amzn1.x86_64
kernel-headers-4.14.146-93.123.amzn1.x86_64
glibc-headers-2.17-260.175.amzn1.x86_64
glibc-devel-2.17-260.175.amzn1.x86_64
gcc-4.8.5-1.22.amzn1.noarch
gcc48-4.8.5-28.142.amzn1.x86_64
mpfr-3.1.1-4.14.amzn1.x86_64
libmpc-1.0.1-3.3.amzn1.x86_64
libgomp-6.4.1-1.45.amzn1.x86_64
libgcc48-4.8.5-28.142.amzn1.x86_64
cpp48-4.8.5-28.142.amzn1.x86_64
python36-pip-9.0.3-1.26.amzn1.noarch
python36-libs-3.6.8-1.14.amzn1.x86_64
python36-3.6.8-1.14.amzn1.x86_64
python36-setuptools-36.2.7-1.33.amzn1.noarchEnsuite, installez les dépendances Python à l'aide de pip3 :
pip-3.6 install setuptools cryptography defusedxml apsw dugong pytest requests llfuse==1.3.6Une caractéristique notable de cet outil est le système de fichiers S3QL créé au-dessus du compartiment S3.
Dingo
goofys est une option lorsque les performances l'emportent sur la conformité POSIX. Ses objectifs sont à l'opposé de s3fs-fuse. L'accent mis sur la vitesse se reflète également dans le modèle de distribution. Pour Linux, il existe des binaires pré-construits. Une fois téléchargé, lancez :
~/temp/goofys $ ./goofys s9s-postgresql-backup ~/mnt/s9s/Et sauvegarde :
~/mnt/s9s $ time pg_dump -d test | gzip -c >test.pg_dump-$(date +%Y%m%d-%H%M%S).gz
real 0m27.427s
user 0m15.962s
sys 0m2.169s
~/mnt/s9s $ aws s3 ls s3://s9s-postgresql-backup
2019-10-28 04:29:05 79110010 test.pg_dump-20191028-042902.gzNotez que l'heure de création de l'objet sur S3 n'est qu'à 3 secondes de l'horodatage du fichier.
ObjectFS
ObjectFS semble avoir été maintenu jusqu'à il y a environ 6 mois. Une vérification du téléchargement en plusieurs parties révèle qu'il n'est pas implémenté. D'après le document de recherche de l'auteur, nous apprenons que le système est toujours en développement, et depuis la publication du document en 2019, j'ai pensé qu'il valait la peine de le mentionner.
Client S3
Comme mentionné précédemment, pour utiliser l'AWS S3 CLI, nous devons prendre en considération plusieurs aspects spécifiques au stockage d'objets en général, et à Amazon S3 en particulier. Si la seule exigence est la capacité de transférer des données vers et depuis le stockage S3, un outil qui suit de près les recommandations d'Amazon S3 peut faire le travail.
s3cmd est l'un des outils qui a résisté à l'épreuve du temps. Ce blog Open BI 2010 en parle, à une époque où S3 était le nouveau venu.
Caractéristiques notables :
- Chiffrement côté serveur
- téléchargements automatiques en plusieurs parties
- limitation de la bande passante
Rendez-vous sur S3cmd :FAQ et base de connaissances pour plus d'informations.
Conclusion
Les options disponibles pour sauvegarder un cluster PostgreSQL sur Amazon S3 diffèrent par les méthodes de transfert de données et la façon dont elles s'alignent sur les stratégies Amazon S3.
AWS Storage Gateway complète le stockage d'objets S3 d'Amazon, au prix d'une complexité accrue et de connaissances supplémentaires requises pour tirer le meilleur parti de ce service. Par exemple, la sélection du nombre correct de disques nécessite une planification minutieuse, et une bonne compréhension des coûts liés à S3 d'Amazon est indispensable afin de minimiser les coûts opérationnels.
Bien qu'elle s'applique à tout stockage cloud et pas seulement à Amazon S3, la décision de stocker les données dans un cloud public a des implications en matière de sécurité. Amazon S3 fournit un chiffrement pour les données au repos et les données en transit, sans garantie de connaissance nulle ou sans preuve de connaissance. Les organisations souhaitant avoir un contrôle total sur leurs données doivent implémenter le chiffrement côté client et stocker les clés de chiffrement en dehors de leur infrastructure AWS.
Pour des alternatives commerciales au mappage de S3 sur un système de fichiers local, il vaut la peine de consulter les produits d'ObjectiveFS ou de NetApp.
Enfin, les organisations souhaitant développer leurs propres outils de sauvegarde, soit en s'appuyant sur les bases fournies par les nombreuses applications open source, soit en partant de zéro, devraient envisager d'utiliser le test de compatibilité S3, mis à disposition par le projet Ceph.