SQL Server propose deux méthodes de collecte de données de diagnostic et de dépannage concernant la charge de travail exécutée sur le serveur :SQL Trace et Extended Events. À compter de SQL Server 2012, l'implémentation des événements étendus fournit des fonctionnalités de collecte de données comparables à SQL Trace et peut être utilisée pour comparer la surcharge induite par ces deux fonctionnalités. Dans cet article, nous examinerons la comparaison de la « surcharge d'observateur » qui se produit lors de l'utilisation de SQL Trace et d'événements étendus dans diverses configurations afin de déterminer l'impact sur les performances que la collecte de données peut avoir sur notre charge de travail grâce à l'utilisation d'une charge de travail de relecture. capture et relecture distribuée.
L'environnement de test
L'environnement de test est composé de six machines virtuelles, d'un contrôleur de domaine, d'un serveur SQL Server 2012 Enterprise Edition et de quatre serveurs clients sur lesquels le service client Distributed Replay est installé. Différentes configurations d'hôte ont été testées pour cet article et des résultats similaires ont résulté des trois configurations différentes qui ont été testées en fonction du rapport d'impact. Le serveur SQL Server Enterprise Edition est configuré avec 4 vCPU et 4 Go de RAM. Les cinq serveurs restants sont configurés avec 1 vCPU et 1 Go de RAM. Le service de contrôleur Distributed Replay a été exécuté sur le serveur SQL Server 2012 Enterprise Edition, car il nécessite une licence Enterprise pour utiliser plusieurs clients pour la relecture.
Tester la charge de travail
La charge de travail de test utilisée pour la capture de relecture est la charge de travail AdventureWorks Books Online que j'ai créée l'année dernière pour générer des charges de travail fictives sur SQL Server. Cette charge de travail utilise les exemples de requêtes de la documentation en ligne sur la famille de bases de données AdventureWorks et est pilotée par PowerShell. La charge de travail a été configurée sur chacun des quatre clients de relecture et exécutée avec quatre connexions totales au serveur SQL à partir de chacun des serveurs clients pour générer une capture de trace de relecture de 1 Go. La trace de relecture a été créée à l'aide du modèle TSQL_Replay de SQL Server Profiler, exportée vers un script et configurée en tant que trace côté serveur vers un fichier. Une fois le fichier de trace de relecture capturé, il a été prétraité pour être utilisé avec la relecture distribuée, puis les données de relecture ont été utilisées comme charge de travail de relecture pour tous les tests.
Configuration de relecture
L'opération de relecture a été configurée pour utiliser la configuration du mode stress afin de générer la quantité maximale de charge sur l'instance SQL Server de test. De plus, la configuration utilise une échelle de temps de réflexion et de connexion réduite, qui ajuste le rapport de temps entre le début de la trace de relecture et le moment où un événement s'est réellement produit jusqu'au moment où il est rejoué pendant l'opération de relecture, pour permettre aux événements d'être relus à échelle maximale. L'échelle de contrainte pour la relecture est également configurée par spid. Les détails du fichier de configuration pour l'opération de relecture étaient les suivants :
<?xml version="1.0" encoding="utf-8"?>
<Options>
<ReplayOptions>
<Server>SQL2K12-SVR1</Server>
<SequencingMode>stress</SequencingMode>
<ConnectTimeScale>1</ConnectTimeScale>
<ThinkTimeScale>1</ThinkTimeScale>
<HealthmonInterval>60</HealthmonInterval>
<QueryTimeout>3600</QueryTimeout>
<ThreadsPerClient>255</ThreadsPerClient>
<EnableConnectionPooling>Yes</EnableConnectionPooling>
<StressScaleGranularity>spid</StressScaleGranularity>
</ReplayOptions>
<OutputOptions>
<ResultTrace>
<RecordRowCount>No</RecordRowCount>
<RecordResultSet>No</RecordResultSet>
</ResultTrace>
</OutputOptions>
</Options> Au cours de chacune des opérations de relecture, des compteurs de performances ont été collectés à intervalles de cinq secondes pour les compteurs suivants :
- Processeur\% Temps processeur\_Total
- SQL Server\Statistiques SQL\Requêtes par lot/s
Ces compteurs seront utilisés pour mesurer la charge globale du serveur et les caractéristiques de débit de chacun des tests à des fins de comparaison.
Tester les configurations
Au total, sept configurations différentes ont été testées avec Distributed Replay :
- Référence
- Traçage côté serveur
- Profiler sur le serveur
- Profiler à distance
- Événements étendus à event_file
- Événements étendus à ring_buffer
- Événements étendus à event_stream
Chaque test a été répété trois fois pour s'assurer que les résultats étaient cohérents entre les différents tests et pour fournir un ensemble moyen de résultats à des fins de comparaison. Pour les tests de référence initiaux, aucune collecte de données supplémentaire n'a été configurée pour l'instance SQL Server, mais les collectes de données par défaut fournies avec SQL Server 2012 sont restées activées :la trace par défaut et la session d'événements system_health. Cela reflète la configuration générale de la plupart des serveurs SQL, car il n'est généralement pas recommandé de désactiver la trace par défaut ou la session system_health en raison des avantages qu'ils offrent aux administrateurs de base de données. Ce test a été utilisé pour déterminer la ligne de base globale pour la comparaison avec les tests où la collecte de données supplémentaires a été effectuée. Les tests restants sont basés sur le modèle TSQL_SPs fourni avec SQL Server Profiler et collecte les événements suivants :
- Audit de sécurité\Connexion d'audit
- Audit de sécurité\Déconnexion d'audit
- Sessions\Connexion existante
- Procédures stockées\RPC :Démarrage
- Procédures stockées\SP :terminées
- Procédures stockées\SP :Démarrage
- Procédures stockées\SP:StmtStarting
- TSQL\SQL :Démarrage du lot
Ce modèle a été sélectionné en fonction de la charge de travail utilisée pour les tests, qui est principalement constituée de lots SQL capturés par SQL:BatchStarting événement, puis un certain nombre d'événements en utilisant les différentes méthodes de hierarchyid , qui sont capturés par le SP:Starting , SP:StmtStarting , et SP:Completed événements. Un script de trace côté serveur a été généré à partir du modèle à l'aide de la fonctionnalité d'exportation dans SQL Server Profiler, et les seules modifications apportées au script consistaient à définir le maxfilesize paramètre à 500 Mo, activez le remplacement du fichier de trace et fournissez un nom de fichier dans lequel la trace a été écrite.
Les troisième et quatrième tests ont utilisé SQL Server Profiler pour collecter les mêmes événements que la trace côté serveur afin de mesurer la surcharge de performances de la trace à l'aide de l'application Profiler. Ces tests ont été exécutés à l'aide de SQL Profiler localement sur SQL Server et à distance à partir d'un client distinct pour déterminer s'il y avait une différence de surcharge en exécutant Profiler localement ou à distance.
Les tests finaux ont utilisé des événements étendus collectant les mêmes événements et les mêmes colonnes basées sur une session d'événements créée à l'aide de mon script de conversion Trace vers événements étendus pour SQL Server 2012. Les tests comprenaient l'évaluation de event_file, ring_buffer et du nouveau fournisseur de streaming dans SQL Server 2012 séparément pour déterminer la surcharge que chaque cible peut imposer aux performances du serveur. De plus, la session d'événements a été configurée avec les options de mémoire tampon par défaut, mais a été modifiée pour spécifier NO_EVENT_LOSS pour le EVENT_RETENTION_MODE option pour les tests event_file et ring_buffer pour faire correspondre le comportement de Trace côté serveur à un fichier, ce qui garantit également aucune perte d'événement.
Résultats
À une exception près, les résultats des tests n'étaient pas surprenants. Le test de référence a été en mesure d'effectuer la charge de travail de relecture en treize minutes et trente-cinq secondes, et en moyenne 2345 requêtes par seconde pendant les tests. Avec la trace côté serveur en cours d'exécution, l'opération de relecture s'est terminée en 16 minutes et 40 secondes, ce qui représente une dégradation des performances de 18,1 %. Les traces de Profiler ont eu les moins bonnes performances dans l'ensemble et ont nécessité 149 minutes lorsque Profiler était exécuté localement sur le serveur, et 123 minutes et 20 secondes lorsque Profiler était exécuté à distance, entraînant une dégradation des performances de 90,8 % et 87,6 % respectivement. Les tests Extended Events ont été les plus performants, prenant 15 minutes et 15 secondes pour event_file et 15 minutes et 40 secondes pour la cible ring_buffer, entraînant une dégradation des performances de 10,4 % et 11,6 %. Les résultats moyens pour tous les tests sont affichés dans le tableau 1 et représentés graphiquement dans la figure 2 :
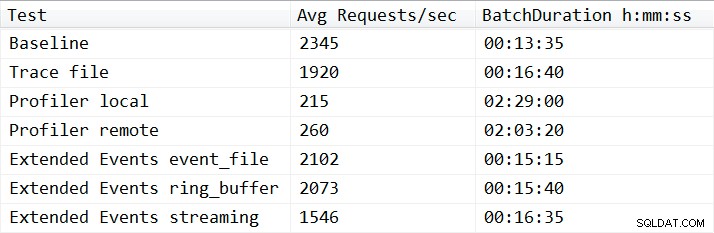
Tableau 1 – Résultats moyens de tous les tests
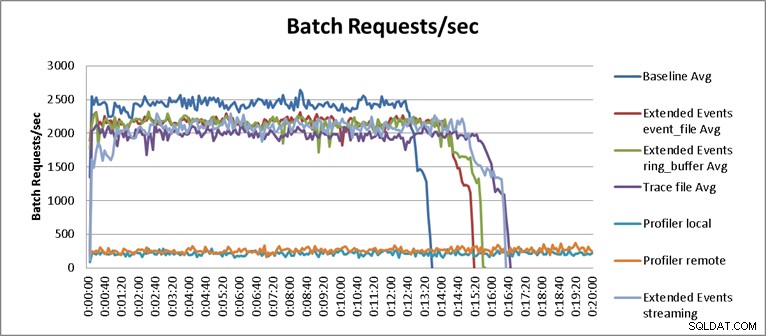
Figure 2 – Tableau des résultats
Le test de streaming d'événements étendus n'est pas tout à fait un résultat juste dans le contexte des tests qui ont été exécutés et nécessite un peu plus d'explications pour comprendre le résultat. D'après les résultats du tableau, nous pouvons voir que les tests de diffusion en continu pour les événements étendus se sont terminés en seize minutes et trente-cinq secondes, ce qui équivaut à une dégradation des performances de 34,1 %. Cependant, si nous zoomons sur le graphique et modifions son échelle, comme le montre la figure 3, nous verrons que le streaming a eu un impact beaucoup plus important sur les performances au départ, puis a commencé à fonctionner de manière similaire aux autres tests d'événements étendus. :
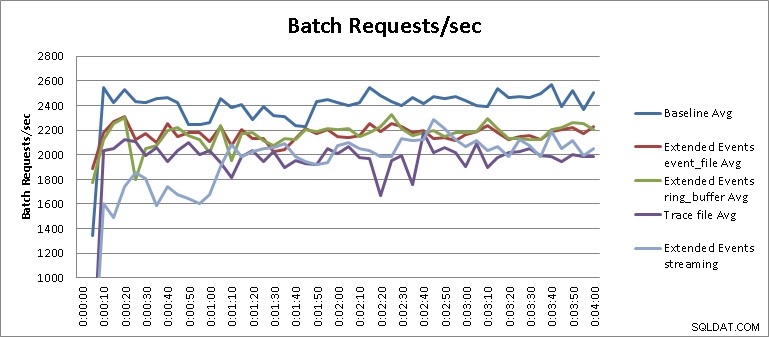
Figure 3 – Résultats agrandis
L'explication à cela se trouve dans la conception de la nouvelle cible de diffusion d'événements étendus dans SQL Server 2012. Si les tampons de mémoire interne pour le flux d'événements se remplissent et ne sont pas consommés par l'application cliente assez rapidement, le moteur de base de données forcera une déconnexion de l'event_stream pour éviter d'avoir un impact important sur les performances du serveur. Cela se traduit par une erreur générée dans SQL Server 2012 Management Studio similaire à l'erreur de la figure 4 :
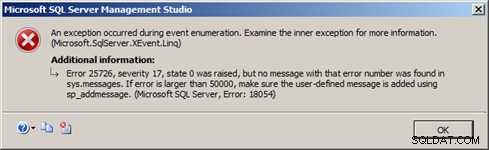
Figure 4 – event_stream déconnecté par le serveur
(Microsoft.SqlServer.XEvent.Linq)
L'erreur 25726, gravité 17, état 0 a été déclenchée, mais aucun message avec ce numéro d'erreur n'a été trouvé dans sys.messages. Si l'erreur est supérieure à 50000, assurez-vous que le message défini par l'utilisateur est ajouté à l'aide de sp_addmessage.
(Microsoft SQL Server, Erreur :18054)
Conclusion
Toutes les méthodes de collecte de données de diagnostic à partir de SQL Server sont associées à une « surcharge d'observateur » et peuvent avoir un impact sur les performances d'une charge de travail sous forte charge. Pour les systèmes exécutés sur SQL Server 2012, les événements étendus offrent le moins de temps système et offrent des fonctionnalités similaires pour les événements et les colonnes comme SQL Trace (certains événements dans SQL Trace sont cumulés dans d'autres événements dans les événements étendus). Si SQL Trace est nécessaire pour capturer des données d'événement (ce qui peut être le cas jusqu'à ce que des outils tiers soient recodés pour exploiter les données d'événements étendus), une trace côté serveur vers un fichier entraînera le moins de surcharge de performances. SQL Server Profiler est un outil à proscrire sur les serveurs de production très sollicités, comme le montre le déculement de la durée et la réduction significative du débit pour le replay.
Bien que les résultats semblent favoriser l'exécution à distance de SQL Server Profiler lorsque Profiler doit être utilisé, cette conclusion ne peut pas être définitivement tirée sur la base des tests spécifiques qui ont été exécutés dans ce scénario. Des tests et une collecte de données supplémentaires devraient être effectués pour déterminer si les résultats du profileur distant résultaient d'un changement de contexte inférieur sur l'instance SQL Server, ou si la mise en réseau entre les machines virtuelles jouait un rôle dans l'impact plus faible sur les performances de la collecte à distance. Le but de ces tests était de montrer la surcharge importante que Profiler encourt, quel que soit l'endroit où Profiler était exécuté. Enfin, le flux d'événements en direct dans les événements étendus a également une surcharge élevée lorsqu'il est réellement connecté à la collecte de données, mais comme indiqué dans les tests, le moteur de base de données déconnectera un flux en direct s'il prend du retard sur les événements pour éviter d'affecter gravement le performances du serveur.



