Utilisez-vous des sous-requêtes SQL ou évitez-vous de les utiliser ?
Supposons que le responsable du crédit et du recouvrement vous demande de répertorier les noms des personnes, leurs soldes impayés par mois et le solde courant actuel et souhaite que vous importiez ce tableau de données dans Excel. L'objectif est d'analyser les données et de proposer une offre allégeant les paiements pour atténuer les effets de la pandémie de COVID19.
Choisissez-vous d'utiliser une requête et une sous-requête imbriquée ou une jointure ? Quelle décision allez-vous prendre ?
Sous-requêtes SQL :de quoi s'agit-il ?
Avant d'approfondir la syntaxe, l'impact sur les performances et les mises en garde, pourquoi ne pas commencer par définir une sous-requête ?
Dans les termes les plus simples, une sous-requête est une requête dans une requête. Alors qu'une requête qui incarne une sous-requête est la requête externe, nous appelons une sous-requête la requête interne ou la sélection interne. Et les parenthèses entourent une sous-requête similaire à la structure ci-dessous :
SELECT
col1
,col2
,(subquery) as col3
FROM table1
[JOIN table2 ON table1.col1 = table2.col2]
WHERE col1 <operator> (subquery)Nous allons aborder les points suivants dans cet article :
- Syntaxe de sous-requête SQL en fonction des différents types de sous-requête et opérateurs.
- Quand et dans quel type d'instructions peut-on utiliser une sous-requête.
- Implications sur les performances par rapport aux JOINs .
- Mises en garde courantes lors de l'utilisation de sous-requêtes SQL
Comme à l'accoutumée, nous fournissons des exemples et des illustrations pour améliorer la compréhension. Mais gardez à l'esprit que l'objectif principal de cet article est sur les sous-requêtes dans SQL Server.
Maintenant, commençons.
Créer des sous-requêtes SQL autonomes ou corrélées
D'une part, les sous-requêtes sont classées en fonction de leur dépendance à la requête externe.
Permettez-moi de décrire ce qu'est une sous-requête autonome.
Les sous-requêtes autonomes (ou parfois appelées sous-requêtes simples ou non corrélées) sont indépendantes des tables de la requête externe. Permettez-moi d'illustrer ceci :
-- Get sales orders of customers from Southwest United States
-- (TerritoryID = 4)
USE [AdventureWorks]
GO
SELECT CustomerID, SalesOrderID
FROM Sales.SalesOrderHeader
WHERE CustomerID IN (SELECT [CustomerID]
FROM [AdventureWorks].[Sales].[Customer]
WHERE TerritoryID = 4)Comme démontré dans le code ci-dessus, la sous-requête (entre parenthèses ci-dessous) ne fait référence à aucune colonne de la requête externe. De plus, vous pouvez mettre en surbrillance la sous-requête dans SQL Server Management Studio et l'exécuter sans obtenir d'erreurs d'exécution.
Ce qui, à son tour, facilite le débogage des sous-requêtes autonomes.
La prochaine chose à considérer est les sous-requêtes corrélées. Comparé à son homologue autonome, celui-ci a au moins une colonne référencée à partir de la requête externe. Pour clarifier, je vais donner un exemple :
USE [AdventureWorks]
GO
SELECT DISTINCT a.LastName, a.FirstName, b.BusinessEntityID
FROM Person.Person AS p
JOIN HumanResources.Employee AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE 1262000.00 IN
(SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE p.BusinessEntityID = spq.BusinessEntityID)Avez-vous été suffisamment attentif pour remarquer la référence à BusinessEntityID de la personne table? Bravo !
Une fois qu'une colonne de la requête externe est référencée dans la sous-requête, elle devient une sous-requête corrélée. Un autre point à considérer :si vous mettez en surbrillance une sous-requête et que vous l'exécutez, une erreur se produira.
Et oui, vous avez tout à fait raison :cela rend les sous-requêtes corrélées assez difficiles à déboguer.
Pour rendre le débogage possible, suivez ces étapes :
- isoler la sous-requête.
- remplacer la référence à la requête externe par une valeur constante.
Isoler la sous-requête pour le débogage la fera ressembler à ceci :
SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE spq.BusinessEntityID = <constant value>Maintenant, approfondissons un peu le résultat des sous-requêtes.
Créer des sous-requêtes SQL avec 3 valeurs renvoyées possibles
Eh bien, d'abord, réfléchissons aux valeurs renvoyées que nous pouvons attendre des sous-requêtes SQL.
En fait, il y a 3 résultats possibles :
- Une seule valeur
- Plusieurs valeurs
- Tableaux entiers
Valeur unique
Commençons par une sortie à valeur unique. Ce type de sous-requête peut apparaître n'importe où dans la requête externe où une expression est attendue, comme WHERE clause.
-- Output a single value which is the maximum or last TransactionID
USE [AdventureWorks]
GO
SELECT TransactionID, ProductID, TransactionDate, Quantity
FROM Production.TransactionHistory
WHERE TransactionID = (SELECT MAX(t.TransactionID)
FROM Production.TransactionHistory t)Lorsque vous utilisez un MAX (), vous récupérez une seule valeur. C'est exactement ce qui est arrivé à notre sous-requête ci-dessus. En utilisant l'égal (= ) indique à SQL Server que vous attendez une valeur unique. Autre chose :si la sous-requête renvoie plusieurs valeurs en utilisant les égaux (= ) opérateur, vous obtenez une erreur, similaire à celui ci-dessous :
Msg 512, Level 16, State 1, Line 20
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.Valeurs multiples
Ensuite, nous examinons la sortie à valeurs multiples. Ce type de sous-requête renvoie une liste de valeurs avec une seule colonne. De plus, des opérateurs comme IN et PAS DANS attendra une ou plusieurs valeurs.
-- Output multiple values which is a list of customers with lastnames that --- start with 'I'
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.lastname LIKE N'I%' AND p.PersonType='SC')Valeurs entières du tableau
Et enfin, pourquoi ne pas vous plonger dans les sorties de table entières.
-- Output a table of values based on sales orders
USE [AdventureWorks]
GO
SELECT [ShipYear],
COUNT(DISTINCT [CustomerID]) AS CustomerCount
FROM (SELECT YEAR([ShipDate]) AS [ShipYear], [CustomerID]
FROM Sales.SalesOrderHeader) AS Shipments
GROUP BY [ShipYear]
ORDER BY [ShipYear]Avez-vous remarqué le DE clause ?
Au lieu d'utiliser une table, il a utilisé une sous-requête. C'est ce qu'on appelle une table dérivée ou une sous-requête de table.
Et maintenant, permettez-moi de vous présenter quelques règles de base lors de l'utilisation de ce type de requête :
- Toutes les colonnes de la sous-requête doivent avoir des noms uniques. Tout comme une table physique, une table dérivée doit avoir des noms de colonne uniques.
- TRIER PAR n'est pas autorisé sauf si TOP est également spécifié. En effet, la table dérivée représente une table relationnelle dans laquelle les lignes n'ont pas d'ordre défini.
Dans ce cas, une table dérivée présente les avantages d'une table physique. C'est pourquoi dans notre exemple, nous pouvons utiliser COUNT () dans une des colonnes de la table dérivée.
C'est à peu près tout ce qui concerne les sorties de sous-requête. Mais avant d'aller plus loin, vous avez peut-être remarqué que la logique derrière l'exemple pour plusieurs valeurs et d'autres peut également être effectuée à l'aide d'un JOIN .
-- Output multiple values which is a list of customers with lastnames that start with 'I'
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.LastName LIKE N'I%' AND p.PersonType = 'SC'En fait, le rendu sera le même. Mais lequel est le plus performant ?
Avant d'entrer dans les détails, laissez-moi vous dire que j'ai consacré une section à ce sujet brûlant. Nous l'examinerons avec des plans d'exécution complets et regarderons des illustrations.
Alors, supportez-moi un instant. Discutons d'une autre façon de placer vos sous-requêtes.
Autres instructions où vous pouvez utiliser des sous-requêtes SQL
Jusqu'à présent, nous avons utilisé des sous-requêtes SQL sur SELECT déclarations. Et le fait est que vous pouvez profiter des avantages des sous-requêtes sur INSERT , MISE À JOUR , et SUPPRIMER instructions ou dans toute instruction T-SQL qui forme une expression.
Alors, jetons un coup d'œil à une série d'exemples supplémentaires.
Utilisation des sous-requêtes SQL dans les instructions UPDATE
Il est assez simple d'inclure des sous-requêtes dans UPDATE déclarations. Pourquoi ne pas consulter cet exemple ?
-- In the products inventory, transfer all products of Vendor 1602 to ----
-- location 6
USE [AdventureWorks]
GO
UPDATE [Production].[ProductInventory]
SET LocationID = 6
WHERE ProductID IN
(SELECT ProductID
FROM Purchasing.ProductVendor
WHERE BusinessEntityID = 1602)
GOAvez-vous aperçu ce que nous avons fait là-bas ?
Le truc, c'est que vous pouvez mettre des sous-requêtes dans WHERE clause d'une UPDATE déclaration.
Comme nous ne l'avons pas dans l'exemple, vous pouvez également utiliser une sous-requête pour le SET clause comme SET colonne =(sous-requête) . Mais attention :il ne doit afficher qu'une seule valeur, sinon une erreur se produit.
Que faisons-nous ensuite ?
Utilisation des sous-requêtes SQL dans les instructions INSERT
Comme vous le savez déjà, vous pouvez insérer des enregistrements dans une table à l'aide d'un SELECT déclaration. Je suis sûr que vous avez une idée de ce que sera la structure de la sous-requête, mais démontrons cela avec un exemple :
-- Impose a salary increase for all employees in DepartmentID 6
-- (Research and Development) by 10 (dollars, I think)
-- effective June 1, 2020
USE [AdventureWorks]
GO
INSERT INTO [HumanResources].[EmployeePayHistory]
([BusinessEntityID]
,[RateChangeDate]
,[Rate]
,[PayFrequency]
,[ModifiedDate])
SELECT
a.BusinessEntityID
,'06/01/2020' as RateChangeDate
,(SELECT MAX(b.Rate) FROM [HumanResources].[EmployeePayHistory] b
WHERE a.BusinessEntityID = b.BusinessEntityID) + 10 as NewRate
,2 as PayFrequency
,getdate() as ModifiedDate
FROM [HumanResources].[EmployeeDepartmentHistory] a
WHERE a.DepartmentID = 6
and StartDate = (SELECT MAX(c.StartDate)
FROM HumanResources.EmployeeDepartmentHistory c
WHERE c.BusinessEntityID = a.BusinessEntityID)Alors, qu'est-ce qu'on regarde ici ?
- La première sous-requête récupère le dernier taux de salaire d'un employé avant d'ajouter les 10 supplémentaires.
- La deuxième sous-requête obtient le dernier enregistrement de salaire de l'employé.
- Enfin, le résultat de la SELECT est inséré dans EmployeePayHistory tableau.
Dans d'autres instructions T-SQL
En dehors de SELECT , INSÉRER , MISE À JOUR , et SUPPRIMER , vous pouvez également utiliser des sous-requêtes SQL dans les éléments suivants :
Déclarations de variables ou instructions SET dans les procédures et fonctions stockées
Permettez-moi de clarifier en utilisant cet exemple :
DECLARE @maxTransId int = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)Alternativement, vous pouvez le faire de la manière suivante :
DECLARE @maxTransId int
SET @maxTransId = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)Dans les expressions conditionnelles
Pourquoi ne pas jeter un coup d'œil à cet exemple :
IF EXISTS(SELECT [Name] FROM sys.tables where [Name] = 'MyVendors')
BEGIN
DROP TABLE MyVendors
ENDEn dehors de cela, nous pouvons le faire comme ceci :
IF (SELECT count(*) FROM MyVendors) > 0
BEGIN
-- insert code here
ENDCréer des sous-requêtes SQL avec des opérateurs de comparaison ou logiques
Jusqu'à présent, nous avons vu les égaux (= ) et l'opérateur IN. Mais il y a bien plus à explorer.
Utilisation des opérateurs de comparaison
Lorsqu'un opérateur de comparaison tel que =, <,>, <>,>=ou <=est utilisé avec une sous-requête, la sous-requête doit renvoyer une seule valeur. De plus, une erreur se produit si la sous-requête renvoie plusieurs valeurs.
L'exemple ci-dessous générera une erreur d'exécution.
USE [AdventureWorks]
GO
SELECT b.LastName, b.FirstName, b.MiddleName, a.JobTitle, a.BusinessEntityID
FROM HumanResources.Employee a
INNER JOIN Person.Person b on a.BusinessEntityID = b.BusinessEntityID
INNER JOIN HumanResources.EmployeeDepartmentHistory c on a.BusinessEntityID
= c.BusinessEntityID
WHERE c.DepartmentID = 6
and StartDate = (SELECT d.StartDate
FROM HumanResources.EmployeeDepartmentHistory d
WHERE d.BusinessEntityID = a.BusinessEntityID)Savez-vous ce qui ne va pas dans le code ci-dessus ?
Tout d'abord, le code utilise l'opérateur égal (=) avec la sous-requête. De plus, la sous-requête renvoie une liste de dates de début.
Afin de résoudre le problème, faites en sorte que la sous-requête utilise une fonction telle que MAX () dans la colonne de date de début pour renvoyer une seule valeur.
Utiliser des opérateurs logiques
Utiliser EXISTS ou NOT EXISTS
EXISTE renvoie VRAI si la sous-requête renvoie des lignes. Sinon, il renvoie FALSE . Pendant ce temps, en utilisant NOT EXISTE renverra TRUE s'il n'y a pas de lignes et FALSE , sinon.
Prenons l'exemple ci-dessous :
IF EXISTS(SELECT name FROM sys.tables where name = 'Token')
BEGIN
DROP TABLE Token
ENDTout d'abord, permettez-moi de vous expliquer. Le code ci-dessus supprimera le jeton de table s'il se trouve dans sys.tables , c'est-à-dire s'il existe dans la base de données. Autre point :la référence au nom de la colonne n'est pas pertinente.
Pourquoi est-ce ?
Il s'avère que le moteur de base de données n'a besoin que d'obtenir au moins 1 ligne en utilisant EXISTS . Dans notre exemple, si la sous-requête renvoie une ligne, la table sera supprimée. En revanche, si la sous-requête n'a renvoyé aucune ligne, les instructions suivantes ne seront pas exécutées.
Ainsi, le souci de EXISTE est juste des lignes et pas de colonnes.
De plus, EXISTE utilise une logique à deux valeurs :TRUE ou FAUX . Il n'y a aucun cas où il retournera NULL . La même chose se produit lorsque vous annulez EXISTS en utilisant PAS .
Utiliser IN ou NOT IN
Une sous-requête introduite avec IN ou PAS DANS renverra une liste de zéro ou plusieurs valeurs. Et contrairement à EXISTS , une colonne valide avec le type de données approprié est requise.
Permettez-moi de clarifier cela avec un autre exemple :
-- From the product inventory, extract the products that are available
-- (Quantity >0)
-- except for products from Vendor 1676, and introduce a price cut for the --- whole month of June 2020.
-- Insert the results in product price history.
USE [AdventureWorks]
GO
INSERT INTO [Production].[ProductListPriceHistory]
([ProductID]
,[StartDate]
,[EndDate]
,[ListPrice]
,[ModifiedDate])
SELECT
a.ProductID
,'06/01/2020' as StartDate
,'06/30/2020' as EndDate
,a.ListPrice - 2 as ReducedListPrice
,getdate() as ModifiedDate
FROM [Production].[ProductListPriceHistory] a
WHERE a.StartDate = (SELECT MAX(StartDate)
FROM Production.ProductListPriceHistory
WHERE ProductID = a.ProductID)
AND a.ProductID IN (SELECT ProductID
FROM Production.ProductInventory
WHERE Quantity > 0)
AND a.ProductID NOT IN (SELECT ProductID
FROM [Purchasing].[ProductVendor]
WHERE BusinessEntityID = 1676Comme vous pouvez le voir dans le code ci-dessus, les deux IN et PAS DANS opérateurs sont introduits. Et dans les deux cas, les lignes seront renvoyées. Chaque ligne de la requête externe sera comparée au résultat de chaque sous-requête afin d'obtenir un produit disponible et un produit qui ne provient pas du fournisseur 1676.
Imbrication de sous-requêtes SQL
Vous pouvez imbriquer des sous-requêtes jusqu'à 32 niveaux. Néanmoins, cette capacité dépend de la mémoire disponible du serveur et de la complexité des autres expressions de la requête.
Que pensez-vous de cela ?
D'après mon expérience, je ne me souviens pas d'avoir imbriqué jusqu'à 4. J'utilise rarement 2 ou 3 niveaux. Mais ce n'est que moi et mes exigences.
Que diriez-vous d'un bon exemple pour comprendre cela :
-- List down the names of employees who are also customers.
USE [AdventureWorks]
GO
SELECT
LastName
,FirstName
,MiddleName
FROM Person.Person
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Sales.Customer
WHERE BusinessEntityID IN
(SELECT BusinessEntityID
FROM HumanResources.Employee))Comme on peut le voir dans cet exemple, l'imbrication a atteint 2 niveaux.
Les sous-requêtes SQL nuisent-elles aux performances ?
En un mot :oui et non. En d'autres termes, cela dépend.
Et n'oubliez pas, c'est dans le contexte de SQL Server.
Pour commencer, de nombreuses instructions T-SQL qui utilisent des sous-requêtes peuvent également être réécrites à l'aide de JOIN s. Et les performances pour les deux sont généralement les mêmes. Malgré cela, il existe des cas particuliers où une jointure est plus rapide. Et il y a des cas où la sous-requête fonctionne plus rapidement.
Exemple 1
Examinons un exemple de sous-requête. Avant de les exécuter, appuyez sur Control-M ou activez Inclure le plan d'exécution réel à partir de la barre d'outils de SQL Server Management Studio.
USE [AdventureWorks]
GO
SELECT Name
FROM Production.Product
WHERE ListPrice = SELECT ListPrice
FROM Production.Product
WHERE Name = 'Touring End Caps')Alternativement, la requête ci-dessus peut être réécrite à l'aide d'une jointure qui produit le même résultat.
USE [AdventureWorks]
GO
SELECT Prd1.Name
FROM Production.Product AS Prd1
INNER JOIN Production.Product AS Prd2 ON (Prd1.ListPrice = Prd2.ListPrice)
WHERE Prd2.Name = 'Touring End Caps'Au final, le résultat des deux requêtes est de 200 lignes.
En plus de cela, vous pouvez consulter le plan d'exécution pour les deux déclarations.
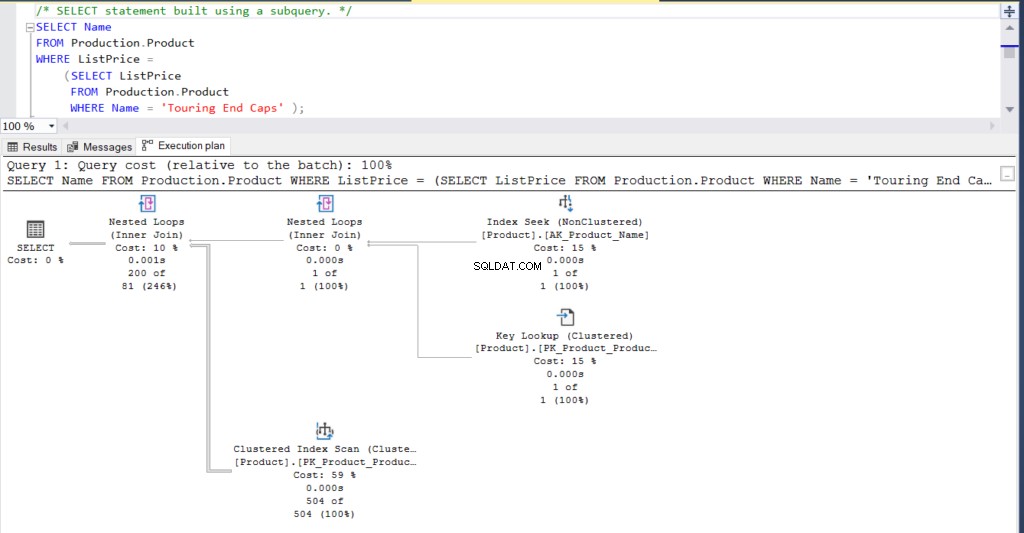
Figure 1 :Plan d'exécution à l'aide d'une sous-requête
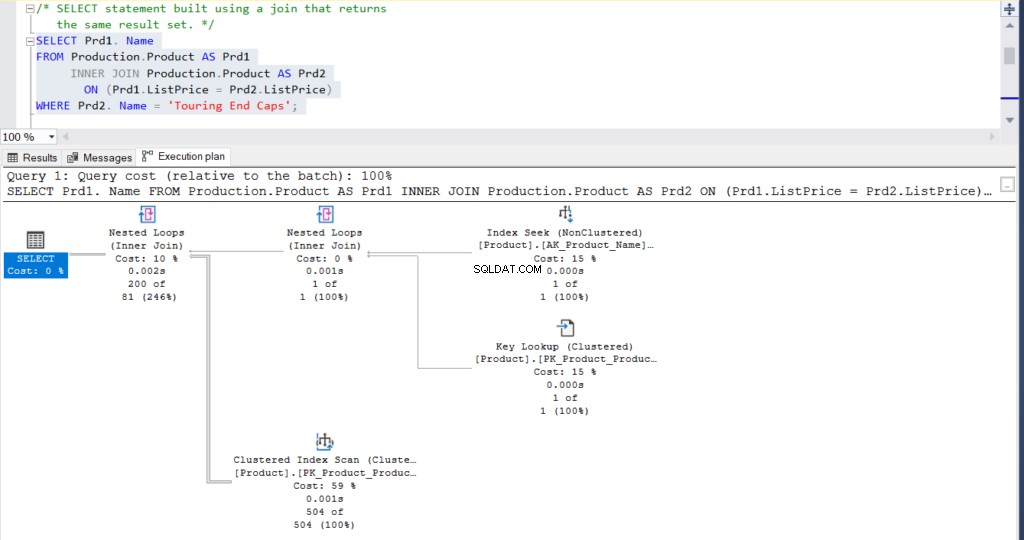
Figure 2 :Plan d'exécution à l'aide d'une jointure
Qu'en penses-tu? Sont-ils pratiquement les mêmes ? À l'exception du temps écoulé réel de chaque nœud, tout le reste est fondamentalement le même.
Mais voici une autre façon de le comparer en dehors des différences visuelles. Je suggère d'utiliser le Comparer Showplan .
Pour l'exécuter, suivez ces étapes :
- Cliquez avec le bouton droit sur le plan d'exécution de l'instruction à l'aide de la sous-requête.
- Sélectionnez Enregistrer le plan d'exécution sous .
- Nommez le fichier subquery-execution-plan.sqlplan .
- Accédez au plan d'exécution de l'instruction à l'aide d'une jointure et cliquez dessus avec le bouton droit.
- Sélectionnez Comparer Showplan .
- Sélectionnez le nom de fichier que vous avez enregistré dans #3.
Maintenant, consultez ceci pour plus d'informations sur Comparer Showplan .
Vous devriez pouvoir voir quelque chose de similaire à ceci :
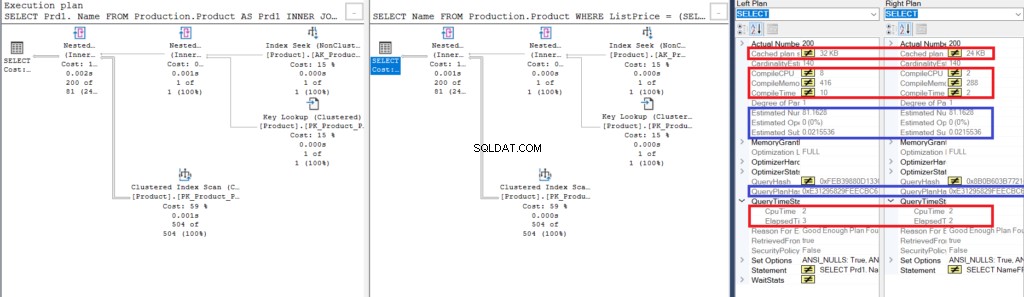
Figure 3 :Comparez Showplan pour l'utilisation d'une jointure et l'utilisation d'une sous-requête
Remarquez les similitudes :
- Les lignes et les coûts estimés sont les mêmes.
- QueryPlanHash est également identique, ce qui signifie qu'ils ont des plans d'exécution similaires.
Néanmoins, notez les différences :
- La taille du plan de cache est plus grande avec la jointure qu'avec la sous-requête
- Le processeur et le temps de compilation (en ms), y compris la mémoire en Ko, utilisés pour analyser, lier et optimiser le plan d'exécution sont plus élevés en utilisant la jointure qu'en utilisant la sous-requête
- Le temps CPU et le temps écoulé (en ms) pour exécuter le plan sont légèrement plus élevés en utilisant la jointure par rapport à la sous-requête
Dans cet exemple, la sous-requête est un tic plus rapide que la jointure, même si les lignes résultantes sont les mêmes.
Exemple 2
Dans l'exemple précédent, nous n'avons utilisé qu'une seule table. Dans l'exemple qui suit, nous allons utiliser 3 tables différentes.
Faisons en sorte que cela se produise :
-- Subquery example
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID =
p.BusinessEntityID
WHERE p.PersonType='SC')-- Join example
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'Les deux requêtes génèrent les mêmes 3 806 lignes.
Examinons ensuite leurs plans d'exécution :
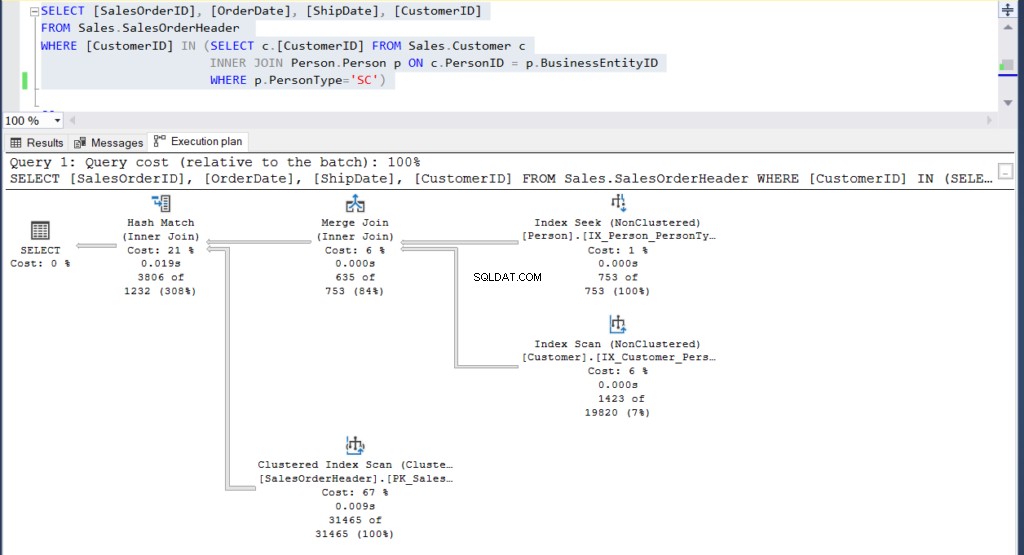
Figure 4 :Plan d'exécution pour notre deuxième exemple utilisant une sous-requête
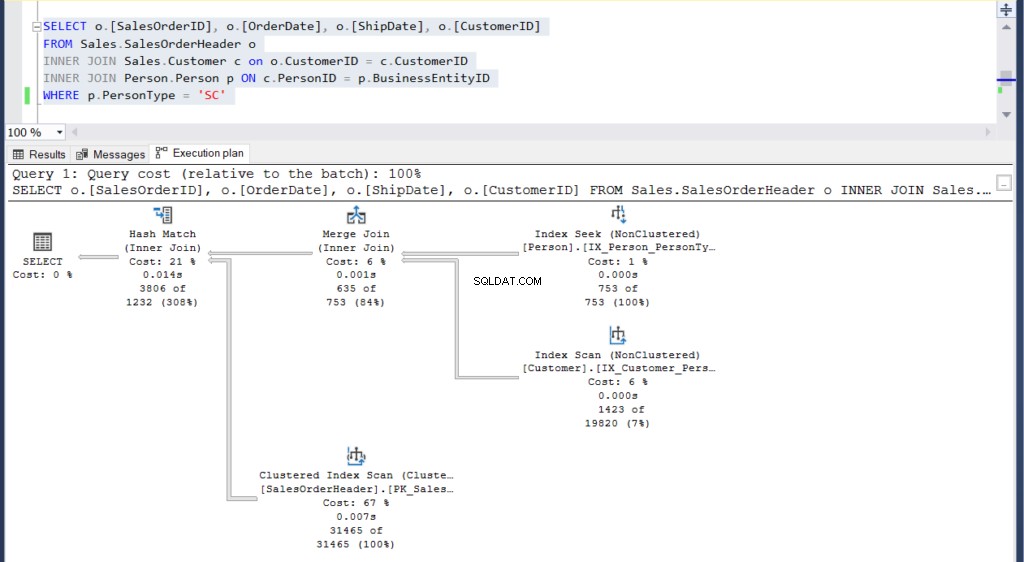
Figure 5 :Plan d'exécution pour notre deuxième exemple utilisant une jointure
Pouvez-vous voir les 2 plans d'exécution et trouver une différence entre eux ? En un coup d'œil, ils se ressemblent.
Mais un examen plus attentif avec le Comparer Showplan révèle ce qu'il y a vraiment à l'intérieur.
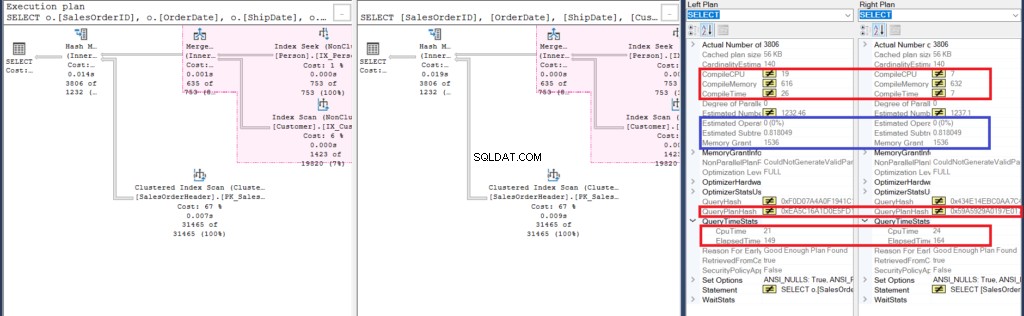
Figure 6 :Détails de Compare Showplan pour le deuxième exemple
Commençons par analyser quelques similarités :
- La surbrillance rose dans le plan d'exécution révèle des opérations similaires pour les deux requêtes. Étant donné que la requête interne utilise une jointure au lieu d'imbriquer des sous-requêtes, cela est tout à fait compréhensible.
- Les coûts estimés pour l'opérateur et le sous-arbre sont les mêmes.
Examinons ensuite les différences :
- Tout d'abord, la compilation prenait plus de temps lorsque nous utilisions des jointures. Vous pouvez vérifier cela dans Compile CPU et Compile Time. Cependant, la requête avec une sous-requête a pris une mémoire de compilation plus élevée en Ko.
- Ensuite, le QueryPlanHash des deux requêtes est différent, ce qui signifie qu'elles ont un plan d'exécution différent.
- Enfin, le temps écoulé et le temps CPU pour exécuter le plan sont plus rapides en utilisant la jointure que d'utiliser une sous-requête.
Sous-requête vs Join Performance Takeaway
Vous êtes susceptible de rencontrer trop d'autres problèmes liés aux requêtes qui peuvent être résolus en utilisant une jointure ou une sous-requête.
Mais l'essentiel est qu'une sous-requête n'est pas intrinsèquement mauvaise par rapport aux jointures. Et il n'y a pas de règle empirique selon laquelle, dans une situation particulière, une jointure est meilleure qu'une sous-requête ou l'inverse.
Alors, pour vous assurer que vous avez le meilleur choix, vérifiez les plans d'exécution. Le but est de mieux comprendre comment SQL Server traitera une requête particulière.
Cependant, si vous choisissez d'utiliser une sous-requête, sachez que des problèmes peuvent survenir et mettre vos compétences à l'épreuve.
Mises en garde courantes dans l'utilisation des sous-requêtes SQL
Il existe 2 problèmes courants qui peuvent entraîner un comportement anormal de vos requêtes lors de l'utilisation de sous-requêtes SQL.
La douleur de la résolution des noms de colonnes
Ce problème introduit des bogues logiques dans vos requêtes et ils peuvent être très difficiles à trouver. Un exemple peut clarifier davantage ce problème.
Commençons par créer un tableau à des fins de démonstration et remplissons-le avec des données.
USE [AdventureWorks]
GO
-- Create the table for our demonstration based on Vendors
CREATE TABLE Purchasing.MyVendors
(
BusinessEntity_id int,
AccountNumber nvarchar(15),
Name nvarchar(50)
)
GO
-- Populate some data to our new table
INSERT INTO Purchasing.MyVendors
SELECT BusinessEntityID, AccountNumber, Name
FROM Purchasing.Vendor
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.ProductVendor)
AND BusinessEntityID like '14%'
GOMaintenant que la table est définie, lançons quelques sous-requêtes en l'utilisant. Mais avant d'exécuter la requête ci-dessous, rappelez-vous que les ID de fournisseur que nous avons utilisés dans le code précédent commencent par '14'.
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.MyVendors)Le code ci-dessus s'exécute sans erreur, comme vous pouvez le voir ci-dessous. Quoi qu'il en soit, faites attention à la liste des BusinessEntityIDs .
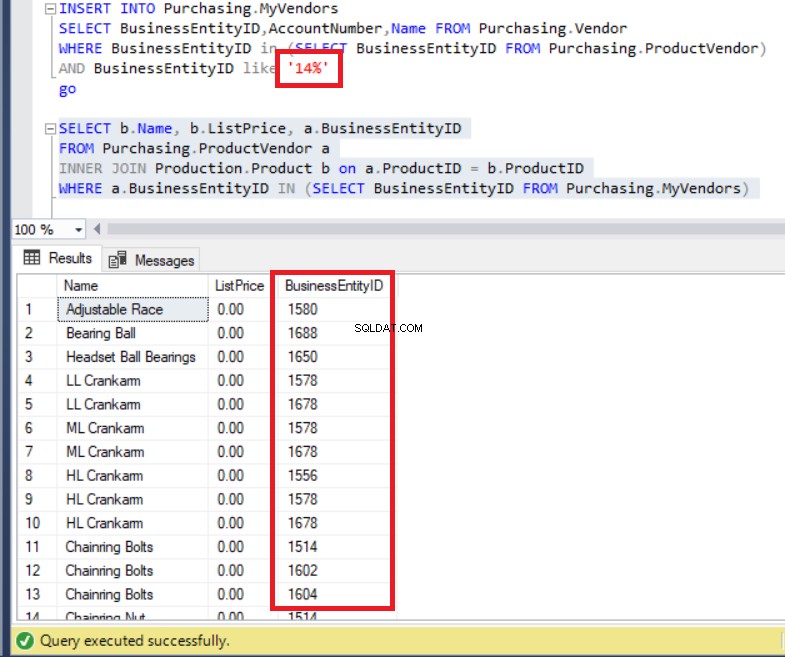
Figure 7 :les BusinessEntityID de l'ensemble de résultats sont incohérents avec les enregistrements de la table MyVendors
N'avons-nous pas inséré des données avec BusinessEntityID commençant par '14'? Alors quel est le problème? En fait, nous pouvons voir BusinessEntityIDs qui commencent par '15' et '16'. D'où viennent-ils ?
En fait, la requête répertorie toutes les données de ProductVendor tableau.
Dans ce cas, vous pourriez penser qu'un alias résoudra ce problème afin qu'il fasse référence à MyVendors tableau comme celui ci-dessous :
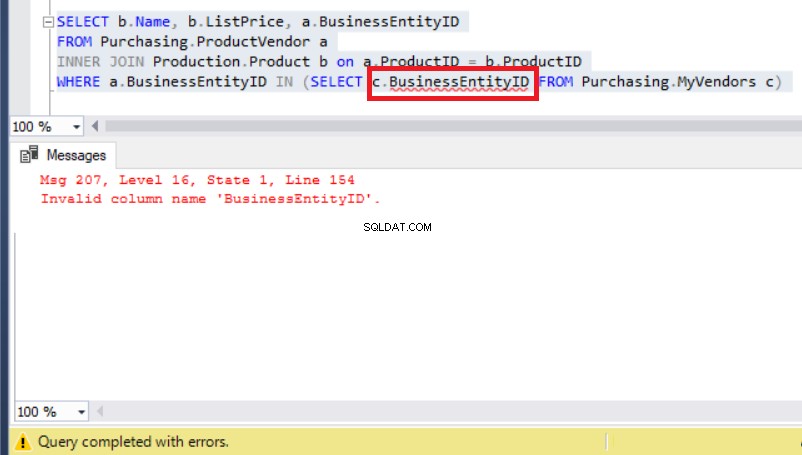
Figure 8 :L'ajout d'un alias au BusinessEntityID entraîne une erreur
Sauf que maintenant le vrai problème est apparu à cause d'une erreur d'exécution.
Vérifiez MyVendors table à nouveau et vous verrez cela au lieu de BusinessEntityID , le nom de la colonne doit être BusinessEntity_id (avec un trait de soulignement).
Ainsi, l'utilisation du nom de colonne correct résoudra finalement ce problème, comme vous pouvez le voir ci-dessous :
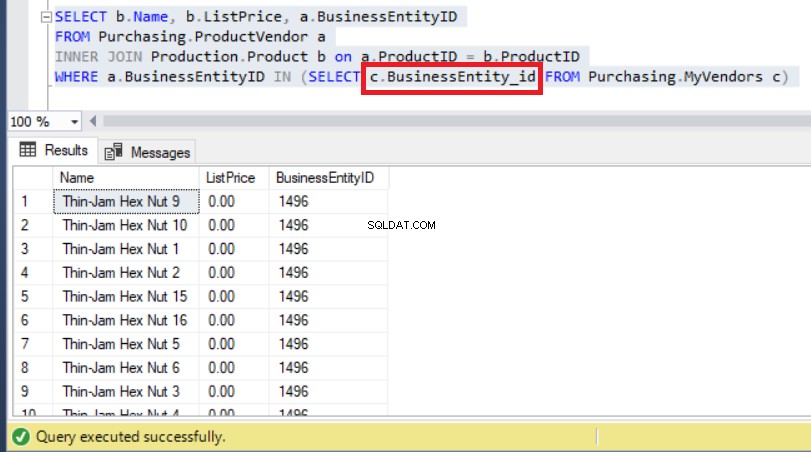
Figure 9 :Changer la sous-requête avec le nom de colonne correct a résolu le problème
Comme vous pouvez le voir ci-dessus, nous pouvons maintenant observer les BusinessEntityIDs commençant par '14' comme nous l'avions prévu précédemment.
Mais vous vous demandez peut-être :pourquoi diable SQL Server a-t-il permis d'exécuter la requête avec succès ?
Voici le kicker :la résolution des noms de colonne sans alias fonctionne dans le contexte de la sous-requête en elle-même vers la requête externe. C'est pourquoi la référence à BusinessEntityID à l'intérieur de la sous-requête n'a pas déclenché d'erreur car il se trouve en dehors de la sous-requête - dans le ProductVendor tableau.
En d'autres termes, SQL Server recherche la colonne sans alias BusinessEntityID dans MesVendeurs table. Puisqu'il n'est pas là, il a regardé à l'extérieur et l'a trouvé dans le ProductVendor table. Fou, n'est-ce pas ?
Vous pourriez dire que c'est un bogue dans SQL Server, mais, en fait, c'est par conception dans la norme SQL et Microsoft l'a suivi.
D'accord, c'est clair, nous ne pouvons rien faire au sujet de la norme, mais comment pouvons-nous éviter de tomber dans une erreur ?
- Tout d'abord, préfixez les noms de colonne avec le nom de la table ou utilisez un alias. En d'autres termes, évitez les noms de table sans préfixe ou sans alias.
- Deuxièmement, nommez les colonnes de manière cohérente. Évitez d'avoir à la fois BusinessEntityID et BusinessEntity_id , par exemple.
Ça a l'air bien? Oui, cela apporte un peu de bon sens à la situation.
Mais ce n'est pas la fin.
NULL fous
Comme je l'ai mentionné, il y a plus à couvrir. T-SQL utilise une logique à 3 valeurs en raison de sa prise en charge de NULL . Et NULL peut presque nous rendre fous lorsque nous utilisons des sous-requêtes SQL avec NOT IN .
Permettez-moi de commencer par vous présenter cet exemple :
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c)Le résultat de la requête nous amène à une liste de produits qui ne se trouvent pas dans MyVendors tableau., comme indiqué ci-dessous :
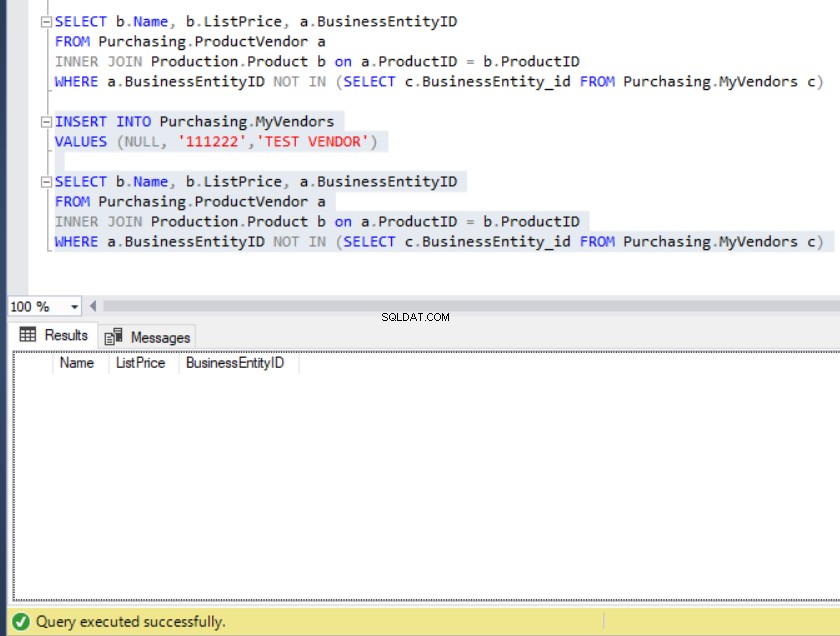
Figure 10 :La sortie de l'exemple de requête utilisant NOT IN
Maintenant, supposons que quelqu'un ait involontairement inséré un enregistrement dans MyVendors table avec un NULL BusinessEntity_id . Qu'allons-nous faire à ce sujet ?
Figure 11 :L'ensemble de résultats devient vide lorsqu'un BusinessEntity_id NULL est inséré dans MyVendors
Où sont passées toutes les données ?
Vous voyez, le PAS l'opérateur a annulé le IN prédicat. Donc, PAS VRAI deviendra maintenant FALSE . Mais PAS NULL est INCONNU. Cela a amené le filtre à rejeter les lignes INCONNUES, et c'est le coupable.
Pour vous assurer que cela ne vous arrive pas :
- Soit faire en sorte que la colonne de table interdise les NULL si les données ne doivent pas être ainsi.
- Ou ajoutez le nom_colonne IS NOT NULL à votre OÙ clause. Dans notre cas, la sous-requête est la suivante :
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c
WHERE c.BusinessEntity_id IS NOT NULL)À emporter
Nous avons beaucoup parlé des sous-requêtes, et le moment est venu de fournir les principaux points à retenir de cet article sous la forme d'une liste résumée :
Une sous-requête :
- est une requête dans une requête.
- est entre parenthèses.
- peut substituer une expression n'importe où.
- peut être utilisé dans SELECT , INSÉRER , MISE À JOUR , SUPPRIMER, ou d'autres instructions T-SQL.
- peut être autonome ou corrélé.
- affiche des valeurs uniques, multiples ou de table.
- fonctionne sur les opérateurs de comparaison comme =, <>,>, <,>=, <=et les opérateurs logiques comme IN /PAS DANS et EXISTE /N'EXISTE PAS .
- n'est ni mauvais ni mauvais. Il peut fonctionner mieux ou moins bien que JOIN s en fonction d'une situation. Suivez donc mon conseil et vérifiez toujours les plans d'exécution.
- peut avoir un comportement désagréable sur NULL s lorsqu'il est utilisé avec NOT IN , et lorsqu'une colonne n'est pas explicitement identifiée avec une table ou un alias de table.
Get familiarized with several additional references for your reading pleasure:
- Discussion of Subqueries from Microsoft.
- IN (Transact-SQL)
- EXISTS (Transact-SQL)
- ALL (Transact-SQL)
- SOME | ANY (Transact-SQL)
- Comparison Operators