La surveillance des changements de schéma de votre base de données dans MySQL/MariaDB fournit une aide considérable car elle permet de gagner du temps en analysant la croissance de votre base de données, les changements de définition de table, la taille des données, la taille de l'index ou la taille des lignes. Pour MySQL/MariaDB, l'exécution d'une requête référençant information_schema avec performance_schema vous donne des résultats collectifs pour une analyse plus approfondie. Le schéma sys vous fournit des vues qui servent de métriques collectives très utiles pour suivre les modifications ou l'activité de la base de données.
Si vous avez plusieurs serveurs de base de données, il serait fastidieux d'exécuter une requête tout le temps. Vous devez également digérer ce résultat dans un format plus lisible et plus facile à comprendre.
Dans ce blog, nous allons créer une automatisation qui serait utile en tant qu'outil utilitaire pour surveiller votre base de données existante et collecter des métriques concernant les modifications de base de données ou les opérations de modification de schéma.
Création d'une automatisation pour la vérification d'objet de schéma de base de données
Dans cet exercice, nous surveillerons les métriques suivantes :
-
Aucune table de clé primaire
-
Index en double
-
Générer un graphique pour le nombre total de lignes dans nos schémas de base de données
-
Générer un graphique pour la taille totale de nos schémas de base de données
Cet exercice vous donnera un aperçu et peut être modifié pour collecter des métriques plus avancées à partir de votre base de données MySQL/MariaDB.
Utilisation de Puppet pour notre IaC et l'automatisation
Cet exercice doit utiliser Puppet pour fournir une automatisation et générer les résultats attendus en fonction des métriques que nous voulons surveiller. Nous ne couvrirons pas l'installation et la configuration de Puppet, y compris le serveur et le client, donc je m'attends à ce que vous sachiez comment utiliser Puppet. Vous voudrez peut-être visiter notre ancien blog Déploiement automatisé de MySQL Galera Cluster sur Amazon AWS avec Puppet, qui couvre la configuration et l'installation de Puppet.
Nous utiliserons la dernière version de Puppet dans cet exercice, mais comme notre code se compose d'une syntaxe de base, il fonctionnerait pour les anciennes versions de Puppet.
Serveur de base de données MySQL préféré
Dans cet exercice, nous utiliserons Percona Server 8.0.22-13 car je préfère Percona Server principalement pour les tests et certains déploiements mineurs, à usage professionnel ou personnel.
Outil graphique
Il existe des tonnes d'options à utiliser, en particulier dans l'environnement Linux. Dans ce blog, j'utiliserai le plus simple que j'ai trouvé et un outil open source https://quickchart.io/.
Jouons avec la marionnette
L'hypothèse que j'ai faite ici est que vous avez configuré un serveur maître avec un client enregistré qui est prêt à communiquer avec le serveur maître pour recevoir des déploiements automatiques.
Avant de continuer, voici les informations sur mon serveur :
Serveur maître :192.168.40.200
Client/Agent Serveur :192.168.40.160
Dans ce blog, notre serveur client/agent est l'endroit où s'exécute notre serveur de base de données. Dans un scénario réel, il n'est pas nécessaire que ce soit spécialement pour la surveillance. Tant qu'il est capable de communiquer en toute sécurité avec le nœud cible, c'est également une configuration parfaite.
Configurer le module et le code
-
Allez sur le serveur maître et dans le chemin /etc/puppetlabs/code/environments/production/module, créons les répertoires requis pour cet exercice :
mkdir schema_change_mon/{files,manifests}
-
Créer les fichiers dont nous avons besoin
touch schema_change_mon/files/graphing_gen.sh
touch schema_change_mon/manifests/init.pp
-
Remplissez le script init.pp avec le contenu suivant :
class schema_change_mon (
$db_provider = "mysql",
$db_user = "root",
$db_pwd = "example@sqldat.com",
$db_schema = []
) {
$dbs = ['pauldb', 'sbtest']
service { $db_provider :
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
exec { "mysql-without-primary-key" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"select concat(tables.table_schema,'.',tables.table_name,', ', tables.engine) from information_schema.tables left join ( select table_schema , table_name from information_schema.statistics group by table_schema , table_name , index_name having sum( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks on tables.table_schema = puks.table_schema and tables.table_name = puks.table_name where puks.table_name is null and tables.table_type = 'BASE TABLE' and tables.table_schema not in ('performance_schema', 'information_schema', 'mysql');\" >> /opt/schema_change_mon/assets/no-pk.log"
}
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"SELECT concat(t.table_schema,'.', t.table_name, '.', t.index_name, '(', t.idx_cols,')') FROM ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='${db}' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) t JOIN ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='pauldb' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) u where t.table_schema = u.table_schema AND t.table_name = u.table_name AND t.index_name<>u.index_name AND locate(t.idx_cols,u.idx_cols);\" information_schema >> /opt/schema_change_mon/assets/dupe-indexes.log"
}
}
$genscript = "/tmp/graphing_gen.sh"
file { "${genscript}" :
ensure => present,
owner => root,
group => root,
mode => '0655',
source => 'puppet:///modules/schema_change_mon/graphing_gen.sh'
}
exec { "generate-graph-total-rows" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_rows"
}
exec { "generate-graph-total-len" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_len"
}
}
-
Remplissez le fichier graphing_gen.sh. Ce script s'exécutera sur le nœud cible et générera des graphiques pour le nombre total de lignes dans notre base de données ainsi que la taille totale de notre base de données. Pour ce script, simplifions les choses et n'autorisons que les bases de données de type MyISAM ou InnoDB.
#!/bin/bash
graph_ident="${1:-total_rows}"
unset json myisam innodb nmyisam ninnodb; json='' myisam='' innodb='' nmyisam='' ninnodb='' url=''; json=$(MYSQL_PWD="example@sqldat.com" mysql -uroot -Nse "select json_object('dbschema', concat(table_schema,' - ', engine), 'total_rows', sum(table_rows), 'total_len', sum(data_length+data_length), 'fragment', sum(data_free)) from information_schema.tables where table_schema not in ('performance_schema', 'sys', 'mysql', 'information_schema') and engine in ('myisam','innodb') group by table_schema, engine;" | jq . | sed ':a;N;$!ba;s/\n//g' | sed 's|}{|},{|g' | sed 's/^/[/g'| sed 's/$/]/g' | jq '.' ); innodb=""; myisam=""; for r in $(echo $json | jq 'keys | .[]'); do if [[ $(echo $json| jq .[$r].'dbschema') == *"MyISAM"* ]]; then nmyisam=$(echo $nmyisam || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; myisam=$(echo $myisam || echo '')$(echo $json| jq .[$r].'dbschema')','; else ninnodb=$(echo $ninnodb || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; innodb=$(echo $innodb || echo '')$(echo $json| jq .[$r].'dbschema')','; fi; done; myisam=$(echo $myisam|sed 's/,$//g'); nmyisam=$(echo $nmyisam|sed 's/,$//g'); innodb=$(echo $innodb|sed 's/,$//g');ninnodb=$(echo $ninnodb|sed 's/,$//g'); echo $myisam "|" $nmyisam; echo $innodb "|" $ninnodb; url=$(echo "{type:'bar',data:{labels:['MyISAM','InnoDB'],datasets:[{label:[$myisam],data:[$nmyisam]},{label:[$innodb],data:[$ninnodb]}]},options:{title:{display:true,text:'Database Schema Total Rows Graph',fontSize:20,}}}"); curl -L -o /vagrant/schema_change_mon/assets/db-${graph_ident}.png -g https://quickchart.io/chart?c=$(python -c "import urllib,os,sys; print urllib.quote(os.environ['url'])")
-
Enfin, allez dans le répertoire du chemin du module ou /etc/puppetlabs/code/environments /production dans ma configuration. Créons le fichier manifests/schema_change_mon.pp.
touch manifests/schema_change_mon.pp-
Remplissez ensuite le fichier manifests/schema_change_mon.pp avec le contenu suivant,
node 'pupnode16.puppet.local' { # Applies only to mentioned node. If nothing mentioned, applies to all.
class { 'schema_change_mon':
}
}
Si vous avez terminé, vous devriez avoir l'arborescence suivante, tout comme la mienne,
example@sqldat.com:/etc/puppetlabs/code/environments/production/modules# tree schema_change_mon
schema_change_mon
├── files
│ └── graphing_gen.sh
└── manifests
└── init.ppQue fait notre module ?
Notre module appelé schema_change_mon collecte les éléments suivants,
exec { "mysql-without-primary-key" :...
Qui exécute une commande mysql et exécute une requête pour récupérer des tables sans clés primaires. Ensuite,
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :qui collecte les index en double qui existent dans les tables de la base de données.
Ensuite, les lignes génèrent des graphiques basés sur les métriques collectées. Ce sont les lignes suivantes,
exec { "generate-graph-total-rows" :
...
exec { "generate-graph-total-len" :
…Une fois la requête exécutée avec succès, elle génère le graphique, qui dépend de l'API fournie par https://quickchart.io/.
Voici les résultats suivants du graphique :
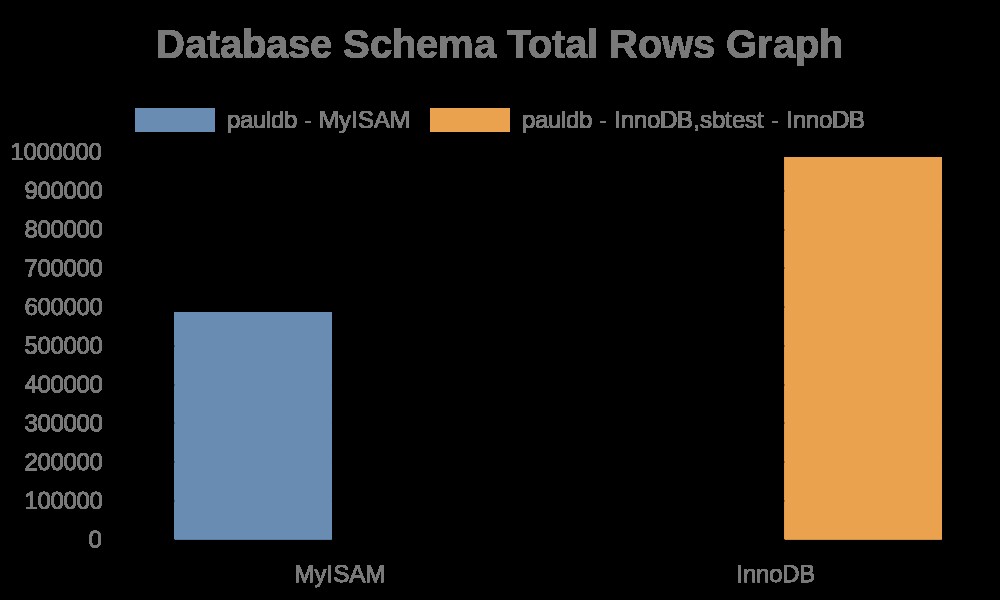
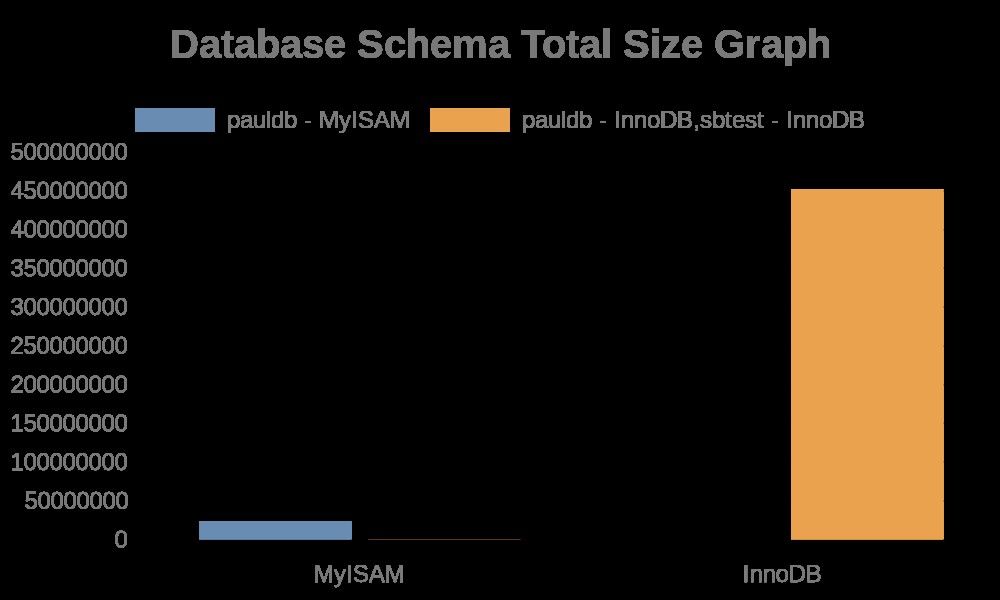
Alors que le fichier logs contient simplement des chaînes avec ses noms de table, des noms d'index. Voir le résultat ci-dessous,
example@sqldat.com:~# tail -n+1 /opt/schema_change_mon/assets/*.log
==> /opt/schema_change_mon/assets/dupe-indexes.log <==
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
==> /opt/schema_change_mon/assets/no-pk.log <==
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDBPourquoi ne pas utiliser ClusterControl ?
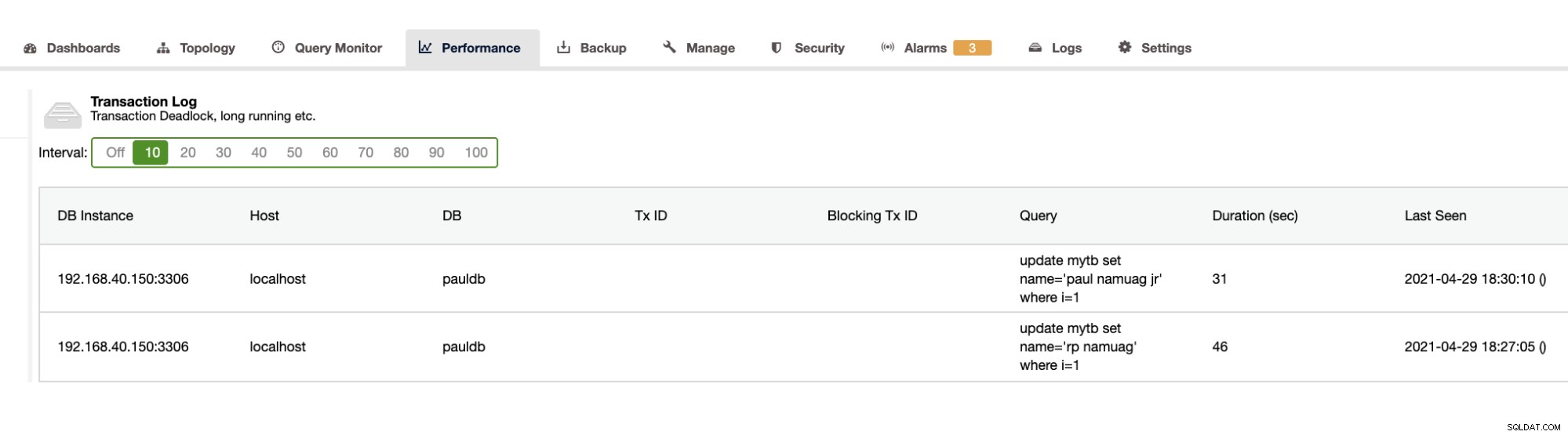
Comme notre exercice présente l'automatisation et l'obtention des statistiques du schéma de base de données telles que les modifications ou les opérations, ClusterControl le fournit également. Il existe également d'autres fonctionnalités à part cela et vous n'avez pas besoin de réinventer la roue. ClusterControl peut fournir les journaux de transactions tels que les blocages comme indiqué ci-dessus, ou les requêtes longues comme indiqué ci-dessous :
ClusterControl affiche également la croissance de la base de données comme indiqué ci-dessous,
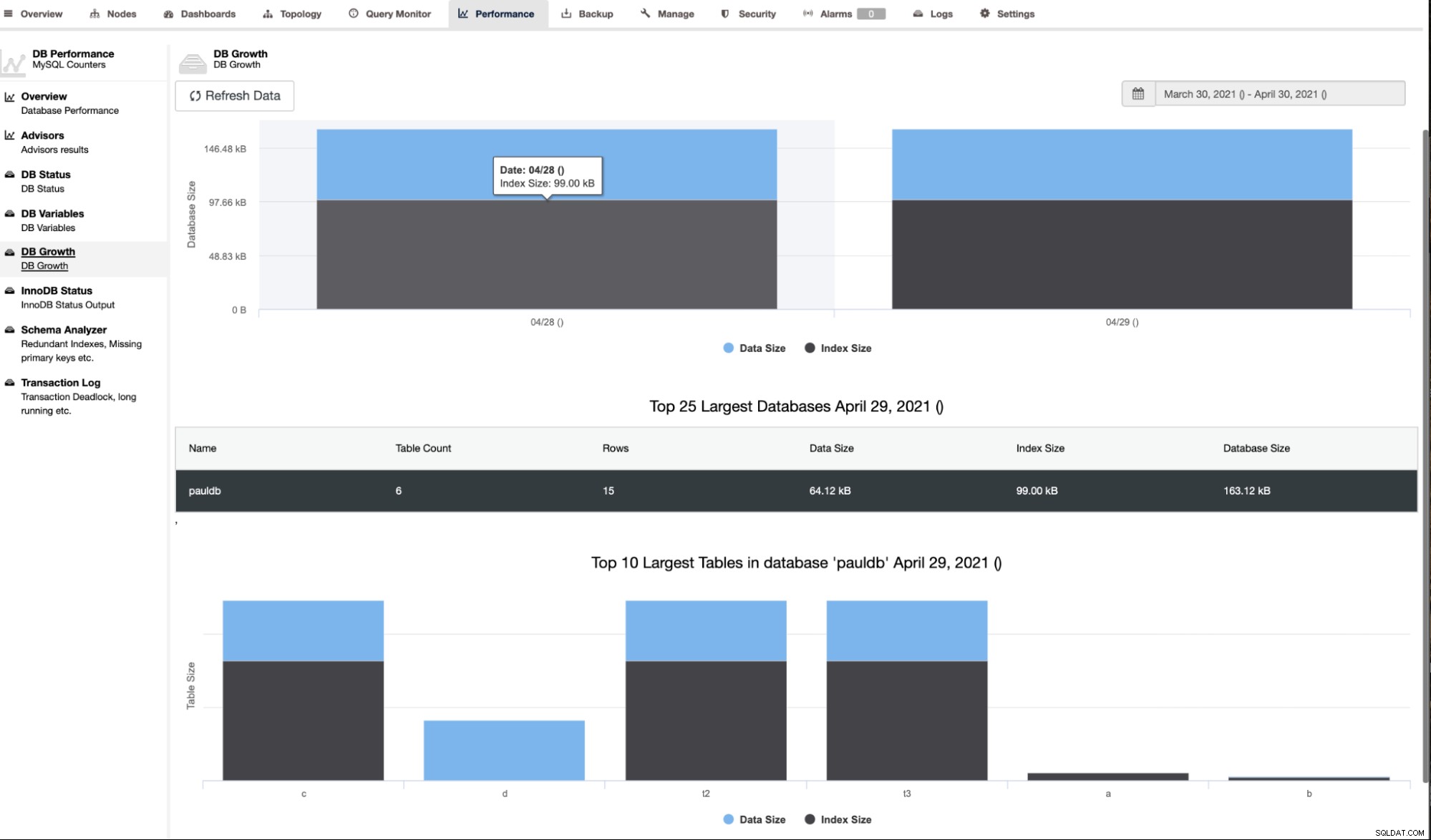
ClusterControl fournit également des informations supplémentaires telles que le nombre de lignes, la taille du disque, la taille de l'index et la taille totale.
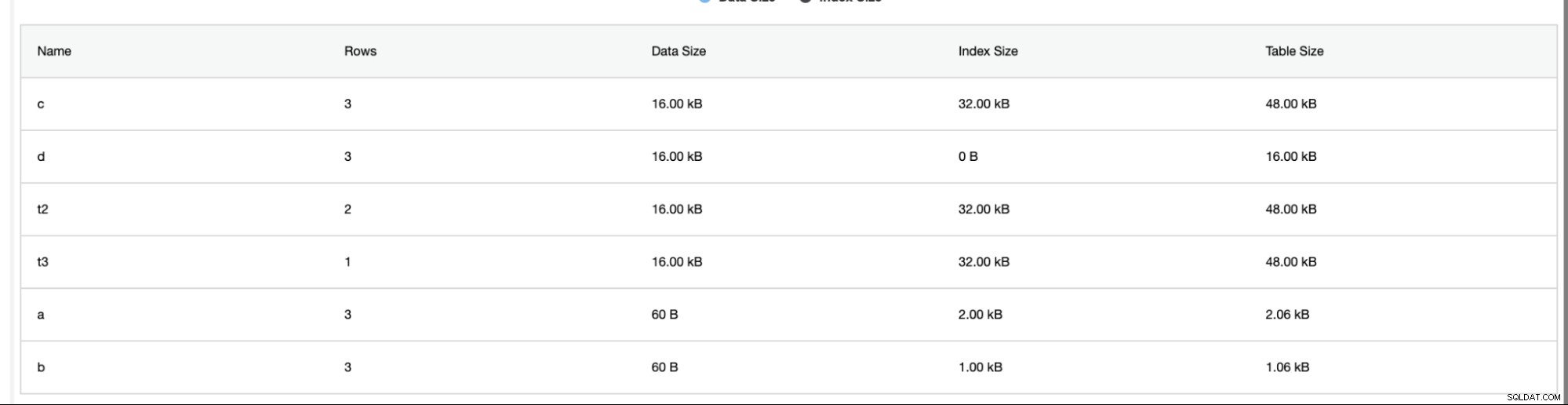
L'analyseur de schéma sous l'onglet Performances -> Analyseur de schéma est très utile. Il fournit des tables sans clés primaires, des tables MyISAM et des index en double,

Il fournit également des alarmes en cas de détection d'index ou de tables en double sans primaire touches telles que ci-dessous,

Vous pouvez consulter plus d'informations sur ClusterControl et ses autres fonctionnalités sur la page de notre produit.
Conclusion
Fournir une automatisation pour surveiller les modifications de votre base de données ou toutes les statistiques de schéma telles que les écritures, les index en double, les mises à jour des opérations telles que les modifications DDL et de nombreuses activités de base de données est très bénéfique pour les DBA. Cela aide à identifier rapidement les liens faibles et les requêtes problématiques qui vous donneraient un aperçu d'une cause possible de mauvaises requêtes qui bloqueraient votre base de données ou obsolèteraient votre base de données.



