Auteur invité :Michael J Swart (@MJSwart)
Je passe beaucoup de temps à traduire les exigences logicielles en schémas et en requêtes. Ces exigences sont parfois faciles à mettre en œuvre mais sont souvent difficiles. Je veux parler des choix de conception de l'interface utilisateur qui conduisent à des modèles d'accès aux données difficiles à implémenter à l'aide de SQL Server.
Trier par colonne
Sort-By-Column est un modèle si familier que nous pouvons le tenir pour acquis. Chaque fois que nous interagissons avec un logiciel qui affiche un tableau, nous pouvons nous attendre à ce que les colonnes puissent être triées comme ceci :
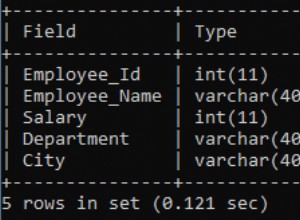
Sort-By-Colunn est un excellent modèle lorsque toutes les données peuvent tenir dans le navigateur. Mais si l'ensemble de données contient des milliards de lignes, cela peut devenir gênant même si la page Web ne nécessite qu'une seule page de données. Considérez ce tableau de chansons :
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); Et considérez ces quatre requêtes triées par colonne :
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
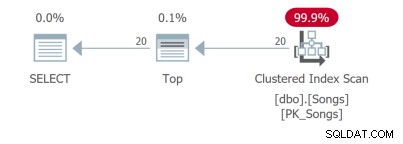
Même pour une requête aussi simple, il existe différents plans de requête. Les deux premières requêtes utilisent des index couvrants :
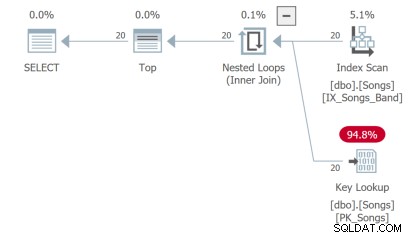
La troisième requête doit effectuer une recherche de clé, ce qui n'est pas idéal :
Mais le pire est la quatrième requête qui doit parcourir toute la table et faire un tri afin de retourner les 20 premières lignes :
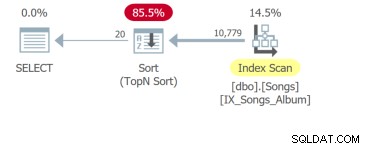
Le fait est que même si la seule différence est la clause ORDER BY, ces requêtes doivent être analysées séparément. L'unité de base du réglage SQL est la requête. Donc, si vous me montrez les exigences de l'interface utilisateur avec dix colonnes triables, je vous montrerai dix requêtes à analyser.
Quand cela devient-il gênant ?
La fonctionnalité Trier par colonne est un excellent modèle d'interface utilisateur, mais cela peut devenir gênant si les données proviennent d'une énorme table croissante avec de très nombreuses colonnes. Il peut être tentant de créer des index couvrants sur chaque colonne, mais cela a d'autres compromis. Les index columnstore peuvent aider dans certaines circonstances, mais cela introduit un autre niveau de maladresse. Il n'y a pas toujours d'alternative facile.
Résultats paginés
L'utilisation de résultats paginés est un bon moyen de ne pas submerger l'utilisateur avec trop d'informations à la fois. C'est aussi un bon moyen de ne pas submerger les serveurs de bases de données… généralement.
Considérez cette conception :

Les données sous-jacentes à cet exemple nécessitent de compter et de traiter l'intégralité de l'ensemble de données afin de rapporter le nombre de résultats. La requête de cet exemple peut utiliser une syntaxe comme celle-ci :
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
C'est une syntaxe pratique et la requête ne produit que 25 lignes. Mais ce n'est pas parce que l'ensemble de résultats est petit qu'il est nécessairement bon marché. Tout comme nous l'avons vu avec le modèle Trier par colonne, un opérateur TOP n'est bon marché que s'il n'a pas besoin de trier beaucoup de données en premier.
Demandes de page asynchrones
Lorsqu'un utilisateur navigue d'une page de résultats à l'autre, les requêtes Web impliquées peuvent être séparées par des secondes ou des minutes. Cela conduit à des problèmes qui ressemblent beaucoup aux pièges rencontrés lors de l'utilisation de NOLOCK. Par exemple :
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
Lorsqu'une ligne est ajoutée entre les deux requêtes, l'utilisateur peut voir la même ligne deux fois. Et si une ligne est supprimée, l'utilisateur peut manquer une ligne lorsqu'il navigue dans les pages. Ce modèle de résultats paginés équivaut à "Donnez-moi les lignes 26 à 50". Quand la vraie question devrait être "Donnez-moi les 25 prochaines lignes". La différence est subtile.
Meilleurs modèles
Avec les résultats paginés, ce "OFFSET @N ROWS" peut prendre de plus en plus de temps à mesure que @N grandit. Considérez plutôt les boutons Load-More ou Infinite-Scrolling. Avec la pagination Load-More, il y a au moins une chance d'utiliser efficacement un index. La requête ressemblerait à :
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
Il souffre toujours de certains des pièges des demandes de page asynchrones, mais à cause du signet, l'utilisateur reprendra là où il s'est arrêté.
Recherche de texte pour une sous-chaîne
La recherche est partout sur Internet. Mais quelle solution utiliser en back-end ? Je souhaite mettre en garde contre la recherche d'une sous-chaîne à l'aide du filtre LIKE de SQL Server avec des caractères génériques comme celui-ci :
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
Cela peut conduire à des résultats gênants comme celui-ci :
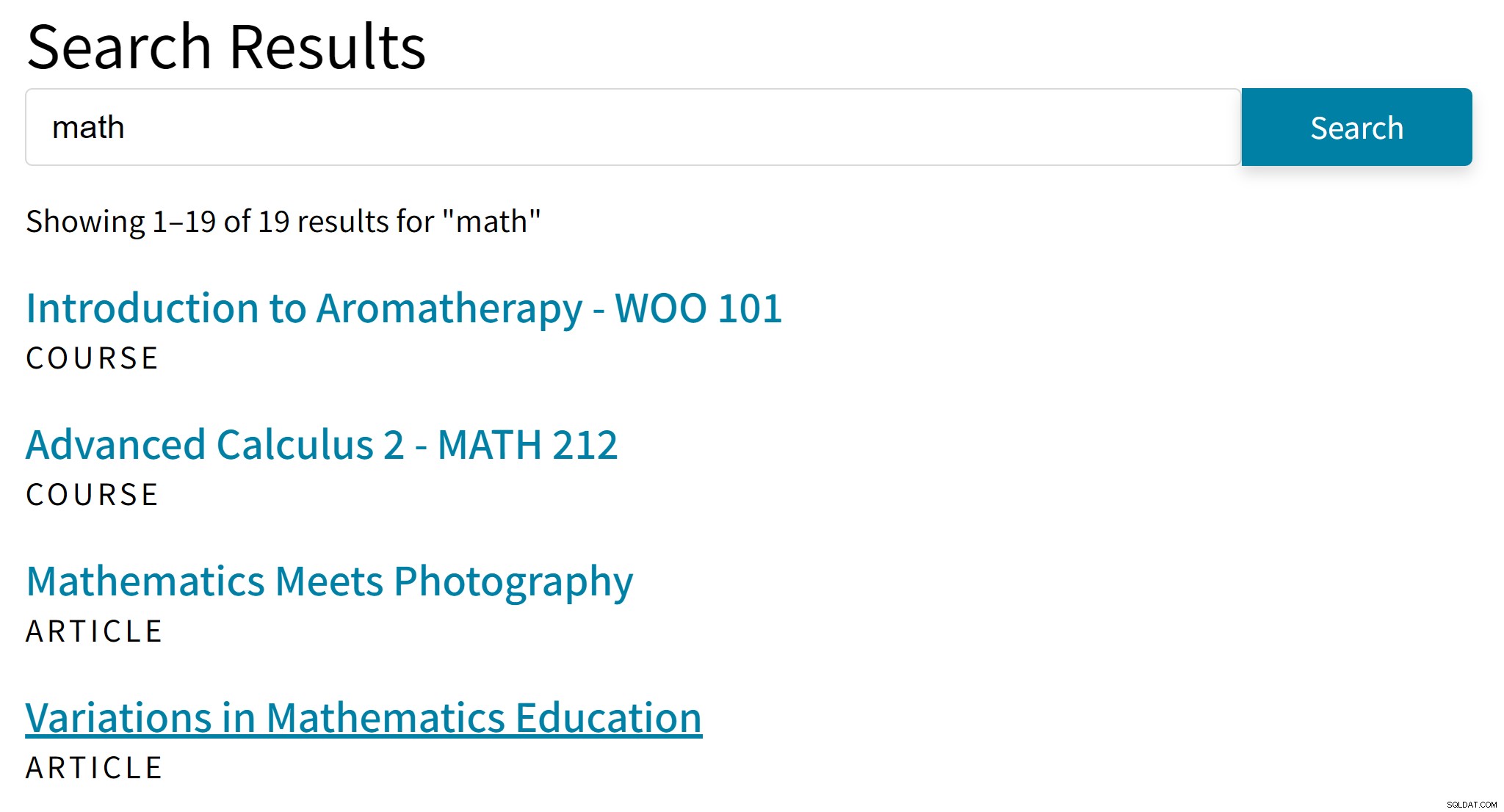
"Aromathérapie" n'est probablement pas un bon résultat pour le terme de recherche "maths". Pendant ce temps, les résultats de recherche manquent d'articles qui ne mentionnent que l'algèbre ou la trigonométrie.
Il peut également être très difficile de réussir efficacement avec SQL Server. Il n'y a pas d'index simple qui prend en charge ce type de recherche. Paul White a donné une solution délicate avec Trigram Wildcard String Search dans SQL Server. Des difficultés peuvent également survenir avec les classements et Unicode. Cela peut devenir une solution coûteuse pour une expérience utilisateur pas si bonne.
Qu'utiliser à la place
La recherche en texte intégral de SQL Server semble pouvoir aider, mais je ne l'ai personnellement jamais utilisée. En pratique, je n'ai vu le succès que dans des solutions en dehors de SQL Server (par exemple, Elasticsearch).
Conclusion
D'après mon expérience, j'ai constaté que les concepteurs de logiciels sont souvent très réceptifs aux commentaires selon lesquels leurs conceptions seront parfois difficiles à mettre en œuvre. Quand ce n'est pas le cas, j'ai trouvé utile de mettre en évidence les pièges, les coûts et les délais de livraison. Ce type de commentaires est nécessaire pour aider à créer des solutions maintenables et évolutives.
À propos de l'auteur
 Michael J Swart est un professionnel passionné des bases de données et un blogueur qui se concentre sur le développement de bases de données et l'architecture logicielle. Il aime parler de tout ce qui concerne les données, contribuer aux projets communautaires. Michael blogue en tant que "Database Whisperer" sur michaeljswart.com.
Michael J Swart est un professionnel passionné des bases de données et un blogueur qui se concentre sur le développement de bases de données et l'architecture logicielle. Il aime parler de tout ce qui concerne les données, contribuer aux projets communautaires. Michael blogue en tant que "Database Whisperer" sur michaeljswart.com.