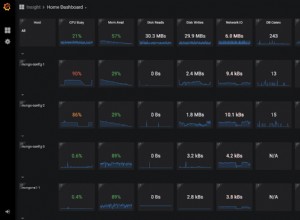
J'utilise Solr avec succès depuis près de 2 ans maintenant et je n'ai jamais utilisé Sphinx, donc je suis évidemment partial. Cependant, je vais essayer de rester objectif en citant les docs ou d'autres personnes. Je vais aussi apporter des correctifs à ma réponse :-)
Similitudes :
- Solr et Sphinx répondent à toutes vos exigences. Ils sont rapides et conçus pour indexer et rechercher efficacement de grandes quantités de données.
- Les deux ont une longue liste de sites à fort trafic qui les utilisent (Solr , Sphinx )
- Les deux proposent une assistance commerciale. (Solr , Sphinx )
- Les deux proposent des liaisons d'API client pour plusieurs plates-formes/langages (Sphinx , Solr )
- Les deux peuvent être distribués pour augmenter la vitesse et la capacité (Sphinx , Solr )
Voici quelques différences :
- Solr, étant un projet Apache, est évidemment sous licence Apache2. Sphinx est GPLv2 . Cela signifie que si jamais vous avez besoin d'intégrer ou d'étendre (pas seulement "d'utiliser") Sphinx dans une application commerciale, vous devrez acheter une licence commerciale (justification )
- Solr est facilement intégrable dans les applications Java.
- Solr repose sur Lucene, qui est une technologie éprouvée sur 8 ans avec un énorme base d'utilisateurs (ce n'est qu'une petite partie). Chaque fois que Lucene obtient une nouvelle fonctionnalité ou une accélération, Solr l'obtient également. De nombreux développeurs qui s'engagent pour Solr sont également des committers Lucene.
- Sphinx s'intègre plus étroitement aux SGBDR, en particulier MySQL.
- Solr peut être intégré à Hadoop pour créer des applications distribuées
- Solr peut être intégré à Nutch pour créer rapidement un moteur de recherche Web à part entière avec robot d'exploration .
- Solr peut indexer des formats propriétaires comme Microsoft Word, PDF, etc . Sphinx ne peut pas .
- Solr est livré avec un correcteur orthographique prêt à l'emploi .
- Solr est livré avec prise en charge des facettes prête à l'emploi . Le facettage dans Sphinx demande plus de travail .
- Sphinx n'autorise pas les mises à jour d'index partielles pour les données de champ .
- Dans Sphinx, tous les identifiants de document doivent être des entiers non nuls uniques non signés numéros . Solr ne nécessite même pas de clé unique pour de nombreuses opérations , et les clés uniques peuvent être des nombres entiers ou des chaînes.
- Solr prend en charge le l'effondrement des champs (actuellement en tant que patch supplémentaire uniquement) pour éviter de dupliquer des résultats similaires. Sphinx ne semble pas fournir de fonctionnalité de ce type.
- Alors que Sphinx est conçu pour récupérer uniquement les identifiants de documents , dans Solr, vous pouvez obtenir directement des documents entiers avec à peu près n'importe quel type de données, ce qui le rend plus indépendant de tout magasin de données externe et permet d'économiser l'aller-retour supplémentaire.
- Solr, sauf lorsqu'il est utilisé intégré, s'exécute dans un conteneur Web Java
tels que Tomcat ou Jetty, qui nécessitent une configuration et un réglage spécifiques supplémentaires
(ou vous pouvez utiliser la jetée incluse
et lancez-le simplement avec
java -jar start.jar). Sphinx n'a pas de configuration supplémentaire.
Questions connexes :
- Recherche de texte intégral avec Rails
- Comparaison des moteurs de recherche plein texte - Lucene, Sphinx, Postgresql, MySQL ?