La gestion d'une installation PostgreSQL implique l'inspection et le contrôle d'un large éventail d'aspects de la pile logicielle/infrastructure sur laquelle PostgreSQL s'exécute. Cela doit couvrir :
- Optimisation de l'application concernant l'utilisation/les transactions/les connexions de la base de données
- Code de la base de données (requêtes, fonctions)
- Système de base de données (performances, haute disponibilité, sauvegardes)
- Matériel/Infrastructure (disques, CPU/Mémoire)
Le noyau PostgreSQL fournit la couche de base de données sur laquelle nous faisons confiance à nos données pour être stockées, traitées et servies. Il fournit également toute la technologie pour avoir un système vraiment moderne, efficace, fiable et sécurisé. Mais souvent, cette technologie n'est pas disponible en tant que produit prêt à l'emploi et raffiné de classe entreprise dans la distribution principale de PostgreSQL. Au lieu de cela, il existe de nombreux produits/solutions de la communauté PostgreSQL ou des offres commerciales qui répondent à ces besoins. Ces solutions se présentent sous la forme d'améliorations conviviales des technologies de base, d'extensions des technologies de base ou même d'intégration entre les composants PostgreSQL et d'autres composants du système. Dans notre blog précédent intitulé Dix conseils pour passer en production avec PostgreSQL, nous avons examiné certains de ces outils qui peuvent aider à gérer une installation PostgreSQL en production. Dans ce blog, nous explorerons plus en détail les aspects qui doivent être couverts lors de la gestion d'une installation PostgreSQL en production, et les outils les plus couramment utilisés à cette fin. Nous aborderons les sujets suivants :
- Déploiement
- Gestion
- Mise à l'échelle
- Surveillance
Déploiement
Autrefois, les gens téléchargeaient et compilaient PostgreSQL à la main, puis configuraient les paramètres d'exécution et le contrôle d'accès des utilisateurs. Il y a encore des cas où cela pourrait être nécessaire, mais à mesure que les systèmes mûrissaient et commençaient à se développer, le besoin de moyens plus standardisés pour déployer et gérer Postgresql s'est fait sentir. La plupart des systèmes d'exploitation fournissent des packages pour installer, déployer et gérer les clusters PostgreSQL. Debian a standardisé sa propre disposition du système prenant en charge de nombreuses versions de Postgresql et de nombreux clusters par version en même temps. Le paquet debian postgresql-common fournit les outils nécessaires. Par exemple, pour créer un nouveau cluster (appelé i18n_cluster) pour PostgreSQL version 10 dans Debian, nous pouvons le faire en donnant les commandes suivantes :
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsPuis actualisez systemd :
$ sudo systemctl daemon-reloadet enfin démarrer et utiliser le nouveau cluster :
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(notez que Debian gère différents clusters en utilisant différents ports 5432, 5433, etc.)
Alors que le besoin augmente pour des déploiements plus automatisés et massifs, de plus en plus d'installations utilisent des outils d'automatisation comme Ansible, Chef et Puppet. Outre l'automatisation et la reproductibilité des déploiements, les outils d'automatisation sont excellents car ils constituent un bon moyen de documenter le déploiement et la configuration d'un cluster. D'autre part, l'automatisation a évolué pour devenir un vaste domaine à part entière, nécessitant des personnes qualifiées pour écrire, gérer et exécuter des scripts automatisés. Plus d'informations sur le provisionnement PostgreSQL peuvent être trouvées dans ce blog :Devenez un administrateur de base de données PostgreSQL :provisionnement et déploiement.
Gestion
La gestion d'un système en direct implique des tâches telles que :planifier les sauvegardes et surveiller leur état, la reprise après sinistre, la gestion de la configuration, la gestion de la haute disponibilité et la gestion automatique du basculement. La sauvegarde d'un cluster Postgresql peut être effectuée de différentes manières. Outils de bas niveau :
- pg_dump traditionnel (sauvegarde logique)
- sauvegardes au niveau du système de fichiers (sauvegarde physique)
- pg_basebackup (sauvegarde physique)
Ou niveau supérieur :
- Barman
- PgBackRest
Chacune de ces méthodes couvre différents cas d'utilisation et scénarios de récupération, et varie en complexité. La sauvegarde PostgreSQL est étroitement liée aux notions de PITR, d'archivage WAL et de réplication. Au fil des années, la procédure de prise, de test et enfin (croisons les doigts !) d'utilisation des sauvegardes avec PostgreSQL a évolué pour devenir une tâche complexe. On peut trouver un bon aperçu des solutions de sauvegarde pour PostgreSQL dans ce blog :Top Backup Tools for PostgreSQL.
En ce qui concerne la haute disponibilité et le basculement automatique, le strict minimum qu'une installation doit avoir pour mettre en œuvre ceci est :
- Un primaire qui fonctionne
- Un serveur de secours acceptant les WAL diffusés depuis le primaire
- En cas d'échec du primaire, une méthode pour dire au primaire qu'il n'est plus le primaire (parfois appelé STONITH)
- Un mécanisme de pulsation pour vérifier la connectivité entre les deux serveurs et la santé du serveur principal
- Une méthode pour effectuer le basculement (par exemple via la promotion pg_ctl ou le fichier déclencheur)
- Une procédure automatisée pour recréer l'ancien serveur principal en tant que nouveau serveur de secours :une fois qu'une interruption ou une panne sur le serveur principal est détectée, un serveur de secours doit être promu en tant que nouveau serveur principal. L'ancien primaire n'est plus valide ou utilisable. Le système doit donc avoir un moyen de gérer cet état entre le basculement et la recréation de l'ancien serveur principal en tant que nouveau serveur de secours. Cet état est appelé état dégénéré, et PostgreSQL fournit un outil appelé pg_rewind afin d'accélérer le processus de remise en état de synchronisation de l'ancien primaire à partir du nouveau primaire.
- Une méthode pour effectuer des basculements à la demande/planifiés
Un outil largement utilisé qui gère tout ce qui précède est Repmgr. Nous décrirons la configuration minimale qui permettra un basculement réussi. Nous commençons par un primaire PostgreSQL 10.4 fonctionnant sous FreeBSD 11.1, construit et installé manuellement, et repmgr 4.0 également construit et installé manuellement pour cette version (10.4). Nous utiliserons deux hôtes nommés fbsd (192.168.1.80) et fbsdclone (192.168.1.81) avec des versions identiques de PostgreSQL et repmgr. Sur le serveur principal (initialement fbsd , 192.168.1.80), nous nous assurons que les paramètres PostgreSQL suivants sont définis :
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' Ensuite, nous créons l'utilisateur repmgr (en tant que superutilisateur) et la base de données :
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgret configurez le contrôle d'accès basé sur l'hôte dans pg_hba.conf en plaçant les lignes suivantes en haut :
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustNous nous assurons de configurer une connexion sans mot de passe pour l'utilisateur repmgr dans tous les nœuds du cluster, dans notre cas fbsd et fbsdclone en définissant les clés autorisées dans .ssh, puis en partageant .ssh. Ensuite, nous créons repmrg.conf sur le primaire en tant que :
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Ensuite, nous enregistrons le principal :
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredEt vérifiez l'état du cluster :
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2Nous travaillons maintenant sur le standby en configurant repmgr.conf comme suit :
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Nous nous assurons également que le répertoire de données spécifié juste dans la ligne ci-dessus existe, est vide et dispose des autorisations correctes :
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataNous devons maintenant cloner vers notre nouvelle veille :
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"Et démarrez la mise en veille :
example@sqldat.com:~ % pg_ctl -D data startÀ ce stade, la réplication devrait fonctionner comme prévu, vérifiez cela en interrogeant pg_stat_replication (fbsd) et pg_stat_wal_receiver (fbsdclone). L'étape suivante consiste à enregistrer la veille :
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerNous pouvons maintenant obtenir l'état du cluster sur le standly ou le primaire et vérifier que le standby est enregistré :
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Supposons maintenant que nous souhaitions effectuer une commutation manuelle planifiée afin, par ex. pour effectuer un travail d'administration sur le nœud fbsd. Sur le nœud de secours, nous exécutons la commande suivante :
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyLe basculement a été exécuté avec succès ! Voyons ce que donne cluster show :
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Les deux serveurs ont échangé leurs rôles ! Repmgr fournit le démon repmgrd qui assure la surveillance, le basculement automatique, ainsi que les notifications/alertes. En combinant repmgrd avec pgbouncer, il est possible d'implémenter la mise à jour automatique des informations de connexion de la base de données, fournissant ainsi une clôture pour le nœud principal défaillant (empêchant le nœud défaillant de toute utilisation par l'application) ainsi qu'un temps d'arrêt minimal pour l'application. Dans des schémas plus complexes, une autre idée est de combiner Keepalived avec HAProxy en plus de pgbouncer et repmgr, afin d'obtenir :
- équilibrage de charge (mise à l'échelle)
- haute disponibilité
Notez que ClusterControl gère également le basculement des configurations de réplication PostgreSQL et intègre HAProxy et VirtualIP pour rediriger automatiquement les connexions client vers le maître de travail. Vous trouverez plus d'informations dans ce livre blanc sur l'automatisation de PostgreSQL.
Téléchargez le livre blanc aujourd'hui PostgreSQL Management &Automation with ClusterControlDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blancMise à l'échelle
Depuis PostgreSQL 10 (et 11), il n'y a toujours aucun moyen d'avoir une réplication multi-maître, du moins pas depuis le noyau PostgreSQL. Cela signifie que seule l'activité de sélection (lecture seule) peut être mise à l'échelle. La mise à l'échelle dans PostgreSQL est obtenue en ajoutant plus de serveurs de secours, fournissant ainsi plus de ressources pour l'activité en lecture seule. Avec repmgr, il est facile d'ajouter une nouvelle veille comme nous l'avons vu précédemment via clone de veille et registre de secours commandes. Les standby ajoutés (ou supprimés) doivent être signalés à la configuration du load-balancer. HAProxy, comme mentionné ci-dessus dans le sujet de gestion, est un équilibreur de charge populaire pour PostgreSQL. Habituellement, il est couplé à Keepalived qui fournit une adresse IP virtuelle via VRRP. Un bon aperçu de l'utilisation de HAProxy et Keepalived avec PostgreSQL peut être trouvé dans cet article :PostgreSQL Load Balancing Using HAProxy &Keepalived.
Surveillance
Un aperçu de ce qu'il faut surveiller dans PostgreSQL est disponible dans cet article :Eléments clés à surveiller dans PostgreSQL - Analyse de votre charge de travail. Il existe de nombreux outils qui peuvent fournir une surveillance du système et de postgresql via des plugins. Certains outils couvrent le domaine de la présentation graphique des valeurs historiques (munin), d'autres outils couvrent le domaine de la surveillance des données en direct et de la fourniture d'alertes en direct (nagios), tandis que certains outils couvrent les deux domaines (zabbix). Une liste de ces outils pour PostgreSQL peut être trouvée ici :https://wiki.postgresql.org/wiki/Monitoring. Un outil populaire pour la surveillance hors ligne (basée sur un fichier journal) est pgBadger. pgBadger est un script Perl qui fonctionne en parsant le journal PostgreSQL (qui couvre généralement l'activité d'une journée), en extrayant des informations, en calculant des statistiques et enfin en produisant une page html sophistiquée présentant les résultats. pgBadger n'est pas restrictif sur le paramètre log_line_prefix, il peut s'adapter à votre format déjà existant. Par exemple, si vous avez défini dans votre postgresql.conf quelque chose comme :
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'alors la commande pgbadger pour analyser le fichier journal et produire les résultats peut ressembler à :
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger fournit des rapports pour :
- Statistiques d'ensemble (principalement le trafic SQL)
- Connexions (par seconde, par base de données/utilisateur/hôte)
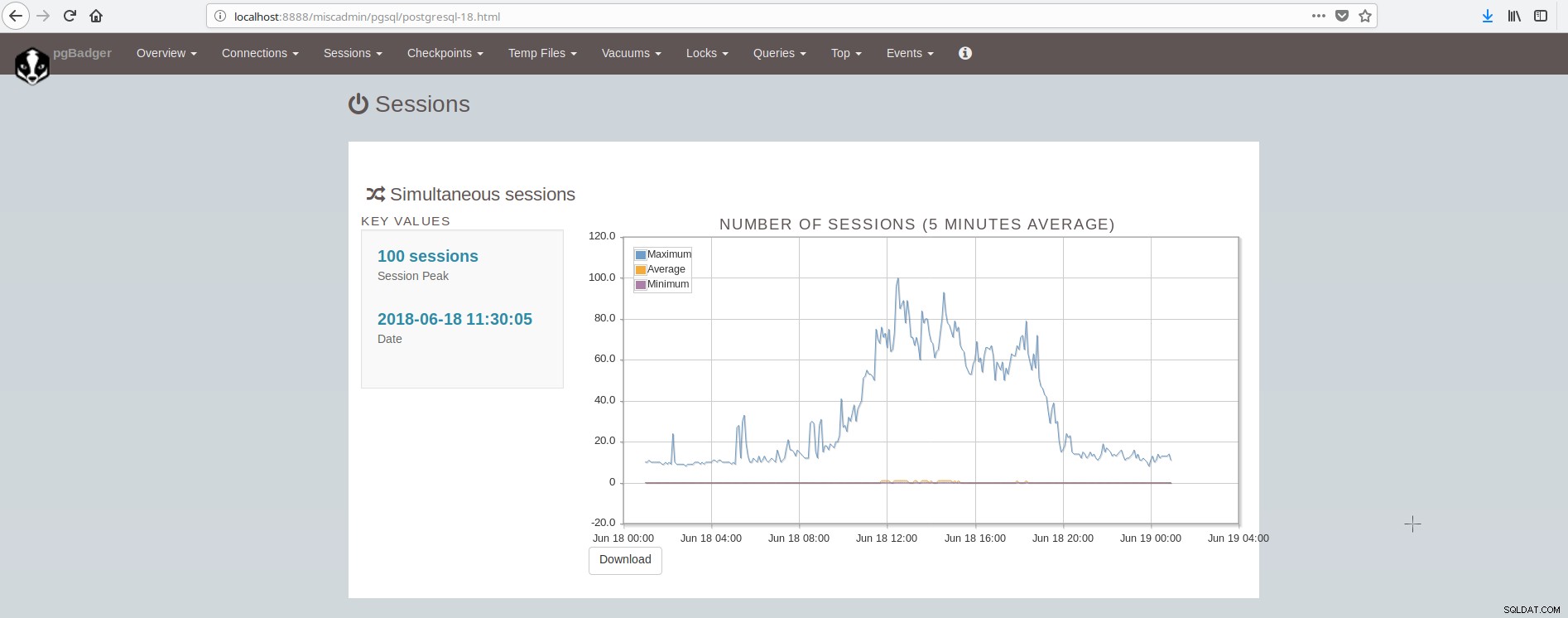
- Sessions (nombre, heures de session, par base de données/utilisateur/hôte/application)
- Points de contrôle (tampons, fichiers wal, activité)
- Utilisation des fichiers temporaires
- Vacuum/Analyser l'activité (par table, tuples/pages supprimés)
- Verrous
- Requêtes (par type/base de données/utilisateur/hôte/application, durée par utilisateur)
- Top (Requêtes :les plus lentes, les plus longues, les plus fréquentes, les plus lentes normalisées)
- Événements (Erreurs, Avertissements, Fatals, etc.)
L'écran montrant les sessions ressemble à :
Comme nous pouvons en conclure, l'installation moyenne de PostgreSQL doit intégrer et prendre en charge de nombreux outils afin d'avoir une infrastructure moderne, fiable et rapide et cela est assez complexe à réaliser, à moins qu'il y ait de grandes équipes impliquées dans postgresql et l'administration système. Une belle suite qui fait tout ce qui précède et plus encore est ClusterControl.