Bref résumé
- Les performances de la méthode des sous-requêtes dépendent de la distribution des données.
- Les performances de l'agrégation conditionnelle ne dépendent pas de la distribution des données.
La méthode des sous-requêtes peut être plus rapide ou plus lente que l'agrégation conditionnelle, cela dépend de la distribution des données.
Naturellement, si la table a un index approprié, les sous-requêtes sont susceptibles d'en bénéficier, car l'index permettrait de parcourir uniquement la partie pertinente de la table au lieu de l'analyse complète. Il est peu probable qu'un index approprié profite de manière significative à la méthode d'agrégation conditionnelle, car elle analysera de toute façon l'index complet. Le seul avantage serait que l'index soit plus étroit que la table et que le moteur doive lire moins de pages en mémoire.
Sachant cela, vous pouvez décider quelle méthode choisir.
Premier essai
J'ai créé une table de test plus grande, avec 5 millions de lignes. Il n'y avait pas d'index sur la table. J'ai mesuré les statistiques IO et CPU à l'aide de SQL Sentry Plan Explorer. J'ai utilisé SQL Server 2014 SP1-CU7 (12.0.4459.0) Express 64 bits pour ces tests.
En effet, vos requêtes d'origine se sont comportées comme vous l'avez décrit, c'est-à-dire que les sous-requêtes étaient plus rapides même si les lectures étaient 3 fois plus élevées.
Après quelques essais sur une table sans index, j'ai réécrit votre agrégat conditionnel et ajouté des variables pour contenir la valeur de DATEADD expressions.
Le temps global est devenu beaucoup plus rapide.
Puis j'ai remplacé SUM avec COUNT et c'est redevenu un peu plus rapide.
Après tout, l'agrégation conditionnelle est devenue à peu près aussi rapide que les sous-requêtes.
Réchauffer le cache (UC=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Sous-requêtes (UC=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
Agrégation conditionnelle d'origine (UC=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agrégation conditionnelle avec des variables (UC=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agrégation conditionnelle avec des variables et COUNT au lieu de SUM (UC=1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Sur la base de ces résultats, je suppose que CASE appelé DATEADD pour chaque ligne, tandis que WHERE était assez intelligent pour le calculer une fois. Plus COUNT est un tout petit peu plus efficace que SUM .
Au final, l'agrégation conditionnelle n'est que légèrement plus lente que les sous-requêtes (1062 vs 1031), peut-être parce que WHERE est un peu plus efficace que CASE en soi, et d'ailleurs, WHERE filtre pas mal de lignes, donc COUNT doit traiter moins de lignes.
En pratique, j'utiliserais l'agrégation conditionnelle, car je pense que le nombre de lectures est plus important. Si votre table est petite pour tenir et rester dans le pool de mémoire tampon, toute requête sera rapide pour l'utilisateur final. Mais, si la table est plus grande que la mémoire disponible, je m'attends à ce que la lecture à partir du disque ralentisse considérablement les sous-requêtes.
Deuxième essai
D'autre part, il est également important de filtrer les lignes le plus tôt possible.
Voici une légère variation du test, qui le démontre. Ici, j'ai défini le seuil sur GETDATE() + 100 ans, pour m'assurer qu'aucune ligne ne répond aux critères de filtre.
Réchauffer le cache (UC=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Sous-requêtes (UC=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
Agrégation conditionnelle d'origine (UC=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agrégation conditionnelle avec des variables (UC=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agrégation conditionnelle avec des variables et COUNT au lieu de SUM (UC=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
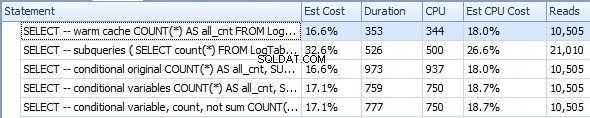
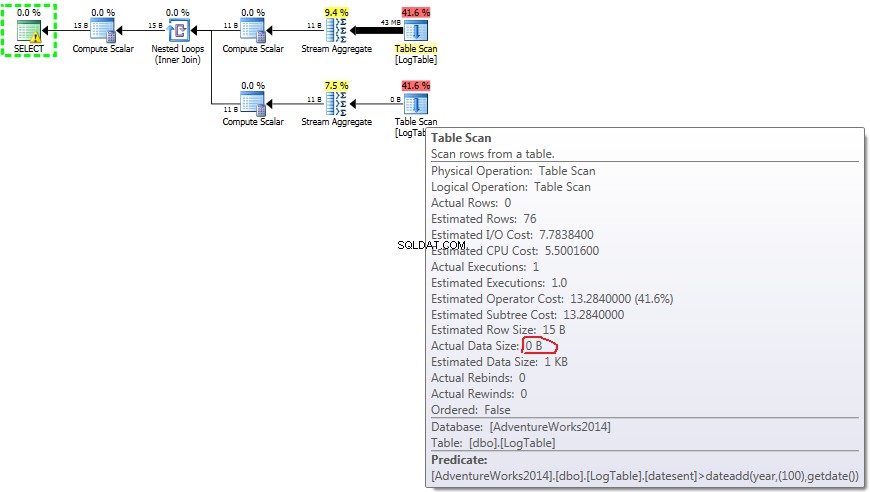
Vous trouverez ci-dessous un plan avec des sous-requêtes. Vous pouvez voir que 0 lignes sont entrées dans l'agrégat de flux dans la deuxième sous-requête, toutes ont été filtrées à l'étape d'analyse de la table.
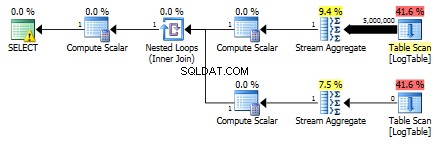
Par conséquent, les sous-requêtes sont à nouveau plus rapides.
Troisième essai
Ici j'ai changé les critères de filtrage du test précédent :tous > ont été remplacés par < . Par conséquent, le conditionnel COUNT compté toutes les lignes au lieu d'aucune. Surprise Surprise! La requête d'agrégation conditionnelle a pris les mêmes 750 ms, tandis que les sous-requêtes sont devenues 813 au lieu de 500.

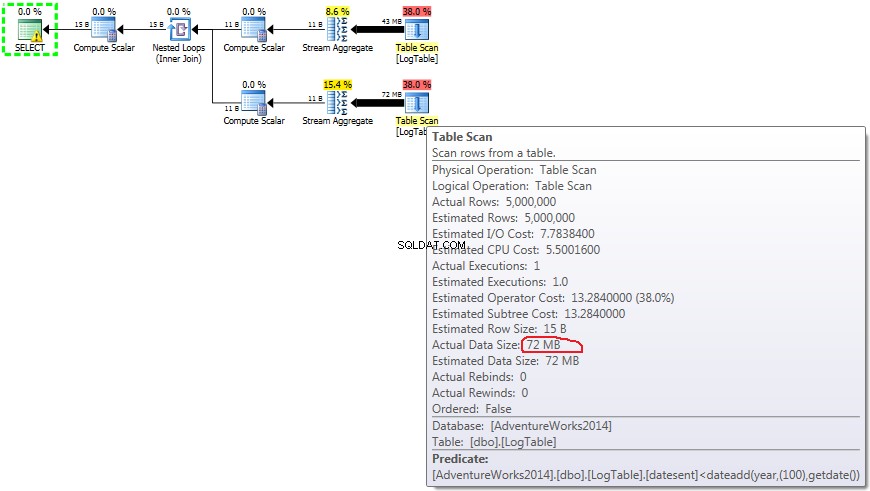
Voici le plan pour les sous-requêtes :
Pourriez-vous me donner un exemple, où l'agrégation conditionnelle surpasse considérablement la solution de sous-requête ?
C'est ici. Les performances de la méthode des sous-requêtes dépendent de la distribution des données. Les performances de l'agrégation conditionnelle ne dépendent pas de la distribution des données.
La méthode des sous-requêtes peut être plus rapide ou plus lente que l'agrégation conditionnelle, cela dépend de la distribution des données.
Sachant cela, vous pouvez décider quelle méthode choisir.
Détails des bonus
Si vous passez la souris sur le Table Scan opérateur, vous pouvez voir la Actual Data Size dans différentes variantes.
- Simple
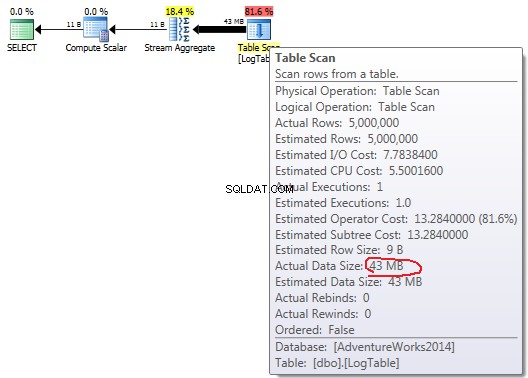
COUNT(*):
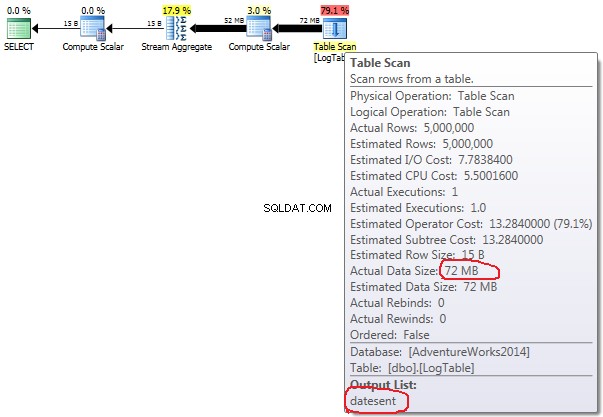
- Agrégation conditionnelle :
- Sous-requête dans le test 2 :
- Sous-requête dans le test 3 :
Maintenant, il devient clair que la différence de performances est probablement due à la différence de quantité de données qui transite par le plan.
En cas de simple COUNT(*) il n'y a pas de Output list (aucune valeur de colonne n'est nécessaire) et la taille des données est la plus petite (43 Mo).
En cas d'agrégation conditionnelle ce montant ne change pas entre les tests 2 et 3, il est toujours de 72Mo. Output list a une colonne datesent .
En cas de sous-requêtes, ce montant ne changer en fonction de la distribution des données.