Vos choix de types de données de serveur SQL et leurs tailles sont-ils importants ?
La réponse réside dans le résultat obtenu. Votre base de données a-t-elle gonflé en peu de temps ? Vos requêtes sont lentes ? Avez-vous eu les mauvais résultats ? Qu'en est-il des erreurs d'exécution lors des insertions et des mises à jour ?
Ce n'est pas tellement une tâche intimidante si vous savez ce que vous faites. Aujourd'hui, vous apprendrez les 5 pires choix que l'on puisse faire avec ces types de données. S'ils sont devenus une habitude chez vous, c'est la chose que nous devrions corriger pour vous et vos utilisateurs.
Beaucoup de types de données en SQL, beaucoup de confusion
Lorsque j'ai découvert les types de données SQL Server pour la première fois, les choix étaient écrasants. Tous les types sont mélangés dans mon esprit comme ce nuage de mots dans la figure 1 :

Cependant, nous pouvons l'organiser en catégories :
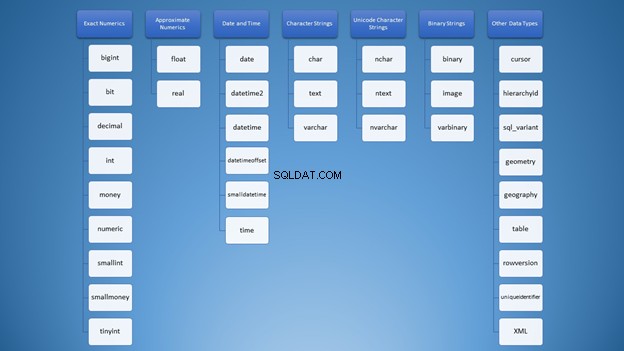
Pourtant, pour utiliser des chaînes, vous avez beaucoup d'options qui peuvent conduire à une mauvaise utilisation. Au début, je pensais que varchar et nvarchar étaient exactement les mêmes. De plus, ce sont tous deux des types de chaînes de caractères. L'utilisation des chiffres n'est pas différente. En tant que développeurs, nous devons savoir quel type utiliser dans différentes situations.
Mais vous vous demandez peut-être quelle est la pire chose qui puisse arriver si je fais le mauvais choix ? Laissez-moi vous dire !
1. Choisir les mauvais types de données SQL
Cet élément utilisera des chaînes et des nombres entiers pour prouver le point.
Utilisation du mauvais type de données SQL de chaîne de caractères
Tout d'abord, revenons aux cordes. Il y a cette chose appelée chaînes Unicode et non-Unicode. Les deux ont des tailles de stockage différentes. Vous définissez souvent cela sur les colonnes et les déclarations de variables.
La syntaxe est soit varchar (n)/caractère (n) ou nvarchar (n)/nchar (n) où n est la taille.
Notez que n n'est pas le nombre de caractères mais le nombre d'octets. C'est une idée fausse courante qui se produit parce que, dans varchar , le nombre de caractères est égal à la taille en octets. Mais pas dans nvarchar .
Pour prouver ce fait, créons 2 tables et insérons-y des données.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
Vérifions maintenant la taille de leurs lignes à l'aide de DATALENGTH.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
La figure 3 montre que la différence est double. Découvrez-le ci-dessous.
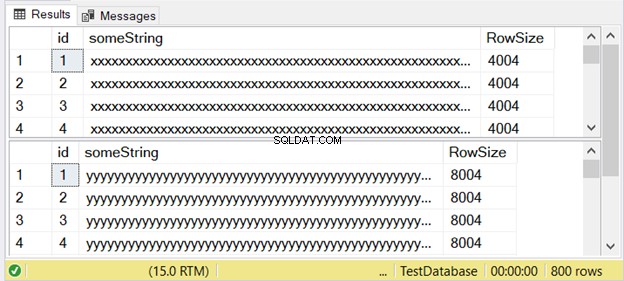
Remarquez le deuxième jeu de résultats avec une taille de ligne de 8004. Cela utilise le nvarchar Type de données. Elle est également presque deux fois plus grande que la taille de ligne du premier jeu de résultats. Et cela utilise le varchar type de données.
Vous voyez l'implication sur le stockage et les E/S. La figure 4 montre les lectures logiques des 2 requêtes.
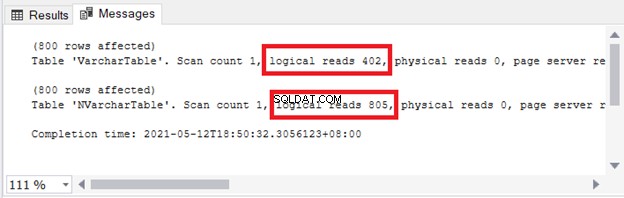
Voir? Les lectures logiques sont également doubles lors de l'utilisation de nvarchar comparé à varchar .
Ainsi, vous ne pouvez pas simplement utiliser chacun de manière interchangeable. Si vous avez besoin de stocker multilingue caractères, utilisez nvarchar . Sinon, utilisez varchar .
Cela signifie que si vous utilisez nvarchar pour les caractères à un octet uniquement (comme l'anglais), la taille de stockage est plus élevée . Les performances des requêtes sont également plus lentes avec des lectures logiques plus élevées.
Dans SQL Server 2019 (et versions ultérieures), vous pouvez stocker la gamme complète de données de caractères Unicode à l'aide de varchar ou caractère avec l'une des options de classement UTF-8.
Utilisation du mauvais type de données numériques SQL
Le même concept s'applique avec bigint vs int – leurs tailles peuvent signifier nuit et jour. Comme nvarchar et varchar , bigint est le double de la taille de int (8 octets pour bigint et 4 octets pour int ).
Pourtant, un autre problème est possible. Si leur taille ne vous dérange pas, des erreurs peuvent se produire. Si vous utilisez un int colonne et stocker un nombre supérieur à 2 147 483 647, un débordement arithmétique se produira :
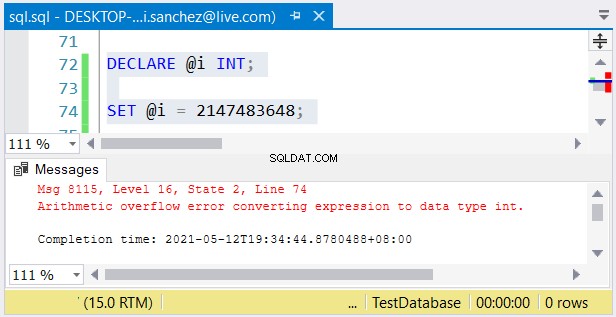
Lorsque vous choisissez des types de nombres entiers, assurez-vous que les données avec la valeur maximale conviendront . Par exemple, vous pouvez concevoir une table avec des données historiques. Vous envisagez d'utiliser des nombres entiers comme valeur de clé primaire. Pensez-vous qu'il n'atteindra pas 2 147 483 647 lignes ? Ensuite, utilisez int au lieu de bigint comme type de colonne de clé primaire.
La pire chose qui puisse arriver
Choisir les mauvais types de données peut affecter les performances des requêtes ou provoquer des erreurs d'exécution. Ainsi, choisissez le type de données qui convient aux données.
2. Création de grandes lignes de tableau à l'aide de types de données volumineuses pour SQL
Notre prochain article est lié au premier, mais il élargira encore plus le point avec des exemples. En outre, cela a quelque chose à voir avec les pages et les varchar de grande taille ou nvarchar colonnes.
Qu'en est-il des pages et des tailles de lignes ?
Le concept de pages dans SQL Server peut être comparé aux pages d'un cahier à spirale. Chaque page d'un bloc-notes a la même taille physique. Vous écrivez des mots et dessinez des images dessus. Si une page ne suffit pas pour un ensemble de paragraphes et d'images, vous passez à la page suivante. Parfois, vous déchirez aussi une page et recommencez.
De même, les données de table, les entrées d'index et les images dans SQL Server sont stockées dans des pages.
Une page a la même taille de 8 Ko. Si une ligne de données est très volumineuse, elle ne rentrera pas dans la page de 8 Ko. Une ou plusieurs colonnes seront écrites sur une autre page sous l'unité d'allocation ROW_OVERFLOW_DATA. Il contient un pointeur vers la ligne d'origine sur la page sous l'unité d'allocation IN_ROW_DATA.
Sur cette base, vous ne pouvez pas simplement insérer de nombreuses colonnes dans une table lors de la conception de la base de données. Il y aura des conséquences sur les E/S. De plus, si vous interrogez beaucoup sur ces données de dépassement de ligne, le temps d'exécution est plus lent . Cela peut être un cauchemar.
Un problème survient lorsque vous maximisez toutes les colonnes de tailles variables. Ensuite, les données passeront à la page suivante sous ROW_OVERFLOW_DATA. mettre à jour les colonnes avec des données de plus petite taille, et il doit être supprimé sur cette page. La nouvelle ligne de données plus petite sera écrite sur la page sous IN_ROW_DATA avec les autres colonnes. Imaginez les E/S impliquées ici.
Exemple de grande ligne
Préparons d'abord nos données. Nous utiliserons des types de données de chaîne de caractères avec de grandes tailles.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
Obtenir la taille de ligne
À partir des données générées, inspectons leurs tailles de ligne en fonction de DATALENGTH.
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
Les 300 premiers enregistrements conviendront aux pages IN_ROW_DATA car chaque ligne contient moins de 8060 octets ou 8 Ko. Mais les 100 dernières lignes sont trop grandes. Consultez le jeu de résultats de la figure 6.
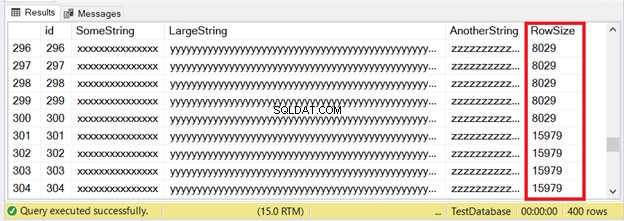
Vous voyez une partie des 300 premières lignes. Les 100 suivants dépassent la limite de taille de page. Comment savons-nous que les 100 dernières lignes se trouvent dans l'unité d'allocation ROW_OVERFLOW_DATA ?
Inspection des ROW_OVERFLOW_DATA
Nous utiliserons sys.dm_db_index_physical_stats . Il renvoie des informations de page sur les entrées de table et d'index.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
Le jeu de résultats est illustré à la figure 7.

Le voilà. La figure 7 montre 100 lignes sous ROW_OVERFLOW_DATA. Ceci est cohérent avec la figure 6 lorsque de grandes lignes existent en commençant par les lignes 301 à 400.
La question suivante est de savoir combien de lectures logiques nous obtenons lorsque nous interrogeons ces 100 lignes. Essayons.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

Nous voyons 102 lectures logiques et 100 lectures logiques lob de LargeTable . Laissez ces chiffres pour le moment - nous les comparerons plus tard.
Voyons maintenant ce qui se passe si nous mettons à jour les 100 lignes avec des données plus petites.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
Cette instruction de mise à jour a utilisé les mêmes lectures logiques et lectures logiques lob que dans la figure 8. À partir de là, nous savons que quelque chose de plus important s'est produit en raison des lectures logiques lob de 100 pages.
Mais pour être sûr, vérifions-le avec sys.dm_db_index_physical_stats comme nous l'avons fait plus tôt. La figure 9 montre le résultat :

Disparu! Les pages et les lignes de ROW_OVERFLOW_DATA sont devenues nulles après la mise à jour de 100 lignes avec des données plus petites. Nous savons maintenant que le déplacement des données de ROW_OVERFLOW_DATA vers IN_ROW_DATA se produit lorsque de grandes lignes sont réduites. Imaginez si cela se produit souvent pour des milliers, voire des millions d'enregistrements. Fou, n'est-ce pas ?
Dans la figure 8, nous avons vu 100 lectures logiques lob. Maintenant, voir la figure 10 après avoir réexécuté la requête :

C'est devenu nul !
La pire chose qui puisse arriver
La lenteur des performances des requêtes est le sous-produit des données de dépassement de ligne. Envisagez de déplacer la ou les colonnes de grande taille vers une autre table pour l'éviter. Ou, le cas échéant, réduisez la taille du varchar ou nvarchar colonne.
3. Utiliser aveuglément la conversion implicite
SQL ne nous permet pas d'utiliser des données sans spécifier le type. Mais c'est pardonner si on fait un mauvais choix. Il essaie de convertir la valeur dans le type qu'il attend, mais avec une pénalité. Cela peut se produire dans une clause WHERE ou JOIN.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
Le numéro de carte colonne n'est pas un type numérique. C'est nvarchar . Ainsi, le premier SELECT provoquera une conversion implicite. Cependant, les deux fonctionneront parfaitement et produiront le même ensemble de résultats.
Vérifions le plan d'exécution de la figure 11.
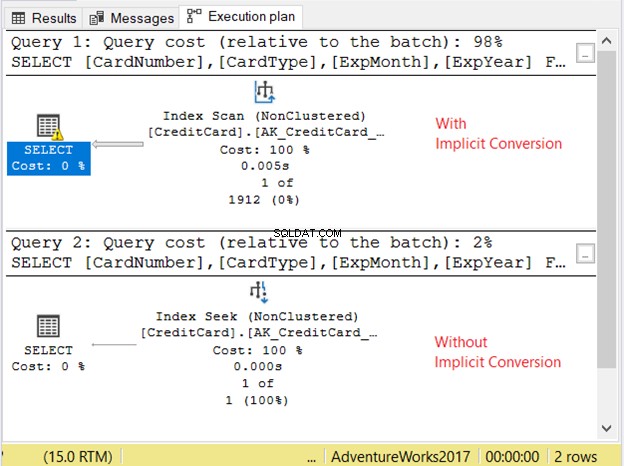
Les 2 requêtes ont été exécutées très rapidement. Dans la figure 11, c'est zéro seconde. Mais regardez les 2 plans. Celui avec conversion implicite avait un parcours d'index. Il y a aussi une icône d'avertissement et une grosse flèche pointant vers l'opérateur SELECT. Il nous dit que c'est mauvais.
Mais cela ne s'arrête pas là. Si vous passez votre souris sur l'opérateur SELECT, vous verrez autre chose :

L'icône d'avertissement dans l'opérateur SELECT concerne la conversion implicite. Mais quelle est l'ampleur de l'impact ? Vérifions les lectures logiques.
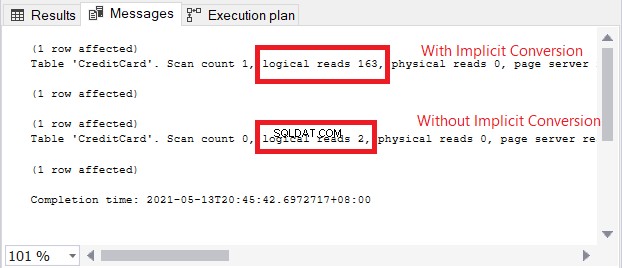
La comparaison des lectures logiques dans la figure 13 est comme le ciel et la terre. Dans la requête d'informations de carte de crédit, la conversion implicite a provoqué plus d'une centaine de lectures logiques. Très mauvais !
La pire chose qui puisse arriver
Si une conversion implicite entraînait des lectures logiques élevées et un mauvais plan, attendez-vous à un ralentissement des performances des requêtes sur des ensembles de résultats volumineux. Pour éviter cela, utilisez le type de données exact dans la clause WHERE et les JOIN pour faire correspondre les colonnes que vous comparez.
4. Utiliser des nombres approximatifs et les arrondir
Vérifiez à nouveau la figure 2. Les types de données du serveur SQL appartenant aux valeurs numériques approximatives sont flottant et réel . Les colonnes et les variables qui en sont constituées stockent une approximation proche d'une valeur numérique. Si vous envisagez d'arrondir ces chiffres vers le haut ou vers le bas, vous pourriez avoir une grosse surprise. J'ai un article qui en parle en détail ici. Découvrez comment 1 + 1 donne 3 et comment vous pouvez gérer les nombres arrondis.
La pire chose qui puisse arriver
Arrondir un flottant ou réel peut avoir des résultats fous. Si vous voulez des valeurs exactes après arrondi, utilisez décimal ou numérique à la place.
5. Définition des types de données de chaîne de taille fixe sur NULL
Portons notre attention sur les types de données de taille fixe comme char et nchar . Mis à part les espaces rembourrés, les définir sur NULL aura toujours une taille de stockage égale à la taille du char colonne. Donc, définir un char (500) la colonne à NULL aura une taille de 500, pas zéro ou 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
Dans le code ci-dessus, les données sont maximisées en fonction de la taille de char et varchar Colonnes. La vérification de leur taille de ligne à l'aide de DATALENGTH affichera également la somme des tailles de chaque colonne. Maintenant, définissons les colonnes sur NULL.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
Ensuite, nous interrogeons les lignes à l'aide de DATALENGTH :
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
Selon vous, quelles seront les tailles de données de chaque colonne ? Consultez la figure 14.
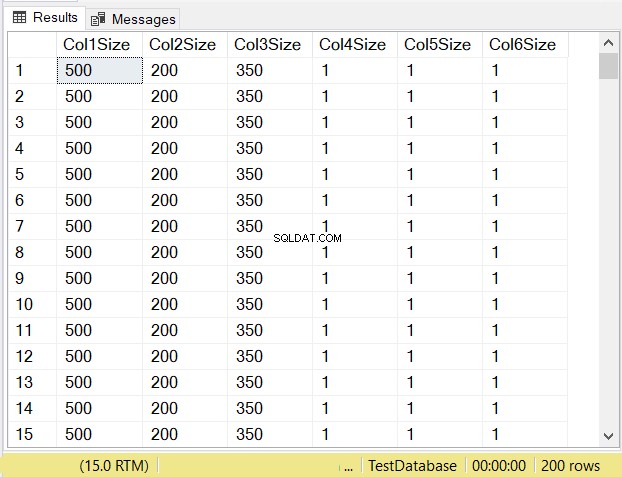
Regardez les tailles de colonne des 3 premières colonnes. Comparez-les ensuite au code ci-dessus lors de la création de la table. La taille des données des colonnes NULL est égale à la taille de la colonne. Pendant ce temps, le varchar les colonnes lorsque NULL ont une taille de données de 1.
La pire chose qui puisse arriver
Lors de la conception des tables, nullable char les colonnes, lorsqu'elles sont définies sur NULL, auront toujours la même taille de stockage. Ils consommeront également les mêmes pages et RAM. Si vous ne remplissez pas toute la colonne avec des caractères, pensez à utiliser varchar à la place.
Quelle est la prochaine ?
Alors, vos choix dans les types de données du serveur SQL et leurs tailles sont-ils importants ? Les points présentés ici devraient être suffisants pour faire un point. Alors, que pouvez-vous faire maintenant ?
- Prenez le temps d'examiner la base de données que vous utilisez. Commencez par le plus facile si vous en avez plusieurs dans votre assiette. Et oui, prenez le temps, ne trouvez pas le temps. Dans notre métier, il est presque impossible de trouver le temps.
- Passez en revue les tables, les procédures stockées et tout ce qui concerne les types de données. Notez l'impact positif lors de l'identification des problèmes. Vous en aurez besoin lorsque votre patron vous demandera pourquoi vous devez travailler là-dessus.
- Prévoyez d'attaquer chacune des zones problématiques. Suivez les méthodologies ou politiques mises en place par votre entreprise pour résoudre les problèmes.
- Une fois les problèmes résolus, célébrez.
Cela semble facile, mais nous savons tous que ce n'est pas le cas. Nous savons également qu'il y a un bon côté à la fin du voyage. C'est pourquoi ils sont appelés problèmes - parce qu'il y a une solution. Alors, réjouissez-vous.
Avez-vous autre chose à ajouter sur ce sujet ? Faites le nous savoir dans la section "Commentaires. Et si cet article vous a donné une idée brillante, partagez-la sur vos plateformes de réseaux sociaux préférées.



