Historiquement, la tâche la plus difficile lorsque vous travaillez avec PostgreSQL a été de gérer les mises à niveau. Le moyen de mise à niveau le plus intuitif auquel vous pouvez penser est de générer une réplique dans une nouvelle version et d'y effectuer un basculement de l'application. Avec PostgreSQL, ce n'était tout simplement pas possible de manière native. Pour effectuer des mises à niveau, vous deviez penser à d'autres moyens de mise à niveau, tels que l'utilisation de pg_upgrade, le vidage et la restauration, ou l'utilisation d'outils tiers comme Slony ou Bucardo, chacun ayant ses propres mises en garde.
Pourquoi était-ce? En raison de la façon dont PostgreSQL implémente la réplication.
La réplication en continu intégrée de PostgreSQL est ce qu'on appelle physique :elle répliquera les modifications au niveau octet par octet, créant une copie identique de la base de données sur un autre serveur. Cette méthode présente de nombreuses limites lorsque vous envisagez une mise à niveau, car vous ne pouvez tout simplement pas créer une réplique dans une version de serveur différente ou même dans une architecture différente.
C'est donc ici que PostgreSQL 10 change la donne. Avec ces nouvelles versions 10 et 11, PostgreSQL implémente la réplication logique intégrée qui, contrairement à la réplication physique, vous pouvez répliquer entre différentes versions majeures de PostgreSQL. Ceci, bien sûr, ouvre une nouvelle porte pour la mise à niveau des stratégies.
Dans ce blog, voyons comment nous pouvons mettre à niveau notre PostgreSQL 10 vers PostgreSQL 11 sans temps d'arrêt en utilisant la réplication logique. Tout d'abord, passons en revue une introduction à la réplication logique.
Qu'est-ce que la réplication logique ?
La réplication logique est une méthode de réplication des objets de données et de leurs modifications, basée sur leur identité de réplication (généralement une clé primaire). Il est basé sur un mode de publication et d'abonnement, où un ou plusieurs abonnés s'abonnent à une ou plusieurs publications sur un nœud d'éditeur.
Une publication est un ensemble de modifications générées à partir d'une table ou d'un groupe de tables (également appelé jeu de réplication). Le nœud où une publication est définie est appelé éditeur. Un abonnement est le côté aval de la réplication logique. Le nœud où un abonnement est défini est appelé l'abonné, et il définit la connexion à une autre base de données et un ensemble de publications (une ou plusieurs) auxquelles il souhaite s'abonner. Les abonnés extraient les données des publications auxquelles ils sont abonnés.
La réplication logique est construite avec une architecture similaire à la réplication physique en continu. Il est implémenté par les processus "walsender" et "apply". Le processus walsender lance le décodage logique du WAL et charge le plugin de décodage logique standard. Le plugin transforme les modifications lues depuis WAL vers le protocole de réplication logique et filtre les données en fonction de la spécification de publication. Les données sont ensuite transférées en continu à l'aide du protocole de réplication en continu vers le travailleur d'application, qui mappe les données sur des tables locales et applique les modifications individuelles au fur et à mesure de leur réception, dans un ordre transactionnel correct.
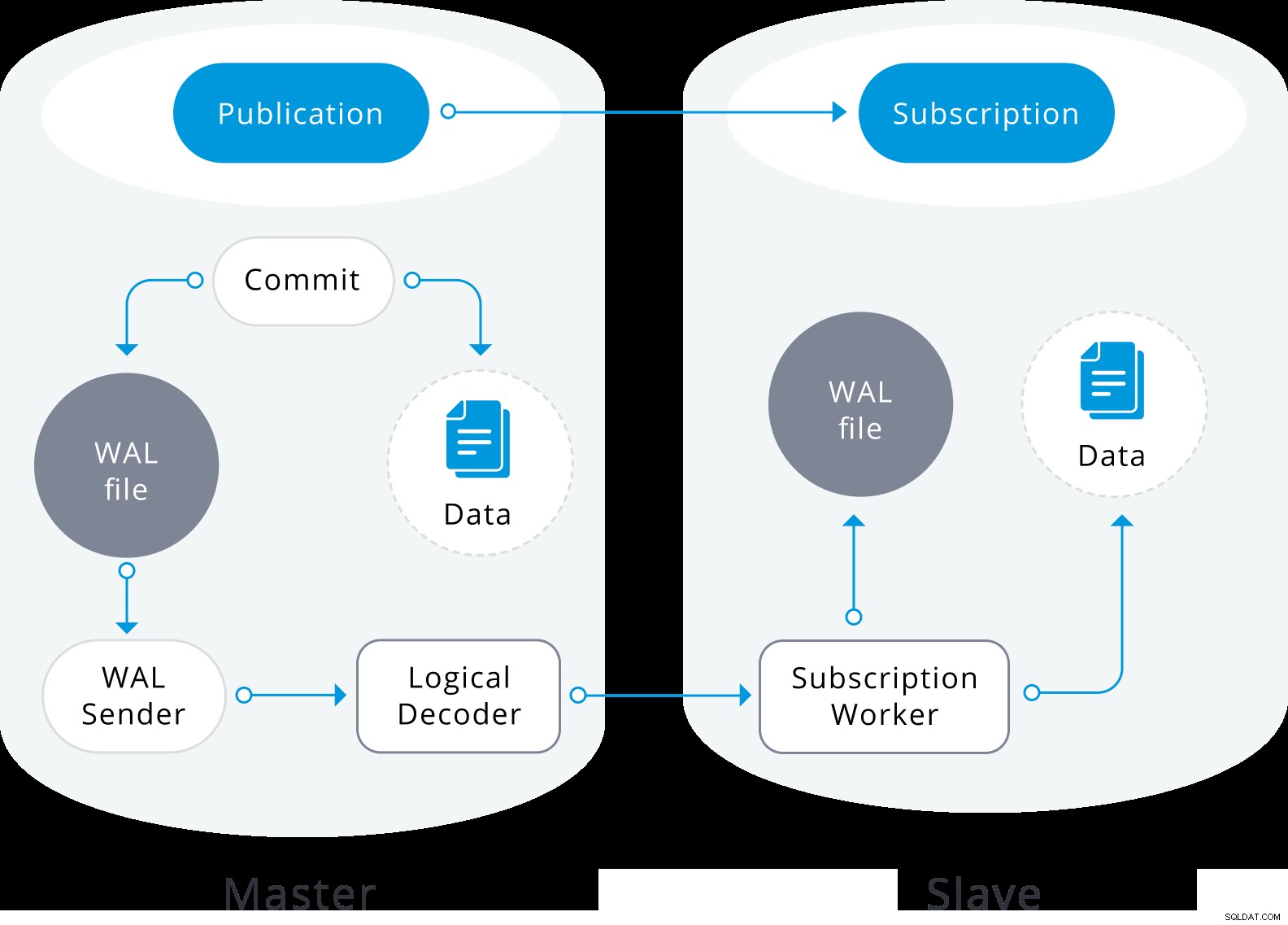 Diagramme de réplication logique
Diagramme de réplication logique La réplication logique commence par prendre un instantané des données sur la base de données de l'éditeur et le copier sur l'abonné. Les données initiales des tables souscrites existantes sont prises en instantané et copiées dans une instance parallèle d'un type spécial de processus d'application. Ce processus créera son propre emplacement de réplication temporaire et copiera les données existantes. Une fois les données existantes copiées, l'agent passe en mode de synchronisation, ce qui garantit que la table est mise à un état synchronisé avec le processus d'application principal en diffusant en continu toutes les modifications survenues lors de la copie initiale des données à l'aide de la réplication logique standard. Une fois la synchronisation effectuée, le contrôle de la réplication de la table est rendu au processus d'application principal où la réplication se poursuit normalement. Les modifications apportées à l'éditeur sont envoyées à l'abonné au fur et à mesure qu'elles se produisent en temps réel.
Vous pouvez en savoir plus sur la réplication logique dans les blogs suivants :
- Un aperçu de la réplication logique dans PostgreSQL
- Réplication en continu PostgreSQL vs réplication logique
Comment mettre à niveau PostgreSQL 10 vers PostgreSQL 11 à l'aide de la réplication logique
Donc, maintenant que nous savons en quoi consiste cette nouvelle fonctionnalité, nous pouvons réfléchir à la manière dont nous pouvons l'utiliser pour résoudre le problème de mise à niveau.
Nous allons configurer la réplication logique entre deux versions majeures différentes de PostgreSQL (10 et 11), et bien sûr, après que cela fonctionne, il ne s'agit que d'effectuer un basculement de l'application dans la base de données avec la version la plus récente.
Nous allons effectuer les étapes suivantes pour faire fonctionner la réplication logique :
- Configurer le nœud de l'éditeur
- Configurer le nœud d'abonné
- Créer l'utilisateur abonné
- Créer une publication
- Créer la structure de la table dans l'abonné
- Créer l'abonnement
- Vérifiez l'état de la réplication
Alors commençons.
Côté éditeur, nous allons configurer les paramètres suivants dans le fichier postgresql.conf :
- listen_addresses :sur quelle(s) adresse(s) IP écouter. Nous utiliserons '*' pour tous.
- wal_level :détermine la quantité d'informations écrites dans le WAL. Nous allons le définir sur logique.
- max_replication_slots :spécifie le nombre maximal d'emplacements de réplication que le serveur peut prendre en charge. Il doit être défini sur au moins le nombre d'abonnements censés se connecter, plus une réserve pour la synchronisation des tables.
- max_wal_senders :spécifie le nombre maximal de connexions simultanées à partir de serveurs de secours ou de clients de sauvegarde de base en continu. Il doit être au moins égal à max_replication_slots plus le nombre de répliques physiques connectées en même temps.
Gardez à l'esprit que certains de ces paramètres nécessitaient un redémarrage du service PostgreSQL pour s'appliquer.
Le fichier pg_hba.conf doit également être ajusté pour permettre la réplication. Nous devons autoriser l'utilisateur de réplication à se connecter à la base de données.
Sur cette base, configurons donc notre éditeur (dans ce cas, notre serveur PostgreSQL 10) comme suit :
- postgresql.conf :
listen_addresses = '*' wal_level = logical max_wal_senders = 8 max_replication_slots = 4 - pg_hba.conf :
# TYPE DATABASE USER ADDRESS METHOD host all rep 192.168.100.144/32 md5
Nous devons changer l'utilisateur (dans notre exemple rep), qui sera utilisé pour la réplication, et l'adresse IP 192.168.100.144/32 pour l'IP qui correspond à notre PostgreSQL 11.
Du côté de l'abonné, il faut également que max_replication_slots soit défini. Dans ce cas, il doit être défini au moins sur le nombre d'abonnements qui seront ajoutés à l'abonné.
Les autres paramètres qui doivent également être définis ici sont :
- max_logical_replication_workers :spécifie le nombre maximal de travailleurs de réplication logique. Cela inclut à la fois les agents d'application et les agents de synchronisation de table. Les agents de réplication logique sont extraits du pool défini par max_worker_processes. Il doit être défini au moins sur le nombre d'abonnements, plus une réserve pour la synchronisation des tables.
- max_worker_processes :définit le nombre maximal de processus d'arrière-plan que le système peut prendre en charge. Il peut être nécessaire de l'ajuster pour s'adapter aux agents de réplication, au moins max_logical_replication_workers + 1. Ce paramètre nécessite un redémarrage de PostgreSQL.
Nous devons donc configurer notre abonné (dans ce cas notre serveur PostgreSQL 11) comme suit :
- postgresql.conf :
listen_addresses = '*' max_replication_slots = 4 max_logical_replication_workers = 4 max_worker_processes = 8
Comme ce PostgreSQL 11 sera bientôt notre nouveau maître, nous devrions envisager d'ajouter les paramètres wal_level et archive_mode dans cette étape, pour éviter un nouveau redémarrage du service plus tard.
wal_level = logical
archive_mode = onCes paramètres seront utiles si nous voulons ajouter un nouvel esclave de réplication ou pour utiliser des sauvegardes PITR.
Dans l'éditeur, il faut créer l'utilisateur avec lequel notre abonné va se connecter :
world=# CREATE ROLE rep WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLELe rôle utilisé pour la connexion de réplication doit avoir l'attribut REPLICATION. L'accès pour le rôle doit être configuré dans pg_hba.conf et il doit avoir l'attribut LOGIN.
Afin de pouvoir copier les données initiales, le rôle utilisé pour la connexion de réplication doit avoir le privilège SELECT sur une table publiée.
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep;
GRANTNous allons créer la publication pub1 dans le nœud de l'éditeur, pour toutes les tables :
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONL'utilisateur qui créera une publication doit avoir le privilège CREATE dans la base de données, mais pour créer une publication qui publie automatiquement toutes les tables, l'utilisateur doit être un superutilisateur.
Pour confirmer la publication créée nous allons utiliser le catalogue pg_publication. Ce catalogue contient des informations sur toutes les publications créées dans la base de données.
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+------
pubname | pub1
pubowner | 16384
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | tDescription des colonnes :
- pubname :nom de la publication.
- pubowner :propriétaire de la publication.
- puballtables :si true, cette publication inclut automatiquement toutes les tables de la base de données, y compris celles qui seront créées ultérieurement.
- pubinsert :si true, les opérations INSERT sont répliquées pour les tables de la publication.
- pubupdate :si true, les opérations UPDATE sont répliquées pour les tables de la publication.
- pubdelete :si true, les opérations DELETE sont répliquées pour les tables de la publication.
Comme le schéma n'est pas répliqué, nous devons faire une sauvegarde dans PostgreSQL 10 et la restaurer dans notre PostgreSQL 11. La sauvegarde ne sera prise que pour le schéma, puisque les informations seront répliquées dans le transfert initial.
Dans PostgreSQL 10 :
$ pg_dumpall -s > schema.sqlDans PostgreSQL 11 :
$ psql -d postgres -f schema.sqlUne fois que nous avons notre schéma dans PostgreSQL 11, nous créons l'abonnement, en remplaçant les valeurs de host, dbname, user et password par celles qui correspondent à notre environnement.
PostgreSQL 11 :
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.100.143 dbname=world user=rep password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONCe qui précède démarrera le processus de réplication, qui synchronisera le contenu initial des tables dans la publication, puis commencera à répliquer les modifications incrémentielles de ces tables.
L'utilisateur qui crée un abonnement doit être un superutilisateur. Le processus d'application de l'abonnement s'exécutera dans la base de données locale avec les privilèges d'un superutilisateur.
Pour vérifier l'abonnement créé, nous pouvons utiliser le catalogue pg_stat_subscription. Cette vue contiendra une ligne par abonnement pour le nœud de calcul principal (avec un PID nul si le nœud de calcul n'est pas en cours d'exécution) et des lignes supplémentaires pour les nœuds de calcul gérant la copie initiale des données des tables abonnées.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16428
subname | sub1
pid | 1111
relid |
received_lsn | 0/172AF90
last_msg_send_time | 2018-12-05 22:11:45.195963+00
last_msg_receipt_time | 2018-12-05 22:11:45.196065+00
latest_end_lsn | 0/172AF90
latest_end_time | 2018-12-05 22:11:45.195963+00Description des colonnes :
- subid :OID de l'abonnement.
- sous-nom :nom de l'abonnement.
- pid :ID de processus du processus de travail d'abonnement.
- relid :OID de la relation que le worker est en train de synchroniser ; null pour le travailleur d'application principal.
- received_lsn :dernier emplacement de journal à écriture anticipée reçu, la valeur initiale de ce champ étant 0.
- last_msg_send_time :heure d'envoi du dernier message reçu de l'expéditeur WAL d'origine.
- last_msg_receipt_time :heure de réception du dernier message reçu de l'expéditeur WAL d'origine.
- latest_end_lsn :dernier emplacement du journal à écriture anticipée signalé à l'expéditeur du WAL d'origine.
- latest_end_time :heure du dernier emplacement du journal à écriture anticipée signalé à l'expéditeur du WAL d'origine.
Pour vérifier l'état de la réplication dans le maître, nous pouvons utiliser pg_stat_replication :
world=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 1178
usesysid | 16427
usename | rep
application_name | sub1
client_addr | 192.168.100.144
client_hostname |
client_port | 58270
backend_start | 2018-12-05 22:11:45.097539+00
backend_xmin |
state | streaming
sent_lsn | 0/172AF90
write_lsn | 0/172AF90
flush_lsn | 0/172AF90
replay_lsn | 0/172AF90
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | asyncDescription des colonnes :
- pid :ID de processus d'un processus expéditeur WAL.
- usesysid :OID de l'utilisateur connecté à ce processus d'envoi WAL.
- usename :nom de l'utilisateur connecté à ce processus d'envoi WAL.
- application_name :nom de l'application qui est connectée à cet expéditeur WAL.
- client_addr :adresse IP du client connecté à cet expéditeur WAL. Si ce champ est nul, cela indique que le client est connecté via un socket Unix sur la machine serveur.
- client_hostname :nom d'hôte du client connecté, tel que rapporté par une recherche DNS inversée de client_addr. Ce champ sera uniquement non nul pour les connexions IP, et uniquement lorsque log_hostname est activé.
- client_port :numéro de port TCP que le client utilise pour communiquer avec cet expéditeur WAL, ou -1 si un socket Unix est utilisé.
- backend_start :heure à laquelle ce processus a été lancé.
- backend_xmin :l'horizon xmin de cette veille signalé par hot_standby_feedback.
- state :état actuel de l'expéditeur WAL. Les valeurs possibles sont :démarrage, rattrapage, diffusion, sauvegarde et arrêt.
- sent_lsn :dernier emplacement du journal à écriture anticipée envoyé sur cette connexion.
- write_lsn :dernier emplacement du journal à écriture anticipée écrit sur le disque par ce serveur de secours.
- flush_lsn :dernier emplacement du journal à écriture anticipée vidé sur le disque par ce serveur de secours.
- replay_lsn :dernier emplacement du journal à écriture anticipée rejoué dans la base de données sur ce serveur de secours.
- write_lag :temps écoulé entre le vidage local des WAL récents et la réception de la notification indiquant que ce serveur de secours l'a écrit (mais pas encore vidé ou appliqué).
- flush_lag :temps écoulé entre le vidage local des WAL récents et la réception de la notification indiquant que ce serveur de secours l'a écrit et vidé (mais pas encore appliqué).
- replay_lag :temps écoulé entre le vidage local des WAL récents et la réception de la notification indiquant que ce serveur de secours l'a écrit, vidé et appliqué.
- sync_priority :priorité de ce serveur de secours pour être choisi comme serveur de secours synchrone dans une réplication synchrone basée sur la priorité.
- sync_state :état synchrone de ce serveur de secours. Les valeurs possibles sont async, potential, sync, quorum.
Pour vérifier quand le transfert initial est terminé, nous pouvons voir le journal PostgreSQL sur l'abonné :
2018-12-05 22:11:45.096 UTC [1111] LOG: logical replication apply worker for subscription "sub1" has started
2018-12-05 22:11:45.103 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2018-12-05 22:11:45.114 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2018-12-05 22:11:45.156 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2018-12-05 22:11:45.162 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2018-12-05 22:11:45.168 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2018-12-05 22:11:45.206 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedOu en vérifiant la variable srsubstate sur le catalogue pg_subscription_rel. Ce catalogue contient l'état de chaque relation répliquée dans chaque souscription.
world=# SELECT * FROM pg_subscription_rel;
-[ RECORD 1 ]---------
srsubid | 16428
srrelid | 16387
srsubstate | r
srsublsn | 0/172AF20
-[ RECORD 2 ]---------
srsubid | 16428
srrelid | 16393
srsubstate | r
srsublsn | 0/172AF58
-[ RECORD 3 ]---------
srsubid | 16428
srrelid | 16400
srsubstate | r
srsublsn | 0/172AF90Description des colonnes :
- srsubid :référence à l'abonnement.
- srrelid :référence à la relation.
- srsubstate :code d'état :i =initialiser, d =les données sont en cours de copie, s =synchronisé, r =prêt (réplication normale).
- srsublsn :LSN de fin pour les états s et r.
Nous pouvons insérer des enregistrements de test dans notre PostgreSQL 10 et valider que nous les avons dans notre PostgreSQL 11 :
PostgreSQL 10 :
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 11 :
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)À ce stade, tout est prêt pour faire pointer notre application vers notre PostgreSQL 11.
Pour cela, tout d'abord, nous devons confirmer que nous n'avons pas de décalage de réplication.
Sur le maître :
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0Et maintenant, nous n'avons plus qu'à changer notre point de terminaison de notre application ou équilibreur de charge (si nous en avons un) vers le nouveau serveur PostgreSQL 11.
Si nous avons un équilibreur de charge comme HAProxy, nous pouvons le configurer en utilisant PostgreSQL 10 comme actif et PostgreSQL 11 comme sauvegarde, de cette manière :
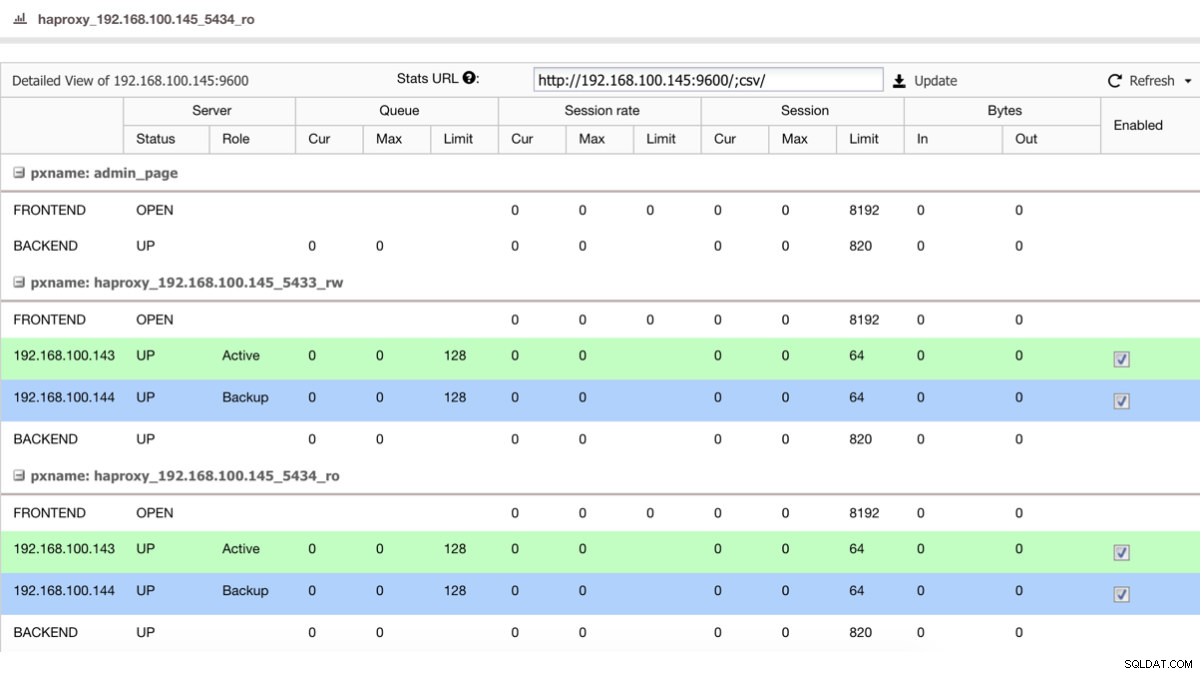 Affichage de l'état HAProxy
Affichage de l'état HAProxy Ainsi, si vous venez d'arrêter le maître dans PostgreSQL 10, le serveur de sauvegarde, dans ce cas dans PostgreSQL 11, commence à recevoir le trafic de manière transparente pour l'utilisateur/l'application.
A la fin de la migration, nous pouvons supprimer l'abonnement dans notre nouveau master dans PostgreSQL 11 :
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONEt vérifiez qu'il est correctement supprimé :
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)Limites
Avant d'utiliser la réplication logique, veuillez garder à l'esprit les limitations suivantes :
- Le schéma de la base de données et les commandes DDL ne sont pas répliqués. Le schéma initial peut être copié en utilisant pg_dump --schema-only.
- Les données de séquence ne sont pas répliquées. Les données des colonnes de série ou d'identité soutenues par des séquences seront répliquées dans le cadre de la table, mais la séquence elle-même affichera toujours la valeur de départ sur l'abonné.
- La réplication des commandes TRUNCATE est prise en charge, mais certaines précautions doivent être prises lors de la troncature de groupes de tables connectées par des clés étrangères. Lors de la réplication d'une action de troncation, l'abonné tronquera le même groupe de tables que celui qui a été tronqué sur l'éditeur, soit explicitement spécifié, soit implicitement collecté via CASCADE, moins les tables qui ne font pas partie de l'abonnement. Cela fonctionnera correctement si toutes les tables concernées font partie du même abonnement. Mais si certaines tables à tronquer sur l'abonné ont des liens de clé étrangère vers des tables qui ne font pas partie du même abonnement (ou d'aucun), alors l'application de l'action de troncature sur l'abonné échouera.
- Les grands objets ne sont pas répliqués. Il n'y a pas de solution de contournement pour cela, autre que le stockage des données dans des tables normales.
- La réplication n'est possible que de tables de base à tables de base. Autrement dit, les tables côté publication et côté abonnement doivent être des tables normales, et non des vues, des vues matérialisées, des tables racine de partition ou des tables étrangères. Dans le cas des partitions, vous pouvez répliquer une hiérarchie de partition un à un, mais vous ne pouvez pas actuellement répliquer vers une configuration partitionnée différemment.
Conclusion
Garder votre serveur PostgreSQL à jour en effectuant des mises à jour régulières était une tâche nécessaire mais difficile jusqu'à la version PostgreSQL 10.
Dans ce blog, nous avons fait une brève introduction à la réplication logique, une fonctionnalité de PostgreSQL introduite nativement dans la version 10, et nous vous avons montré comment elle peut vous aider à relever ce défi avec une stratégie sans temps d'arrêt.