Au moment de la rédaction de cet article, T-SQL ne prend pas en charge ces options, mais dans les liens suivants, vous pouvez trouver des demandes d'amélioration de fonctionnalités demandant leur inclusion dans T-SQL à l'avenir, et voter pour elles :
- Ajouter la prise en charge de la clause ISO/IEC SQL SEARCH aux CTE récursifs dans T-SQL
- Ajouter la prise en charge de la clause ISO/IEC SQL CYCLE aux CTE récursifs dans T-SQL
Dans les sections suivantes, je décrirai les deux options standard et fournirai également des solutions alternatives logiquement équivalentes qui sont actuellement disponibles dans T-SQL.
Clause RECHERCHE
La clause SEARCH standard définit l'ordre de recherche récursif comme BREADTH FIRST ou DEPTH FIRST par une ou plusieurs colonnes de classement spécifiées et crée une nouvelle colonne de séquence avec les positions ordinales des nœuds visités. Vous spécifiez BREADTH FIRST pour rechercher d'abord à travers chaque niveau (largeur) puis vers le bas des niveaux (profondeur). Vous spécifiez DEPTH FIRST pour rechercher d'abord vers le bas (profondeur) puis à travers (largeur).
Vous spécifiez la clause SEARCH juste avant la requête externe.
Je vais commencer par un exemple pour la largeur du premier ordre de recherche récursive. N'oubliez pas que cette fonctionnalité n'est pas disponible dans T-SQL, vous ne pourrez donc pas exécuter les exemples qui utilisent les clauses standard dans SQL Server ou Azure SQL Database. Le code suivant renvoie le sous-arbre de l'employé 1, en demandant un premier ordre de recherche en largeur par empid, en créant une colonne de séquence appelée seqbreadth avec les positions ordinales des nœuds visités :
DECLARER @root AS INT =1 ; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) RECHERCHER LA LARGE D'ABORD PAR empid SET seqbreadth---------------------------------------- ---- SELECT empid, mgrid, empname, seqbreadthFROM CORDER BY seqbreadth;
Voici la sortie souhaitée de ce code :
empid mgrid empname seqbreadth------ ------ -------- -----------1 NULL David 12 1 Eitan 23 1 Ina 34 2 Seraph 45 2 Jiru 56 2 Steve 67 3 Aaron 78 5 Lilach 89 7 Rita 910 5 Sean 1011 7 Gabriel 1112 9 Emilia 1213 9 Michael 1314 9 Didi 14
Ne soyez pas confus par le fait que les valeurs seqbreadth semblent être identiques aux valeurs empid. C'est juste par hasard en raison de la façon dont j'ai attribué manuellement les valeurs empid dans les exemples de données que j'ai créés.
La figure 2 présente une représentation graphique de la hiérarchie des employés, avec une ligne en pointillé indiquant la largeur du premier ordre dans lequel les nœuds ont été recherchés. Les valeurs empid apparaissent juste en dessous des noms des employés et les valeurs seqbreadth attribuées apparaissent dans le coin inférieur gauche de chaque case.
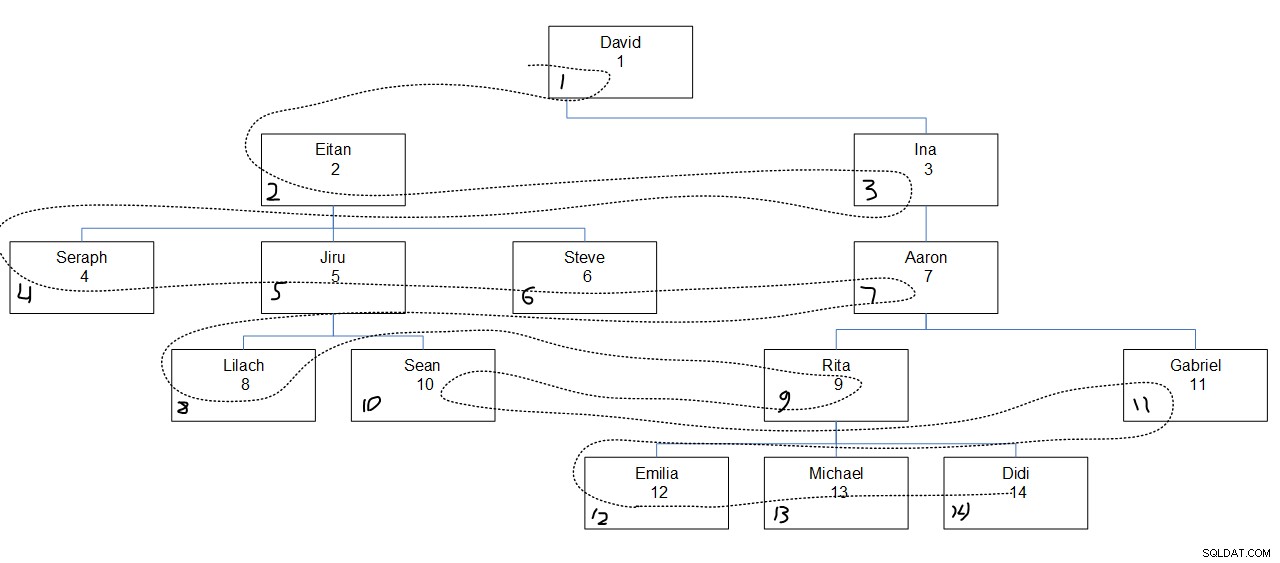 Figure 2 :Étendue de la recherche en premier
Figure 2 :Étendue de la recherche en premier
Ce qui est intéressant à noter ici, c'est qu'au sein de chaque niveau, les nœuds sont recherchés en fonction de l'ordre de colonne spécifié (empid dans notre cas) indépendamment de l'association parent du nœud. Par exemple, notez qu'au quatrième niveau, Lilach est accessible en premier, Rita en second, Sean en troisième et Gabriel en dernier. C'est parce que parmi tous les employés du quatrième niveau, c'est leur ordre basé sur leurs valeurs empid. Ce n'est pas comme si Lilach et Sean étaient censés être fouillés consécutivement parce qu'ils sont des subordonnés directs du même manager, Jiru.
Il est assez simple de trouver une solution T-SQL qui fournit l'équivalent logique de l'option standard SAERCH DEPTH FIRST. Vous créez une colonne appelée lvl comme je l'ai montré plus tôt pour suivre le niveau du nœud par rapport à la racine (0 pour le premier niveau, 1 pour le second, etc.). Ensuite, vous calculez la colonne de séquence de résultats souhaitée dans la requête externe à l'aide d'une fonction ROW_NUMBER. En tant que fenêtre de commande, vous spécifiez d'abord lvl, puis la colonne de commande souhaitée (empid dans notre cas). Voici le code complet de la solution :
DECLARER @root AS INT =1 ; WITH C AS( SELECT empid, mgrid, empname, 0 AS lvl FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ROW_NUMBER() OVER(ORDER BY lvl, empid) AS seqbreadthFROM CORDER BY seqbreadth;
Examinons ensuite l'ordre de recherche DEPTH FIRST. Selon la norme, le code suivant devrait renvoyer le sous-arbre de l'employé 1, en demandant un premier ordre de recherche en profondeur par empid, en créant une colonne de séquence appelée seqdepth avec les positions ordinales des nœuds recherchés :
DECLARER @root AS INT =1 ; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) PROFONDEUR DE RECHERCHE D'ABORD PAR empid SET seqdepth---------------------------------------- SELECT empid, mgrid, empname, seqdepthFROM CORDER BY seqdepth;
Voici la sortie souhaitée de ce code :
empid mgrid empname seqdepth------ ------ -------- ---------1 NULL David 12 1 Eitan 24 2 Seraph 35 2 Jiru 48 5 Lilach 510 5 Sean 66 2 Steve 73 1 Ina 87 3 Aaron 99 7 Rita 1012 9 Emilia 1113 9 Michael 1214 9 Didi 1311 7 Gabriel 14
En regardant la sortie de requête souhaitée, il est probablement difficile de comprendre pourquoi les valeurs de séquence ont été affectées telles qu'elles l'étaient. La figure 3 devrait vous aider. Il présente une représentation graphique de la hiérarchie des employés, avec une ligne pointillée reflétant le premier ordre de recherche en profondeur, avec les valeurs de séquence attribuées dans le coin inférieur gauche de chaque case.
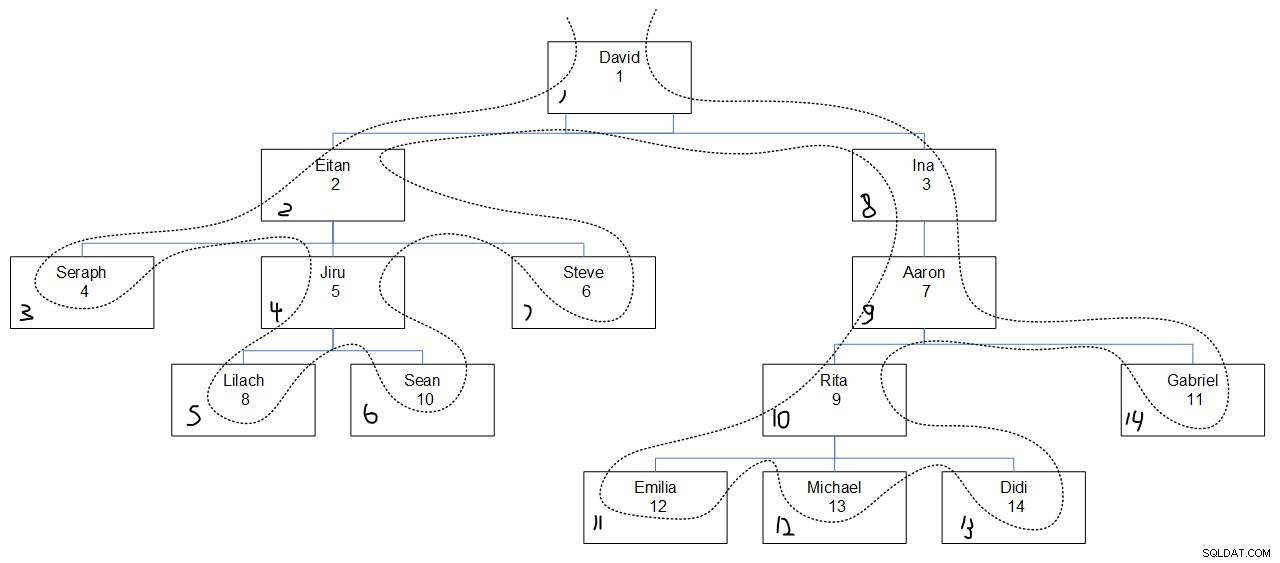 Figure 3 :profondeur de recherche en premier
Figure 3 :profondeur de recherche en premier
Trouver une solution T-SQL qui fournit l'équivalent logique de l'option standard SEARCH DEPTH FIRST est un peu délicat, mais faisable. Je vais décrire la solution en deux étapes.
À l'étape 1, pour chaque nœud, vous calculez un chemin de tri binaire constitué d'un segment par ancêtre du nœud, chaque segment reflétant la position de tri de l'ancêtre parmi ses frères et sœurs. Vous construisez ce chemin de la même manière que vous calculez la colonne lvl. Autrement dit, commencez par une chaîne binaire vide pour le nœud racine dans la requête d'ancrage. Ensuite, dans la requête récursive, vous concaténez le chemin du parent avec la position de tri du nœud parmi les frères après l'avoir converti en un segment binaire. Vous utilisez la fonction ROW_NUMBER pour calculer la position, partitionnée par le parent (mgrid dans notre cas) et ordonnée par la colonne de classement pertinente (empid dans notre cas). Vous convertissez le numéro de ligne en une valeur binaire d'une taille suffisante en fonction du nombre maximum d'enfants directs qu'un parent peut avoir dans votre graphique. BINARY(1) prend en charge jusqu'à 255 enfants par parent, BINARY(2) prend en charge 65 535, BINARY(3) :16 777 215, BINARY(4) :4 294 967 295. Dans un CTE récursif, les colonnes correspondantes dans les requêtes d'ancrage et récursives doivent être du même type et taille , assurez-vous donc de convertir le chemin de tri en une valeur binaire de la même taille dans les deux.
Voici le code implémentant l'étape 1 dans notre solution (en supposant que BINARY(1) est suffisant par segment, ce qui signifie que vous n'avez pas plus de 255 subordonnés directs par responsable) :
DECLARER @root AS INT =1 ; WITH C AS( SELECT empid, mgrid, empname, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M. sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, sortpathFROM C;
Ce code génère la sortie suivante :
empid mgrid empname sortpath------ ------ -------- -----------1 NULL David 0x2 1 Eitan 0x013 1 Ina 0x027 3 Aaron 0x02019 7 Rita 0x02010111 7 Gabriel 0x02010212 9 Emilia 0x0201010113 9 Michael 0x0201010214 9 Didi 0x020101034 2 SERAP
Notez que j'ai utilisé une chaîne binaire vide comme chemin de tri pour le nœud racine du sous-arbre unique que nous interrogeons ici. Si le membre d'ancrage peut potentiellement renvoyer plusieurs racines de sous-arbre, commencez simplement par un segment basé sur un calcul ROW_NUMBER dans la requête d'ancrage, de la même manière que vous le calculez dans la requête récursive. Dans ce cas, votre chemin de tri sera plus long d'un segment.
Ce qu'il reste à faire à l'étape 2, c'est de créer la colonne seqdepth du résultat souhaité en calculant les numéros de ligne classés par chemin de tri dans la requête externe, comme ceci
DECLARER @root AS INT =1 ; WITH C AS( SELECT empid, mgrid, empname, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M. sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepthFROM CORDER BY seqdepth;
Cette solution est l'équivalent logique de l'utilisation de l'option standard SEARCH DEPTH FIRST présentée précédemment avec la sortie souhaitée.
Une fois que vous avez une colonne de séquence reflétant la profondeur du premier ordre de recherche (seqdepth dans notre cas), avec juste un peu plus d'effort, vous pouvez générer une très belle représentation visuelle de la hiérarchie. Vous aurez également besoin de la colonne lvl susmentionnée. Vous commandez la requête externe par la colonne de séquence. Vous renvoyez un attribut que vous souhaitez utiliser pour représenter le nœud (par exemple, empname dans notre cas), préfixé par une chaîne (par exemple ' | ') répliqué lvl fois. Voici le code complet pour obtenir une telle représentation visuelle :
DECLARER @root AS INT =1 ; WITH C AS( SELECT empid, empname, 0 AS lvl, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.empname, M.lvl + 1 AS lvl, CAST(M.sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth, REPLICATE(' | ', lvl) + empname AS empFROM CORDER BY seqdepth;
Ce code génère la sortie suivante :
empid seqdepth emp------ --------- --------------------1 1 David2 2 | Eitan4 3 | | Séraphin5 4 | | Jiru8 5 | | | Lilaque10 6 | | | Sean6 7 | | Steve3 8 | Ina7 9 | | Aaron9 10 | | | Rita12 11 | | | | Émilie13 12 | | | | Michel14 13 | | | | Didi11 14 | | | Gabriel
C'est plutôt cool !
Clause CYCLE
Les structures de graphe peuvent avoir des cycles. Ces cycles peuvent être valides ou invalides. Un exemple de cycles valides est un graphique représentant les autoroutes et les routes reliant les villes et les villages. C'est ce qu'on appelle un graphe cyclique . A l'inverse, un graphe représentant une hiérarchie d'employés comme dans notre cas n'est pas censé avoir de cycles. C'est ce qu'on appelle un acyclique graphique. Cependant, supposons qu'en raison d'une mise à jour erronée, vous vous retrouviez avec un cycle involontairement. Par exemple, supposons que vous mettez à jour par erreur l'ID de responsable du PDG (employé 1) en employé 14 en exécutant le code suivant :
UPDATE Employés SET mgrid =14WHERE empid =1 ;
Vous avez maintenant un cycle invalide dans la hiérarchie des employés.
Que les cycles soient valides ou invalides, lorsque vous parcourez la structure du graphe, vous ne voulez certainement pas continuer à suivre un chemin cyclique à plusieurs reprises. Dans les deux cas, vous voulez arrêter de poursuivre un chemin une fois qu'une occurrence non première du même nœud est trouvée, et marquer un tel chemin comme cyclique.
Alors, que se passe-t-il lorsque vous interrogez un graphique qui a des cycles à l'aide d'une requête récursive, sans mécanisme en place pour les détecter ? Cela dépend de la mise en œuvre. Dans SQL Server, à un moment donné, vous atteindrez la limite de récursivité maximale et votre requête sera abandonnée. Par exemple, en supposant que vous avez exécuté la mise à jour ci-dessus qui a introduit le cycle, essayez d'exécuter la requête récursive suivante pour identifier la sous-arborescence de l'employé 1 :
DECLARER @root AS INT =1 ; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid)SELECT empid, mgrid, empnameFROM C;
Étant donné que ce code ne définit pas de limite de récursivité maximale explicite, la limite par défaut de 100 est supposée. SQL Server interrompt l'exécution de ce code avant la fin et génère une erreur :
empid mgrid empname------ ------ --------1 14 David2 1 Eitan3 1 Ina7 3 Aaron9 7 Rita11 7 Gabriel12 9 Emilia13 9 Michael14 9 Didi1 14 David2 1 Eitan3 1 Ina7 3 Aaron...
Msg 530, Niveau 16, État 1, Ligne 432
L'instruction s'est terminée. La récursivité maximale 100 a été épuisée avant la fin de l'instruction.
Le standard SQL définit une clause appelée CYCLE pour les CTE récursifs, vous permettant de gérer les cycles dans votre graphe. Vous spécifiez cette clause juste avant la requête externe. Si une clause SEARCH est également présente, vous la spécifiez d'abord, puis la clause CYCLE. Voici la syntaxe de la clause CYCLE :
CYCLE
SET TO DEFAULT
USING
La détection d'un cycle est basée sur la liste de colonnes de cycle spécifiée . Par exemple, dans notre hiérarchie d'employés, vous voudrez probablement utiliser la colonne empid à cette fin. Lorsque la même valeur empid apparaît pour la deuxième fois, un cycle est détecté et la requête ne poursuit pas un tel chemin plus loin. Vous spécifiez une nouvelle colonne de marque de cycle qui indiquera si un cycle a été trouvé ou non, et vos propres valeurs comme marque de cycle et marque non-cycle valeurs. Par exemple, ceux-ci peuvent être 1 et 0 ou "Oui" et "Non", ou toute autre valeur de votre choix. Dans la clause USING, vous spécifiez un nouveau nom de colonne de tableau qui contiendra le chemin des nœuds trouvés jusqu'à présent.
Voici comment vous traiteriez une demande de subordonnés d'un employé racine d'entrée, avec la possibilité de détecter des cycles basés sur la colonne empid, en indiquant 1 dans la colonne de marque de cycle lorsqu'un cycle est détecté, et 0 sinon :
DECLARER @root AS INT =1 ; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) CYCLE empid SET cycle TO 1 DEFAULT 0---------------------------------------- SELECT empid, mgrid, empnameFROM C;
Voici la sortie souhaitée de ce code :
empid mgrid empname cycle------ ------ -------- ------1 14 David 02 1 Eitan 03 1 Ina 07 3 Aaron 09 7 Rita 011 7 Gabriel 012 9 Emilia 013 9 Michael 014 9 Didi 01 14 David 14 2 Seraph 05 2 Jiru 06 2 Steve 08 5 Lilach 010 5 Sean 0
T-SQL ne prend actuellement pas en charge la clause CYCLE, mais il existe une solution de contournement qui fournit un équivalent logique. Il comporte trois étapes. Rappelez-vous que vous avez créé précédemment un chemin de tri binaire pour gérer l'ordre de recherche récursif. De la même manière, comme première étape de la solution, vous construisez un chemin d'ancêtres basé sur une chaîne de caractères composé des ID de nœud (ID d'employé dans notre cas) des ancêtres menant au nœud actuel, y compris le nœud actuel. Vous voulez des séparateurs entre les ID de nœud, dont un au début et un à la fin.
Voici le code pour construire un tel chemin d'ancêtre :
DECLARER @root AS INT =1 ; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ancpathFROM C;
Ce code génère la sortie suivante, poursuivant toujours des chemins cycliques, et donc abandonnant avant la fin une fois la limite de récursivité maximale dépassée :
empid mgrid empname ancpath------ ------ -------- -------------------1 14 David . 1.2 1 Eitan .1.2.3 1 Ina .1.3.7 3 Aaron .1.3.7.9 7 Rita .1.3.7.9.11 7 Gabriel .1.3.7.11.12 9 Emilia .1.3.7.9.12.13 9 Michael .1.3.7.9. 13.14 9 Didi .1.3.7.9.14.1 14 David .1.3.7.9.14.1.2 1 Eitan .1.3.7.9.14.1.2.3 1 Ina .1.3.7.9.14.1.3.7 3 Aaron .1.3.7.9.14.1.3.7. ...
Msg 530, Niveau 16, État 1, Ligne 492
L'instruction s'est terminée. La récursivité maximale 100 a été épuisée avant la fin de l'instruction.
Eyeballing the output, you can identify a cyclic path when the current node appears in the path for the nonfirst time, such as in the path '.1.3.7.9.14.1.' .
In the second step of the solution you produce the cycle mark column. In the anchor query you simply set it to 0 since clearly a cycle cannot be found in the first node. In the recursive member you use a CASE expression that checks with a LIKE-based predicate whether the current node ID already appears in the parent’s path, in which case it returns the value 1, or not, in which case it returns the value 0.
Here’s the code implementing Step 2:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, 0 AS cycle FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1 ELSE 0 END AS cycle FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ancpath, cycleFROM C;
This code generates the following output, again, still pursuing cyclic paths and failing once the max recursion limit is reached:
empid mgrid empname ancpath cycle------ ------ -------- ------------------- ------1 14 David .1. 02 1 Eitan .1.2. 03 1 Ina .1.3. 07 3 Aaron .1.3.7. 09 7 Rita .1.3.7.9. 011 7 Gabriel .1.3.7.11. 012 9 Emilia .1.3.7.9.12. 013 9 Michael .1.3.7.9.13. 014 9 Didi .1.3.7.9.14. 01 14 David .1.3.7.9.14.1. 12 1 Eitan .1.3.7.9.14.1.2. 03 1 Ina .1.3.7.9.14.1.3. 17 3 Aaron .1.3.7.9.14.1.3.7. 1...
Msg 530, Level 16, State 1, Line 532
The statement terminated. The maximum recursion 100 has been exhausted before statement completion.
The third and last step is to add a predicate to the ON clause of the recursive member that pursues a path only if a cycle was not detected in the parent’s path.
Here’s the code implementing Step 3, which is also the complete solution:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, 0 AS cycle FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1 ELSE 0 END AS cycle FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid AND M.cycle =0)SELECT empid, mgrid, empname, cycleFROM C;
This code runs to completion, and generates the following output:
empid mgrid empname cycle------ ------ -------- -----------1 14 David 02 1 Eitan 03 1 Ina 07 3 Aaron 09 7 Rita 011 7 Gabriel 012 9 Emilia 013 9 Michael 014 9 Didi 01 14 David 14 2 Seraph 05 2 Jiru 06 2 Steve 08 5 Lilach 010 5 Sean 0
You identify the erroneous data easily here, and fix the problem by setting the manager ID of the CEO to NULL, like so:
UPDATE Employees SET mgrid =NULLWHERE empid =1;
Run the recursive query and you will find that there are no cycles present.
Conclusion
Recursive CTEs enable you to write concise declarative solutions for purposes such as traversing graph structures. A recursive CTE has at least one anchor member, which gets executed once, and at least one recursive member, which gets executed repeatedly until it returns an empty result set. Using a query option called MAXRECURSION you can control the maximum number of allowed executions of the recursive member as a safety measure. To limit the executions of the recursive member programmatically for filtering purposes you can maintain a column that tracks the level of the current node with respect to the root node.
The SQL standard supports two very powerful options for recursive CTEs that are currently not available in T-SQL. One is a clause called SEARCH that controls the recursive search order, and another is a clause called CYCLE that detects cycles in the traversed paths. I provided logically equivalent solutions that are currently available in T-SQL. If you find that the unavailable standard features could be important future additions to T-SQL, make sure to vote for them here:
- Add support for ISO/IEC SQL SEARCH clause to recursive CTEs in T-SQL
- Add support for ISO/IEC SQL CYCLE clause to recursive CTEs in T-SQL
This article concludes the coverage of the logical aspects of CTEs. Next month I’ll turn my attention to physical/performance considerations of CTEs.
 Figure 1 :Hiérarchie des employés
Figure 1 :Hiérarchie des employés