En 2014, j'ai écrit un article intitulé Performance Tuning the Whole Query Plan. Il a examiné les moyens de trouver un nombre relativement restreint de valeurs distinctes à partir d'un ensemble de données modérément volumineux et a conclu qu'une solution récursive pourrait être optimale. Ce post de suivi revisite la question pour SQL Server 2019, en utilisant un plus grand nombre de lignes.
Environnement de test
J'utiliserai la base de données Stack Overflow 2013 de 50 Go, mais n'importe quelle grande table avec un faible nombre de valeurs distinctes ferait l'affaire.
Je chercherai des valeurs distinctes dans le BountyAmount colonne du dbo.Votes tableau, présenté dans l'ordre croissant du montant de la prime. La table Votes compte un peu moins de 53 millions de lignes (52 928 720 pour être exact). Il n'y a que 19 montants de prime différents, y compris NULL .
La base de données Stack Overflow 2013 est livrée sans index non clusterisés pour minimiser le temps de téléchargement. Il existe un index de clé primaire clusterisé sur l'Id colonne du dbo.Votes table. Il est réglé sur la compatibilité SQL Server 2008 (niveau 100), mais nous commencerons par un réglage plus moderne de SQL Server 2017 (niveau 140) :
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
Les tests ont été effectués sur mon ordinateur portable à l'aide de SQL Server 2019 CU 2. Cette machine dispose de quatre processeurs i7 (hyperthreadés à 8) avec une vitesse de base de 2,4 GHz. Il dispose de 32 Go de RAM, dont 24 Go disponibles pour l'instance SQL Server 2019. Le seuil de coût pour le parallélisme est fixé à 50.
Chaque résultat de test représente le meilleur des dix essais, avec toutes les données requises et les pages d'index en mémoire.
1. Index groupé du magasin de lignes
Pour définir une ligne de base, la première exécution est une requête en série sans aucune nouvelle indexation (et rappelez-vous que c'est avec la base de données définie sur le niveau de compatibilité 140) :
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1);
Cela analyse l'index clusterisé et utilise un agrégat de hachage en mode ligne pour trouver les valeurs distinctes de BountyAmount :
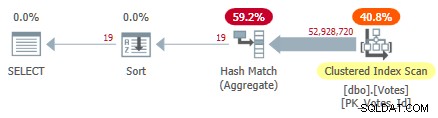 Plan d'index groupé en série
Plan d'index groupé en série
Cela prend 10 500 ms pour terminer, en utilisant la même quantité de temps CPU. N'oubliez pas qu'il s'agit du meilleur temps sur dix exécutions avec toutes les données en mémoire. Statistiques échantillonnées créées automatiquement sur le BountyAmount colonne ont été créées lors de la première exécution.
Environ la moitié du temps écoulé est consacrée à l'analyse de l'index clusterisé et environ la moitié à l'agrégat de correspondance de hachage. Le tri n'a que 19 lignes à traiter, il ne consomme donc qu'environ 1 ms. Tous les opérateurs de ce plan utilisent l'exécution en mode ligne.
Suppression du MAXDOP 1 l'indice donne un plan parallèle :
 Plan d'index clusterisé parallèle
Plan d'index clusterisé parallèle
C'est le plan que l'optimiseur choisit sans aucun indice dans ma configuration. Il renvoie les résultats en 4 200 ms utilisant un total de 32 800 ms de CPU (à DOP 8).
2. Index non clusterisé
Analyser l'ensemble du tableau pour trouver uniquement le BountyAmount semble inefficace, il est donc naturel d'essayer d'ajouter un index non clusterisé sur la seule colonne dont cette requête a besoin :
CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
Cet index prend du temps à créer (1m 40s). Le MAXDOP 1 la requête utilise désormais un Stream Aggregate car l'optimiseur peut utiliser l'index non clusterisé pour présenter des lignes dans BountyAmount commande :
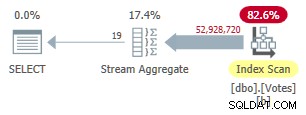 Plan en mode ligne série non cluster
Plan en mode ligne série non cluster
Cela dure 9 300 ms (consommant la même quantité de temps CPU). Une amélioration utile par rapport aux 10 500 ms d'origine, mais à peine bouleversante.
Suppression du MAXDOP 1 indice donne un plan parallèle avec agrégation locale (par thread) :
 Plan en mode ligne parallèle non cluster
Plan en mode ligne parallèle non cluster
Cela s'exécute en 3 400 ms en utilisant 25 800 ms de temps CPU. Nous pourrions peut-être améliorer la compression des lignes ou des pages sur le nouvel index, mais je souhaite passer à des options plus intéressantes.
3. Mode batch sur magasin de lignes (BMOR)
Définissez maintenant la base de données sur le mode de compatibilité SQL Server 2019 en utilisant :
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
Cela donne à l'optimiseur la liberté de choisir le mode batch sur le magasin de lignes s'il le juge utile. Cela peut fournir certains des avantages de l'exécution en mode batch sans nécessiter un index de stockage de colonnes. Pour des détails techniques approfondis et des options non documentées, consultez l'excellent article de Dmitry Pilugin sur le sujet.
Malheureusement, l'optimiseur choisit toujours une exécution entièrement en mode ligne à l'aide d'agrégats de flux pour les requêtes de test série et parallèles. Afin d'obtenir un mode batch sur le plan d'exécution du magasin de lignes, nous pouvons ajouter un indice pour encourager l'agrégation à l'aide de la correspondance de hachage (qui peut s'exécuter en mode batch) :
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); Cela nous donne un plan avec tous les opérateurs fonctionnant en mode batch :
 Mode de lot en série sur le plan de magasin en ligne
Mode de lot en série sur le plan de magasin en ligne
Les résultats sont renvoyés en 2 600 ms (tout CPU comme d'habitude). C'est déjà plus rapide que le parallèle plan en mode ligne (3 400 ms écoulés) tout en utilisant beaucoup moins de CPU (2 600 ms contre 25 800 ms).
Suppression du MAXDOP 1 indice (mais en gardant HASH GROUP ) donne un mode batch parallèle sur plan de magasin en ligne :
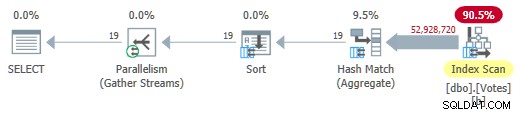 Mode de lot parallèle sur le plan de magasin en ligne
Mode de lot parallèle sur le plan de magasin en ligne
Cela s'exécute en seulement 725 ms utilisant 5 700 ms de CPU.
4. Mode batch sur le magasin de colonnes
Le mode batch parallèle sur le résultat du magasin de lignes est une amélioration impressionnante. Nous pouvons faire encore mieux en fournissant une représentation en colonne des données. Pour garder tout le reste identique, je vais ajouter un élément non clusterisé index de magasin de colonnes sur la colonne dont nous avons besoin :
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
Celui-ci est rempli à partir de l'index non clusterisé b-tree existant et sa création ne prend que 15 secondes.
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); L'optimiseur choisit un plan entièrement en mode batch incluant une analyse d'index de magasin de colonnes :
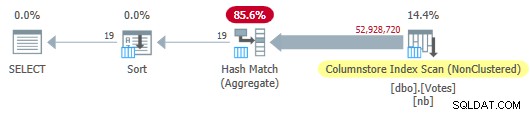 Plan de magasin de colonnes en série
Plan de magasin de colonnes en série
Cela s'exécute en 115 ms en utilisant la même quantité de temps CPU. L'optimiseur choisit ce plan sans aucun indice sur la configuration de mon système car le coût estimé du plan est inférieur au seuil de coût pour le parallélisme .
Pour obtenir un plan parallèle, nous pouvons soit réduire le seuil de coût, soit utiliser un indice non documenté :
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); Dans tous les cas, le plan parallèle est :
 Plan de magasin à colonnes parallèles
Plan de magasin à colonnes parallèles
Le temps écoulé de la requête est maintenant réduit à 30 ms , tout en consommant 210 ms de CPU.
5. Mode batch sur Column Store avec Push Down
Le meilleur temps d'exécution actuel de 30 ms est impressionnant, surtout par rapport aux 10 500 ms d'origine. Néanmoins, il est un peu dommage que nous devions passer près de 53 millions de lignes (en 58 868 lots) du Scan au Hash Match Aggregate.
Ce serait bien si SQL Server pouvait pousser l'agrégation vers le bas dans l'analyse et simplement renvoyer directement des valeurs distinctes à partir du magasin de colonnes. Vous pourriez penser que nous devons exprimer le DISTINCT en tant que GROUP BY pour obtenir Grouped Aggregate Pushdown, mais c'est logiquement redondant et ce n'est pas toute l'histoire en tout cas.
Avec l'implémentation actuelle de SQL Server, nous devons en fait calculer un agrégat pour activer le refoulement agrégé. Plus que cela, nous devons utiliser le résultat agrégé d'une manière ou d'une autre, ou l'optimiseur le supprimera simplement comme inutile.
Une façon d'écrire la requête pour obtenir un refoulement agrégé consiste à ajouter une exigence de classement secondaire logiquement redondante :
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); Le plan de série est maintenant :
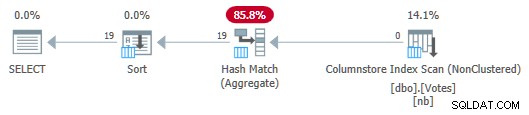 Plan de magasin de colonnes en série avec push down agrégé
Plan de magasin de colonnes en série avec push down agrégé
Notez qu'aucune ligne n'est transmise de l'analyse à l'agrégat ! Sous les couvertures, des agrégats partiels du BountyAmount Les valeurs et leurs nombres de lignes associés sont transmis à l'agrégat de correspondance de hachage, qui additionne les agrégats partiels pour former l'agrégat final (global) requis. C'est très efficace, comme le confirme le temps écoulé de 13 ms (tout cela est du temps CPU). Pour rappel, le plan de série précédent prenait 115 ms.
Pour compléter l'ensemble, on peut obtenir une version parallèle de la même manière qu'avant :
 Plan de magasin à colonnes parallèles avec push down agrégé
Plan de magasin à colonnes parallèles avec push down agrégé
Cela dure 7 ms utilisant 40 ms de CPU au total.
C'est dommage que nous ayons besoin de calculer et d'utiliser un agrégat dont nous n'avons pas besoin uniquement pour obtenir un push down. Peut-être que cela sera amélioré à l'avenir afin que DISTINCT et GROUP BY sans agrégats peuvent être poussés jusqu'à l'analyse.
6. Expression de table commune récursive en mode ligne
Au début, j'avais promis de revoir la solution CTE récursive utilisée pour trouver un petit nombre de doublons dans un grand ensemble de données. La mise en œuvre de l'exigence actuelle à l'aide de cette technique est assez simple, bien que le code soit nécessairement plus long que tout ce que nous avons vu jusqu'à présent :
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0); L'idée a ses racines dans un soi-disant index skip scan :nous trouvons la valeur d'intérêt la plus basse au début de l'index b-tree dans l'ordre croissant, puis cherchons à trouver la valeur suivante dans l'ordre de l'index, et ainsi de suite. La structure d'un index b-tree rend la recherche de la prochaine valeur la plus élevée très efficace - il n'est pas nécessaire de parcourir les doublons.
La seule vraie astuce ici est de convaincre l'optimiseur de nous permettre d'utiliser TOP dans la partie "récursive" du CTE pour renvoyer une copie de chaque valeur distincte. Veuillez consulter mon article précédent si vous avez besoin d'un rappel sur les détails.
Le plan d'exécution (expliqué en général par Craig Freedman ici) est :
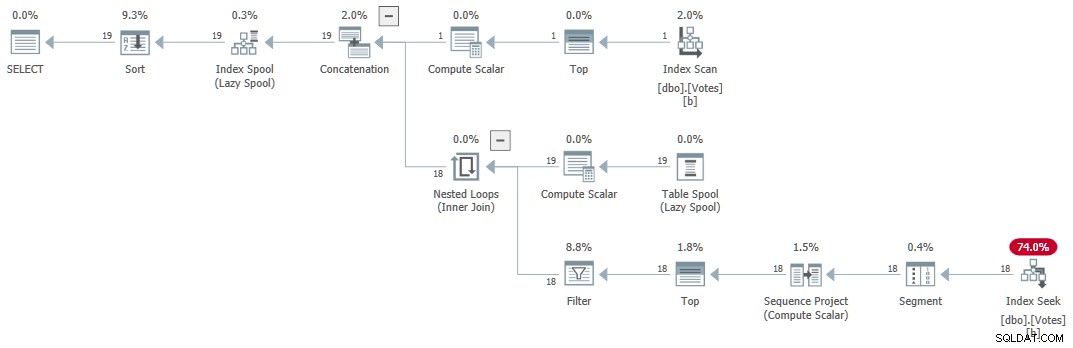 CTE récursif en série
CTE récursif en série
La requête renvoie des résultats corrects en 1 ms utilisant 1 ms de CPU, selon Sentry One Plan Explorer.
7. T-SQL itératif
Une logique similaire peut être exprimée en utilisant un WHILE boucle. Le code peut être plus facile à lire et à comprendre que le CTE récursif. Cela évite également d'avoir à utiliser des astuces pour contourner les nombreuses restrictions sur la partie récursive d'un CTE. Les performances sont compétitives à environ 15 ms. Ce code est fourni à titre indicatif et n'est pas inclus dans le tableau récapitulatif des performances.
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount; Tableau récapitulatif des performances
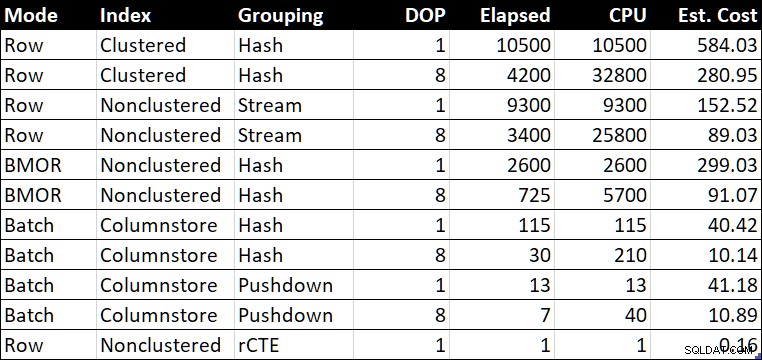 Tableau récapitulatif des performances (durée / CPU en millisecondes)
Tableau récapitulatif des performances (durée / CPU en millisecondes)
Le « Est. Coût » indique l'estimation du coût de l'optimiseur pour chaque requête, telle qu'elle est indiquée sur le système de test.
Réflexions finales
Trouver un petit nombre de valeurs distinctes peut sembler une exigence assez spécifique, mais je l'ai rencontré assez fréquemment au fil des ans, généralement dans le cadre du réglage d'une requête plus large.
Les derniers exemples étaient assez proches en termes de performances. Beaucoup de gens seraient satisfaits de l'un des résultats inférieurs à la seconde, selon les priorités. Même le résultat de 2 600 ms du mode de traitement par lots en série sur le stockage de lignes se compare bien au meilleur parallèle plans en mode ligne, ce qui augure bien d'accélérations significatives simplement en passant à SQL Server 2019 et en activant le niveau de compatibilité de base de données 150. Tout le monde ne pourra pas passer rapidement au stockage en colonne, et ce ne sera pas toujours la bonne solution de toute façon . Le mode batch sur le magasin de lignes offre un moyen pratique d'obtenir certains des gains possibles avec les magasins de colonnes, en supposant que vous puissiez convaincre l'optimiseur de choisir de l'utiliser.
Résultat agrégé du push down du magasin de colonnes parallèles de 57 millions de lignes traité en 7 ms (utilisant 40 ms de CPU) est remarquable, surtout compte tenu du matériel. Le résultat du push down agrégé en série de 13 ms est tout aussi impressionnant. Ce serait formidable si je n'avais pas eu à ajouter un résultat agrégé sans signification pour obtenir ces plans.
Pour ceux qui ne peuvent pas encore passer à SQL Server 2019 ou au stockage de colonnes, le CTE récursif est toujours une solution viable et efficace lorsqu'un index b-tree approprié existe, et le nombre de valeurs distinctes nécessaires est garanti assez petit. Ce serait bien si SQL Server pouvait accéder à un b-tree comme celui-ci sans avoir besoin d'écrire un CTE récursif (ou un code T-SQL en boucle itératif équivalent en utilisant WHILE ).
Une autre solution possible au problème consiste à créer une vue indexée. Cela fournira des valeurs distinctes avec une grande efficacité. L'inconvénient, comme d'habitude, est que chaque modification de la table sous-jacente devra mettre à jour le nombre de lignes stockées dans la vue matérialisée.
Chacune des solutions présentées ici a sa place, selon les besoins. Avoir une large gamme d'outils disponibles est généralement une bonne chose lors du réglage des requêtes. La plupart du temps, je choisirais l'une des solutions en mode batch car leurs performances seront assez prévisibles, quel que soit le nombre de doublons présents.