Il y a eu de nombreuses discussions sur l'OLTP en mémoire (la fonctionnalité anciennement connue sous le nom de "Hekaton") et sur la manière dont elle peut aider des charges de travail très spécifiques et à volume élevé. Au milieu d'une conversation différente, j'ai remarqué quelque chose dans le CREATE TYPE documentation pour SQL Server 2014 qui m'a fait penser qu'il pourrait y avoir un cas d'utilisation plus général :

Ajouts relativement silencieux et non annoncés à la documentation CREATE TYPE
Sur la base du diagramme de syntaxe, il semble que les paramètres de table (TVP) peuvent être optimisés en mémoire, tout comme les tables permanentes. Et avec cela, les roues ont immédiatement commencé à tourner.
Une chose pour laquelle j'ai utilisé les TVP est d'aider les clients à éliminer les méthodes coûteuses de fractionnement de chaînes dans T-SQL ou CLR (voir le contexte dans les articles précédents ici, ici et ici). Dans mes tests, l'utilisation d'un TVP standard a surpassé les modèles équivalents utilisant les fonctions de fractionnement CLR ou T-SQL par une marge significative (25-50%). Je me suis logiquement demandé :Y aurait-il un gain de performances à partir d'un TVP à mémoire optimisée ?
Il y a eu une certaine appréhension à propos de l'OLTP en mémoire en général, car il existe de nombreuses limitations et lacunes dans les fonctionnalités, vous avez besoin d'un groupe de fichiers séparé pour les données optimisées en mémoire, vous devez déplacer des tables entières vers une mémoire optimisée, et le meilleur avantage est généralement obtenu en créant également des procédures stockées compilées en mode natif (qui ont leur propre ensemble de limitations). Comme je vais le démontrer, en supposant que votre type de table contient des structures de données simples (par exemple, représentant un ensemble d'entiers ou de chaînes), l'utilisation de cette technologie uniquement pour les TVP élimine certaines de ces problèmes.
L'épreuve
Vous aurez toujours besoin d'un groupe de fichiers à mémoire optimisée même si vous n'allez pas créer de tables permanentes à mémoire optimisée. Créons donc une nouvelle base de données avec la structure appropriée en place :
CREATE DATABASE xtp; GO ALTER DATABASE xtp ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE xtp ADD FILE (name='xtpmod', filename='c:\...\xtp.mod') TO FILEGROUP xtp; GO ALTER DATABASE xtp SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON; GO
Maintenant, nous pouvons créer un type de table standard, comme nous le ferions aujourd'hui, et un type de table à mémoire optimisée avec un index de hachage non clusterisé et un nombre de compartiments que j'ai sortis de l'air (plus d'informations sur le calcul des besoins en mémoire et du nombre de compartiments dans le monde réel ici):
USE xtp; GO CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Si vous essayez ceci dans une base de données qui n'a pas de groupe de fichiers à mémoire optimisée, vous obtiendrez ce message d'erreur, comme vous le feriez si vous essayiez de créer une table normale à mémoire optimisée :
Msg 41337, Niveau 16, État 0, Ligne 9Le groupe de fichiers MEMORY_OPTIMIZED_DATA n'existe pas ou est vide. Les tables à mémoire optimisée ne peuvent pas être créées pour une base de données tant qu'elle n'a pas un groupe de fichiers MEMORY_OPTIMIZED_DATA qui n'est pas vide.
Pour tester une requête sur une table standard non optimisée en mémoire, j'ai simplement extrait des données dans une nouvelle table à partir de l'exemple de base de données AdventureWorks2012, en utilisant SELECT INTO pour ignorer toutes ces contraintes, index et propriétés étendues embêtants, puis j'ai créé un index clusterisé sur la colonne sur laquelle je savais que je chercherais (ProductID ):
SELECT * INTO dbo.Products FROM AdventureWorks2012.Production.Product; -- 504 rows CREATE UNIQUE CLUSTERED INDEX p ON dbo.Products(ProductID);
Ensuite, j'ai créé quatre procédures stockées :deux pour chaque type de table; chacun utilisant EXISTS et JOIN approches (j'aime généralement examiner les deux, même si je préfère EXISTS; plus tard, vous verrez pourquoi je ne voulais pas limiter mes tests à EXISTS ). Dans ce cas, j'attribue simplement une ligne arbitraire à une variable, afin de pouvoir observer un nombre élevé d'exécutions sans avoir à gérer les jeux de résultats et autres sorties et frais généraux :
-- Old-school TVP using EXISTS:
CREATE PROCEDURE dbo.ClassicTVP_Exists
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @Classic AS t
WHERE t.Item = p.ProductID
);
END
GO
-- In-Memory TVP using EXISTS:
CREATE PROCEDURE dbo.InMemoryTVP_Exists
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @InMemory AS t
WHERE t.Item = p.ProductID
);
END
GO
-- Old-school TVP using a JOIN:
CREATE PROCEDURE dbo.ClassicTVP_Join
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @Classic AS t
ON t.Item = p.ProductID;
END
GO
-- In-Memory TVP using a JOIN:
CREATE PROCEDURE dbo.InMemoryTVP_Join
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO
Ensuite, j'avais besoin de simuler le type de requête qui vient généralement contre ce type de table et nécessite un TVP ou un modèle similaire en premier lieu. Imaginez un formulaire avec une liste déroulante ou un ensemble de cases à cocher contenant une liste de produits, et l'utilisateur peut sélectionner les 20, 50 ou 200 qu'il souhaite comparer, répertorier, ce que vous avez. Les valeurs ne seront pas dans un bel ensemble contigu; ils seront généralement dispersés partout (s'il s'agissait d'une plage contiguë prévisible, la requête serait beaucoup plus simple :valeurs de début et de fin). J'ai donc juste choisi 20 valeurs arbitraires dans la table (en essayant de rester en dessous, disons, de 5% de la taille de la table), ordonnées au hasard. Un moyen simple de créer un VALUES réutilisable une clause comme celle-ci est la suivante :
DECLARE @x VARCHAR(4000) = '';
SELECT TOP (20) @x += '(' + RTRIM(ProductID) + '),'
FROM dbo.Products ORDER BY NEWID();
SELECT @x; Les résultats (les vôtres varieront presque certainement) :
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473),(442),(450),(735) ),(441),(409),(454),(780),(966),(988),(512),
Contrairement à un INSERT...SELECT direct , cela facilite la manipulation de cette sortie dans une instruction réutilisable pour remplir nos TVP à plusieurs reprises avec les mêmes valeurs et tout au long de plusieurs itérations de test :
SET NOCOUNT ON; DECLARE @ClassicTVP dbo.ClassicTVP; DECLARE @InMemoryTVP dbo.InMemoryTVP; INSERT @ClassicTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); INSERT @InMemoryTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP; EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
Si nous exécutons ce lot à l'aide de SQL Sentry Plan Explorer, les plans résultants montrent une grande différence :le TVP en mémoire est capable d'utiliser une jointure de boucles imbriquées et 20 recherches d'index clusterisées à une seule ligne, par rapport à une jointure de fusion alimentée par 502 lignes. une analyse d'index clusterisé pour le TVP classique. Et dans ce cas, EXISTS et JOIN ont produit des plans identiques. Cela pourrait basculer avec un nombre de valeurs beaucoup plus élevé, mais continuons avec l'hypothèse que le nombre de valeurs sera inférieur à 5 % de la taille de la table :
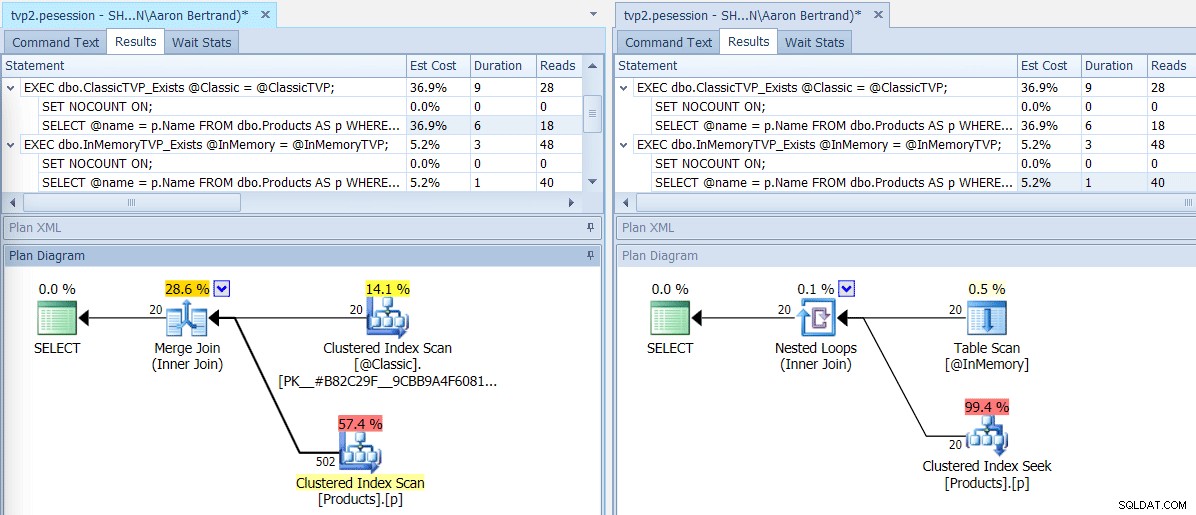 Plans pour les TVP classiques et en mémoire
Plans pour les TVP classiques et en mémoire
 Info-bulles pour les opérateurs d'analyse/recherche, mettant en évidence les principales différences – Classique à gauche, In- Mémoire à droite
Info-bulles pour les opérateurs d'analyse/recherche, mettant en évidence les principales différences – Classique à gauche, In- Mémoire à droite
Qu'est-ce que cela signifie à grande échelle ? Désactivons toute collection showplan et modifions légèrement le script de test pour exécuter chaque procédure 100 000 fois, en capturant manuellement le temps d'exécution cumulé :
DECLARE @i TINYINT = 1, @j INT = 1;
WHILE @i <= 4
BEGIN
SELECT SYSDATETIME();
WHILE @j <= 100000
BEGIN
IF @i = 1
BEGIN
EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP;
END
IF @i = 2
BEGIN
EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP;
END
IF @i = 3
BEGIN
EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP;
END
IF @i = 4
BEGIN
EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
END
SET @j += 1;
END
SELECT @i += 1, @j = 1;
END
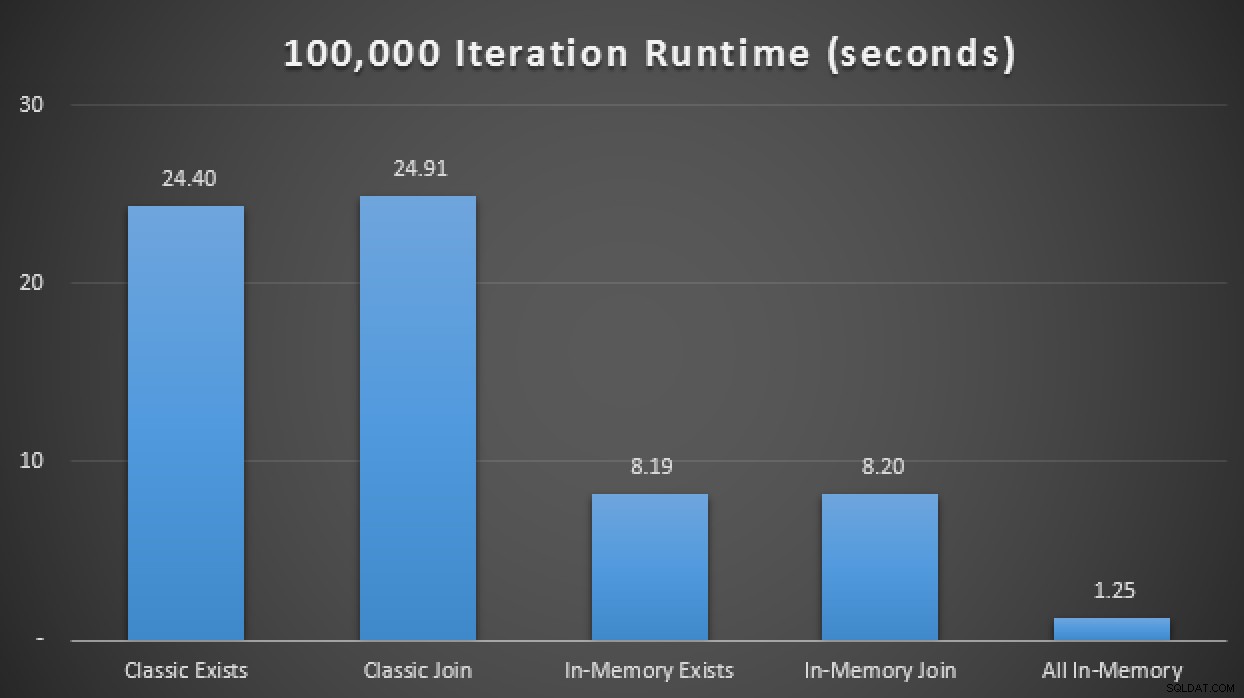
SELECT SYSDATETIME(); Dans les résultats, en moyenne sur 10 exécutions, nous voyons que, dans ce cas de test limité au moins, l'utilisation d'un type de table à mémoire optimisée a produit une amélioration d'environ 3 fois sur sans doute la mesure de performance la plus critique dans OLTP (durée d'exécution) :
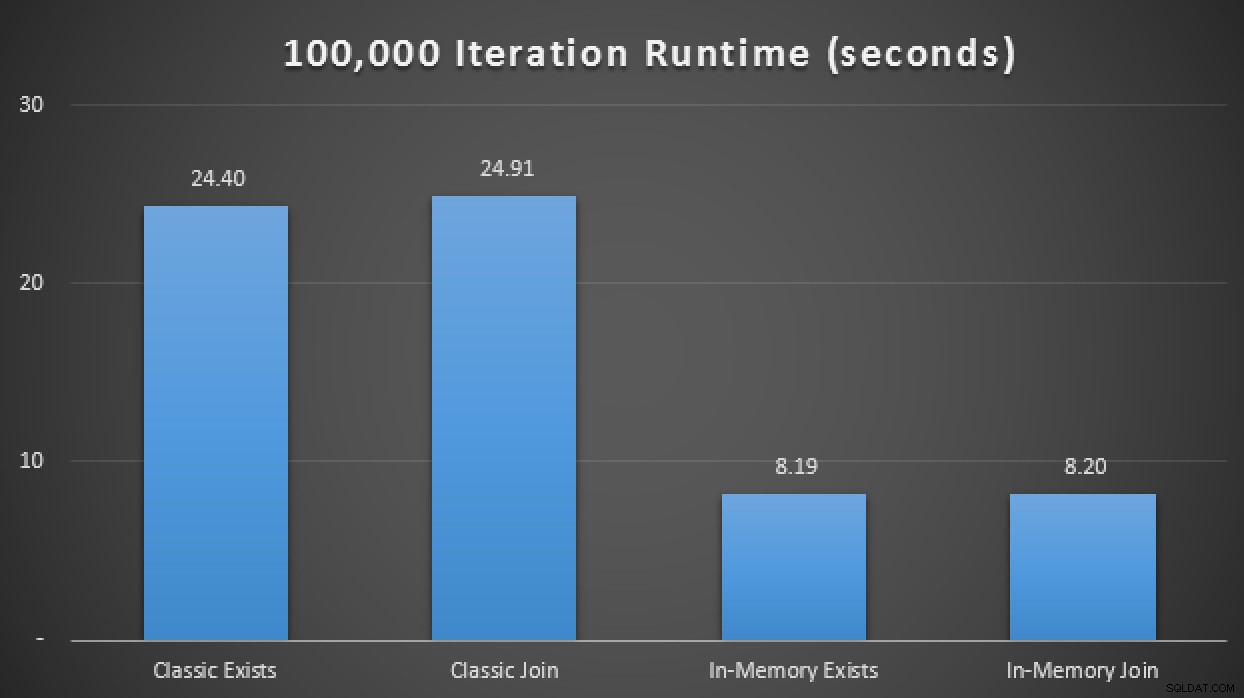
Résultats d'exécution montrant une amélioration de 3X avec les TVP en mémoire
In-Memory + In-Memory + In-Memory :Inception In-Memory
Maintenant que nous avons vu ce que nous pouvons faire en changeant simplement notre type de table standard en un type de table à mémoire optimisée, voyons si nous pouvons tirer davantage de performances de ce même modèle de requête lorsque nous appliquons le tiercé gagnant :une table en mémoire table, à l'aide d'une procédure stockée optimisée en mémoire compilée en mode natif, qui accepte une table en mémoire table comme paramètre table.
Tout d'abord, nous devons créer une nouvelle copie de la table et la remplir à partir de la table locale que nous avons déjà créée :
CREATE TABLE dbo.Products_InMemory ( ProductID INT NOT NULL, Name NVARCHAR(50) NOT NULL, ProductNumber NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlag BIT NULL, Color NVARCHAR(15) NULL, SafetyStockLevel SMALLINT NOT NULL, ReorderPoint SMALLINT NOT NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Size] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [Weight] DECIMAL(8, 2) NULL, DaysToManufacture INT NOT NULL, ProductLine NCHAR(2) NULL, [Class] NCHAR(2) NULL, Style NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, SellStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMARY KEY NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT = 256) ) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA ); INSERT dbo.Products_InMemory SELECT * FROM dbo.Products;
Ensuite, nous créons une procédure stockée compilée en mode natif qui prend notre type de table optimisé en mémoire existant comme TVP :
CREATE PROCEDURE dbo.InMemoryProcedure
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @Name NVARCHAR(50);
SELECT @Name = Name
FROM dbo.Products_InMemory AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO Quelques mises en garde. Nous ne pouvons pas utiliser un type de table standard non optimisé en mémoire comme paramètre d'une procédure stockée compilée en mode natif. Si nous essayons, nous obtenons :
Msg 41323, niveau 16, état 1, procédure InMemoryProcedureLe type de table 'dbo.ClassicTVP' n'est pas un type de table à mémoire optimisée et ne peut pas être utilisé dans une procédure stockée compilée en mode natif.
De plus, nous ne pouvons pas utiliser le EXISTS modèle ici non plus; quand on essaie, on obtient :
Les sous-requêtes (requêtes imbriquées dans une autre requête) ne sont pas prises en charge avec les procédures stockées compilées en mode natif.
Il existe de nombreuses autres mises en garde et limitations avec l'OLTP en mémoire et les procédures stockées compilées en mode natif, je voulais juste partager quelques éléments qui pourraient sembler manquer manifestement dans les tests.
Donc, en ajoutant cette nouvelle procédure stockée compilée nativement à la matrice de test ci-dessus, j'ai trouvé que - encore une fois, en moyenne sur 10 exécutions - elle exécutait les 100 000 itérations en seulement 1,25 seconde. Cela représente une amélioration d'environ 20 X par rapport aux TVP classiques et une amélioration de 6 à 7 X par rapport aux TVP en mémoire utilisant des tables et des procédures traditionnelles :
Résultats d'exécution montrant une amélioration jusqu'à 20X avec In-Memory tout autour
Conclusion
Si vous utilisez actuellement des TVP ou si vous utilisez des modèles qui pourraient être remplacés par des TVP, vous devez absolument envisager d'ajouter des TVP à mémoire optimisée à vos plans de test, mais en gardant à l'esprit que vous ne verrez peut-être pas les mêmes améliorations dans votre scénario. (Et, bien sûr, en gardant à l'esprit que les TVP en général ont beaucoup de mises en garde et de limitations, et qu'elles ne conviennent pas non plus à tous les scénarios. Erland Sommarskog a un excellent article sur les TVP d'aujourd'hui ici.)
En fait, vous pouvez voir qu'au bas du volume et de la simultanéité, il n'y a pas de différence - mais veuillez tester à une échelle réaliste. Il s'agissait d'un test très simple et artificiel sur un ordinateur portable moderne avec un seul SSD, mais lorsque vous parlez de volume réel et/ou de disques mécaniques tournants, ces caractéristiques de performance peuvent avoir beaucoup plus de poids. Il y a un suivi à venir avec quelques démonstrations sur des tailles de données plus importantes.