Introduction
Une bobine d'index avide lit toutes les lignes de son opérateur enfant dans une table de travail indexée, avant de commencer à renvoyer des lignes à son opérateur parent. À certains égards, une bobine d'index avide est la suggestion d'index manquant ultime , mais il n'est pas signalé comme tel.
Évaluation des coûts
L'insertion de lignes dans une table de travail indexée est relativement peu coûteuse, mais pas gratuite. L'optimiseur doit considérer que le travail impliqué économise plus qu'il ne coûte. Pour que cela joue en faveur du spool, il faut estimer que le plan consomme plus d'une fois les lignes du spool. Sinon, il pourrait tout aussi bien ignorer la bobine et ne faire l'opération sous-jacente qu'une seule fois.
- Pour être accessible plusieurs fois, le spool doit apparaître à l'intérieur d'un opérateur de jointure de boucles imbriquées.
- Chaque itération de la boucle doit rechercher une valeur de clé de bobine d'index particulière fournie par le côté extérieur de la boucle.
Cela signifie que la jointure doit être une application , pas une jointure de boucles imbriquées . Pour la différence entre les deux, veuillez consulter mon article Apply versus Nested Loops Join.
Caractéristiques notables
Alors qu'un spool d'index impatient ne peut apparaître que sur le côté intérieur d'une boucle imbriquée appliquer , ce n'est pas une « bobine de performance ». Un spool d'index impatient ne peut pas être désactivé avec l'indicateur de trace 8690 ou le NO_PERFORMANCE_SPOOL indice de requête.
Les lignes insérées dans la bobine d'index ne sont normalement pas pré-triées dans l'ordre des clés d'index, ce qui peut entraîner des fractionnements de page d'index. L'indicateur de trace non documenté 9260 peut être utilisé pour générer un Sort opérateur avant le spool d'index pour éviter cela. L'inconvénient est que le coût de tri supplémentaire peut dissuader l'optimiseur de choisir l'option spool.
SQL Server ne prend pas en charge les insertions parallèles dans un index b-tree. Cela signifie que tout ce qui se trouve en dessous d'un spool d'index avide parallèle s'exécute sur un seul thread. Les opérateurs sous la bobine sont toujours (de manière trompeuse) marqués de l'icône de parallélisme. Un fil est choisi pour écrire à la bobine. Les autres threads attendent EXECSYNC pendant que cela se termine. Une fois le spool rempli, il peut être lu depuis par des fils parallèles.
Les spools d'index n'indiquent pas à l'optimiseur qu'ils prennent en charge les sorties triées par les clés d'index du spool. Si une sortie triée du spool est requise, vous pouvez voir un Sort inutile opérateur. De toute façon, les bobines d'index impatientes doivent souvent être remplacées par un index permanent, c'est donc une préoccupation mineure la plupart du temps.
Cinq règles d'optimisation peuvent générer un Eager Index Spool option (connue en interne sous le nom d'index à la volée ). Nous examinerons trois d'entre eux en détail pour comprendre d'où viennent les spools d'index impatients.
SelToIndexOnTheFly
C'est le plus courant. Il correspond à une ou plusieurs sélections relationnelles (c'est-à-dire des filtres ou des prédicats) juste au-dessus d'un opérateur d'accès aux données. Le SelToIndexOnTheFly règle remplace les prédicats par un prédicat de recherche sur un spool d'index impatient.
Démo
Un AdventureWorks un exemple de base de données est illustré ci-dessous :
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%';
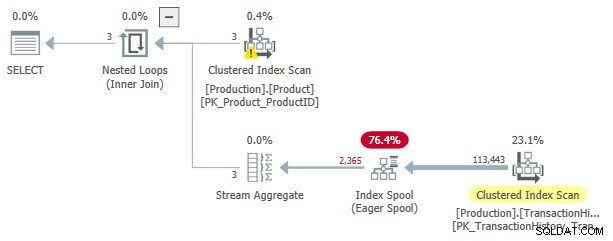
Ce plan d'exécution a un coût estimé à 3,0881 unités. Quelques points d'intérêt :
- La jointure interne des boucles imbriquées l'opérateur est une application , avec
ProductIDetSafetyStockLevelduProducttable comme références externes . - Lors de la première itération de l'application, le Eager Index Spool est entièrement renseigné à partir de l'analyse d'index cluster de l'
TransactionHistorytableau. - La table de travail du spool a un index clusterisé sur
(ProductID, Quantity). - Lignes correspondant aux prédicats
TH.ProductID = P.ProductIDetTH.Quantity < P.SafetyStockLevelsont répondus par le spool à l'aide de son index. Cela est vrai pour chaque itération de l'application, y compris la première. - L'
TransactionHistoryla table n'est scannée qu'une seule fois.
Entrée triée vers le spool
Il est possible d'imposer une entrée triée au spool d'index impatient, mais cela affecte le coût estimé, comme indiqué dans l'introduction. Pour l'exemple ci-dessus, l'activation de l'indicateur de trace non documenté produit un plan sans spool :
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%'
OPTION (QUERYTRACEON 9260);
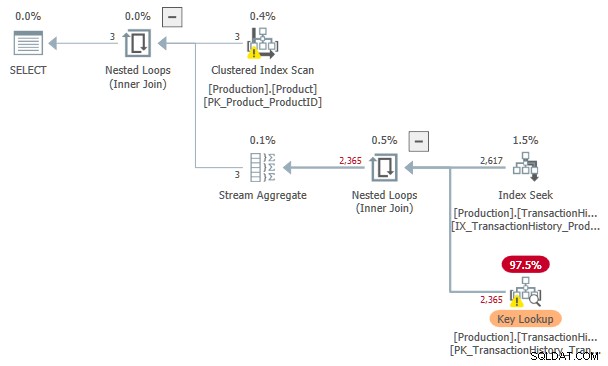
Le coût estimé de cette recherche d'index et Recherche de clé le plan est 3.11631 unités. C'est plus que le coût du plan avec un spool d'index seul, mais moins que le plan avec un spool d'index et une entrée triée.
Pour voir un plan avec une entrée triée dans le spool, nous devons augmenter le nombre attendu d'itérations de boucle. Cela donne à la bobine une chance de rembourser le coût supplémentaire du Tri . Une façon d'augmenter le nombre de lignes attendues du Product table est de faire le Name prédicat moins restrictif :
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'[A-P]%'
OPTION (QUERYTRACEON 9260); Cela nous donne un plan d'exécution avec une entrée triée dans le spool :
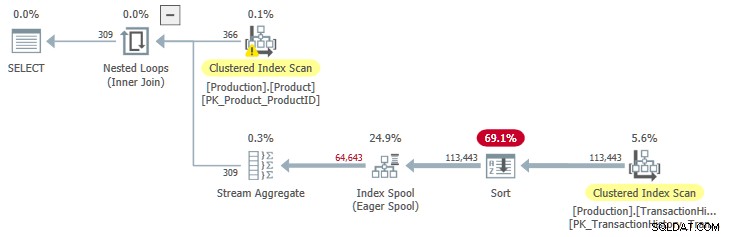
JoinToIndexOnTheFly
Cette règle transforme une jointure interne à une candidature , avec une bobine d'index avide sur le côté intérieur. Au moins un des prédicats de jointure doit être une inégalité pour que cette règle soit respectée.
Il s'agit d'une règle beaucoup plus spécialisée que SelToIndexOnTheFly , mais l'idée est sensiblement la même. Dans ce cas, la sélection (prédicat) transformée en une recherche de spool d'index est associée à la jointure. La transformation de joindre à appliquer permet au prédicat de jointure d'être déplacé de la jointure elle-même vers le côté interne de l'application.
Démo
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN);
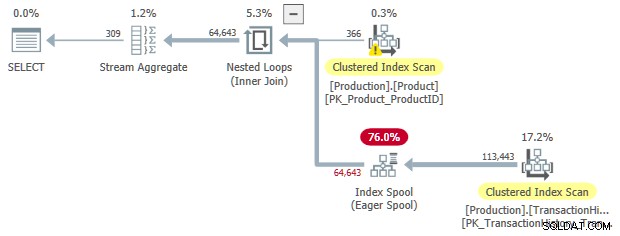
Comme précédemment, nous pouvons demander une entrée triée au spool :
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN, QUERYTRACEON 9260);
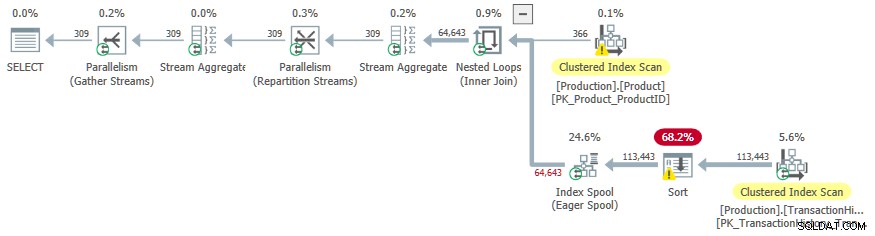
Cette fois, le surcoût du tri a incité l'optimiseur à choisir un plan parallèle.
Un effet secondaire indésirable est le Trier l'opérateur déborde sur tempdb . L'allocation totale de mémoire disponible pour le tri est suffisante, mais elle est également répartie entre les threads parallèles (comme d'habitude). Comme indiqué dans l'introduction, SQL Server ne prend pas en charge les insertions parallèles dans un index b-tree, de sorte que les opérateurs sous le spool d'index impatient s'exécutent sur un seul thread. Ce thread unique ne reçoit qu'une fraction de l'allocation de mémoire, donc le Sort déborde sur tempdb .
Cet effet secondaire est peut-être l'une des raisons pour lesquelles l'indicateur de trace n'est pas documenté et n'est pas pris en charge.
SelSTVFToIdxOnFly
Cette règle fait la même chose que SelToIndexOnTheFly , mais pour une fonction table de flux (sTVF) source de ligne. Ces sTVF sont largement utilisés en interne pour mettre en œuvre des DMV et des DMF, entre autres. Ils apparaissent dans les plans d'exécution modernes en tant que fonction de valeur de table opérateurs (à l'origine en tant que balayages de table distants ).
Dans le passé, bon nombre de ces sTVF ne pouvaient pas accepter les paramètres corrélés d'une application. Ils pourraient accepter des littéraux, des variables et des paramètres de module, mais pas appliquer références extérieures. Il y a encore des avertissements à ce sujet dans la documentation, mais ils sont quelque peu obsolètes maintenant.
Quoi qu'il en soit, le fait est que parfois il n'est pas possible pour SQL Server de passer un apply référence externe en tant que paramètre d'un sTVF. Dans cette situation, il peut être judicieux de matérialiser une partie du résultat sTVF dans un spool d'index impatient. La règle actuelle fournit cette possibilité.
Démo
L'exemple de code suivant montre une requête DMV qui est convertie avec succès d'une jointure à une application . Références externes sont passés en paramètres à la deuxième DMV :
-- Transformed to an apply
-- Outer reference passed as a parameter
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id = DES.session_id
OPTION (FORCE ORDER);
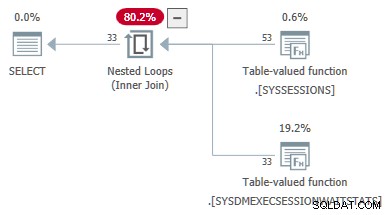
Les propriétés du plan des statistiques d'attente TVF affichent les paramètres d'entrée. La deuxième valeur de paramètre est fournie en tant que référence externe des séances DMV :
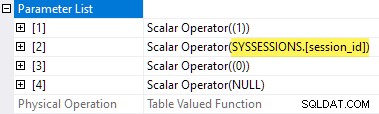
Il est dommage que sys.dm_exec_session_wait_stats est une vue, pas une fonction, car cela nous empêche d'écrire une application directement.
La réécriture ci-dessous suffit à vaincre la conversion interne :
-- Rewrite to avoid TVF parameter trickery
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id >= DES.session_id
AND DESWS.session_id <= DES.session_id
OPTION (FORCE ORDER);
Avec le session_id prédicats désormais non consommés en tant que paramètres, le SelSTVFToIdxOnFly la règle est libre de les convertir en un spool d'index impatient :
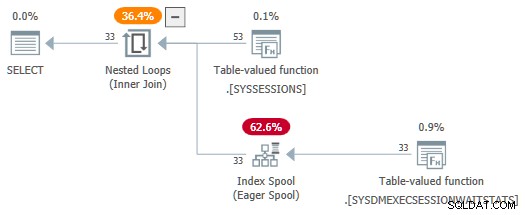
Je ne veux pas vous laisser l'impression que des réécritures délicates sont nécessaires pour obtenir une bobine d'index impatiente sur une source DMV - cela facilite simplement la démonstration. Si vous rencontrez une requête avec des jointures DMV qui produit un plan avec un spool impatient, vous savez au moins comment il est arrivé là.
Vous ne pouvez pas créer d'index sur les DMV, vous devrez donc peut-être utiliser un hachage ou une jointure de fusion si le plan d'exécution ne fonctionne pas assez bien.
CTE récursifs
Les deux règles restantes sont SelIterToIdxOnFly et JoinIterToIdxOnFly . Ce sont des homologues directs de SelToIndexOnTheFly et JoinToIndexOnTheFly pour les sources de données CTE récursives. Ceux-ci sont extrêmement rares dans mon expérience, donc je ne vais pas leur fournir de démos. (Juste pour que le Iter une partie du nom de la règle a du sens :cela vient du fait que SQL Server implémente la récursivité terminale sous forme d'itération imbriquée.)
Lorsqu'un CTE récursif est référencé plusieurs fois à l'intérieur d'une application, une règle différente (SpoolOnIterator ) peut mettre en cache le résultat du CTE :
WITH R AS
(
SELECT 1 AS n
UNION ALL
SELECT R.n + 1
FROM R
WHERE R.n < 10
)
SELECT
R1.n
FROM R AS R1
CROSS JOIN R AS R2; Le plan d'exécution comporte un rare Eager Row Count Spool :
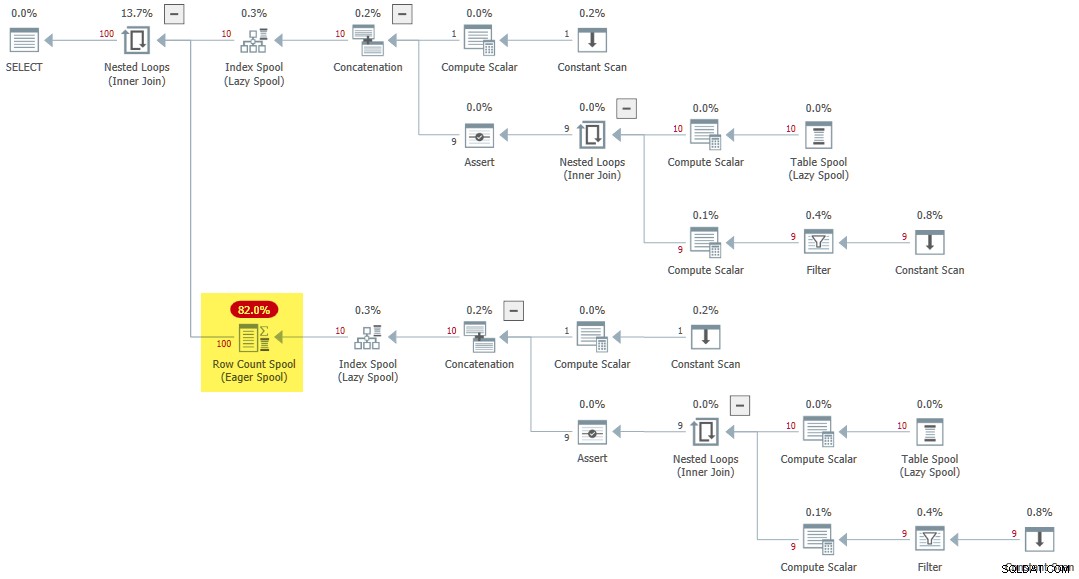
Réflexions finales
Les spools d'index impatients sont souvent le signe qu'un index permanent utile manque dans le schéma de la base de données. Ce n'est pas toujours le cas, comme le montrent les exemples de fonction de table de diffusion en continu.