L'une des principales exigences pour toute base de données est d'atteindre l'évolutivité. Cela ne peut être réalisé que si la contention (verrouillage) est minimisée autant que possible, voire supprimée. Étant donné que la lecture / écriture / mise à jour / suppression fait partie des principales opérations fréquentes dans la base de données, il est très important que ces opérations se poursuivent simultanément sans être bloquées. Pour ce faire, la plupart des principales bases de données utilisent un modèle de concurrence appelé Multi-Version Concurrency Control, ce qui réduit les conflits à un niveau minimum.
Qu'est-ce que le MVCC
Le contrôle de concurrence multi-versions (ci-après MVCC) est un algorithme permettant de contrôler finement la concurrence en maintenant plusieurs versions du même objet afin que les opérations READ et WRITE n'entrent pas en conflit. Ici, WRITE signifie UPDATE et DELETE, car l'enregistrement nouvellement INSÉRÉ sera de toute façon protégé selon le niveau d'isolement. Chaque opération WRITE produit une nouvelle version de l'objet et chaque opération de lecture simultanée lit une version différente de l'objet en fonction du niveau d'isolement. Étant donné que la lecture et l'écriture fonctionnent toutes deux sur différentes versions du même objet, aucune de ces opérations n'a besoin de se verrouiller complètement et, par conséquent, les deux peuvent fonctionner simultanément. Le seul cas où le conflit peut encore exister est lorsque deux transactions simultanées tentent d'ÉCRIRE le même enregistrement.
La plupart des principales bases de données actuelles prennent en charge MVCC. L'intention de cet algorithme est de maintenir plusieurs versions du même objet, de sorte que l'implémentation de MVCC diffère d'une base de données à l'autre uniquement en termes de création et de maintenance de plusieurs versions. En conséquence, le fonctionnement de la base de données correspondante et le stockage des modifications de données.
L'approche la plus reconnue pour implémenter MVCC est celle utilisée par PostgreSQL et Firebird/Interbase et une autre est utilisée par InnoDB et Oracle. Dans les sections suivantes, nous discuterons en détail de la façon dont il a été implémenté dans PostgreSQL et InnoDB.
MVCC dans PostgreSQL
Afin de prendre en charge plusieurs versions, PostgreSQL maintient des champs supplémentaires pour chaque objet (Tuple dans la terminologie PostgreSQL) comme mentionné ci-dessous :
- xmin - ID de transaction de la transaction qui a inséré ou mis à jour le tuple. En cas de mise à jour, une version plus récente du tuple est attribuée avec cet ID de transaction.
- xmax - ID de transaction de la transaction qui a supprimé ou mis à jour le tuple. En cas de mise à jour, une version actuellement existante de tuple se voit attribuer cet ID de transaction. Sur un tuple nouvellement créé, la valeur par défaut de ce champ est null.
PostgreSQL stocke toutes les données dans un stockage principal appelé HEAP (page de taille par défaut de 8 Ko). Tout le nouveau tuple obtient xmin en tant que transaction qui l'a créé et l'ancien tuple de version (qui a été mis à jour ou supprimé) est assigné avec xmax. Il y a toujours un lien entre l'ancien tuple de version et la nouvelle version. L'ancien tuple de version peut être utilisé pour recréer le tuple en cas de restauration et pour lire une ancienne version d'un tuple par l'instruction READ en fonction du niveau d'isolement.
Considérez qu'il y a deux tuples, T1 (avec la valeur 1) et T2 (avec la valeur 2) pour une table, la création de nouvelles lignes peut être démontrée en 3 étapes ci-dessous :
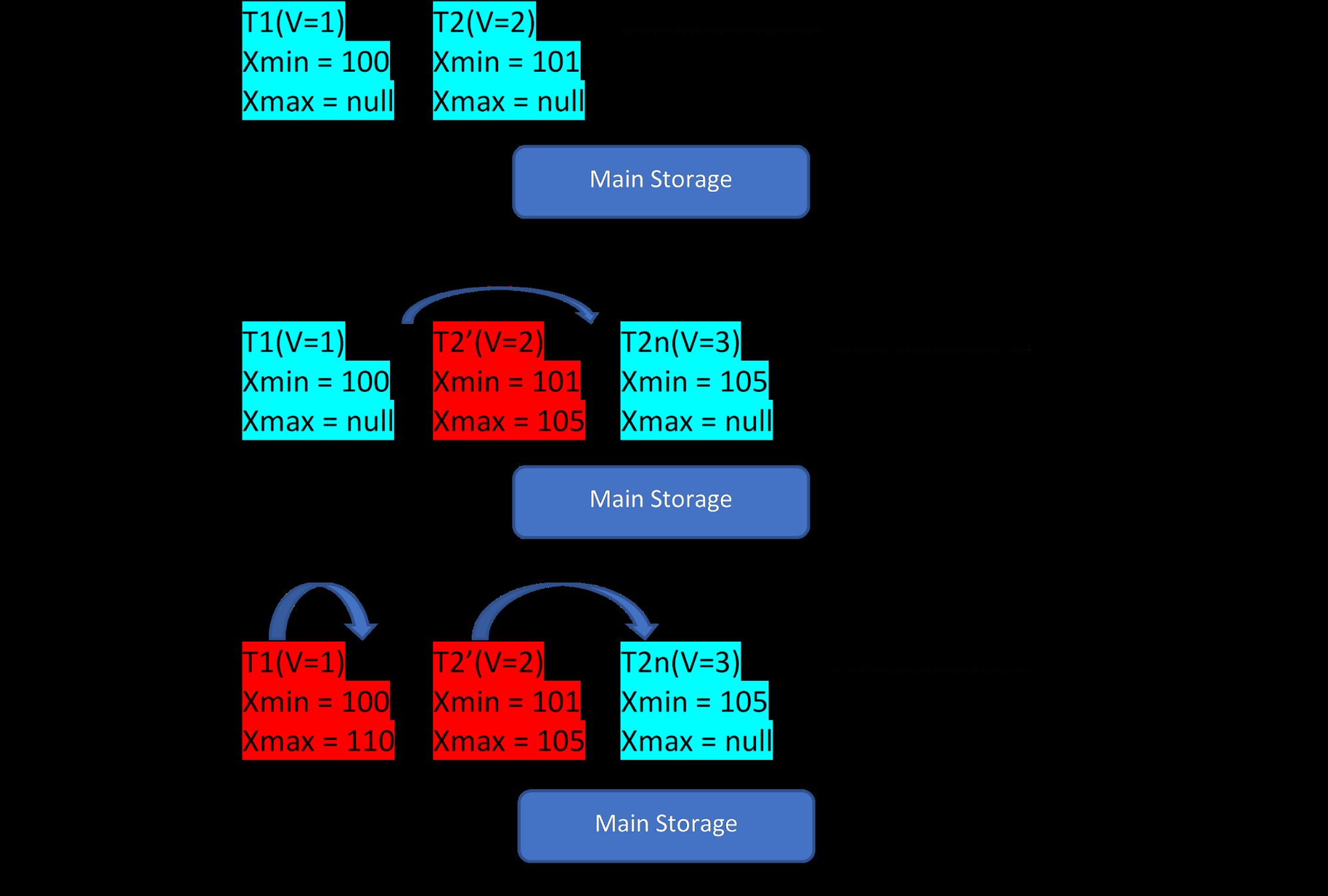 MVCC :Stockage de plusieurs versions dans PostgreSQL
MVCC :Stockage de plusieurs versions dans PostgreSQL Comme on le voit sur l'image, il y a initialement deux tuples dans la base de données avec les valeurs 1 et 2.
Ensuite, selon la deuxième étape, la ligne T2 avec la valeur 2 est mise à jour avec la valeur 3. À ce stade, une nouvelle version est créée avec la nouvelle valeur et elle est simplement stockée à côté du tuple existant dans la même zone de stockage. . Avant cela, l'ancienne version est affectée avec xmax et pointe vers le tuple de la dernière version.
De même, à la troisième étape, lorsque la ligne T1 avec la valeur 1 est supprimée, la ligne existante est pratiquement supprimée (c'est-à-dire qu'elle vient d'attribuer xmax avec la transaction en cours) au même endroit. Aucune nouvelle version n'est créée pour cela.
Ensuite, voyons comment chaque opération crée plusieurs versions et comment le niveau d'isolement des transactions est maintenu sans verrouillage avec quelques exemples réels. Dans tous les exemples ci-dessous, l'isolation "READ COMMITTED" est utilisée par défaut.
INSÉRER
Chaque fois qu'un enregistrement est inséré, il crée un nouveau tuple, qui est ajouté à l'une des pages appartenant à la table correspondante.
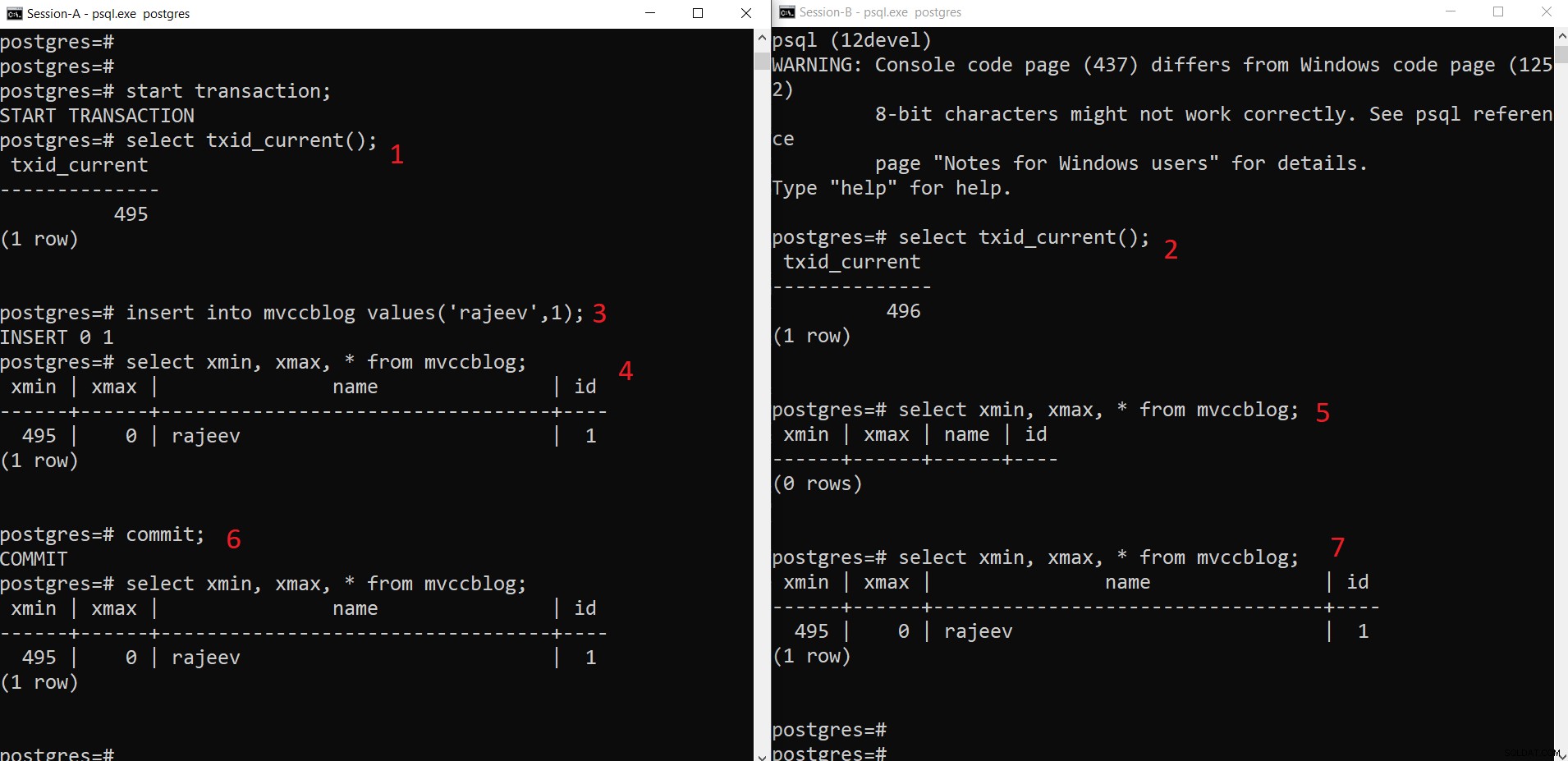 Opération INSERT simultanée PostgreSQL
Opération INSERT simultanée PostgreSQL Comme nous pouvons le voir ici étape par étape :
- Session-A démarre une transaction et obtient l'ID de transaction 495.
- Session-B démarre une transaction et obtient l'ID de transaction 496.
- Session-A insère un nouveau tuple (est stocké dans HEAP)
- Maintenant, le nouveau tuple avec xmin défini sur l'ID de transaction actuel 495 est ajouté.
- Mais la même chose n'est pas visible depuis Session-B car xmin (c'est-à-dire 495) n'est toujours pas validé.
- Une fois engagé.
- Les données sont visibles pour les deux sessions.
MISE À JOUR
PostgreSQL UPDATE n'est pas une mise à jour "EN PLACE", c'est-à-dire qu'il ne modifie pas l'objet existant avec la nouvelle valeur requise. Au lieu de cela, il crée une nouvelle version de l'objet. Ainsi, UPDATE implique globalement les étapes ci-dessous :
- Il marque l'objet actuel comme supprimé.
- Ensuite, il ajoute une nouvelle version de l'objet.
- Redirigez l'ancienne version de l'objet vers une nouvelle version.
Ainsi, même si un certain nombre d'enregistrements restent les mêmes, HEAP prend de l'espace comme si un autre enregistrement était inséré.
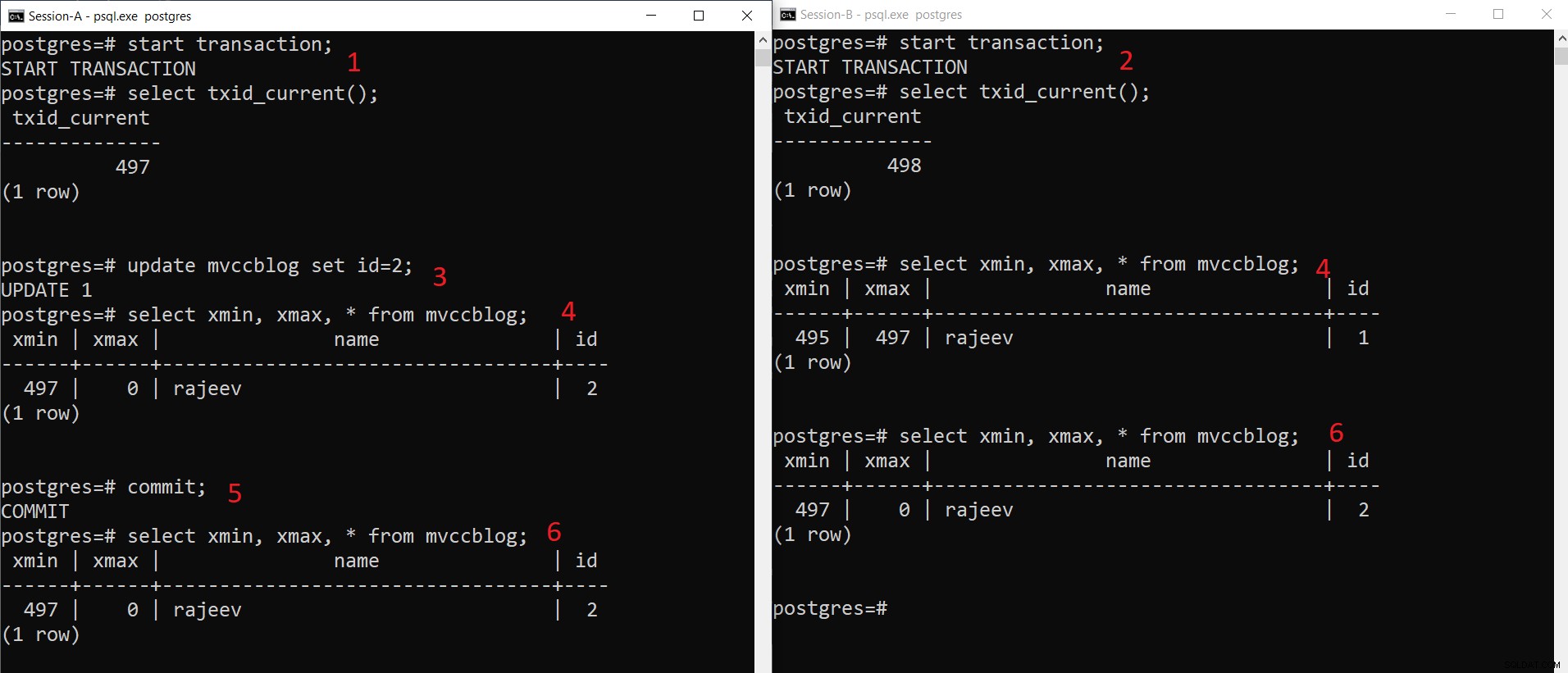 Opération INSERT simultanée PostgreSQL
Opération INSERT simultanée PostgreSQL Comme nous pouvons le voir ici étape par étape :
- Session-A démarre une transaction et obtient l'ID de transaction 497.
- Session-B démarre une transaction et obtient l'ID de transaction 498.
- Session-A met à jour l'enregistrement existant.
- Ici, Session-A voit une version du tuple (tuple mis à jour) tandis que Session-B voit une autre version (tuple plus ancien mais xmax défini sur 497). Les deux versions de tuple sont stockées dans le stockage HEAP (même la même page en fonction de la disponibilité de l'espace)
- Une fois que Session-A a validé la transaction, l'ancien tuple expire lorsque xmax de l'ancien tuple est validé.
- Maintenant, les deux sessions voient la même version de l'enregistrement.
SUPPRIMER
Supprimer est presque comme l'opération UPDATE sauf qu'il n'est pas nécessaire d'ajouter une nouvelle version. Il marque simplement l'objet actuel comme SUPPRIMÉ comme expliqué dans le cas UPDATE.
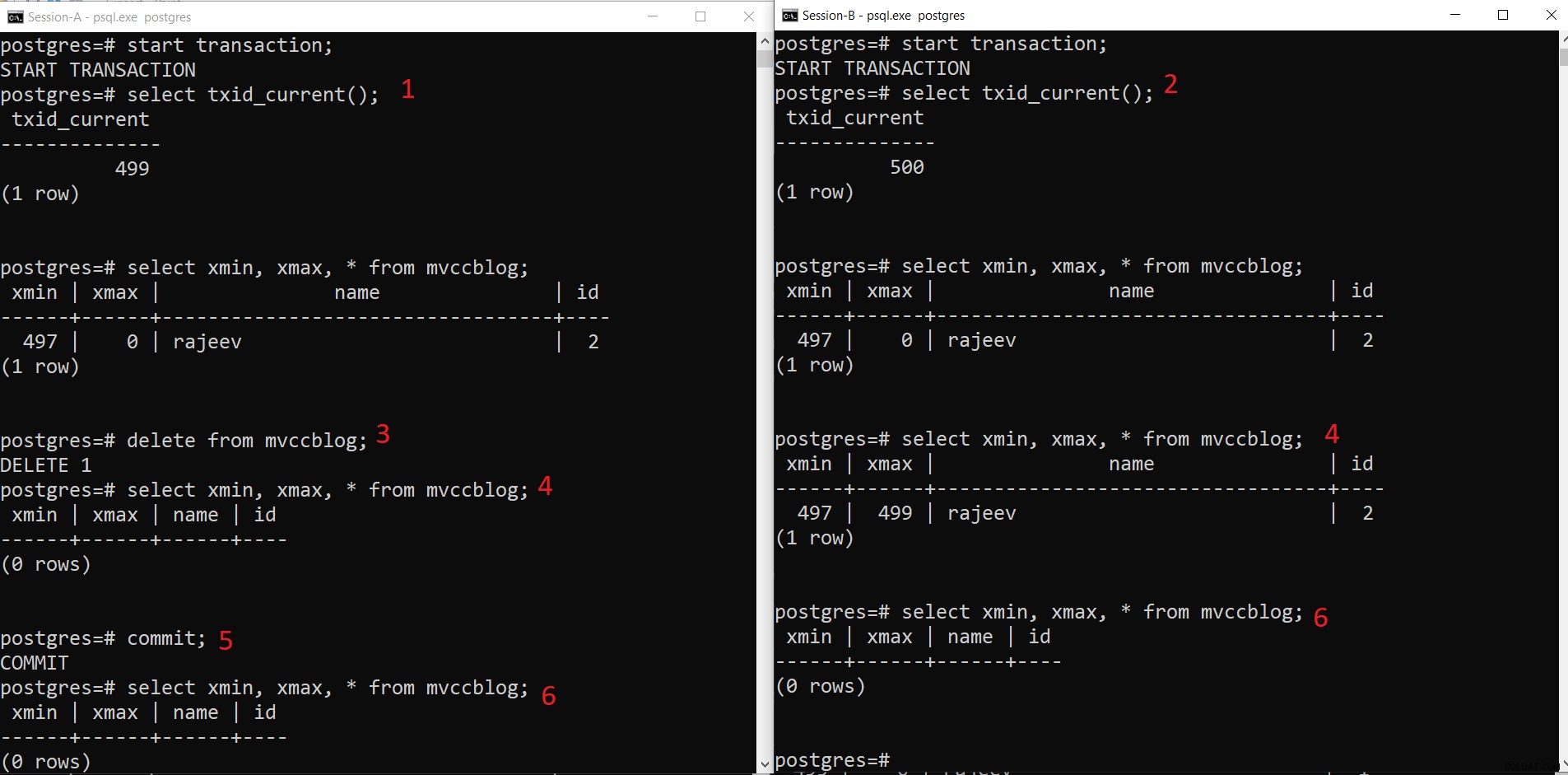 Opération DELETE concurrente PostgreSQL
Opération DELETE concurrente PostgreSQL - Session-A démarre une transaction et obtient l'ID de transaction 499.
- Session-B démarre une transaction et obtient l'ID de transaction 500.
- Session-A supprime l'enregistrement existant.
- Ici, Session-A ne voit aucun tuple supprimé de la transaction en cours. Alors que Session-B voit une ancienne version du tuple (avec xmax comme 499 ; la transaction qui a supprimé cet enregistrement).
- Une fois que Session-A a validé la transaction, l'ancien tuple expire lorsque xmax de l'ancien tuple est validé.
- Maintenant, les deux sessions ne voient pas le tuple supprimé.
Comme nous pouvons le voir, aucune des opérations ne supprime directement la version existante de l'objet et, si nécessaire, elle ajoute une version supplémentaire de l'objet.
Voyons maintenant comment la requête SELECT est exécutée sur un tuple ayant plusieurs versions :SELECT doit lire toutes les versions du tuple jusqu'à ce qu'il trouve le tuple approprié selon le niveau d'isolement. Supposons qu'il y ait un tuple T1, qui a été mis à jour et a créé une nouvelle version T1' et qui à son tour a créé T1'' lors de la mise à jour :
- L'opération SELECT passera par le stockage de tas pour cette table et vérifiera d'abord T1. Si la transaction T1 xmax est validée, elle passe à la version suivante de ce tuple.
- Supposons maintenant que le tuple xmax de T1 est également validé, puis il passe à nouveau à la version suivante de ce tuple.
- Enfin, il trouve T1'' et voit que xmax n'est pas validé (ou nul) et que T1'' xmin est visible pour la transaction en cours selon le niveau d'isolement. Enfin, il lira le tuple T1''.
Comme nous pouvons le voir, il doit parcourir les 3 versions du tuple afin de trouver le tuple visible approprié jusqu'à ce que le tuple expiré soit supprimé par le ramasse-miettes (VACUUM).
MVCC dans InnoDB
Afin de prendre en charge plusieurs versions, InnoDB maintient des champs supplémentaires pour chaque ligne comme mentionné ci-dessous :
- DB_TRX_ID :ID de transaction de la transaction qui a inséré ou mis à jour la ligne.
- DB_ROLL_PTR :il est également appelé le pointeur d'annulation et il pointe vers l'enregistrement de journal d'annulation écrit dans le segment d'annulation (plus d'informations à ce sujet).
Comme PostgreSQL, InnoDB crée également plusieurs versions de la ligne dans le cadre de toutes les opérations, mais le stockage de l'ancienne version est différent.
Dans le cas d'InnoDB, l'ancienne version de la ligne modifiée est conservée dans un tablespace/stockage séparé (appelé segment d'annulation). Ainsi, contrairement à PostgreSQL, InnoDB ne conserve que la dernière version des lignes dans la zone de stockage principale et l'ancienne version est conservée dans le segment d'annulation. Les versions de ligne du segment d'annulation sont utilisées pour annuler l'opération en cas de restauration et pour lire une ancienne version des lignes par l'instruction READ en fonction du niveau d'isolement.
Considérez qu'il y a deux lignes, T1 (avec la valeur 1) et T2 (avec la valeur 2) pour une table, la création de nouvelles lignes peut être démontrée en 3 étapes ci-dessous :
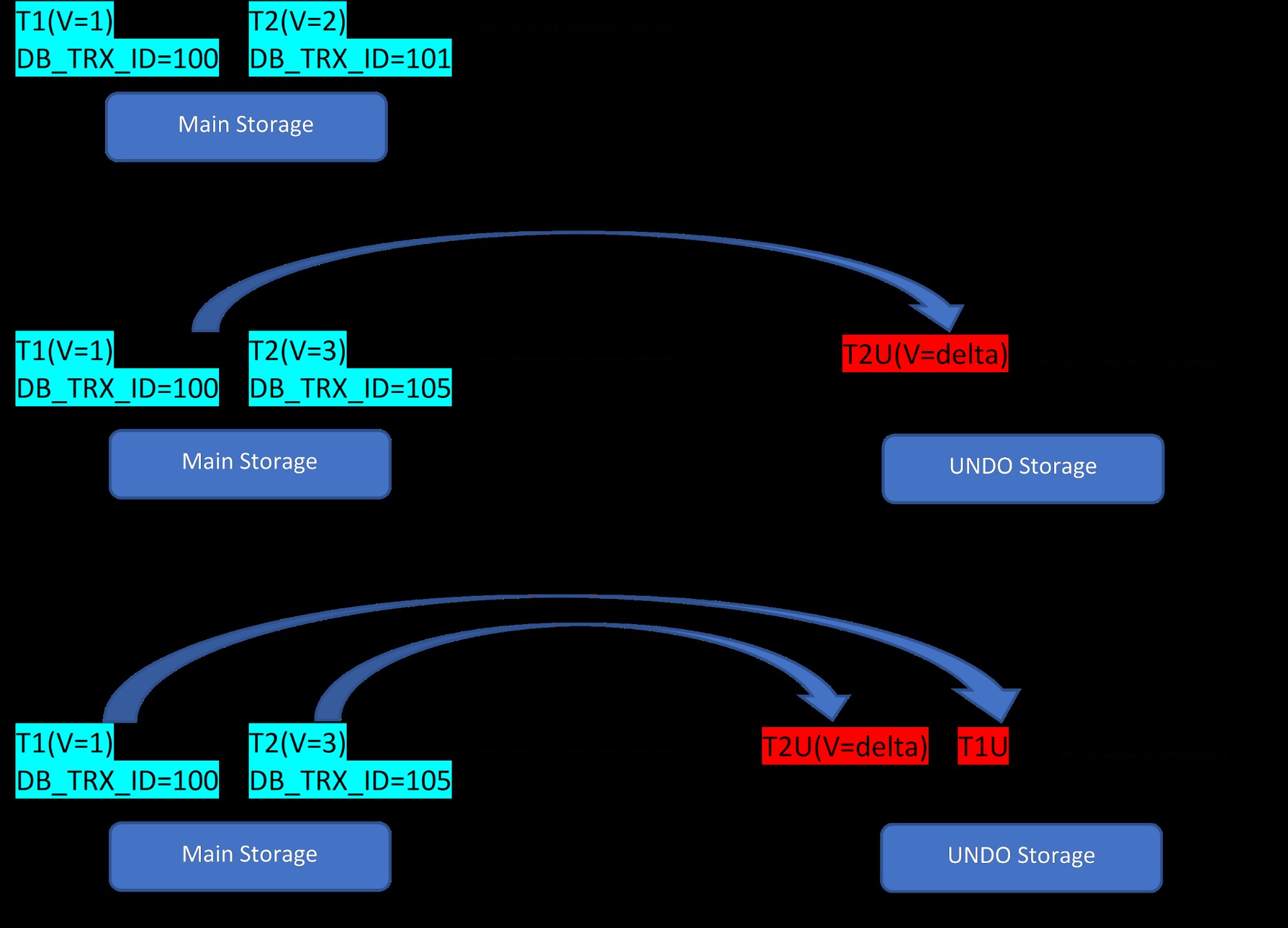 MVCC :Stockage de plusieurs versions dans InnoDB
MVCC :Stockage de plusieurs versions dans InnoDB Comme le montre la figure, il y a initialement deux lignes dans la base de données avec les valeurs 1 et 2.
Ensuite, selon la deuxième étape, la ligne T2 avec la valeur 2 est mise à jour avec la valeur 3. À ce stade, une nouvelle version est créée avec la nouvelle valeur et remplace l'ancienne version. Avant cela, l'ancienne version est stockée dans le segment d'annulation (notez que la version du segment UNDO n'a qu'une valeur delta). Notez également qu'il existe un pointeur de la nouvelle version vers l'ancienne version dans le segment d'annulation. Ainsi, contrairement à PostgreSQL, la mise à jour d'InnoDB est "EN PLACE".
De même, dans la troisième étape, lorsque la ligne T1 avec la valeur 1 est supprimée, la ligne existante est virtuellement supprimée (c'est-à-dire qu'elle marque simplement un bit spécial dans la ligne) dans la zone de stockage principale et une nouvelle version correspondant à celle-ci est ajoutée dans le segment Annuler. Encore une fois, il y a un pointeur de roulement entre le stockage principal et le segment d'annulation.
Toutes les opérations se comportent de la même manière que dans le cas de PostgreSQL lorsqu'elles sont vues de l'extérieur. Seul le stockage interne de plusieurs versions diffère.
Téléchargez le livre blanc aujourd'hui PostgreSQL Management &Automation with ClusterControlDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blancMVCC :PostgreSQL contre InnoDB
Analysons maintenant quelles sont les principales différences entre PostgreSQL et InnoDB en termes d'implémentation de MVCC :
-
Taille d'une ancienne version
PostgreSQL ne fait que mettre à jour xmax sur l'ancienne version du tuple, de sorte que la taille de l'ancienne version reste la même que celle de l'enregistrement inséré correspondant. Cela signifie que si vous avez 3 versions d'un tuple plus ancien, elles auront toutes la même taille (à l'exception de la différence de taille réelle des données, le cas échéant, à chaque mise à jour).
Alors que dans le cas d'InnoDB, la version d'objet stockée dans le segment Undo est généralement plus petite que l'enregistrement inséré correspondant. En effet, seules les valeurs modifiées (c'est-à-dire différentielles) sont écrites dans le journal UNDO.
-
Opération INSÉRER
InnoDB doit écrire un enregistrement supplémentaire dans le segment UNDO même pour INSERT alors que PostgreSQL ne crée une nouvelle version qu'en cas de UPDATE.
-
Restauration d'une ancienne version en cas de restauration
PostgreSQL n'a besoin de rien de spécifique pour restaurer une ancienne version en cas de restauration. N'oubliez pas que l'ancienne version a xmax égal à la transaction qui a mis à jour ce tuple. Ainsi, jusqu'à ce que cet identifiant de transaction soit validé, il est considéré comme un tuple vivant pour un instantané simultané. Une fois la transaction annulée, la transaction correspondante sera automatiquement considérée comme active pour toutes les transactions car il s'agira d'une transaction abandonnée.
Alors que dans le cas d'InnoDB, il est explicitement nécessaire de reconstruire l'ancienne version de l'objet une fois la restauration effectuée.
-
Récupérer l'espace occupé par une ancienne version
Dans le cas de PostgreSQL, l'espace occupé par une ancienne version ne peut être considéré comme mort que lorsqu'il n'y a pas d'instantané parallèle pour lire cette version. Une fois l'ancienne version morte, l'opération VACUUM peut récupérer l'espace qu'elle occupait. VACUUM peut être déclenché manuellement ou en arrière-plan selon la configuration.
Les journaux InnoDB UNDO sont principalement divisés en INSERT UNDO et UPDATE UNDO. Le premier est supprimé dès que la transaction correspondante est validée. Le second doit être conservé jusqu'à ce qu'il soit parallèle à tout autre instantané. InnoDB n'a pas d'opération VACUUM explicite mais sur une ligne similaire, il a PURGE asynchrone pour supprimer les journaux UNDO qui s'exécutent en tâche de fond.
-
Impact du vide retardé
Comme discuté dans un point précédent, il y a un impact énorme du vide retardé dans le cas de PostgreSQL. Cela fait que la table commence à gonfler et à augmenter l'espace de stockage même si les enregistrements sont constamment supprimés. Il peut également atteindre un point où VACUUM FULL doit être effectué, ce qui est une opération très coûteuse.
-
Scan séquentiel en cas de tableau gonflé
L'analyse séquentielle PostgreSQL doit parcourir toutes les anciennes versions d'un objet même si elles sont toutes mortes (jusqu'à ce qu'elles soient supprimées à l'aide de vacuum). C'est le problème typique et le plus évoqué dans PostgreSQL. N'oubliez pas que PostgreSQL stocke toutes les versions d'un tuple dans le même stockage.
Alors que dans le cas d'InnoDB, il n'est pas nécessaire de lire l'enregistrement d'annulation sauf si cela est nécessaire. Dans le cas où tous les enregistrements d'annulation sont morts, il suffira alors de lire toutes les dernières versions des objets.
-
Index
PostgreSQL stocke l'index dans un stockage séparé qui conserve un lien vers les données réelles dans HEAP. Donc PostgreSQL doit également mettre à jour la partie INDEX même s'il n'y a pas eu de changement dans INDEX. Bien que plus tard, ce problème ait été résolu en implémentant la mise à jour HOT (Heap Only Tuple), mais il a toujours la limitation que si un nouveau tuple de tas ne peut pas être hébergé dans la même page, alors il revient à UPDATE normal.
InnoDB n'a pas ce problème car ils utilisent un index clusterisé.
Conclusion
PostgreSQL MVCC a quelques inconvénients, en particulier en termes de stockage gonflé si votre charge de travail a des mises à jour/suppressions fréquentes. Donc, si vous décidez d'utiliser PostgreSQL, vous devez faire très attention à configurer VACUUM judicieusement.
La communauté PostgreSQL a également reconnu cela comme un problème majeur et ils ont déjà commencé à travailler sur l'approche MVCC basée sur UNDO (nom provisoire comme ZHEAP) et nous pourrions voir la même chose dans une future version.