Disons que vous voulez trouver tous les patients qui n'ont jamais été vaccinés contre la grippe. Ou, dans AdventureWorks2012 , une question similaire pourrait être "montre-moi tous les clients qui n'ont jamais passé de commande". Exprimé en utilisant NOT IN , un modèle que je vois trop souvent, qui ressemblerait à ceci (j'utilise l'en-tête agrandi et les tableaux de détails de ce script de Jonathan Kehayias (@SQLPoolBoy)) :
SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
Quand je vois ce modèle, je grince des dents. Mais pas pour des raisons de performances - après tout, cela crée un plan assez décent dans ce cas :
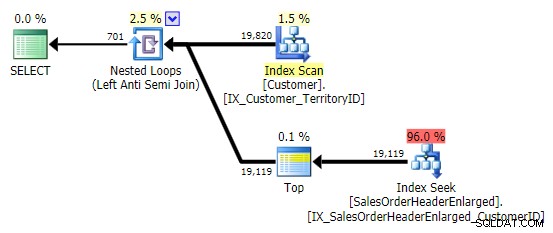
Le principal problème est que les résultats peuvent être surprenants si la colonne cible est NULLable (SQL Server traite cela comme une anti-semi-jointure gauche, mais ne peut pas vous dire de manière fiable si un NULL sur le côté droit est égal à - ou non égal à – la référence sur le côté gauche). De plus, l'optimisation peut se comporter différemment si la colonne est NULLable, même si elle ne contient en fait aucune valeur NULL (Gail Shaw en a parlé en 2010).
Dans ce cas, la colonne cible n'est pas nullable, mais je voulais mentionner ces problèmes potentiels avec NOT IN – J'examinerai peut-être ces problèmes plus en détail dans un prochain article.
TL;Version DR
Au lieu de NOT IN , utilisez un NOT EXISTS corrélé pour ce modèle de requête. Toujours. D'autres méthodes peuvent rivaliser avec elle en termes de performances, lorsque toutes les autres variables sont identiques, mais toutes les autres méthodes introduisent soit des problèmes de performances, soit d'autres défis.
Alternatives
Alors, de quelles autres manières pouvons-nous écrire cette requête ?
APPLIQUER EXTÉRIEUR
Une façon d'exprimer ce résultat consiste à utiliser un OUTER APPLY corrélé .
SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
Logiquement, il s'agit également d'une anti-semi-jointure gauche, mais le plan résultant manque l'opérateur anti-semi-jointure gauche et semble être un peu plus cher que le NOT IN équivalent. En effet, il ne s'agit plus d'une jointure anti-semi gauche ; il est en fait traité d'une manière différente :une jointure externe apporte toutes les lignes correspondantes et non correspondantes, et *ensuite* un filtre est appliqué pour éliminer les correspondances :
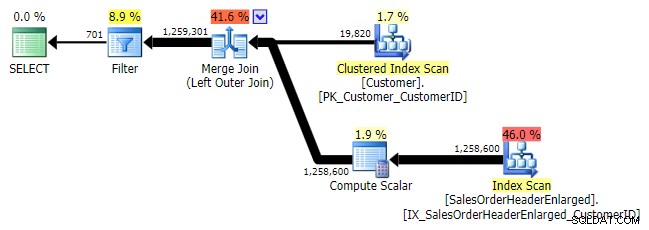
JOINTURE EXTERNE GAUCHE
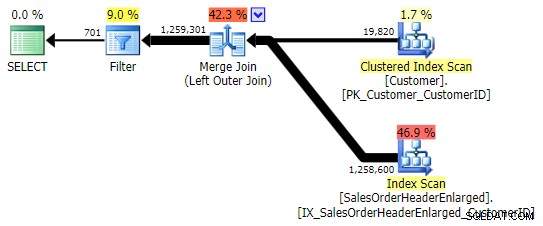
Une alternative plus typique est LEFT OUTER JOIN où le côté droit est NULL . Dans ce cas, la requête serait :
SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
Cela renvoie les mêmes résultats; cependant, comme OUTER APPLY, il utilise la même technique consistant à joindre toutes les lignes, puis à éliminer les correspondances :
Vous devez cependant faire attention à la colonne que vous vérifiez pour NULL . Dans ce cas CustomerID est le choix logique car il s'agit de la colonne de jointure ; il se trouve aussi qu'il est indexé. J'aurais pu choisir SalesOrderID , qui est la clé de clustering, elle est donc également dans l'index sur CustomerID . Mais j'aurais pu choisir une autre colonne qui n'est pas dans (ou qui est supprimée plus tard) de l'index utilisé pour la jointure, conduisant à un plan différent. Ou même une colonne NULLable, conduisant à des résultats incorrects (ou du moins inattendus), car il n'y a aucun moyen de faire la différence entre une ligne qui n'existe pas et une ligne qui existe mais où cette colonne est NULL . Et il n'est peut-être pas évident pour le lecteur/développeur/dépanneur que ce soit le cas. Je vais donc également tester ces trois WHERE clauses :
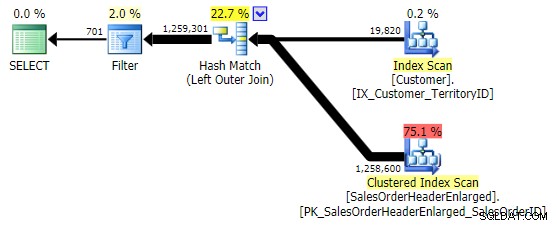
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
La première variante produit le même plan que ci-dessus. Les deux autres choisissent une jointure par hachage au lieu d'une jointure par fusion, et un index plus étroit dans le Customer table, même si la requête finit par lire exactement le même nombre de pages et la même quantité de données. Cependant, alors que le h.SubTotal variation produit les résultats corrects :
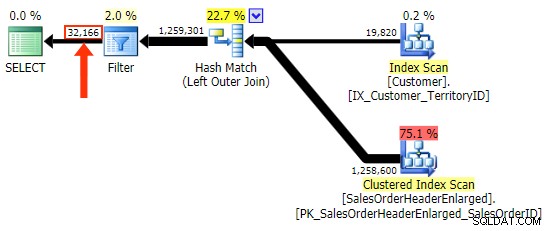
Le h.Comment la variation ne le fait pas, car elle inclut toutes les lignes où h.Comment IS NULL , ainsi que toutes les lignes qui n'existaient pour aucun client. J'ai mis en évidence la différence subtile dans le nombre de lignes dans la sortie après l'application du filtre :
En plus de devoir faire attention à la sélection des colonnes dans le filtre, l'autre problème que j'ai avec le LEFT OUTER JOIN forme est qu'elle n'est pas auto-documentée, de la même manière qu'une jointure interne dans la forme "à l'ancienne" de FROM dbo.table_a, dbo.table_b WHERE ... ne s'auto-documente pas. J'entends par là qu'il est facile d'oublier les critères de jointure lorsqu'ils sont poussés vers WHERE clause, ou pour qu'elle soit mélangée avec d'autres critères de filtre. Je sais que c'est assez subjectif, mais c'est comme ça.
SAUF
Si tout ce qui nous intéresse est la colonne de jointure (qui par définition est dans les deux tables), nous pouvons utiliser EXCEPT – une alternative qui ne semble pas apparaître beaucoup dans ces conversations (probablement parce que – généralement – vous devez étendre la requête afin d'inclure des colonnes que vous ne comparez pas) :
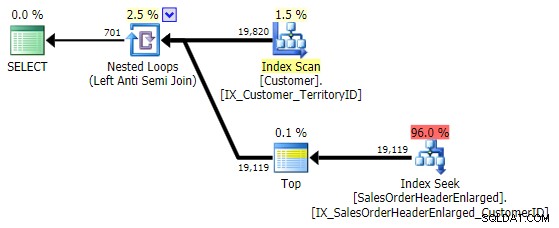
SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
Cela revient exactement au même plan que le NOT IN variante ci-dessus :
Une chose à garder à l'esprit est que EXCEPT inclut un DISTINCT implicite - donc si vous avez des cas où vous voulez que plusieurs lignes aient la même valeur dans la table "gauche", ce formulaire éliminera ces doublons. Pas un problème dans ce cas spécifique, juste quelque chose à garder à l'esprit - tout comme UNION versus UNION ALL .
N'EXISTE PAS
Ma préférence pour ce modèle est définitivement NOT EXISTS :
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(Et oui, j'utilise SELECT 1 au lieu de SELECT * … pas pour des raisons de performances, car SQL Server ne se soucie pas de la ou des colonnes que vous utilisez dans EXISTS et les optimise, mais simplement pour clarifier l'intention :cela me rappelle que cette "sous-requête" ne renvoie aucune donnée.)
Ses performances sont similaires à NOT IN et EXCEPT , et il produit un plan identique, mais n'est pas sujet aux problèmes potentiels causés par les valeurs NULL ou les doublons :
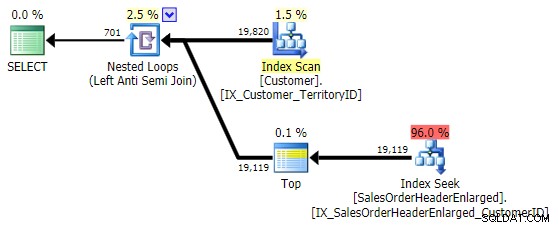
Tests de performances
J'ai effectué une multitude de tests, avec un cache froid et chaud, pour valider que ma perception de longue date sur NOT EXISTS être le bon choix est resté vrai. La sortie typique ressemblait à ceci :
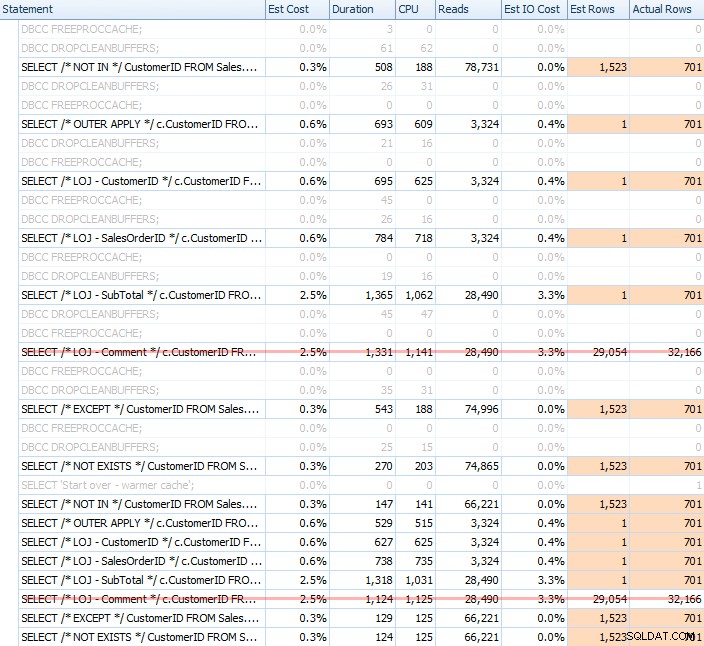
Je retirerai le résultat incorrect du mélange lorsque je montrerai la performance moyenne de 20 exécutions sur un graphique (je ne l'ai inclus que pour démontrer à quel point les résultats sont faux), et j'ai exécuté les requêtes dans un ordre différent à travers les tests pour m'assurer qu'une requête ne bénéficiait pas systématiquement du travail d'une requête précédente. En se concentrant sur la durée, voici les résultats :
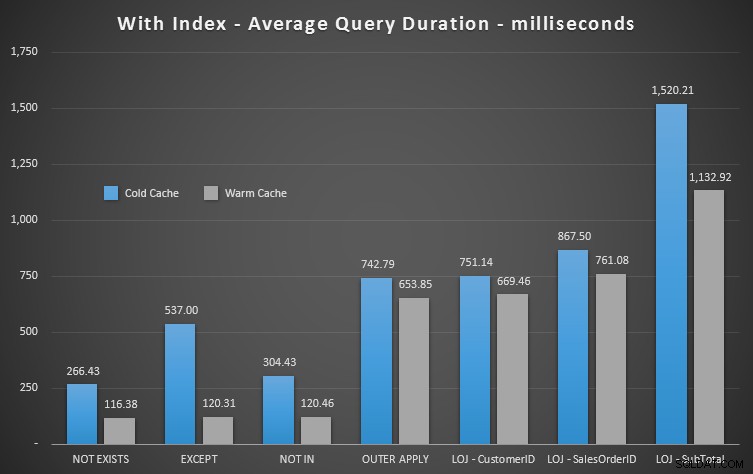
Si nous examinons la durée et ignorons les lectures, NOT EXISTS est votre gagnant, mais pas de beaucoup. EXCEPT et NOT IN ne sont pas loin derrière, mais encore une fois, vous devez examiner plus que les performances pour déterminer si ces options sont valides et tester dans votre scénario.
Et s'il n'y a pas d'index de support ?
Les requêtes ci-dessus bénéficient bien entendu de l'index sur Sales.SalesOrderHeaderEnlarged.CustomerID . Comment ces résultats changent-ils si nous baissons cet indice ? J'ai exécuté à nouveau le même ensemble de tests, après avoir supprimé l'index :
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
Cette fois, il y avait beaucoup moins d'écart en termes de performances entre les différentes méthodes. Je vais d'abord montrer les plans de chaque méthode (dont la plupart, sans surprise, indiquent l'utilité de l'index manquant que nous venons de supprimer). Ensuite, je montrerai un nouveau graphique illustrant le profil de performance à la fois avec un cache froid et un cache chaud.
PAS DANS, SAUF, PAS EXISTE (les trois étaient identiques)
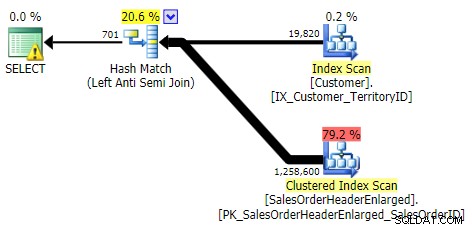
APPLIQUER EXTÉRIEUR
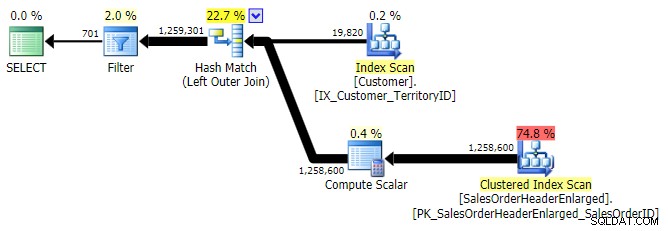
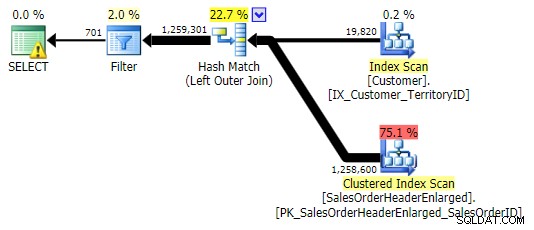
LEFT OUTER JOIN (les trois sont identiques sauf le nombre de lignes)
Résultats des performances
On voit immédiatement l'utilité de l'indice quand on regarde ces nouveaux résultats. Dans tous les cas sauf un (la jointure externe gauche qui sort de toute façon de l'index), les résultats sont clairement pires lorsque nous avons supprimé l'index :
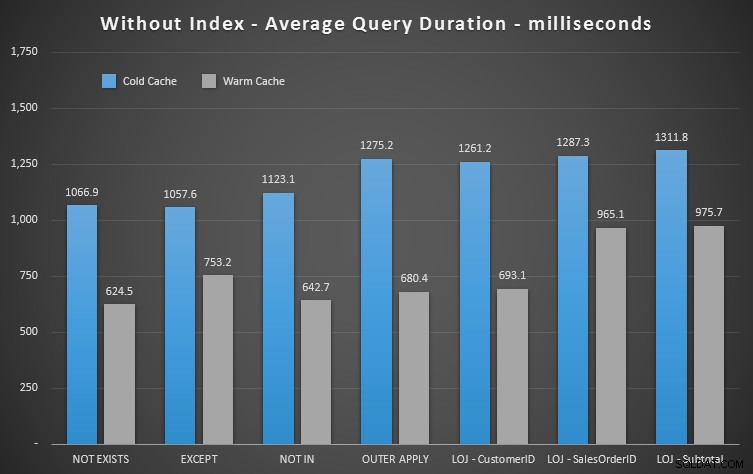
Nous pouvons donc voir que, bien qu'il y ait un impact moins notable, NOT EXISTS est toujours votre gagnant marginal en termes de durée. Et dans les situations où les autres approches sont sensibles à la volatilité du schéma, c'est aussi votre choix le plus sûr.
Conclusion
C'était juste une façon très longue de vous dire que, pour le modèle de recherche de toutes les lignes de la table A où une condition n'existe pas dans la table B, NOT EXISTS sera généralement votre meilleur choix. Mais, comme toujours, vous devez tester ces modèles dans votre propre environnement, en utilisant votre schéma, vos données et votre matériel, et mélangés à vos propres charges de travail.