J'ai récemment été réprimandé pour avoir suggéré que, dans certains cas, un index non clusterisé fonctionnera mieux pour une requête particulière que l'index clusterisé. Cette personne a déclaré que l'index clusterisé est toujours le meilleur car il couvre toujours par définition, et que tout index non clusterisé avec certaines ou toutes les mêmes colonnes clés était toujours redondant.
Je conviendrai volontiers que l'index clusterisé couvre toujours (et pour éviter toute ambiguïté ici, nous allons nous en tenir aux tables sur disque avec les index B-tree traditionnels).
 Je ne suis pas d'accord, cependant, qu'un index clusterisé est toujours plus rapide qu'un index non clusterisé. Je ne suis pas non plus d'accord sur le fait qu'il est toujours redondant de créer un index non clusterisé ou une contrainte unique composée des mêmes colonnes (ou de certaines des mêmes) dans la clé de clustering.
Je ne suis pas d'accord, cependant, qu'un index clusterisé est toujours plus rapide qu'un index non clusterisé. Je ne suis pas non plus d'accord sur le fait qu'il est toujours redondant de créer un index non clusterisé ou une contrainte unique composée des mêmes colonnes (ou de certaines des mêmes) dans la clé de clustering.
Prenons cet exemple, Warehouse.StockItemTransactions , de WideWorldImporters. L'index clusterisé est implémenté via une clé primaire uniquement sur StockItemTransactionID colonne (assez typique lorsque vous avez une sorte d'ID de substitution généré par une IDENTITÉ ou une SÉQUENCE).
C'est une chose assez courante d'exiger un décompte de toute la table (bien que dans de nombreux cas, il existe de meilleures façons). Cela peut être pour une inspection occasionnelle ou dans le cadre d'une procédure de pagination. La plupart des gens procéderont ainsi :
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
Avec le schéma actuel, cela utilisera un index non cluster :
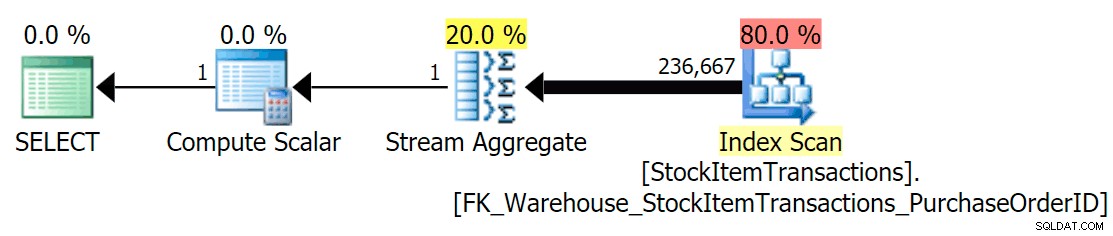
Nous savons que l'index non clusterisé ne contient pas toutes les colonnes de l'index clusterisé. L'opération de comptage doit seulement s'assurer que toutes les lignes sont incluses, sans se soucier des colonnes présentes, donc SQL Server choisira généralement l'index avec le plus petit nombre de pages (dans ce cas, l'index choisi a ~ 414 pages).
Maintenant, exécutons à nouveau la requête, cette fois en la comparant à une requête implicite qui force l'utilisation de l'index clusterisé.
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
Nous obtenons une forme de plan presque identique, mais nous pouvons voir une énorme différence dans les lectures (414 pour l'index choisi contre 1 982 pour l'index clusterisé) :
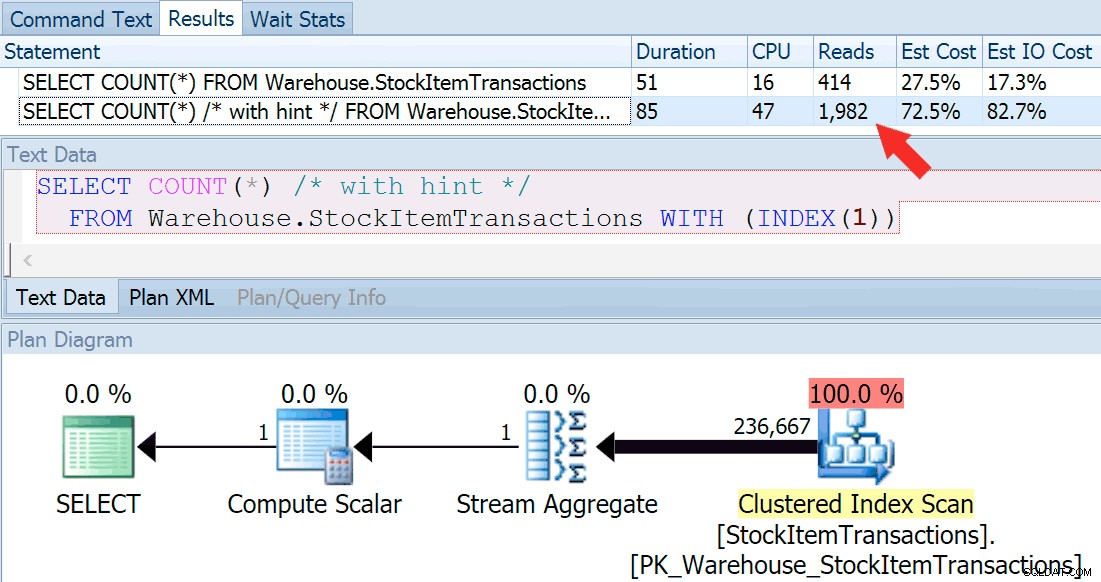
La durée est légèrement supérieure pour l'index clusterisé, mais la différence est négligeable lorsqu'il s'agit d'une petite quantité de données en cache sur un disque rapide. Cet écart serait beaucoup plus prononcé avec plus de données, sur un disque lent ou sur un système avec une pression de mémoire.
Si nous regardons les info-bulles des opérations d'analyse, nous pouvons voir que si le nombre de lignes et les coûts CPU estimés sont identiques, la grande différence vient du coût d'E/S estimé (car SQL Server sait qu'il y a plus de pages dans le index clusterisé que l'index non clusterisé) :
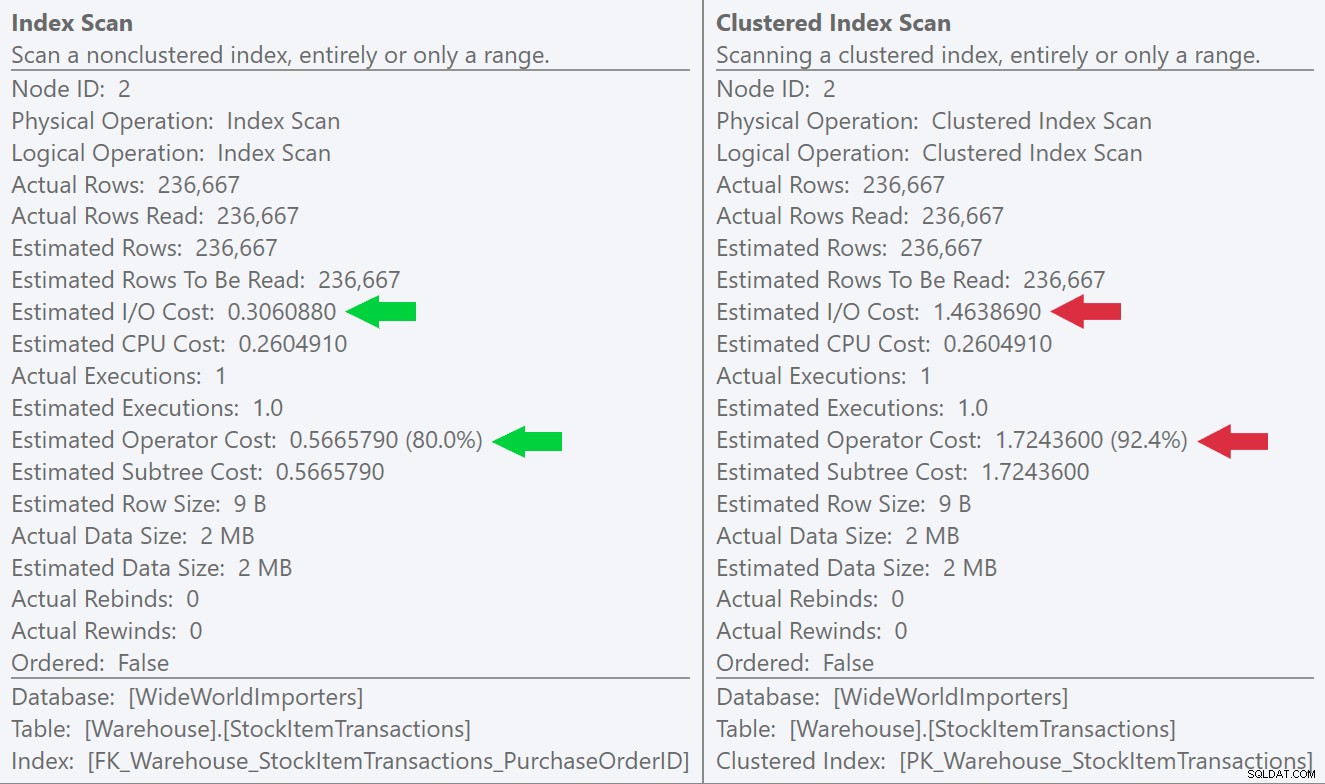
Nous pouvons voir cette différence encore plus clairement si nous créons un nouvel index unique uniquement sur la colonne ID (ce qui le rend "redondant" avec l'index clusterisé, n'est-ce pas ?) :
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
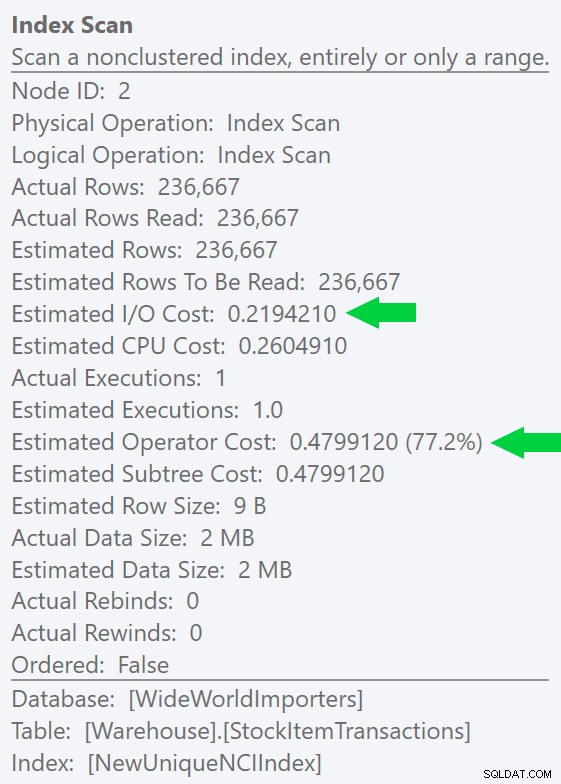 L'exécution d'une requête similaire avec un indice d'index explicite produit la même forme de plan, mais une estimation d'E/S encore plus faible coût (et même des durées inférieures) - voir l'image à droite. Et si vous exécutez la requête d'origine sans l'indice, vous verrez que SQL Server choisit désormais également cet index.
L'exécution d'une requête similaire avec un indice d'index explicite produit la même forme de plan, mais une estimation d'E/S encore plus faible coût (et même des durées inférieures) - voir l'image à droite. Et si vous exécutez la requête d'origine sans l'indice, vous verrez que SQL Server choisit désormais également cet index.
Cela peut sembler évident, mais beaucoup de gens croiraient que l'index clusterisé est le meilleur choix ici. SQL Server va presque toujours privilégier fortement la méthode qui fournira le moyen le moins cher d'effectuer toutes les E/S, et dans le cas d'une analyse complète, ce sera l'index "le plus maigre". Cela peut également se produire avec les deux types de recherches (singleton et range scans), au moins lorsque l'index couvre.
Maintenant, comme toujours, cela ne le fait pas signifie en aucun cas que vous devez aller créer des index supplémentaires sur toutes vos tables pour satisfaire les requêtes de comptage. Non seulement c'est un moyen inefficace de vérifier la taille de la table (encore une fois, voir cet article), mais un index à prendre en charge devrait signifier que vous exécutez cette requête plus souvent que vous ne mettez à jour les données. N'oubliez pas que chaque index nécessite de l'espace sur le disque, de l'espace sur la mémoire et que toutes les écritures sur la table doivent également toucher chaque index (index filtrés mis à part).
Résumé
Je pourrais proposer de nombreux autres exemples qui montrent quand un non-cluster peut être utile et valoir le coût de la maintenance, même lors de la duplication de la ou des colonnes clés de l'index clusterisé. Des index non clusterisés peuvent être créés avec les mêmes colonnes de clé mais dans un ordre de clé différent, ou avec différents ASC/DESC sur les colonnes elles-mêmes pour mieux prendre en charge un ordre de présentation alternatif. Vous pouvez également avoir des index non clusterisés qui ne transportent qu'un petit sous-ensemble de lignes grâce à l'utilisation d'un filtre. Enfin, si vous pouvez satisfaire vos requêtes les plus courantes avec des index plus fins et non clusterisés, c'est également mieux pour la consommation de mémoire.
Mais vraiment, mon but de cette série est simplement de montrer un contre-exemple qui illustre la folie de faire des déclarations générales comme celle-ci. Je vous laisse avec une explication de Paul White qui, dans une réponse DBA.SE, explique pourquoi un tel index non clusterisé peut en fait être beaucoup plus performant qu'un index clusterisé. Cela est vrai même lorsque les deux utilisent l'un ou l'autre type de recherche :
- Différence entre la recherche d'index clusterisé et la recherche d'index non clusterisé