Puppet est un logiciel open source pour la gestion et le déploiement de la configuration. Fondée en 2005, elle est multiplateforme et possède même son propre langage déclaratif pour la configuration.

Les tâches liées à l'administration et à la maintenance de PostgreSQL (ou d'autres logiciels vraiment) se compose de processus quotidiens et répétitifs qui nécessitent une surveillance. Cela s'applique même aux tâches exécutées par des scripts ou des commandes via un outil de planification. La complexité de ces tâches augmente de manière exponentielle lorsqu'elles sont exécutées sur une infrastructure massive, cependant, l'utilisation de Puppet pour ce type de tâches peut souvent résoudre ces types de problèmes à grande échelle car Puppet centralise et automatise les performances de ces opérations de manière très agile.
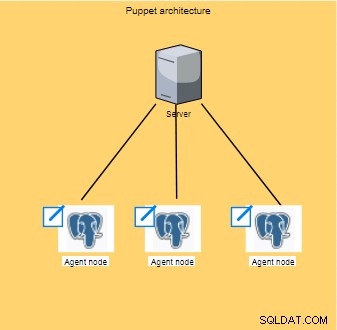
Puppet fonctionne au sein de l'architecture au niveau client/serveur où la configuration est effectuée ; ces opérations sont ensuite diffusées et exécutées sur tous les clients (également appelés nœuds).
Typiquement exécuté toutes les 30 minutes, le nœud des agents va collecter un ensemble d'informations (type de processeur, architecture, adresse IP, etc.), également appelées faits, puis envoie les informations au master qui attend une réponse pour voir s'il y a de nouvelles configurations à appliquer.
Ces faits permettront au maître de personnaliser la même configuration pour chaque nœud.
D'une manière très simpliste, Puppet est l'un des outils DevOps les plus importants disponible aujourd'hui. Dans ce blog, nous examinerons les éléments suivants...
- Le cas d'utilisation de Puppet et PostgreSQL
- Installer Puppet
- Configurer et programmer Puppet
- Configurer Puppet pour PostgreSQL
L'installation et la configuration de Puppet (version 5.3.10) décrites ci-dessous ont été effectuées sur un ensemble d'hôtes utilisant CentOS 7.0 comme système d'exploitation.
Le cas d'utilisation de Puppet et PostgreSQL
Supposons qu'il y ait un problème dans votre pare-feu sur les machines qui hébergent tous vos serveurs PostgreSQL, il faudrait alors refuser toutes les connexions sortantes vers PostgreSQL, et le faire dès que possible.

Puppet est l'outil parfait pour cette situation, surtout parce que la vitesse et l'efficacité sont essentiel. Nous reparlerons de cet exemple présenté dans la section "Configuration de Puppet pour PostgreSQL" en gérant le paramètre listen_addresses.
Installer Puppet
Il existe un ensemble d'étapes courantes à effectuer sur les hôtes maîtres ou agents :
Première étape
Mise à jour du fichier /etc/hosts avec les noms d'hôtes et leur adresse IP
192.168.1.85 agent agent.severalnines.com
192.168.1.87 master master.severalnines.com puppetÉtape 2
Ajout des référentiels Puppet sur le système
$ sudo rpm –Uvh https://yum.puppetlabs.com/puppet5/el/7/x86_64/puppet5-release-5.0.0-1-el7.noarch.rpmPour les autres systèmes d'exploitation ou versions de CentOS, le référentiel le plus approprié se trouve dans Puppet, Inc. Yum Repositories.
Étape 3
Configuration du serveur NTP (Network Time Protocol)
$ sudo yum -y install chronyÉtape 4
Le chrony est utilisé pour synchroniser l'horloge système de différents serveurs NTP et maintient ainsi l'heure synchronisée entre le serveur maître et l'agent.
Une fois chrony installé, il doit être activé et redémarré :
$ sudo systemctl enable chronyd.service
$ sudo systemctl restart chronyd.serviceÉtape 5
Désactiver le paramètre SELinux
Sur le fichier /etc/sysconfig/selinux, le paramètre SELINUX (Security-Enhanced Linux) doit être désactivé afin de ne pas restreindre l'accès sur les deux hôtes.
SELINUX=disabledÉtape 6
Avant l'installation de Puppet (maître ou agent), le pare-feu de ces hôtes doit être défini en conséquence :
$ sudo firewall-cmd -–add-service=ntp -–permanent
$ sudo firewall-cmd –-reload Installation de Puppet Master
Une fois le référentiel de packages puppet5-release-5.0.0-1-el7.noarch.rpm ajouté au système, l'installation de puppetserver peut être effectuée :
$ sudo yum install -y puppetserverLe paramètre d'allocation de mémoire maximale est un paramètre important à mettre à jour sur le fichier /etc/sysconfig/puppetserver à 2 Go (ou à 1 Go si le service ne démarre pas) :
JAVA_ARGS="-Xms2g –Xmx2g "Dans le fichier de configuration /etc/puppetlabs/puppet/puppet.conf il faut ajouter le paramétrage suivant :
[master]
dns_alt_names=master.severalnines.com,puppet
[main]
certname = master.severalnines.com
server = master.severalnines.com
environment = production
runinterval = 1hLe service puppetserver utilise le port 8140 pour écouter les requêtes du nœud, il est donc nécessaire de s'assurer que ce port sera activé :
$ sudo firewall-cmd --add-port=8140/tcp --permanent
$ sudo firewall-cmd --reloadUne fois tous les réglages effectués dans puppet master, il est temps de démarrer ce service :
$ sudo systemctl start puppetserver
$ sudo systemctl enable puppetserver
Installer l'agent Puppet
L'agent Puppet dans le référentiel de packages puppet5-release-5.0.0-1-el7.noarch.rpm est également ajouté au système, l'installation de l'agent puppet peut être effectuée immédiatement :
$ sudo yum install -y puppet-agentLe fichier de configuration puppet-agent /etc/puppetlabs/puppet/puppet.conf doit également être mis à jour en ajoutant le paramètre suivant :
[main]
certname = agent.severalnines.com
server = master.severalnines.com
environment = production
runinterval = 1hL'étape suivante consiste à enregistrer le nœud agent sur l'hôte maître en exécutant la commande suivante :
$ sudo /opt/puppetlabs/bin/puppet resource service puppet ensure=running enable=true
service { ‘puppet’:
ensure => ‘running’,
enable => ‘true’
}En ce moment, sur l'hôte maître, il y a une demande en attente de l'agent marionnette pour signer un certificat :

Cela doit être signé en exécutant l'une des commandes suivantes :
$ sudo /opt/puppetlabs/bin/puppet cert sign agent.severalnines.comou
$ sudo /opt/puppetlabs/bin/puppet cert sign --allEnfin (et une fois que le puppet master a signé le certificat) il est temps d'appliquer les configurations à l'agent en récupérant le catalogue du puppet master :
$ sudo /opt/puppetlabs/bin/puppet agent --testDans cette commande, le paramètre --test ne signifie pas un test, les paramètres récupérés du maître seront appliqués à l'agent local. Pour tester/vérifier les configurations depuis le maître, la commande suivante doit être exécutée :
$ sudo /opt/puppetlabs/bin/puppet agent --noopConfigurer et programmer la marionnette
Puppet utilise une approche de programmation déclarative sur laquelle le but est de spécifier ce qu'il faut faire et peu importe la manière d'y parvenir !
Le morceau de code le plus élémentaire sur Puppet est la ressource qui spécifie une propriété système telle qu'une commande, un service, un fichier, un répertoire, un utilisateur ou un package.
Ci-dessous est présentée la syntaxe d'une ressource pour créer un utilisateur :
user { 'admin_postgresql':
ensure => present,
uid => '1000',
gid => '1000',
home => '/home/admin/postresql'
}Différentes ressources peuvent être jointes à l'ancienne classe (également connue sous le nom de manifeste) de fichier avec l'extension "pp" (il signifie Puppet Program), néanmoins, plusieurs manifestes et données (tels que des faits, fichiers et modèles) composeront un module. Toutes ces hiérarchies et règles logiques sont représentées dans le schéma ci-dessous :
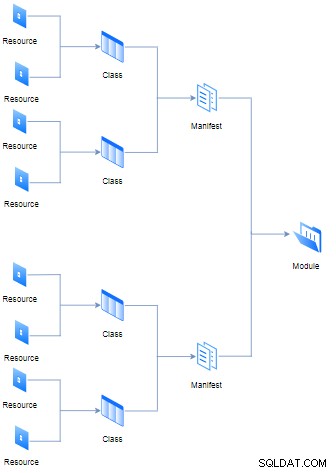
Le but de chaque module est de contenir tous les manifestes nécessaires pour exécuter un seul tâches de manière modulaire. D'autre part, le concept de classe n'est pas le même que celui des langages de programmation orientés objet, dans Puppet, il fonctionne comme un agrégateur de ressources.
L'organisation de ces fichiers a une structure de répertoire spécifique à suivre :
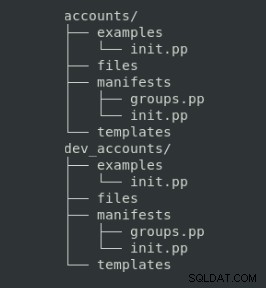
Sur lequel le but de chaque dossier est le suivant :
| Dossier | Description |
| manifestes | Code de marionnette |
| fichiers | Fichiers statiques à copier sur les nœuds |
| modèles | Fichiers modèles à copier sur les nœuds gérés (ils peuvent être personnalisés avec des variables) |
| exemples | Manifeste pour montrer comment utiliser le module |
class dev_accounts {
$rootgroup = $osfamily ? {
'Debian' => 'sudo',
'RedHat' => 'wheel',
default => warning('This distribution is not supported by the Accounts module'),
}
include accounts::groups
user { 'username':
ensure => present,
home => '/home/admin/postresql',
shell => '/bin/bash',
managehome => true,
gid => 'admin_db',
groups => "$rootgroup",
password => '$1$7URTNNqb$65ca6wPFDvixURc/MMg7O1'
}
}Dans la section suivante, nous vous montrerons comment générer le contenu du dossier d'exemples ainsi que les commandes pour tester et publier chaque module.
Configurer Puppet pour PostgreSQL
Avant de présenter les différents exemples de configuration pour déployer et maintenir une base de données PostgreSQL, il est nécessaire d'installer le module puppet PostgreSQL (sur l'hôte du serveur) pour utiliser toutes leurs fonctionnalités :
$ sudo /opt/puppetlabs/bin/puppet module install puppetlabs-postgresqlActuellement, des milliers de modules prêts à l'emploi sur Puppet sont disponibles sur le référentiel de modules public Puppet Forge.
Première étape
Configurez et déployez une nouvelle instance PostgreSQL. Voici toute la programmation et la configuration nécessaires pour installer une nouvelle instance PostgreSQL dans tous les nœuds.
La première étape consiste à créer un nouveau répertoire de structure de module comme partagé précédemment :
$ cd /etc/puppetlabs/code/environments/production/modules
$ mkdir db_postgresql_admin
$ cd db_postgresql_admin; mkdir{examples,files,manifests,templates}Ensuite, dans le fichier manifeste manifests/init.pp, vous devez inclure la classe postgresql::server fournie par le module installé :
class db_postgresql_admin{
include postgresql::server
}Pour vérifier la syntaxe du manifeste, il est recommandé d'exécuter la commande suivante :
$ sudo /opt/puppetlabs/bin/puppet parser validate init.ppSi rien n'est retourné, cela signifie que la syntaxe est correcte
Pour vous montrer comment utiliser ce module dans le dossier d'exemple, il est nécessaire de créer un nouveau fichier manifeste init.pp avec le contenu suivant :
include db_postgresql_adminL'exemple d'emplacement dans le module doit être testé et appliqué au catalogue maître :
$ sudo /opt/puppetlabs/bin/puppet apply --modulepath=/etc/puppetlabs/code/environments/production/modules --noop init.ppEnfin, il faut définir à quel module chaque nœud a accès dans le fichier « /etc/puppetlabs/code/environments/production/manifests/site.pp » :
node ’agent.severalnines.com’,’agent2.severalnines.com’{
include db_postgresql_admin
}Ou une configuration par défaut pour tous les nœuds :
node default {
include db_postgresql_admin
}Habituellement toutes les 30min les nœuds vérifient le catalogue principal, néanmoins cette requête peut être forcée côté nœud par la commande suivante :
$ /opt/puppetlabs/bin/puppet agent -tOu si le but est de simuler les différences entre la configuration principale et les paramètres actuels du nœud, il peut être utilisé le paramètre nopp (pas d'opération) :
$ /opt/puppetlabs/bin/puppet agent -t --noopÉtape 2
Mettre à jour l'instance PostgreSQL pour écouter toutes les interfaces. L'installation précédente définit un paramètre d'instance dans un mode très restrictif :n'autorise que les connexions sur localhost comme cela peut être confirmé par les hôtes associés pour le port 5432 (défini pour PostgreSQL) :
$ sudo netstat -ntlp|grep 5432
tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN 3237/postgres
tcp6 0 0 ::1:5432 :::* LISTEN 3237/postgres Afin de permettre l'écoute de toutes les interfaces, il est nécessaire d'avoir le contenu suivant dans le fichier /etc/puppetlabs/code/environments/production/modules/db_postgresql_admin/manifests/init.pp
class db_postgresql_admin{
class{‘postgresql:server’:
listen_addresses=>’*’ #listening all interfaces
}
}Dans l'exemple ci-dessus, la classe postgresql::server est déclarée et le paramètre listen_addresses est défini sur "*", ce qui signifie toutes les interfaces.
Maintenant, le port 5432 est associé à toutes les interfaces, il peut être confirmé avec l'adresse IP/le port suivant :"0.0.0.0:5432"
$ sudo netstat -ntlp|grep 5432
tcp 0 0 0.0.0.0:5432 0.0.0.0:* LISTEN 1232/postgres
tcp6 0 0 :::5432 :::* LISTEN 1232/postgres Pour rétablir le paramètre initial :autoriser uniquement les connexions à la base de données à partir de localhost, le paramètre listen_addresses doit être défini sur "localhost" ou en spécifiant une liste d'hôtes, si vous le souhaitez :
listen_addresses = 'agent2.severalnines.com,agent3.severalnines.com,localhost'Pour récupérer la nouvelle configuration de l'hôte maître, il suffit de la demander sur le nœud :
$ /opt/puppetlabs/bin/puppet agent -tÉtape 3
Créer une base de données PostgreSQL. L'instance PostgreSQL peut être créée avec une nouvelle base de données ainsi qu'un nouvel utilisateur (avec mot de passe) pour utiliser cette base de données et une règle sur le fichier pg_hab.conf pour autoriser la connexion à la base de données pour ce nouvel utilisateur :
class db_postgresql_admin{
class{‘postgresql:server’:
listen_addresses=>’*’ #listening all interfaces
}
postgresql::server::db{‘nines_blog_db’:
user => ‘severalnines’, password=> postgresql_password(‘severalnines’,’passwd12’)
}
postgresql::server::pg_hba_rule{‘Authentication for severalnines’:
Description =>’Open access to severalnines’,
type => ‘local’,
database => ‘nines_blog_db’,
user => ‘severalnines’,
address => ‘127.0.0.1/32’
auth_method => ‘md5’
}
}Cette dernière ressource s'appelle "Authentication for manynines" et le fichier pg_hba.conf aura une règle supplémentaire :
# Rule Name: Authentication for severalnines
# Description: Open access for severalnines
# Order: 150
local nines_blog_db severalnines 127.0.0.1/32 md5Pour récupérer la nouvelle configuration depuis l'hôte maître, il suffit de la demander sur le nœud :
$ /opt/puppetlabs/bin/puppet agent -tÉtape 4
Créer un utilisateur en lecture seule. Pour créer un nouvel utilisateur, avec des privilèges en lecture seule, les ressources suivantes doivent être ajoutées au manifeste précédent :
postgresql::server::role{‘Creation of a new role nines_reader’:
createdb => false,
createrole => false,
superuser => false, password_hash=> postgresql_password(‘nines_reader’,’passwd13’)
}
postgresql::server::pg_hba_rule{‘Authentication for nines_reader’:
description =>’Open access to nines_reader’,
type => ‘host’,
database => ‘nines_blog_db’,
user => ‘nines_reader’,
address => ‘192.168.1.10/32’,
auth_method => ‘md5’
}Pour récupérer la nouvelle configuration depuis l'hôte maître, il suffit de la demander sur le nœud :
$ /opt/puppetlabs/bin/puppet agent -tConclusion
Dans cet article de blog, nous vous avons montré les étapes de base pour déployer et commencer à configurer votre base de données PostgreSQL de manière automatique et personnalisée sur plusieurs nœuds (qui pourraient même être des machines virtuelles).
Ces types d'automatisation peuvent vous aider à devenir plus efficace que de le faire manuellement et la configuration de PostgreSQL peut facilement être effectuée en utilisant plusieurs des classes disponibles dans le référentiel puppetforge