Introduction
Déterminer le type d'infrastructure de base de données dont vous avez besoin pour répondre aux exigences de performances, de fiabilité et d'évolutivité de vos applications peut s'avérer une tâche difficile. Les choix que vous faites pour la topologie de votre base de données peuvent avoir un impact sur la façon dont l'ensemble de votre pile d'applications répond aux différents types d'utilisation et sur les scénarios d'échec qu'elle peut prendre en compte. Pour cette raison, il est important de comprendre vos options et de prendre une décision éclairée qui correspond à vos objectifs.
Il existe de nombreuses façons de passer d'une base de données unique gérant tous vos besoins d'infrastructure à des systèmes plus complexes. Parallèlement à cela, de nombreux compromis doivent être pris en compte.
Dans ce guide, nous présenterons certains des modèles les plus courants pour l'infrastructure de base de données relationnelle et comment ils s'alignent sur différents modèles d'utilisation. Nous passerons en revue les avantages offerts par chaque configuration ainsi que certaines des lacunes dont vous devez tenir compte. Nous parlerons également de l'impact de différentes décisions sur la complexité globale de vos opérations. Une fois que vous avez terminé, vous devriez être en mesure de prendre une meilleure décision sur les conceptions les mieux adaptées à vos besoins actuels et sur les options que vous souhaiterez peut-être expérimenter au fur et à mesure que vos besoins changeront.
Mise à l'échelle verticale
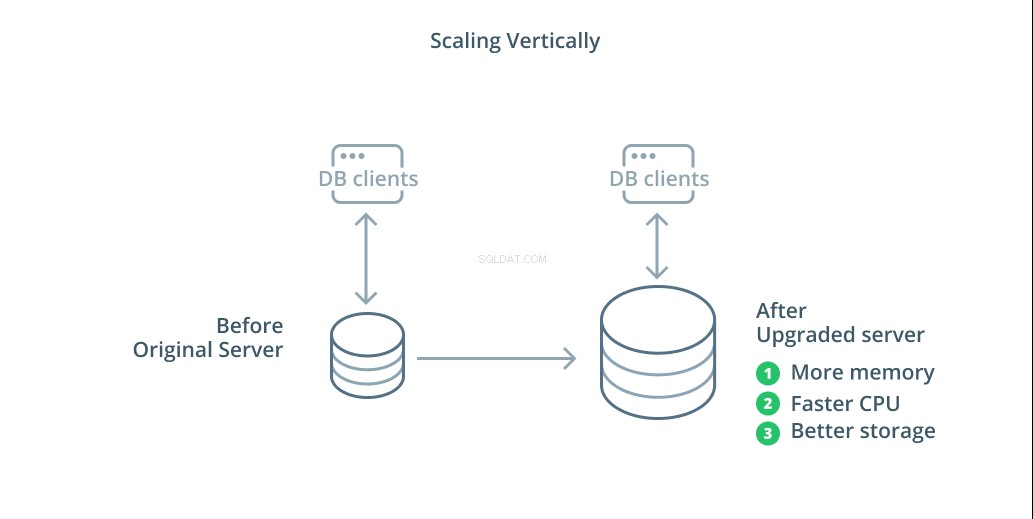
La façon la plus simple de mettre à l'échelle un système de base de données est la mise à l'échelle verticale. Mise à l'échelle verticale , également appelé mise à l'échelle , signifie ajouter de la capacité au serveur qui gère votre base de données. En augmentant la puissance de traitement, l'allocation de mémoire ou la capacité de stockage, vous pouvez augmenter les performances et le volume qu'un système de base de données peut gérer sans augmenter la complexité du système dans son ensemble.
En règle générale, la mise à l'échelle de votre base de données est une bonne première étape car elle augmente les capacités de votre base de données sans affecter la topologie de votre infrastructure. La mise à l'échelle est également généralement assez simple, car une machine de plus grande capacité peut être configurée en tant que suiveur de réplication jusqu'à ce qu'elle soit synchronisée, puis un basculement peut être déclenché pour en faire le nouveau serveur principal.
La mise à l'échelle a cependant ses limites car la quantité de ressources pouvant être raisonnablement allouée à une machine est restreinte. Il représente également un point de défaillance unique si aucun suiveur de réplication n'est configuré pour prendre le relais en cas de problème. Ces problèmes sont résolus par certaines des autres options de mise à l'échelle.
Ségrégation des responsabilités de requête de commande (CQRS) et répliques en lecture seule
L'autre méthode principale de mise à l'échelle de votre infrastructure de base de données consiste à effectuer une mise à l'échelle horizontale. Scaling out signifie qu'au lieu d'augmenter la capacité d'un seul serveur, vous augmentez le nombre de serveurs dédiés à répondre à un besoin spécifique. Ainsi, vous augmentez la capacité en ajoutant des machines supplémentaires à votre infrastructure.
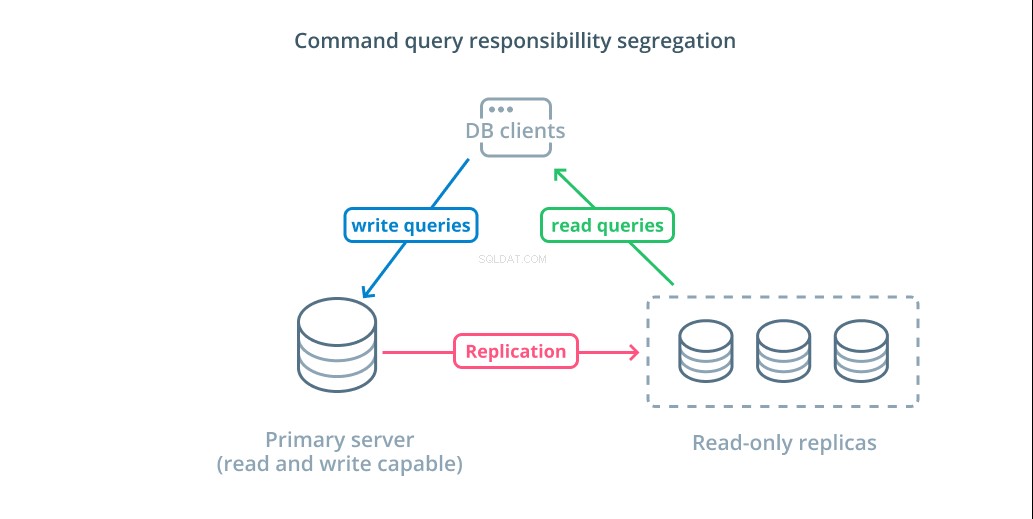
Ségrégation des responsabilités des requêtes de commande (CQRS) est un terme utilisé pour décrire l'ajout d'une logique pour séparer les requêtes qui modifient les données (requêtes d'écriture) de celles qui ne le font pas (requêtes de lecture). Cela vous permet d'acheminer ces différentes catégories de requêtes vers différents hôtes pour aider à répartir la charge.
L'infrastructure la plus basique pour tirer parti de cette conception est un serveur principal qui peut accepter des requêtes de lecture et d'écriture combinées avec un ou plusieurs serveurs répliques suivant le serveur principal qui peut accepter des requêtes de lecture. Cette conception est appropriée pour les modèles d'utilisation d'applications qui nécessitent beaucoup de lecture, car les opérations de lecture peuvent être gérées par n'importe quel serveur de base de données.
De plus, ce système fournit une certaine redondance à votre architecture car le système fonctionnera toujours si l'un des serveurs tombe en panne. Si un suiveur tombe en panne, les demandes de lecture peuvent être acheminées vers les autres serveurs. Si le serveur principal tombe en panne, l'un des suiveurs de réplique peut être promu pour accepter les requêtes en écriture.
Réplication multi-primaire
Bien que l'utilisation de CQRS avec des répliques en lecture seule vous aide à traiter un plus grand nombre de demandes de lecture, cela n'a pas d'impact significatif sur les performances d'écriture de votre infrastructure. Pour augmenter le nombre d'écritures que votre architecture peut gérer, vous devez déterminer si vous pouvez adopter une conception de réplication multi-primaire.
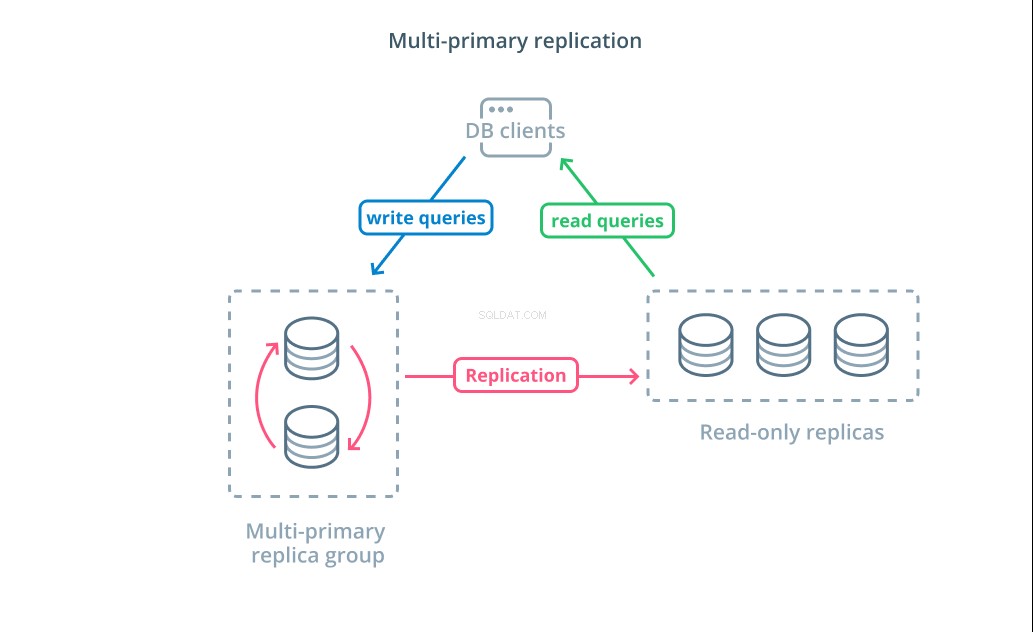
Réplication multi-primaire est une forme de réplication où plusieurs serveurs peuvent accepter des demandes d'écriture. Certains systèmes sont configurés pour que n'importe quel serveur puisse traiter les demandes d'écriture, tandis que d'autres sont conçus pour qu'un groupe central de serveurs principaux gère les écritures avec un plus grand nombre d'abonnés en lecture seule. Quelle que soit l'implémentation, la réplication multi-primaire augmente le nombre de serveurs responsables des requêtes d'écriture.
Bien que cette conception semble idéale au départ, il existe des défis majeurs qui l'empêchent d'être un modèle largement adopté. Bien que plusieurs serveurs puissent gérer les demandes d'écriture, ils doivent toujours se coordonner pour répliquer les modifications entre leurs serveurs et résoudre les conflits dans les modifications de données. Cela peut entraîner de longs temps de réponse lorsque les conflits sont négociés ou la possibilité de données incohérentes.
Chaque système choisit sa propre approche pour relever ces défis. Ceci est une démonstration du théorème CAP — une déclaration décrivant l'interaction entre la cohérence, la disponibilité et la tolérance de partition dans les systèmes distribués — en action. Certains systèmes offrent des garanties de cohérence plus faibles pour maintenir la disponibilité, tandis que d'autres bases de données refusent d'accepter les modifications si leurs homologues ne peuvent pas coordonner la transaction au moment de l'écriture. Le choix de l'approche qui correspond le mieux à vos besoins est un facteur important lors du choix entre différentes implémentations.
Lire la mise en cache des requêtes
Bien que l'utilisation de réplicas en lecture seule soit un moyen d'augmenter les bases de données disponibles pouvant répondre aux demandes de lecture, cela n'améliore pas les performances de requête de base des opérations de lecture complexes. L'un des serveurs doit toujours exécuter l'opération de lecture à chaque requête, même si les résultats sont identiques à la recherche précédente.
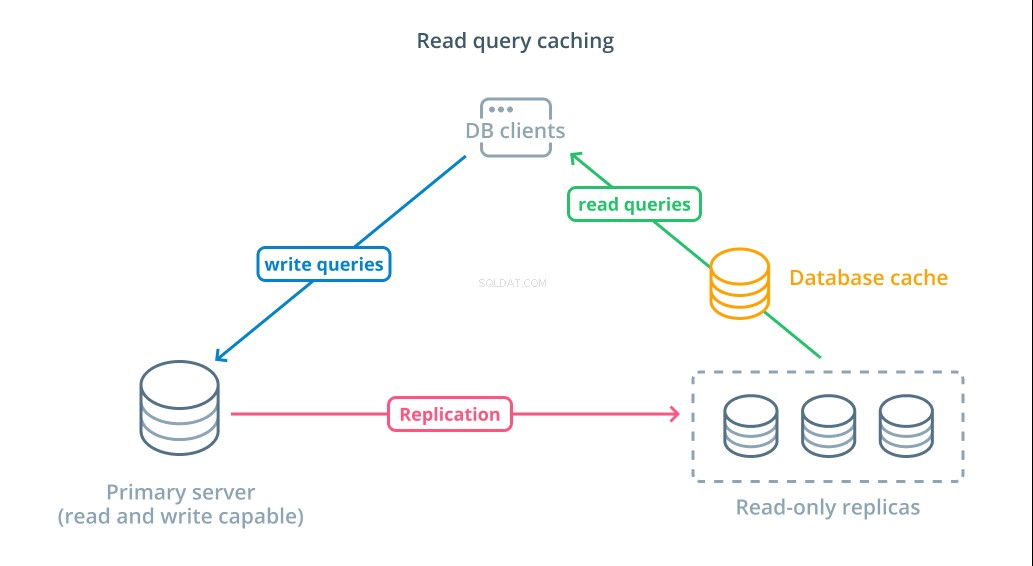
Pour réduire les temps de réponse, une mise en cache des requêtes de lecture couche peut être introduite. L'ajout d'un cache entre vos clients de base de données et les bases de données elles-mêmes peut réduire considérablement le temps d'interrogation des requêtes courantes. L'application peut demander les résultats de lecture du cache et les recevoir presque immédiatement s'ils sont disponibles. Dans les cas où les résultats ne sont pas trouvés dans le cache, ils sont extraits de la base de données elle-même et ajoutés au cache pour la prochaine fois.
Configurer la mise en cache de cette manière est incroyablement efficace pour les scénarios où les données ne sont pas susceptibles de changer à chaque fois que la demande est faite. Il est particulièrement utile pour les requêtes de lecture coûteuses qui consultent plusieurs tables et incluent des opérations de jointure complexes. Ces résultats peuvent être exécutés une seule fois, puis enregistrés pour de futures requêtes.
Dans les cas où les données changent plus rapidement, un cache de lecture peut ne pas être aussi utile. Selon le comportement configuré, les caches risquent de renvoyer des données obsolètes dans ces situations et des stratégies réfléchies d'invalidation du cache doivent être mises en œuvre pour expulser les données obsolètes du cache lorsqu'elles sont modifiées.
Partage des données
Jusqu'à présent, les conceptions dont nous avons parlé comportaient des composants de base de données segmentés selon qu'ils répondaient ou non aux demandes d'écriture. Cependant, une autre façon de diviser la responsabilité consiste à diviser l'ensemble de données réel en plusieurs parties.
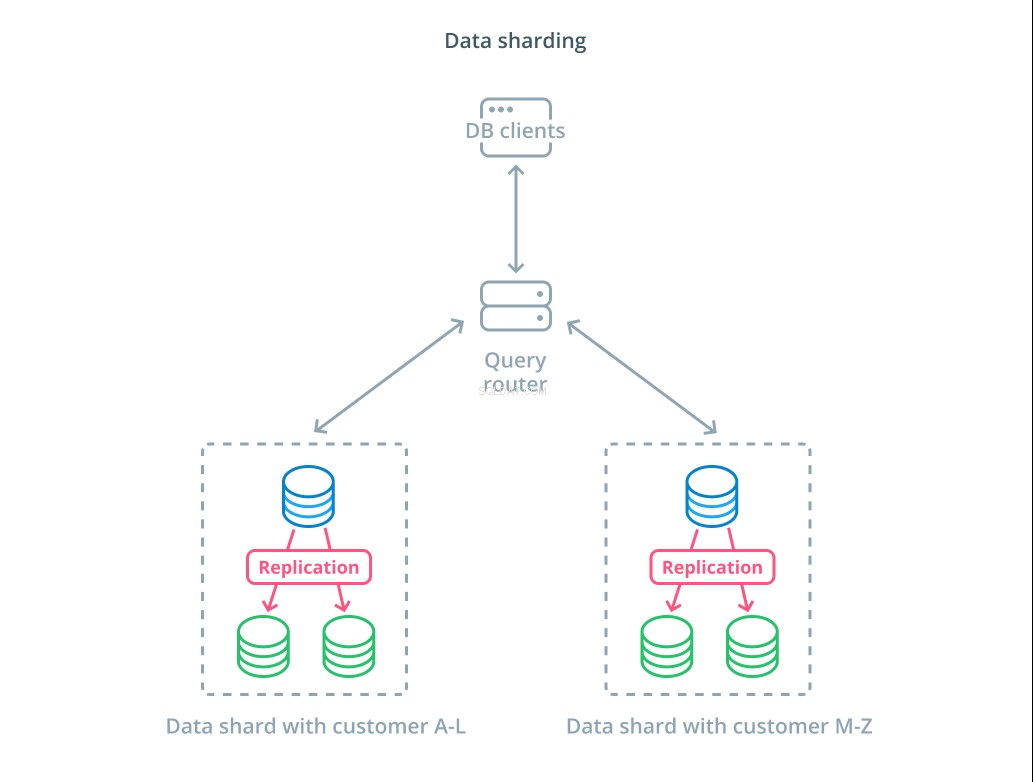
Partage est le processus de décomposition d'un ensemble de données logiques en sous-ensembles plus petits pour répartir leur gestion sur différentes machines. Chaque serveur de base de données ne gère qu'une partie des données et un mécanisme de routage est introduit qui comprend quelles machines sont responsables de quelles données.
En règle générale, le partitionnement est effectué dans des scénarios où il est inutile ou peu courant d'opérer sur l'ensemble du jeu de données en une seule fois. L'ensemble de données est segmenté en fonction de la valeur de chaque enregistrement pour une clé spécifique, appelée clé de partitionnement . Par exemple, vous pouvez partitionner manuellement les données en fonction de l'emplacement des clients. Vous pouvez également partitionner automatiquement à l'aide d'un algorithme de hachage pour déterminer quels nœuds doivent gérer quelles clés. Cela peut aider votre système à éviter une distribution déséquilibrée dans les cas où l'espace de clés de partition est distribué de manière inégale.
Le sharding introduit un peu de complexité dans les systèmes de données et ne convient pas à tous les scénarios. Les opérations qui interagissent avec plusieurs partitions subiront des pénalités de performances importantes lorsqu'elles récupèrent les résultats de chaque membre. Cela peut se produire pour les requêtes agrégées ou si la clé de partition spécifique n'est pas connue à l'avance. De plus, une allocation inégale des fragments peut également entraîner des inefficacités et des goulots d'étranglement qui doivent être corrigés en rééquilibrant la distribution de l'ensemble de données.
Gestion décentralisée des données fonctionnelles
Plutôt que de diviser les valeurs d'un ensemble de données en plusieurs segments, dans de nombreux cas, il est plus logique d'utiliser différentes bases de données à des fins fonctionnelles différentes. Par exemple, si vous disposez d'un service de comptabilité et d'un service de produits, le fait d'avoir des bases de données dédiées qui coïncident avec chaque préoccupation peut vous aider à faire évoluer les différents composants indépendamment.
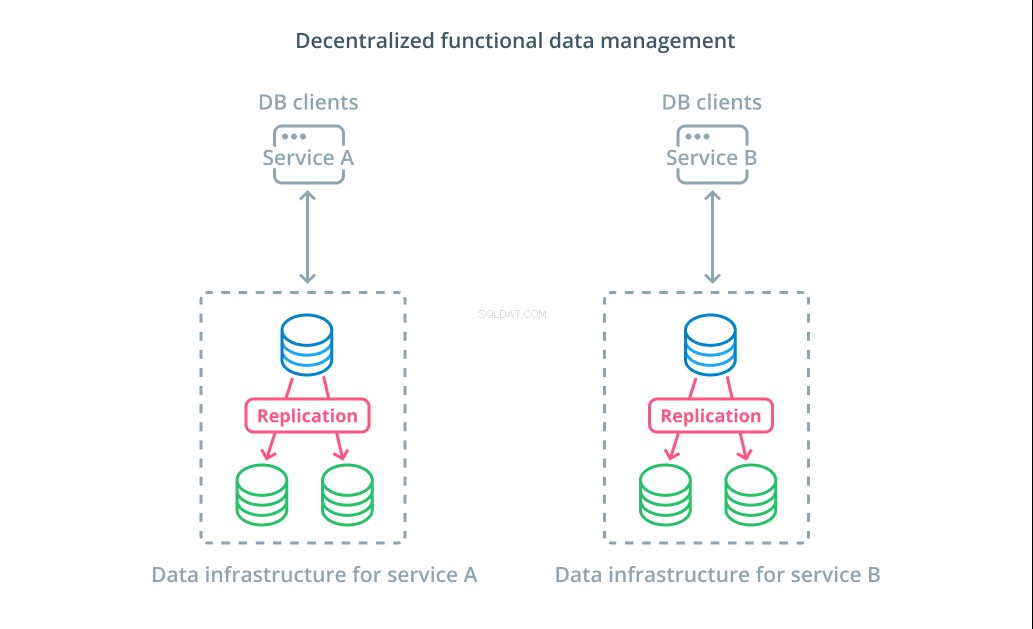
La gestion fonctionnelle des données vous permet de décomposer votre infrastructure de base de données et de gérer chaque partie en fonction des besoins de ses clients. Chaque partie fonctionnelle peut être mise à l'échelle en utilisant la stratégie la plus logique. Il vous permet de concevoir le schéma de base de données et de le déployer à un emplacement qui correspond le mieux aux modèles d'un cas d'utilisation spécifique au lieu de l'obliger à servir l'ensemble de l'organisation.
Pour de nombreuses organisations, cette stratégie présente des avantages importants qui vont au-delà des propriétés des systèmes réels. La décentralisation de la gestion des données peut permettre aux petites équipes de posséder leurs propres données sans coordonner les modifications avec d'autres parties. Cela correspond bien à la séparation ciblée des préoccupations promue par les architectures d'application orientées microservices.
Bases de données sans serveur
Les différents compromis que vous devez évaluer et la quantité d'infrastructure que vous devrez peut-être gérer pour une mise à l'échelle appropriée peuvent être accablants pour de nombreuses personnes. Une option pour vous décharger de cette complexité consiste à tirer parti des services de base de données qui gèrent l'infrastructure et l'évolutivité pour vous.
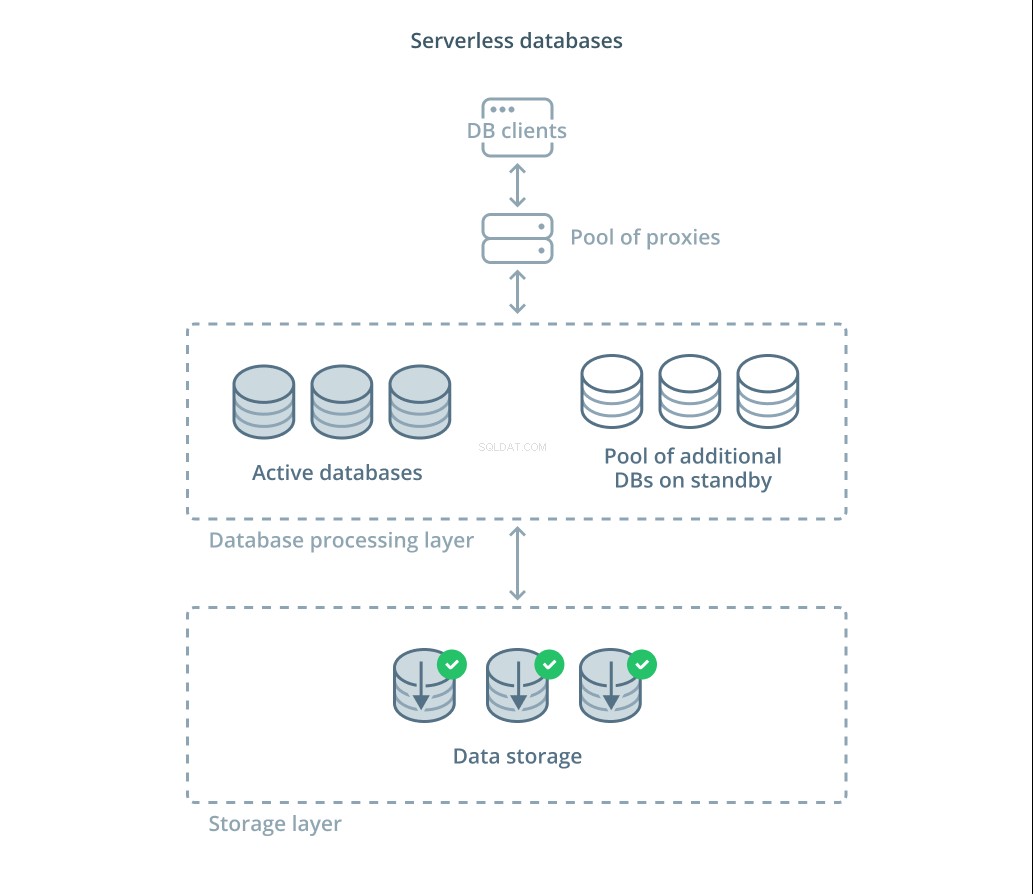
Bases de données sans serveur sont une catégorie de services qui dissocient le stockage des données du traitement des données pour adapter facilement les ressources en réponse aux changements de la demande.
Une couche de stockage de données est chargée de maintenir les données réelles gérées par le système. Devant cette couche, un niveau d'unités de traitement de base de données évolutives est déployé pour gérer le traitement réel des requêtes sur les ensembles de données. Le nombre d'unités actives à un moment donné est directement lié à l'utilisation actuelle, de sorte que davantage de ressources sont allouées en cas de pics de demande et les unités de traitement sont remises en veille si les choses se calment.
Les requêtes sont transmises aux processeurs de base de données via un proxy de routage qui sait comment transmettre les demandes aux nœuds actifs et quand demander des ressources supplémentaires.
Les bases de données sans serveur ont de nombreuses propriétés identiques aux services de base de données traditionnels qui implémentent des fonctionnalités de mise à l'échelle automatique. Les deux peuvent allouer de la capacité en fonction de la demande. Cependant, les bases de données sans serveur vous permettent de séparer les coûts de stockage des coûts de traitement et peuvent réduire le traitement à zéro lorsqu'il n'est pas nécessaire. De plus, les solutions sans serveur ont tendance à évoluer beaucoup plus rapidement pour répondre à la demande par rapport à l'autoscaling proposé par les offres traditionnelles.
Bien que les bases de données sans serveur puissent convenir à certains, elles ne sont pas une solution miracle. Dans les cas où les processeurs de base de données étaient réduit à zéro, il peut y avoir des retards dans le traitement à nouveau en raison de démarrages à froid. De plus, le roulement des connexions entre les différents composants d'une pile de base de données sans serveur peut entraîner une latence supplémentaire.
Les plates-formes de base de données sans serveur peuvent également être difficiles du point de vue des opérations. Les déploiements et les modifications de base de données peuvent être plus difficiles à raisonner et à surveiller. L'environnement de développement local peut également différer considérablement de l'environnement de production en raison de l'état dynamique du système de base de données. Et enfin, comme pour tout autre service cloud, l'utilisation de bases de données sans serveur peut potentiellement vous exposer à un risque de dépendance vis-à-vis d'un fournisseur. Il est important de garder à l'esprit ces compromis lors de la conception autour d'une plate-forme sans serveur.
Conclusion
Il existe de nombreuses façons de concevoir, déployer et gérer votre infrastructure de base de données à mesure que les exigences de vos applications deviennent plus sérieuses. Chaque solution a ses forces et ses limites qu'il est important de comprendre lorsque vous essayez de trouver une solution adaptée à votre environnement.
Connaître l'impact de l'infrastructure de base de données sur la disponibilité, les performances et l'intégrité de vos données vous permet d'éviter des erreurs coûteuses et des implémentations qui n'offrent pas les garanties dont vous avez besoin. Si l'une des conceptions ci-dessus ne couvre pas vos besoins, vous pourrez peut-être combiner certains des éléments de différentes approches pour obtenir des avantages supplémentaires.
Si vous souhaitez en savoir plus sur les modèles généraux abordés ci-dessus, voici quelques ressources supplémentaires que vous pouvez consulter :
- Scaling up versus scale out
- Ségrégation des responsabilités des requêtes de commande
- Réplication multi-primaire
- Mise en cache des requêtes de lecture
- Partage des données
- Gestion décentralisée des données
- Bases de données sans serveur