Que fait l'indexation ?
L'indexation est le moyen d'obtenir une table non ordonnée dans un ordre qui maximisera l'efficacité de la requête lors de la recherche.
Lorsqu'une table n'est pas indexée, l'ordre des lignes ne sera probablement pas perceptible par la requête comme optimisé de quelque manière que ce soit, et votre requête devra donc rechercher dans les lignes de manière linéaire. En d'autres termes, les requêtes devront parcourir chaque ligne pour trouver les lignes correspondant aux conditions. Comme vous pouvez l'imaginer, cela peut prendre beaucoup de temps. Parcourir chaque ligne n'est pas très efficace.
Par exemple, le tableau ci-dessous représente un tableau dans une source de données fictive, qui est complètement désordonné.
| id_entreprise | unité | coût unitaire |
|---|---|---|
| 10 | 12 | 1.15 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 16 | 12 | 1.31 |
| 10 | 12 | 1.15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1.36 |
| 12 | 12 | 1.05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 14 | 24 | 1.05 |
Si nous devions exécuter la requête suivante :
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
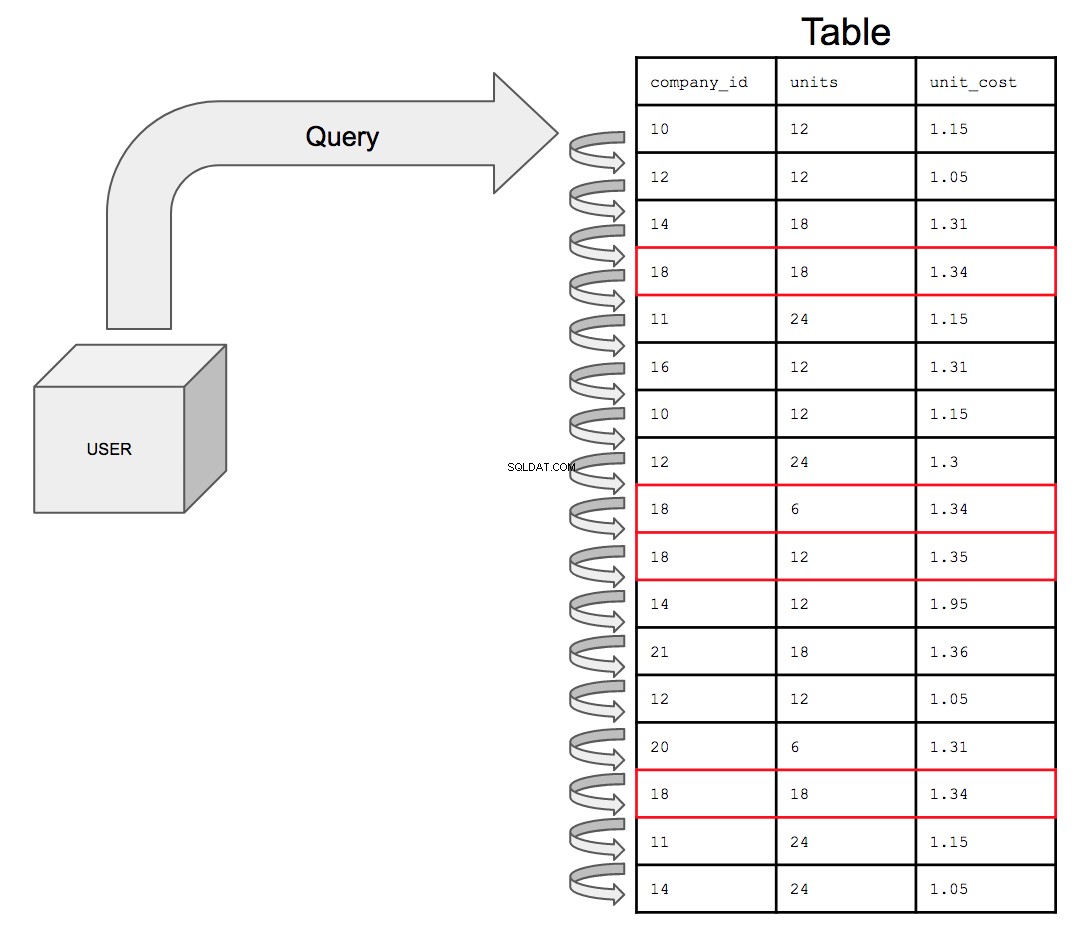
La base de données devrait parcourir les 17 lignes dans l'ordre dans lequel elles apparaissent dans le tableau, de haut en bas, une à la fois. Donc, pour rechercher toutes les instances potentielles de company_id numéro 18, la base de données doit rechercher dans toute la table toutes les apparitions de 18 dans company_id colonne.
Cela ne fera que prendre de plus en plus de temps à mesure que la taille de la table augmente. Au fur et à mesure que la sophistication des données augmente, ce qui pourrait éventuellement arriver, c'est qu'une table avec un milliard de lignes soit jointe à une autre table avec un milliard de lignes; la requête doit maintenant rechercher deux fois plus de lignes, ce qui coûte deux fois plus de temps.
Vous pouvez voir comment cela devient problématique dans notre monde toujours saturé de données. Les tables augmentent en taille et la recherche augmente en temps d'exécution.
L'interrogation d'une table non indexée, si elle était présentée visuellement, ressemblerait à ceci :
Ce que fait l'indexation, c'est configurer la colonne sur laquelle se trouvent les conditions de recherche dans un ordre trié pour aider à optimiser les performances des requêtes.
Avec un index sur le company_id colonne, le tableau "ressemblerait" essentiellement à ceci :
| id_entreprise | unité | coût unitaire |
|---|---|---|
| 10 | 12 | 1.15 |
| 10 | 12 | 1.15 |
| 11 | 24 | 1.15 |
| 11 | 24 | 1.15 |
| 12 | 12 | 1.05 |
| 12 | 24 | 1.3 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1.05 |
| 16 | 12 | 1.31 |
| 18 | 18 | 1.34 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 18 | 18 | 1.34 |
| 20 | 6 | 1.31 |
| 21 | 18 | 1.36 |
Maintenant, la base de données peut rechercher company_id numéro 18 et renvoyez toutes les colonnes demandées pour cette ligne, puis passez à la ligne suivante. Si le comapny_id de la ligne suivante number est également 18, il renverra toutes les colonnes demandées dans la requête. Si company_id de la ligne suivante est 20, la requête sait qu'elle doit arrêter la recherche et la requête se terminera.
Comment fonctionne l'indexation ?
En réalité, la table de la base de données ne se réorganise pas à chaque fois que les conditions de la requête changent afin d'optimiser les performances de la requête :ce serait irréaliste. En réalité, ce qui se passe, c'est que l'index amène la base de données à créer une structure de données. Le type de structure de données est très probablement un B-Tree. Bien que les avantages du B-Tree soient nombreux, le principal avantage pour nos besoins est qu'il est triable. Lorsque la structure des données est triée dans l'ordre, cela rend notre recherche plus efficace pour les raisons évidentes que nous avons soulignées ci-dessus.
Lorsque l'index crée une structure de données sur une colonne spécifique, il est important de noter qu'aucune autre colonne n'est stockée dans la structure de données. Notre structure de données pour le tableau ci-dessus ne contiendra que le company_id Nombres. Unités et unit_cost ne sera pas conservé dans la structure de données.
Comment la base de données sait-elle quels autres champs de la table renvoyer ?
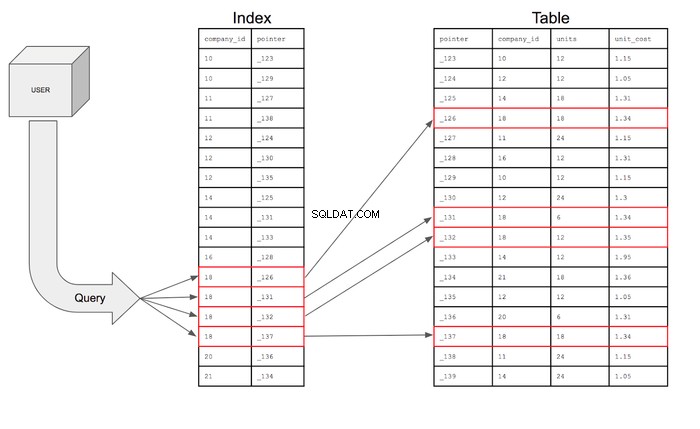
Les index de base de données stockeront également des pointeurs qui sont simplement des informations de référence pour l'emplacement des informations supplémentaires en mémoire. Fondamentalement, l'index contient le company_id et l'adresse d'origine de cette ligne particulière sur le disque mémoire. L'index ressemblera en fait à ceci :
| id_entreprise | pointeur |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
Avec cet index, la requête peut rechercher uniquement les lignes dans company_id colonne qui ont 18, puis en utilisant le pointeur peut aller dans le tableau pour trouver la ligne spécifique où se trouve ce pointeur. La requête peut alors aller dans la table pour récupérer les champs des colonnes demandées pour les lignes remplissant les conditions.
Si la recherche était présentée visuellement, elle ressemblerait à ceci :
Récapitulatif
- L'indexation ajoute une structure de données avec des colonnes pour les conditions de recherche et un pointeur
- Le pointeur est l'adresse sur le disque mémoire de la ligne avec le reste des informations
- La structure des données de l'index est triée pour optimiser l'efficacité des requêtes
- La requête recherche la ligne spécifique dans l'index ; l'index fait référence au pointeur qui trouvera le reste de l'information.
- L'index réduit le nombre de lignes que la requête doit parcourir de 17 à 4.