Une définition simple de la médiane est :
La médiane est la valeur médiane dans une liste triée de nombresPour étoffer un peu cela, nous pouvons trouver la médiane d'une liste de nombres en utilisant la procédure suivante :
- Trier les nombres (par ordre croissant ou décroissant, peu importe lequel).
- Le nombre du milieu (par position) dans la liste triée est la médiane.
- S'il y a deux nombres "également médians", la médiane est la moyenne des deux valeurs médianes.
Aaron Bertrand a déjà testé plusieurs façons de calculer la médiane dans SQL Server :
- Quel est le moyen le plus rapide de calculer la médiane ?
- Meilleures approches pour la médiane groupée
Rob Farley a récemment ajouté une autre approche destinée aux installations antérieures à 2012 :
- Médianes avant SQL 2012
Cet article présente une nouvelle méthode utilisant un curseur dynamique.
La méthode OFFSET-FETCH 2012
Nous commencerons par examiner l'implémentation la plus performante, créée par Peter Larsson. Il utilise le SQL Server 2012 OFFSET extension au ORDER BY clause pour localiser efficacement la ou les deux lignes du milieu nécessaires pour calculer la médiane.
DÉCALER la médiane unique
Le premier article d'Aaron a testé le calcul d'une seule médiane sur une table de dix millions de lignes :
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
La solution de Peter Larsson utilisant le OFFSET l'extension est :
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Le code ci-dessus code en dur le résultat du comptage des lignes de la table. Toutes les méthodes testées pour calculer la médiane ont besoin de ce décompte pour calculer les numéros de ligne médians, il s'agit donc d'un coût constant. Laisser l'opération de comptage de lignes en dehors de la synchronisation évite une source possible de variation.
Le plan d'exécution du OFFSET la solution est illustrée ci-dessous :

L'opérateur Top ignore rapidement les lignes inutiles, ne passant qu'une ou deux lignes nécessaires pour calculer la médiane sur le Stream Aggregate. Lorsqu'elle est exécutée avec un cache à chaud et une collection de plans d'exécution désactivés, cette requête s'exécute pendant 910 ms en moyenne sur mon portable. Il s'agit d'une machine avec un processeur Intel i7 740QM fonctionnant à 1,73 GHz avec Turbo désactivé (pour la cohérence).
Médiane groupée OFFSET
Le deuxième article d'Aaron a testé la performance du calcul d'une médiane par groupe, en utilisant une table Sales d'un million de lignes avec dix mille entrées pour chacun des cent vendeurs :
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Encore une fois, la solution la plus performante utilise OFFSET :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); La partie importante du plan d'exécution est illustrée ci-dessous :

La ligne supérieure du plan concerne la recherche du nombre de lignes du groupe pour chaque vendeur. La ligne inférieure utilise les mêmes éléments de plan vus pour la solution médiane à groupe unique pour calculer la médiane pour chaque vendeur. Lorsqu'elle est exécutée avec un cache à chaud et les plans d'exécution désactivés, cette requête s'exécute en 320 ms en moyenne sur mon portable.
Utiliser un curseur dynamique
Il peut sembler fou de penser à utiliser un curseur pour calculer la médiane. Les curseurs Transact SQL ont la réputation (généralement bien méritée) d'être lents et inefficaces. On pense aussi souvent que les curseurs dynamiques sont le pire type de curseur. Ces points sont valables dans certaines circonstances, mais pas toujours.
Les curseurs Transact SQL sont limités au traitement d'une seule ligne à la fois, ils peuvent donc être lents si de nombreuses lignes doivent être extraites et traitées. Ce n'est cependant pas le cas pour le calcul de la médiane :tout ce que nous avons à faire est de localiser et d'extraire la ou les deux valeurs médianes efficacement . Un curseur dynamique convient très bien à cette tâche comme nous le verrons.
Curseur dynamique médian unique
La solution du curseur dynamique pour un seul calcul de médiane comprend les étapes suivantes :
- Créez un curseur défilant dynamique sur la liste ordonnée des éléments.
- Calculez la position de la première ligne médiane.
- Repositionnez le curseur en utilisant
FETCH RELATIVE. - Décidez si une deuxième ligne est nécessaire pour calculer la médiane.
- Si ce n'est pas le cas, renvoyez immédiatement la valeur médiane unique.
- Sinon, récupérez la deuxième valeur en utilisant
FETCH NEXT. - Calculez la moyenne des deux valeurs et retournez.
Remarquez à quel point cette liste reflète la procédure simple pour trouver la médiane donnée au début de cet article. Une implémentation complète du code Transact SQL est illustrée ci-dessous :
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
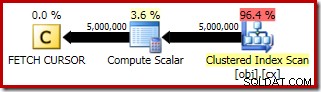
Le plan d'exécution pour le FETCH RELATIVE indique que le curseur dynamique se repositionne efficacement sur la première ligne requise pour le calcul de la médiane :
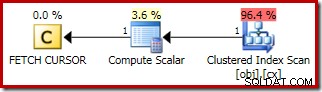
Le plan pour le FETCH NEXT (nécessaire uniquement s'il y a une deuxième ligne du milieu, comme dans ces tests) est une extraction d'une seule ligne à partir de la position enregistrée du curseur :
Les avantages d'utiliser un curseur dynamique ici sont :
- Il évite de parcourir tout l'ensemble (la lecture s'arrête après avoir trouvé les lignes médianes) ; et
- Aucune copie temporaire des données n'est effectuée dans tempdb , comme ce serait le cas pour un curseur statique ou keyset.
Notez que nous ne pouvons pas spécifier de FAST_FORWARD curseur ici (laissant le choix d'un plan de type statique ou dynamique à l'optimiseur) car le curseur doit pouvoir défiler pour prendre en charge FETCH RELATIVE . Dynamique est le choix optimal ici de toute façon.
Lorsqu'elle est exécutée avec un cache à chaud et une collection de plans d'exécution désactivés, cette requête s'exécute pendant 930 ms en moyenne sur ma machine de test. C'est un peu plus lent que les 910 ms pour le OFFSET solution, mais le curseur dynamique est nettement plus rapide que les autres méthodes testées par Aaron et Rob, et il ne nécessite pas SQL Server 2012 (ou version ultérieure).
Je ne vais pas répéter ici les tests des autres méthodes antérieures à 2012, mais à titre d'exemple de l'ampleur de l'écart de performances, la solution de numérotation des lignes suivante prend 1 550 ms en moyenne (70 % plus lent) :
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

Test du curseur dynamique médian groupé
Il est simple d'étendre la solution de curseur dynamique à médiane unique pour calculer des médianes groupées. Par souci de cohérence, je vais utiliser des curseurs imbriqués (oui, vraiment) :
- Ouvrez un curseur statique sur les vendeurs et le nombre de lignes.
- Calculez la médiane pour chaque personne en utilisant un nouveau curseur dynamique à chaque fois.
- Enregistrez chaque résultat dans une variable de table au fur et à mesure.
Le code est affiché ci-dessous :
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Le curseur externe est délibérément statique car toutes les lignes de cet ensemble seront touchées (de plus, un curseur dynamique n'est pas disponible en raison de l'opération de regroupement dans la requête sous-jacente). Il n'y a rien de particulièrement nouveau ou intéressant à voir dans les plans d'exécution cette fois-ci.
Ce qui est intéressant, c'est la performance. Malgré la création et la désallocation répétées du curseur dynamique interne, cette solution fonctionne très bien sur l'ensemble de données de test. Avec un cache à chaud et des plans d'exécution désactivés, le script du curseur se termine en 330 ms en moyenne sur ma machine de test. C'est encore un tout petit peu plus lent que les 320 ms enregistré par le OFFSET médiane regroupée, mais elle bat de loin les autres solutions standard répertoriées dans les articles d'Aaron et de Rob.
Encore une fois, à titre d'exemple de l'écart de performances par rapport aux autres méthodes non 2012, la solution de numérotation des lignes suivante s'exécute pendant 485 ms en moyenne sur mon banc d'essai (50 % moins bon) :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

Résumé des résultats
Dans le test médian unique, le curseur dynamique a duré 930 ms contre 910 ms pour le OFFSET méthode.
Dans le test médian groupé, le curseur imbriqué a fonctionné pendant 330 ms contre 320 ms pour OFFSET .
Dans les deux cas, la méthode du curseur était nettement plus rapide que l'autre non-OFFSET méthodes. Si vous avez besoin de calculer une médiane unique ou groupée sur une instance antérieure à 2012, un curseur dynamique ou un curseur imbriqué pourrait vraiment être le choix optimal.
Performances du cache froid
Certains d'entre vous s'interrogent peut-être sur les performances du cache à froid. Exécution de ce qui suit avant chaque test :
CHECKPOINT; DBCC DROPCLEANBUFFERS;
Voici les résultats du test médian unique :
OFFSET méthode :940 ms
Curseur dynamique :955 ms
Pour la médiane groupée :
OFFSET méthode :380 ms
Curseurs imbriqués :385 ms
Réflexions finales
Les solutions de curseur dynamique sont vraiment beaucoup plus rapides que les non-OFFSET méthodes pour les médianes simples et groupées, au moins avec ces ensembles de données d'échantillon. J'ai délibérément choisi de réutiliser les données de test d'Aaron afin que les ensembles de données ne soient pas intentionnellement orientés vers le curseur dynamique. Il pourrait être d'autres distributions de données pour lesquelles le curseur dynamique n'est pas une bonne option. Néanmoins, cela montre qu'il y a encore des moments où un curseur peut être une solution rapide et efficace au bon type de problème. Même les curseurs dynamiques et imbriqués.
Les lecteurs aux yeux d'aigle ont peut-être remarqué le PAGLOCK indice dans le OFFSET test médian groupé. Ceci est nécessaire pour de meilleures performances, pour des raisons que j'aborderai dans mon prochain article. Sans cela, la solution 2012 perd en fait face au curseur imbriqué avec une marge décente (590 ms contre 330 ms ).