L'année dernière, j'ai publié une astuce intitulée Améliorer l'efficacité de SQL Server en passant à INSTEAD OF Triggers.
La principale raison pour laquelle j'ai tendance à privilégier un déclencheur INSTEAD OF, en particulier dans les cas où je m'attends à de nombreuses violations de la logique métier, est qu'il semble intuitif qu'il serait moins coûteux d'empêcher complètement une action que d'aller de l'avant et de l'exécuter (et log it !), uniquement pour utiliser un déclencheur AFTER pour supprimer les lignes incriminées (ou annuler l'intégralité de l'opération). Les résultats présentés dans cette astuce ont démontré que c'était effectivement le cas - et je soupçonne qu'ils seraient encore plus prononcés avec davantage d'index non clusterisés affectés par l'opération.
Cependant, c'était sur un disque lent et sur un premier CTP de SQL Server 2014. En préparant une diapositive pour une nouvelle présentation que je ferai cette année sur les déclencheurs, j'ai trouvé que sur une version plus récente de SQL Server 2014 - combiné avec du matériel mis à jour - il était un peu plus délicat de démontrer le même delta de performances entre un déclencheur AFTER et INSTEAD OF. J'ai donc entrepris de découvrir pourquoi, même si j'ai tout de suite su que cela allait demander plus de travail que je n'en avais jamais fait pour une seule diapositive.
Une chose que je veux mentionner est que les déclencheurs peuvent utiliser tempdb de différentes manières, ce qui pourrait expliquer certaines de ces différences. Un déclencheur AFTER utilise le magasin de versions pour les pseudo-tables insérées et supprimées, tandis qu'un déclencheur INSTEAD OF fait une copie de ces données dans une table de travail interne. La différence est subtile, mais mérite d'être soulignée.
Les variables
Je vais tester différents scénarios, notamment :
- Trois déclencheurs différents :
- Un déclencheur AFTER qui supprime des lignes spécifiques qui échouent
- Un déclencheur AFTER qui annule toute la transaction si une ligne échoue
- Un déclencheur INSTEAD OF qui n'insère que les lignes qui passent
- Différents modèles de récupération et paramètres d'isolement d'instantané :
- FULL avec SNAPSHOT activé
- FULL avec SNAPSHOT désactivé
- SIMPLE avec SNAPSHOT activé
- SIMPLE avec SNAPSHOT désactivé
- Dispositions de disque différentes* :
- Données sur SSD, connexion sur disque dur 7 200 tr/min
- Données sur SSD, connexion sur SSD
- Données sur disque dur 7 200 tr/min, connexion sur SSD
- Données sur disque dur 7 200 tr/min, connexion sur disque dur 7 200 tr/min
- Différents taux d'échec :
- Taux d'échec de 10 %, 25 % et 50 % sur :
- Insérer un seul lot de 20 000 lignes
- 10 lots de 2 000 lignes
- 100 lots de 200 lignes
- 1 000 lots de 20 lignes
- 20 000 insertions singleton
*
tempdbest un fichier de données unique sur un disque lent à 7200 RPM. Ceci est intentionnel et destiné à amplifier les goulots d'étranglement causés par les diverses utilisations detempdb. Je prévois de revoir ce test à un moment donné lorsquetempdbest sur un SSD plus rapide. - Taux d'échec de 10 %, 25 % et 50 % sur :
D'accord, TL;DR déjà !
Si vous voulez juste connaître les résultats, sautez vers le bas. Tout ce qui se trouve au milieu n'est qu'un arrière-plan et une explication de la façon dont j'ai configuré et exécuté les tests. Je n'ai pas le cœur brisé que tout le monde ne soit pas intéressé par toutes les minuties.
Le scénario
Pour cet ensemble particulier de tests, le scénario réel est celui où un utilisateur choisit un nom d'écran, et le déclencheur est conçu pour détecter les cas où le nom choisi enfreint certaines règles. Par exemple, il ne peut s'agir d'aucune variation de "ninny-muggins" (vous pouvez certainement utiliser votre imagination ici).
J'ai créé une table avec 20 000 noms d'utilisateur uniques :
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
Ensuite, j'ai créé une table qui serait la source de mes "noms coquins" à vérifier. Dans ce cas, c'est juste ninny-muggins-00001 via ninny-muggins-10000 :
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
J'ai créé ces tables dans le model base de données afin que chaque fois que je crée une base de données, elle existe localement, et je prévois de créer de nombreuses bases de données pour tester la matrice de scénario répertoriée ci-dessus (plutôt que de simplement modifier les paramètres de la base de données, effacer le journal, etc.). Veuillez noter que si vous créez des objets dans le modèle à des fins de test, assurez-vous de supprimer ces objets lorsque vous avez terminé.
En passant, je vais intentionnellement laisser de côté les violations de clé et autres erreurs de gestion, en faisant l'hypothèse naïve que l'unicité du nom choisi est vérifiée bien avant que l'insertion ne soit jamais tentée, mais dans la même transaction (tout comme le vérification par rapport à la table des noms coquins aurait pu être faite à l'avance).
Pour soutenir cela, j'ai également créé les trois tables suivantes presque identiques dans model , à des fins d'isolation de test :
USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
Et les trois déclencheurs suivants, un pour chaque table :
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO Vous voudrez probablement envisager une manipulation supplémentaire pour informer l'utilisateur que son choix a été annulé ou ignoré, mais cela aussi est omis pour plus de simplicité.
La configuration du test
J'ai créé des exemples de données représentant les trois taux d'échec que je voulais tester, en changeant 10 % en 25 puis 50, et en ajoutant également ces tables à model :
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ Chaque tableau comporte 20 000 lignes, avec un mélange différent de noms qui réussiront et échoueront, et la colonne de numéro de ligne facilite la division des données en différentes tailles de lots pour différents tests, mais avec des taux d'échec reproductibles pour tous les tests.
Bien sûr, nous avons besoin d'un endroit pour capturer les résultats. J'ai choisi d'utiliser une base de données distincte pour cela, en exécutant chaque test plusieurs fois, en capturant simplement la durée.
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
J'ai rempli le dbo.Tests table avec le script suivant, afin que je puisse exécuter différentes parties pour configurer les quatre bases de données afin qu'elles correspondent aux paramètres de test actuels. Notez que D:\ est un SSD, tandis que G:\ est un disque 7200 RPM :
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) Ensuite, il était simple d'exécuter tous les tests plusieurs fois :
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
Sur mon système, cela a pris près de 6 heures, alors soyez prêt à laisser cela suivre son cours sans interruption. Assurez-vous également que vous n'avez pas de connexions actives ou de fenêtres de requête ouvertes par rapport au model base de données, sinon vous risquez d'obtenir cette erreur lorsque le script tente de créer une base de données :
Impossible d'obtenir un verrou exclusif sur la base de données 'modèle'. Recommencez l'opération plus tard.
Résultats
Il y a de nombreux points de données à examiner (et toutes les requêtes utilisées pour dériver les données sont référencées dans l'annexe). Gardez à l'esprit que chaque durée moyenne indiquée ici est supérieure à 10 tests et insère un total de 100 000 lignes dans la table de destination.
Graphique 1 – Agrégats globaux
Le premier graphique montre les agrégats globaux (durée moyenne) pour les différentes variables isolées (donc *tous* les tests utilisant un déclencheur AFTER qui supprime, *tous* les tests utilisant un déclencheur AFTER qui annule, etc.).
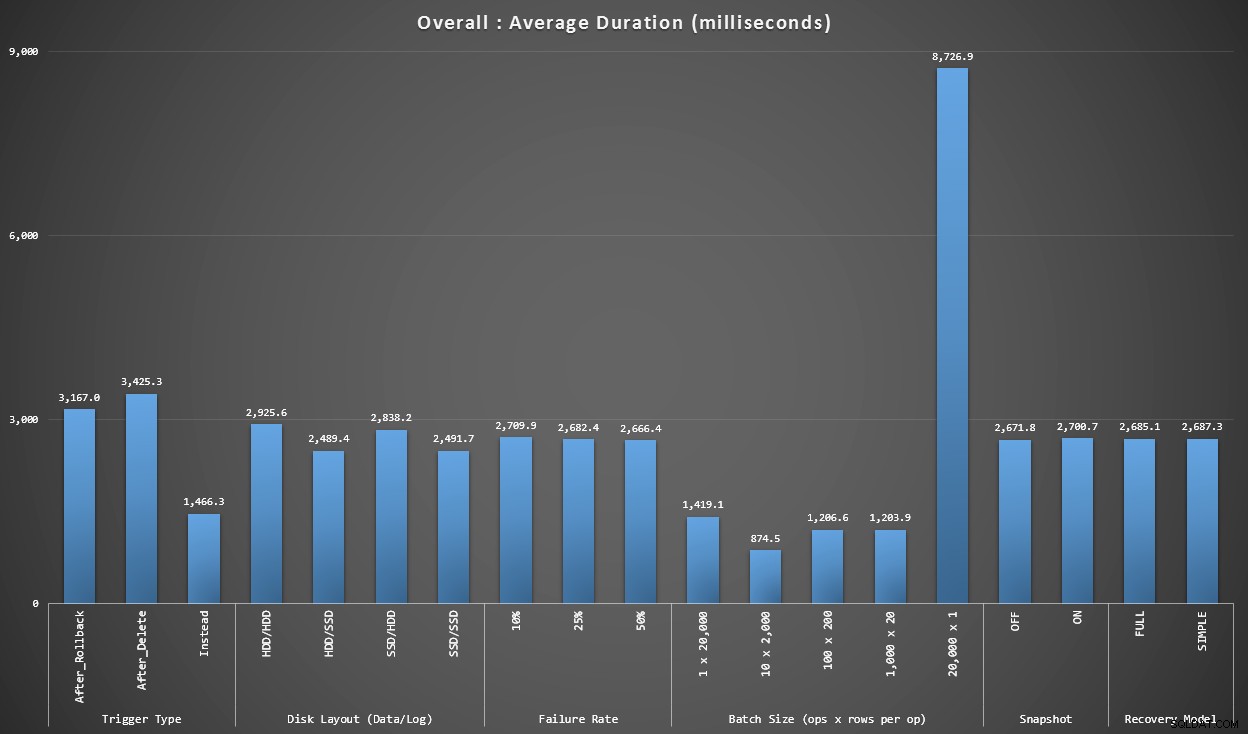
Durée moyenne, en millisecondes, pour chaque variable prise isolément
Quelques éléments nous sautent aux yeux immédiatement :
- Le déclencheur INSTEAD OF ici est deux fois plus rapide que les deux déclencheurs AFTER.
- Avoir le journal des transactions sur SSD a fait une petite différence. L'emplacement du fichier de données l'est beaucoup moins.
- Le lot de 20 000 insertions singleton a été 7 à 8 fois plus lent que n'importe quel autre lot de distribution.
- L'insertion par lot unique de 20 000 lignes était plus lente que toutes les distributions non singleton.
- Le taux d'échec, l'isolation des instantanés et le modèle de récupération ont eu peu ou pas d'impact sur les performances.
Graphique 2 – Les 10 meilleurs au total
Ce graphique montre les 10 résultats les plus rapides lorsque chaque variable est prise en compte. Ce sont tous des déclencheurs INSTEAD OF où le plus grand pourcentage de lignes échoue (50 %). Étonnamment, le plus rapide (mais pas beaucoup) avait à la fois des données et une connexion sur le même disque dur (pas SSD). Il existe ici un mélange de configurations de disque et de modèles de récupération, mais tous les 10 avaient l'isolement d'instantané activé, et les 7 premiers résultats impliquaient tous la taille de lot de 10 x 2 000 lignes.
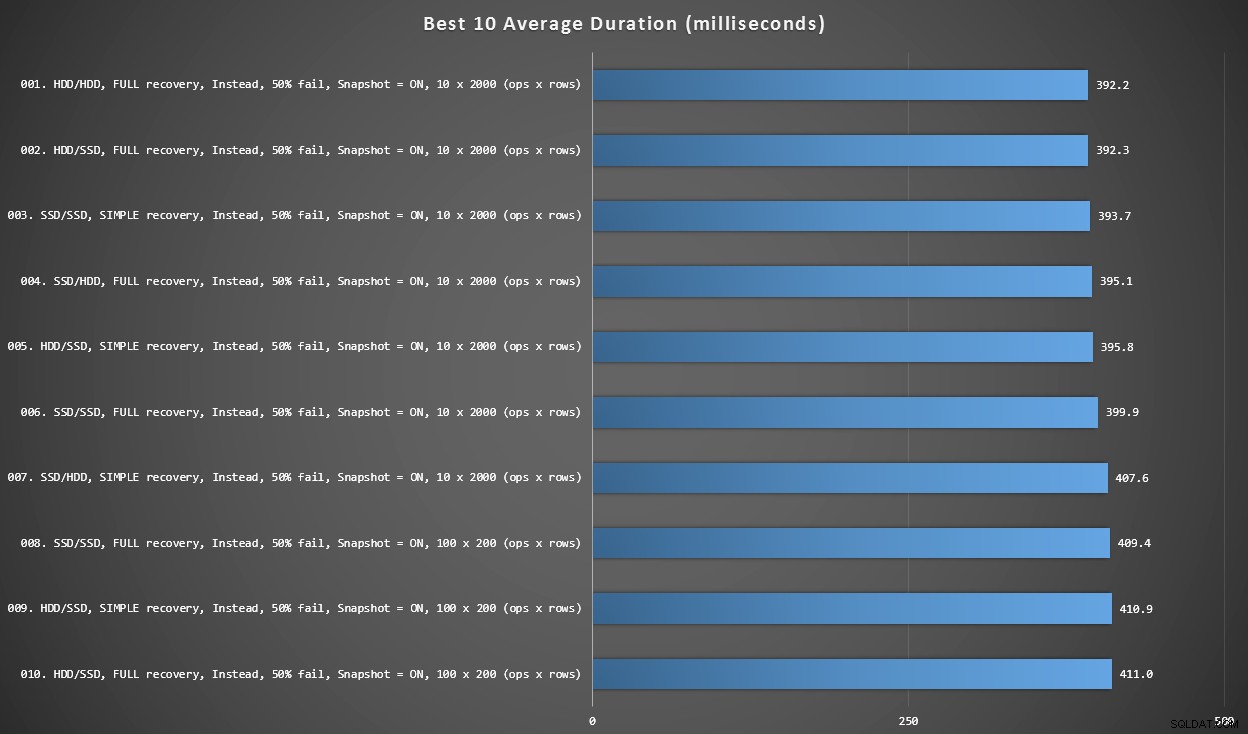
10 meilleures durées, en millisecondes, compte tenu de chaque variable
Le déclencheur AFTER le plus rapide - une variante ROLLBACK avec un taux d'échec de 10 % dans la taille de lot de 100 x 200 lignes - est arrivé à la position 144 (806 ms).
Graphique 3 – Les 10 pires ensemble
Ce graphique montre les 10 résultats les plus lents lorsque chaque variable est prise en compte ; tous sont des variantes AFTER, tous impliquent les 20 000 insertions singleton, et tous ont des données et se connectent sur le même disque dur lent.
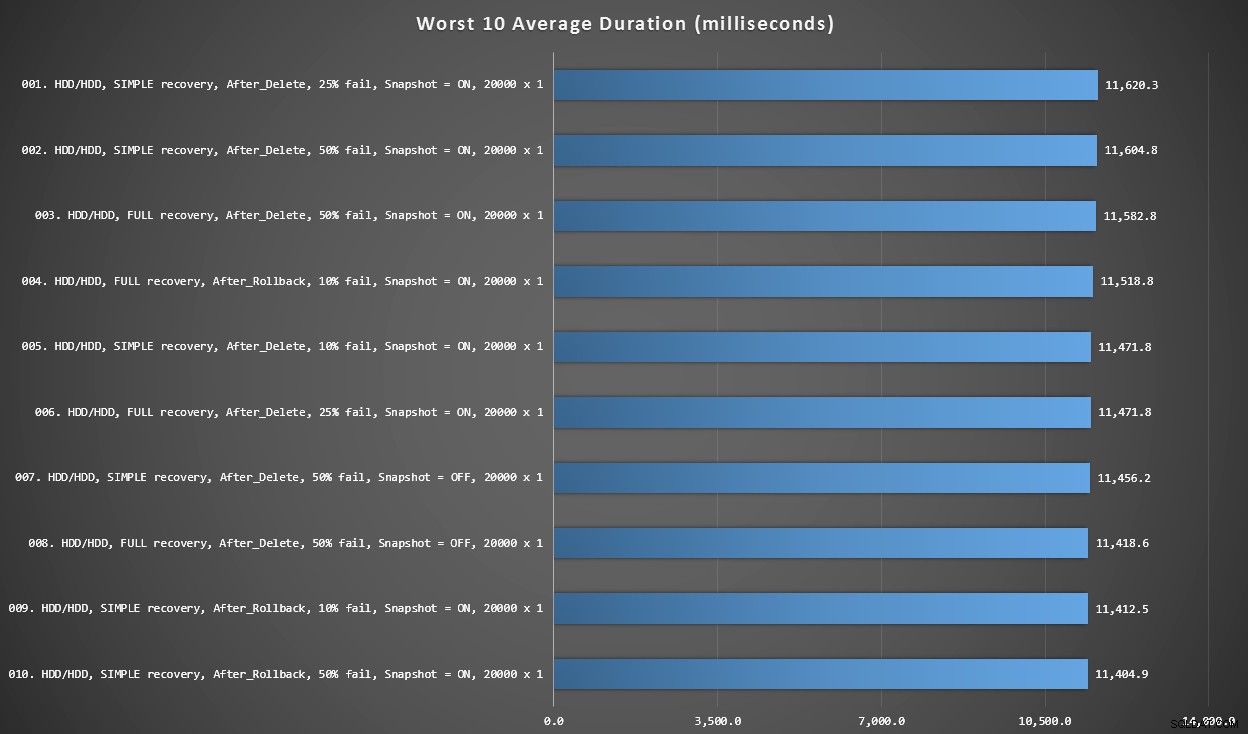
Les 10 pires durées, en millisecondes, en tenant compte de chaque variable
Le test INSTEAD OF le plus lent était en position n ° 97, à 5 680 ms - un test d'insertion de 20 000 singletons où 10% échouent. Il est également intéressant d'observer qu'aucun déclencheur AFTER utilisant la taille de lot d'insertion de 20 000 singletons n'a mieux réussi - en fait, le 96e pire résultat était un test AFTER (suppression) qui est arrivé à 10 219 ms - presque le double du résultat le plus lent suivant. /P>
Graph 4 – Type de disque de journal, insertions de singleton
Les graphiques ci-dessus nous donnent une idée approximative des principaux points faibles, mais ils sont soit trop agrandis, soit pas assez agrandis. Ce graphique filtre jusqu'aux données basées sur la réalité :dans la plupart des cas, ce type d'opération sera une insertion de singleton. Je pensais le décomposer par taux d'échec et par type de disque sur lequel se trouve le journal, mais ne regarder que les lignes où le lot est composé de 20 000 insertions individuelles.
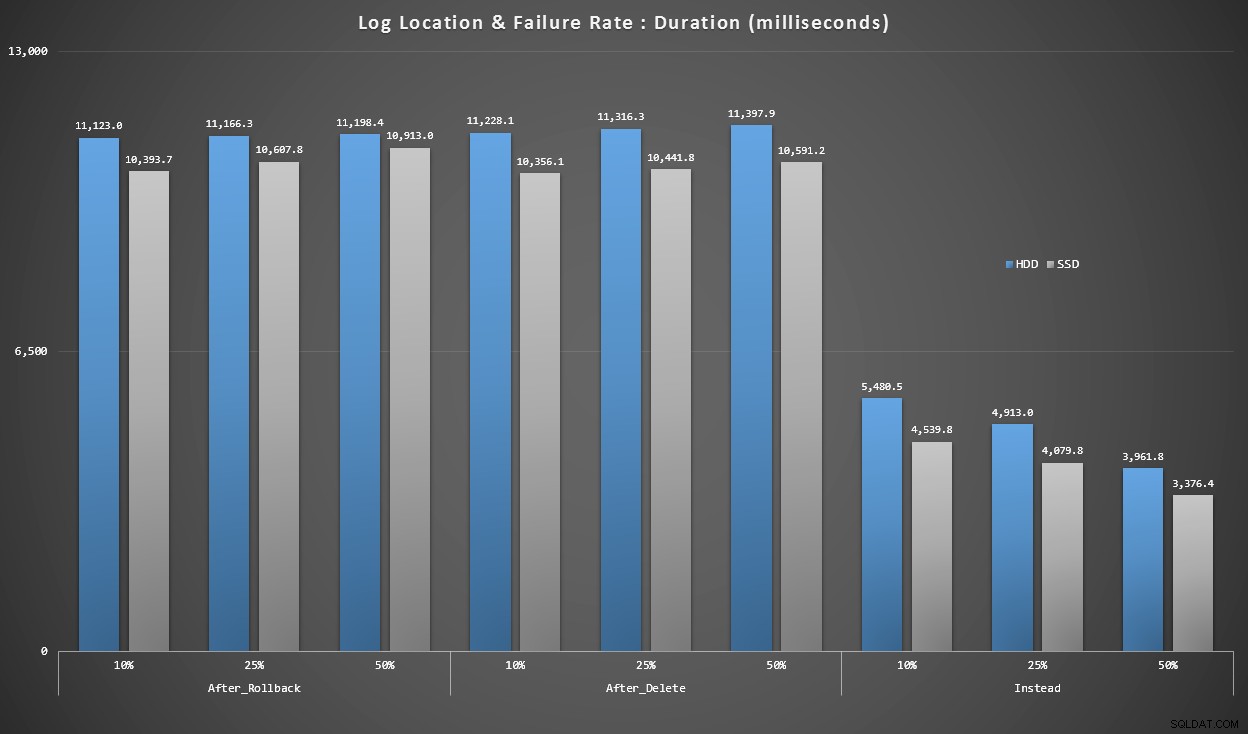
Durée, en millisecondes, regroupée par taux d'échec et emplacement du journal, pour 20 000 encarts individuels
Ici, nous voyons que tous les déclencheurs AFTER se situent en moyenne dans la plage de 10 à 11 secondes (selon l'emplacement du journal), tandis que tous les déclencheurs INSTEAD OF sont bien en dessous de la barre des 6 secondes.
Conclusion
Jusqu'à présent, il me semble clair que le déclencheur INSTEAD OF est gagnant dans la plupart des cas - dans certains cas plus que d'autres (par exemple, à mesure que le taux d'échec augmente). D'autres facteurs, tels que le modèle de récupération, semblent avoir beaucoup moins d'impact sur les performances globales.
Si vous avez d'autres idées sur la façon de décomposer les données, ou si vous souhaitez une copie des données pour effectuer votre propre découpage en tranches et en dés, veuillez me le faire savoir. Si vous avez besoin d'aide pour configurer cet environnement afin que vous puissiez exécuter vos propres tests, je peux également vous aider.
Bien que ce test montre que les déclencheurs INSTEAD OF valent vraiment la peine d'être pris en compte, ce n'est pas tout. J'ai littéralement giflé ces déclencheurs ensemble en utilisant la logique qui me semblait la plus logique pour chaque scénario, mais le code du déclencheur - comme toute instruction T-SQL - peut être réglé pour des plans optimaux. Dans un article de suivi, j'examinerai une optimisation potentielle qui pourrait rendre le déclencheur AFTER plus compétitif.
Annexe
Requêtes utilisées pour la section Résultats :
Graphique 1 – Agrégats globaux
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
Graphiques 2 et 3 – 10 des meilleurs et des pires
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; Graph 4 – Type de disque de journal, insertions de singleton
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;