Avec l'introduction d'Azure SQL Database et l'ajout de plus de fonctionnalités dans la v12, les administrateurs de bases de données commencent à voir leurs organisations plus intéressées par le déplacement des bases de données vers cette plate-forme.
J'ai récemment commencé à plonger davantage dans Azure SQL Database pour voir ce qui est radicalement différent de la prise en charge de la version boîte dans les centres de données à travers le monde et d'Azure SQL Database. Dans mon article précédent, "Optimisation :un bon point de départ", j'ai décrit mon approche pour démarrer avec l'optimisation de SQL Server. J'ai décidé de comparer cela à Azure SQL Database pour découvrir les principales différences.
Dans mon article d'origine, j'ai commencé avec les paramètres courants au niveau de l'instance que je vois ignorés ou laissés par défaut, ainsi que les éléments de maintenance. Ceux-ci incluent la mémoire, maxdop, le seuil de coût pour le parallélisme, l'activation de l'optimisation pour les charges de travail ad hoc et la configuration de tempdb. Avec Azure SQL Database, vous n'êtes pas responsable de l'instance et ne pouvez pas modifier ces paramètres. Azure SQL Database est une plate-forme en tant que service (PaaS), ce qui signifie que Microsoft gère l'instance pour vous; vous êtes simplement un locataire avec votre ou vos bases de données.
Vous êtes cependant responsable de la maintenance, vous devez donc mettre à jour les statistiques et gérer la fragmentation des index comme vous le faites pour le produit en boîte. Pour ces tâches, j'ai constaté que la plupart des clients gèrent ces processus avec une machine virtuelle Azure dédiée exécutant SQL Server et utilisant SQL Server Agent avec des tâches planifiées.
En suivant les étapes de mon article, les prochains domaines que je commence à examiner sont les statistiques de fichiers et d'attente et les requêtes coûteuses. Si vous vous demandez si cet aspect de votre travail en tant que DBA de production avec des bases de données sur site changera lorsque vous travaillerez avec Azure SQL Database, la réponse est pas vraiment . Les statistiques de fichiers et d'attente sont toujours là, mais nous devons y accéder d'une manière légèrement différente. Si vous avez l'habitude d'utiliser les scripts de Paul Randal pour les statistiques de fichiers et les statistiques d'attente (ou les requêtes pour les statistiques de fichiers pendant une période de temps et les statistiques d'attente pendant une période de temps), vous devrez apporter quelques modifications afin que ces scripts pour fonctionner avec Azure SQL Database.
Lorsque j'ai essayé le script de statistiques de fichiers de Paul pour la première fois, il a échoué car Azure SQL Database ne prend pas en charge sys.master_files :
Nom d'objet non valide 'sys.master_files'.
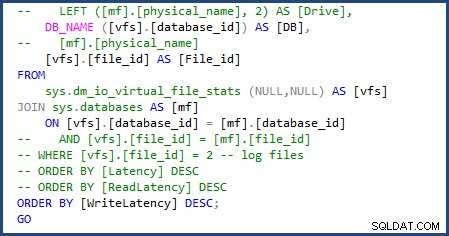
J'ai pu modifier le script pour utiliser sys.databases dans la jointure pour obtenir le nom de la base de données et supprimer la partie du script pour obtenir les noms de fichiers individuels puisque nous n'aurons affaire qu'à un seul fichier de données et journal. Vous pouvez voir les modifications que j'ai dû apporter dans l'image suivante :
Lorsque j'ai exécuté le script file-stats-over-a-period-of-time après, en apportant la même modification à sys.databases et en supprimant les références à file_id dans la jointure, elle a échoué car Azure SQL Database v12 ne prend pas en charge les tables globales ##temp.
Une fois que j'ai changé toutes les tables ##temp globales en locales, j'ai eu un autre problème avec le script incapable de supprimer les tables temporaires existantes qui étaient utilisées, car les tables #temp locales ne peuvent pas être référencées directement par leur nom comme le peuvent les tables ##temp globales, mais cela a été facile à surmonter en changeant ces vérifications en OBJECT_ID('tempdb..#SQLskillsStats1') . J'ai fait la même modification pour la deuxième table temporaire et mis à jour le bloc de code au début et à la fin du script.
J'ai dû faire une autre modification et supprimer [mf].[type_desc] et LEFT ([mf].[physical_name], 2) AS [Drive] puisque ceux-ci dépendent de sys.master_files . Le script était alors terminé et prêt à être utilisé avec Azure SQL Database.
J'utilise régulièrement le fichier-stats-over-a-period-of-time lors du dépannage de problèmes de performances. Les données cumulées ont leur raison d'être, mais je suis plus intéressé par des segments de temps spécifiques pendant lesquels les charges de travail des utilisateurs sont exécutées.
Avec les statistiques de fichiers, nous nous intéressons à notre latence par fichier de base de données et à la façon dont nous pouvons nous adapter pour aider à réduire les E/S globales. L'approche est la même que pour SQL Server, où vous devez régler correctement vos requêtes et disposer des index corrects. Si la charge de travail est tout simplement trop importante, vous devez passer à un niveau de base de données DTU plus performant. Pour moi, c'est génial :il suffit d'y jeter du matériel; mais ce n'est pas vraiment du matériel au sens traditionnel. Avec Azure SQL Database, vous pouvez commencer avec un niveau moins coûteux et évoluer à mesure que votre entreprise et les demandes d'E/S augmentent, essentiellement en basculant simplement un interrupteur.
Essayer de trouver la meilleure méthode pour obtenir des statistiques d'attente était plus facile. Le script standard que beaucoup d'entre nous utilisent fonctionne toujours, mais il extrait les statistiques d'attente pour le conteneur dans lequel votre base de données s'exécute. Ces attentes s'appliquent toujours à votre système, mais peuvent inclure des attentes encourues par d'autres bases de données dans le même conteneur. Azure SQL Database contient une nouvelle DMV, sys.dm_db_wait_stats , qui filtre sur la base de données actuelle. Si vous êtes comme moi et que vous utilisez principalement le script de statistiques d'attente de Paul qui omet toutes les attentes bénignes, modifiez simplement sys.dm_os_wait_stats à sys.dm_db_wait_stats . Le même changement fonctionne également pour le script d'attente sur une période de temps, mais vous devez également passer des variables globales aux variables locales.
Lorsqu'il s'agit de trouver des requêtes à coût élevé, l'un de mes scripts préférés à exécuter trouve les plans d'exécution les plus utilisés. D'après mon expérience, le réglage d'une requête appelée 100 000 fois par jour est généralement plus avantageux que le réglage d'une requête qui a les E/S les plus élevées mais qui n'est exécutée qu'une fois par semaine. La requête suivante est ce que j'utilise pour trouver les forfaits les plus utilisés :
SELECT usecounts , cacheobjtype , objtype , [text]FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle)WHERE usecounts> 1 AND objtype IN ( N'Adhoc', N'Prepared' )ORDER BY usecounts DESC ;Lors de l'utilisation de cette requête dans les démos, je vide toujours le cache de mon plan pour réinitialiser les valeurs. Lorsque j'ai essayé d'exécuter
DBCC FREEPROCCACHEdans Azure SQL Database, j'ai reçu l'erreur suivante :Il s'avère que
SQL Azure ne prend actuellement pas en charge DBCC FREEPROCCACHE (Transact-SQL), vous ne pouvez donc pas supprimer manuellement un plan d'exécution du cache. Cependant, si vous apportez des modifications à la table ou à la vue référencée par la requête (ALTER TABLE et ALTER VIEW), le plan sera supprimé du cache.DBCC FREEPROCCACHEn'est pas pris en charge dans Azure SQL Database. Cela m'a troublé, que se passe-t-il si je suis en production et que j'ai de mauvais plans et que je veux effacer le cache de la procédure comme je le peux avec la version boîte. Une petite recherche sur Google/Bing m'a amené à trouver l'article de Microsoft, "Comprendre le cache de procédure sur SQL Azure", qui stipule :En discutant de cela avec Kimberly Tripp après ne pas avoir vu le comportement décrit, il ne vide pas le plan du cache, mais il invalide le plan (et le plan finira par être vieilli hors du cache). Bien que cela soit utile dans certaines situations, ce n'était pas ce dont j'avais besoin. Pour ma démo, je voulais réinitialiser les compteurs dans sys.dm_exec_cached_plans. Générer un nouveau plan ne me donnerait pas les résultats souhaités. J'ai contacté mon équipe et Glenn Berry m'a dit d'essayer le script suivant :
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE ;Cette commande a fonctionné ; J'ai pu effacer le cache de procédure pour la base de données spécifique. Les configurations étendues de la base de données sont une nouvelle fonctionnalité ajoutée dans SQL Server 2016 RC0; Glenn en a parlé ici :Utilisation de ALTER DATABASE SCOPED CONFIGURATION dans SQL Server 2016.
Je suis ravi de déplacer plusieurs de mes propres bases de données vers Azure SQL Database et de continuer à en apprendre davantage sur les nouvelles fonctionnalités et les options d'évolutivité. Je suis également impatient de travailler avec SentryOne DB Sentry, un ajout récent à la plate-forme SentryOne. Je suis très intéressé par l'expérimentation du tableau de bord d'utilisation DTU, que Mike Wood a décrit dans son récent article.