L'année dernière, j'ai présenté une solution pour simuler les secondaires lisibles du groupe de disponibilité sans investir dans Enterprise Edition. Pas pour empêcher les gens d'acheter Enterprise Edition, car il y a beaucoup d'avantages en dehors des AG, mais plus encore pour ceux qui n'ont aucune chance d'avoir Enterprise Edition en premier lieu :
- Secondaires lisibles sur un budget
J'essaie d'être un défenseur acharné du client Standard Edition; c'est presque une blague courante que sûrement - étant donné le nombre de fonctionnalités qu'elle obtient dans chaque nouvelle version - cette édition dans son ensemble est sur le chemin de la dépréciation. Lors de réunions privées avec Microsoft, j'ai insisté pour que des fonctionnalités soient également incluses dans l'édition Standard, en particulier avec des fonctionnalités beaucoup plus avantageuses pour les petites entreprises que celles disposant d'un budget matériel illimité.
Les clients Enterprise Edition bénéficient des avantages de gestion et de performances offerts par le partitionnement de table, mais cette fonctionnalité n'est pas disponible dans Standard Edition. Une idée m'a récemment frappé qu'il existe un moyen d'obtenir au moins certains des avantages du partitionnement sur n'importe quelle édition, et cela n'implique pas de vues partitionnées. Cela ne veut pas dire que les vues partitionnées ne sont pas une option viable à considérer ; ceux-ci sont bien décrits par d'autres, y compris Daniel Hutmacher (Vues partitionnées sur le partitionnement de table) et Kimberly Tripp (Tables partitionnées v. Vues partitionnées - Pourquoi sont-elles toujours là ?). Mon idée est juste un peu plus simple à mettre en œuvre.
Votre nouveau héros :les index filtrés
Maintenant, je sais, cette fonctionnalité est un mot de quatre lettres pour certains; avant d'aller plus loin, vous devriez être à l'aise avec les index filtrés, ou au moins conscients de leurs limites. Quelques lectures pour vous donner un juste équilibre avant d'essayer de vous les vendre :
- Je parle de plusieurs lacunes dans Comment les index filtrés pourraient être une fonctionnalité plus puissante, et je signale de nombreux éléments Connect pour que vous puissiez voter ;
- Paul White (@SQL_Kiwi) parle des problèmes de réglage dans Limitations de l'optimiseur avec des index filtrés et également dans Un effet secondaire inattendu de l'ajout d'un index filtré ; et,
- Jes Borland (@grrl_geek) nous explique ce que vous pouvez (et ne pouvez pas) faire avec les index filtrés.
Lire tout ça ? Et tu es toujours là ? Génial.
Le TL; DR de ceci est que vous pouvez utiliser des index filtrés pour conserver toutes vos "données chaudes" dans une structure physique séparée, et même sur un matériel sous-jacent séparé (vous pouvez avoir un disque SSD ou PCIe rapide disponible, mais il peut ' t contenir toute la table).
Un exemple rapide
Il existe de nombreux cas d'utilisation où une partie des données est interrogée beaucoup plus fréquemment que le reste - pensez à un magasin de détail gérant les commandes, une boulangerie planifiant les livraisons de gâteaux de mariage ou un stade de football mesurant les données de fréquentation et de concession. Dans ces cas, la plupart ou la totalité de l'activité de requête quotidienne concerne les données "actuelles".
Restons simples; nous allons créer une base de données avec une table Orders très étroite :
CREATE DATABASE PoorManPartition;GO USE PoorManPartition;GO CREATE TABLE dbo.Orders( OrderID INT IDENTITY(1,1) PRIMARY KEY, OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(), OrderTotal DECIMAL(8,2) --, .. .autres colonnes...);
Maintenant, supposons que vous disposiez de suffisamment d'espace sur votre stockage rapide pour conserver un mois de données (avec une marge suffisante pour tenir compte de la saisonnalité et de la croissance future). Nous pouvons ajouter un nouveau groupe de fichiers et placer un fichier de données sur le lecteur rapide.
ALTER DATABASE PoorManPartition ADD FILEGROUP HotData;GO ALTER DATABASE PoorManPartition ADD FILE ( Nom =N'HotData', FileName =N'Z:\folder\HotData.mdf', Size =100MB, FileGrowth =25MB) TO FILEGROUP HotData;
Maintenant, créons un index filtré sur notre groupe de fichiers HotData, où le filtre inclut tout depuis le début de novembre 2015, et les colonnes communes impliquées dans les requêtes basées sur le temps sont dans la clé ou la liste d'inclusion :
CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>='20151101' AND OrderDate <'20151201' ON HotData;
Nous pouvons insérer quelques lignes et vérifier le plan d'exécution pour être sûr que les requêtes couvertes peuvent, en fait, utiliser l'index :
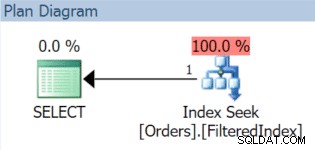
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');GO SELECT index_id, rows FROM sys.partitions WHERE object_id =OBJECT_ID(N'dbo.Orders'); /* Résultats :lignes index_id -------- ---- 1 3 2 2*/ SELECT OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151102' AND OrderDate <'20151106';
Le plan d'exécution résultant, bien sûr, utilise l'index filtré (même si le prédicat de filtre dans la requête ne correspond pas exactement à la définition de l'index) :
Maintenant, le 1er décembre arrive, et il est temps d'échanger nos données de novembre et de les remplacer par celles de décembre. Nous pouvons simplement recréer l'index filtré avec un nouveau prédicat de filtre et utiliser le DROP_EXISTING choix :
CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>='20151201' AND OrderDate <'20160101' WITH (DROP_EXISTING =ON) ON HotData;
Maintenant, nous pouvons ajouter quelques lignes supplémentaires, vérifier les statistiques de la partition et exécuter notre requête précédente et une nouvelle pour vérifier les index utilisés :
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');GO SELECT index_id, lignes FROM sys.partitions WHERE object_id =OBJECT_ID(N'dbo.Orders'); /* Résultats :lignes index_id -------- ---- 1 5 2 2*/ SELECT OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151102' AND OrderDate <'20151106'; SELECT OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151202' AND OrderDate <'20151204';
Dans ce cas, nous obtenons une analyse d'index clusterisé avec la requête de novembre :
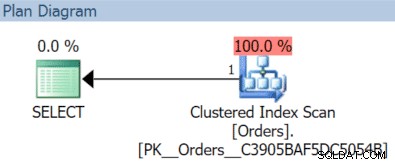
(Mais ce serait différent si nous avions un index séparé et non filtré avec OrderDate comme clé.)
Et je ne le montrerai plus, mais avec la requête de décembre, nous obtenons la même recherche d'index filtrée qu'auparavant.
Vous pouvez également gérer plusieurs index, un pour le mois en cours, un pour le mois précédent, etc., et vous pouvez simplement les gérer séparément (le 1er décembre, vous supprimez simplement l'index d'octobre et laissez celui de novembre seul, par exemple) . Vous pouvez également gérer plusieurs index de périodes plus ou moins longues (semaine en cours et précédente, trimestre en cours et précédent), etc. La solution est assez flexible.
En raison des limitations des index filtrés, je n'essaierai pas de présenter cela comme une solution parfaite, ni un remplacement complet du partitionnement de table ou des vues partitionnées. Changer une partition, par exemple, est une opération de métadonnées, tout en recréant un index avec DROP_EXISTING peut avoir beaucoup de journalisation (et puisque vous n'êtes pas sur Enterprise Edition, ne peut pas être exécuté en ligne). Vous pouvez également constater que les vues partitionnées sont plus rapides :il y a plus de travail autour de la maintenance de tables physiques séparées et des contraintes qui rendent la vue partitionnée possible, mais le gain en termes de performances des requêtes peut être meilleur dans certains cas.
Automatisation
Le fait de recréer l'index peut être automatisé assez facilement, en utilisant une tâche simple qui fait quelque chose comme ça une fois par mois (ou quelle que soit la taille de votre fenêtre "chaude") :
DECLARE @sql NVARCHAR(MAX), @dt DATE =DATEADD(DAY, 1-DAY(GETDATE()), GETDATE()); SET @sql =N'CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>=''' + CONVERT(CHAR(8), @dt, 112) + N''' WITH (DROP_EXISTING =ON ) ON HotData;'; EXEC PoorManPartition.sys.sp_executesql @sql;
Vous pouvez également créer plusieurs index des mois à l'avance, un peu comme créer de futures partitions à l'avance - après tout, les futurs index n'occuperont pas d'espace tant qu'il n'y aura pas de données pertinentes pour leurs prédicats. Et vous pouvez simplement supprimer les index qui segmentaient les anciennes données que vous souhaitez maintenant refroidir.
Rétrospective
Après avoir terminé cet article, bien sûr, je suis tombé sur un autre article de Kimberly Tripp, que vous devriez lire avant de poursuivre quoi que ce soit que je préconise ici (et que j'avais lu avant de commencer) :
- Que diriez-vous des index filtrés au lieu du partitionnement ?
Pour plusieurs raisons, Kimberly est beaucoup plus en faveur des vues partitionnées pour implémenter quelque chose de similaire au partitionnement dans l'édition Standard ; cependant, pour certains scénarios, l'utilisation d'index filtrés m'intrigue encore suffisamment pour poursuivre mon expérimentation. L'un des domaines où les index filtrés peuvent être bénéfiques est lorsque vos données "chaudes" ont plusieurs critères - pas seulement découpées par date, mais aussi par d'autres attributs (peut-être voulez-vous des requêtes rapides sur toutes les commandes de ce mois qui sont pour un niveau spécifique du client ou au-dessus d'un certain montant en dollars).
Suivant…
Dans un prochain article, je jouerai avec ce concept sur un système haut de gamme, avec un volume et une charge de travail réels. Je souhaite découvrir les différences de performances entre cette solution, un index de couverture non filtré, une vue partitionnée et une table partitionnée. À l'intérieur d'une machine virtuelle sur un ordinateur portable avec uniquement des disques SSD disponibles, les tests à grande échelle ne seraient probablement pas réalistes ou équitables.