Dans mon dernier message, j'ai montré quelques approches efficaces de la concaténation groupée. Cette fois-ci, je voulais parler de quelques facettes supplémentaires de ce problème que nous pouvons accomplir facilement avec le FOR XML PATH approche :trier la liste et supprimer les doublons.
J'ai vu que les gens voulaient que la liste séparée par des virgules soit ordonnée de plusieurs manières. Parfois, ils veulent que l'élément de la liste soit classé par ordre alphabétique; Je l'ai déjà montré dans mon message précédent. Mais parfois, ils veulent qu'il soit trié par un autre attribut qui n'est en fait pas introduit dans la sortie ; par exemple, je souhaite peut-être ordonner la liste par élément le plus récent en premier. Prenons un exemple simple, où nous avons une table Employees et une table CoffeeOrders. Remplissons simplement les commandes d'une personne pendant quelques jours :
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
Si nous utilisons l'approche existante sans spécifier un ORDER BY , nous obtenons un ordre arbitraire (dans ce cas, il est fort probable que vous verrez les lignes dans l'ordre dans lequel elles ont été insérées, mais ne dépendez pas de cela avec des ensembles de données plus volumineux, plus d'index, etc.) :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Résultats (rappelez-vous que vous pouvez obtenir des résultats *différents* sauf si vous spécifiez un ORDER BY ):
Cric | Grand double double, Moyen double double, Grand Vanilla Latte, Moyen double double
Si nous voulons ordonner la liste par ordre alphabétique, c'est simple; nous ajoutons simplement ORDER BY c.OrderDetails :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Résultats :
Nom | CommandesCric | Grand double double, Grand Latte à la vanille, Moyen double double, Moyen double double
Nous pouvons également trier par une colonne qui n'apparaît pas dans le jeu de résultats ; par exemple, nous pouvons d'abord commander par commande de café la plus récente :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Résultats :
Nom | CommandesCric | Double double moyen, Grand Latte à la vanille, Double double moyen, Grand double double
Une autre chose que nous voulons souvent faire est de supprimer les doublons; après tout, il y a peu de raisons de voir "double double moyen" deux fois. Nous pouvons éliminer cela en utilisant GROUP BY :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Maintenant, cela * arrive * pour trier la sortie par ordre alphabétique, mais encore une fois, vous ne pouvez pas vous fier à ceci :
Nom | CommandesCric | Grand double double, Grand Latte à la vanille, Moyen double double
Si vous voulez garantir que vous commandez de cette façon, vous pouvez simplement ajouter à nouveau un ORDER BY :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Les résultats sont les mêmes (mais je le répète, ce n'est qu'une coïncidence dans ce cas ; si vous voulez cet ordre, dites-le toujours) :
Nom | CommandesCric | Grand double double, Grand Latte à la vanille, Moyen double double
Mais que se passe-t-il si nous voulons éliminer les doublons *et* trier d'abord la liste par commande de café la plus récente ? Votre premier réflexe pourrait être de conserver le GROUP BY et changez simplement le ORDER BY , comme ceci :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Cela ne fonctionnera pas, puisque le OrderDate n'est pas groupé ou agrégé dans le cadre de la requête :
La colonne "dbo.CoffeeOrders.OrderDate" n'est pas valide dans la clause ORDER BY car elle n'est contenue ni dans une fonction d'agrégat ni dans la clause GROUP BY.
Une solution de contournement, qui rend certes la requête un peu plus laide, consiste à regrouper d'abord les commandes séparément, puis à ne prendre que les lignes avec la date maximale pour cette commande de café par employé :
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Résultats :
Nom | CommandesCric | Double double moyen, Grand Latte à la vanille, Grand double double
Cela permet d'atteindre nos deux objectifs :nous avons éliminé les doublons et nous avons classé la liste en fonction de quelque chose qui n'y figure pas réellement.
Performances
Vous vous demandez peut-être à quel point ces méthodes fonctionnent mal par rapport à un ensemble de données plus robuste. Je vais remplir notre table avec 100 000 lignes, voir comment ils s'en sortent sans aucun index supplémentaire, puis exécuter à nouveau les mêmes requêtes avec un peu de réglage d'index pour prendre en charge nos requêtes. Commençons par obtenir 100 000 lignes réparties sur 1 000 employés :
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; Maintenant, exécutons chacune de nos requêtes deux fois et voyons à quoi ressemble le timing au deuxième essai (nous allons faire un acte de foi ici et supposer que - dans un monde idéal - nous travaillerons avec un cache amorcé ). Je les ai exécutés dans SQL Sentry Plan Explorer, car c'est le moyen le plus simple que je connaisse pour chronométrer et comparer un ensemble de requêtes individuelles :
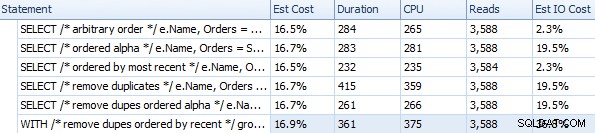 Durée et autres métriques d'exécution pour différentes approches FOR XML PATH
Durée et autres métriques d'exécution pour différentes approches FOR XML PATH
Ces timings (la durée est en millisecondes) ne sont vraiment pas si mauvais du tout à mon humble avis, quand on pense à ce qui se fait réellement ici. Le plan le plus compliqué, du moins visuellement, semblait être celui où nous supprimions les doublons et triions par commande la plus récente :
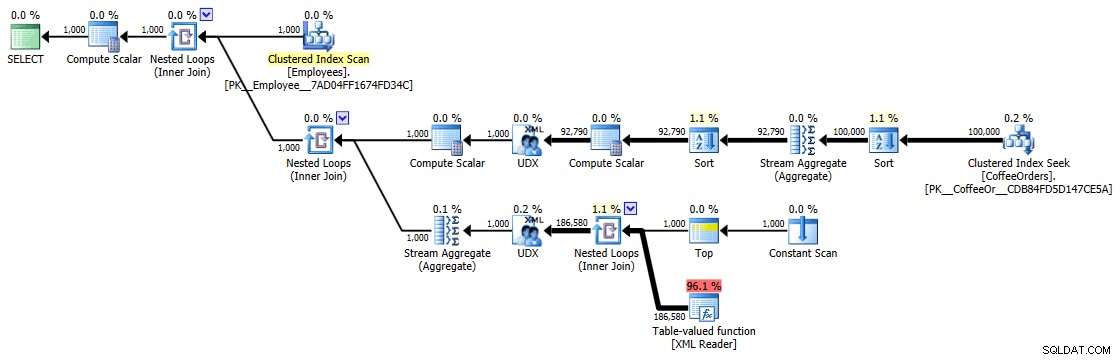 Plan d'exécution pour les requêtes groupées et triées
Plan d'exécution pour les requêtes groupées et triées
Mais même l'opérateur le plus cher ici - la fonction table XML - semble être entièrement CPU (même si j'admettrai librement que je ne suis pas sûr de la quantité de travail réel exposée dans les détails du plan de requête):
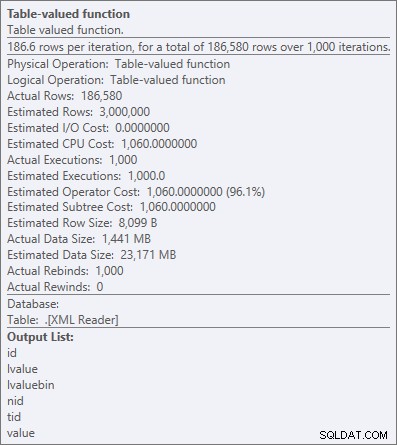 Propriétés de l'opérateur pour la fonction table XML
Propriétés de l'opérateur pour la fonction table XML
"Tous les processeurs" sont généralement corrects, car la plupart des systèmes sont liés aux E/S et/ou à la mémoire, et non au processeur. Comme je le dis assez souvent, dans la plupart des systèmes, j'échangerai une partie de ma marge CPU contre de la mémoire ou du disque n'importe quel jour de la semaine (une des raisons pour lesquelles j'aime OPTION (RECOMPILE) comme solution aux problèmes de détection de paramètres omniprésents).
Cela dit, je vous encourage fortement à tester ces approches par rapport à des résultats similaires que vous pouvez obtenir de l'approche GROUP_CONCAT CLR sur CodePlex, ainsi qu'à effectuer l'agrégation et le tri au niveau de la présentation (en particulier si vous conservez les données normalisées d'une manière ou d'une autre de la couche de mise en cache).