Dans la partie 2 de cette série, vous avez ajouté la possibilité d'enregistrer les modifications apportées via l'API REST à une base de données à l'aide de SQLAlchemy et appris à sérialiser ces données pour l'API REST à l'aide de Marshmallow. Connecter l'API REST à une base de données afin que l'application puisse apporter des modifications aux données existantes et créer de nouvelles données est formidable et rend l'application beaucoup plus utile et robuste.
Cependant, ce n'est qu'une partie de la puissance offerte par une base de données. Une fonctionnalité encore plus puissante est le R partie du SGBD systèmes :relations . Dans une base de données, une relation est la capacité de connecter deux ou plusieurs tables ensemble de manière significative. Dans cet article, vous apprendrez à mettre en place des relations et à transformer votre Person base de données dans une application Web de mini-blogging.
Dans cet article, vous apprendrez :
- Pourquoi plus d'une table dans une base de données est utile et importante
- Comment les tableaux sont liés les uns aux autres
- Comment SQLAlchemy peut vous aider à gérer les relations
- Comment les relations vous aident à créer une application de mini-blogging
À qui s'adresse cet article
La partie 1 de cette série vous a guidé dans la création d'une API REST, et la partie 2 vous a montré comment connecter cette API REST à une base de données.
Cet article élargit davantage votre ceinture à outils de programmation. Vous apprendrez à créer des structures de données hiérarchiques représentées sous forme de relations un-à-plusieurs par SQLAlchemy. De plus, vous allez étendre l'API REST que vous avez déjà créée pour fournir la prise en charge CRUD (créer, lire, mettre à jour et supprimer) pour les éléments de cette structure hiérarchique.
L'application Web présentée dans la partie 2 verra ses fichiers HTML et JavaScript modifiés de manière majeure pour créer une application de mini-blogging plus entièrement fonctionnelle. Vous pouvez consulter la version finale du code de la partie 2 dans le référentiel GitHub de cet article.
Accrochez-vous pendant que vous commencez à créer des relations et votre application de mini-blogging !
Dépendances supplémentaires
Il n'y a pas de nouvelles dépendances Python au-delà de ce qui était requis pour l'article de la partie 2. Cependant, vous utiliserez deux nouveaux modules JavaScript dans l'application Web pour rendre les choses plus faciles et plus cohérentes. Les deux modules sont les suivants :
- Handlebars.js est un moteur de template pour JavaScript, un peu comme Jinja2 pour Flask.
- Moment.js est un module d'analyse et de formatage datetime qui facilite l'affichage des horodatages UTC.
Vous n'avez pas besoin de télécharger l'un ou l'autre, car l'application Web les obtiendra directement du CDN (Content Delivery Network) de Cloudflare, comme vous le faites déjà pour le module jQuery.
Données personnelles étendues pour les blogs
Dans la partie 2, les People les données existaient sous forme de dictionnaire dans build_database.py Code Python. C'est ce que vous avez utilisé pour remplir la base de données avec certaines données initiales. Vous allez modifier les People structure de données pour donner à chaque personne une liste de notes qui lui sont associées. Le nouveau People la structure des données ressemblera à ceci :
# Data to initialize database with
PEOPLE = [
{
"fname": "Doug",
"lname": "Farrell",
"notes": [
("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
("This could be useful", "2019-01-08 22:17:54"),
("Well, sort of useful", "2019-03-06 22:17:54"),
],
},
{
"fname": "Kent",
"lname": "Brockman",
"notes": [
(
"I'm going to make really profound observations",
"2019-01-07 22:17:54",
),
(
"Maybe they'll be more obvious than I thought",
"2019-02-06 22:17:54",
),
],
},
{
"fname": "Bunny",
"lname": "Easter",
"notes": [
("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
("I'm really late delivering these!", "2019-04-06 22:17:54"),
],
},
]
Chaque personne dans le People le dictionnaire inclut maintenant une clé appelée notes , qui est associé à une liste contenant des tuples de données. Chaque tuple dans les notes la liste représente une seule note contenant le contenu et un horodatage. Les horodatages sont initialisés (plutôt que créés dynamiquement) pour démontrer la commande ultérieurement dans l'API REST.
Chaque personne est associée à plusieurs notes et chaque note est associée à une seule personne. Cette hiérarchie de données est connue sous le nom de relation un-à-plusieurs, où un seul objet parent est lié à de nombreux objets enfants. Vous verrez comment cette relation un-à-plusieurs est gérée dans la base de données avec SQLAlchemy.
Approche par force brute
La base de données que vous avez créée a stocké les données dans une table, et une table est un tableau à deux dimensions de lignes et de colonnes. Les People peuvent-ils dictionnaire ci-dessus soit représenté dans un seul tableau de lignes et de colonnes ? Cela peut être, de la manière suivante, dans votre person tableau de la base de données. Malheureusement, inclure toutes les données réelles dans l'exemple crée une barre de défilement pour le tableau, comme vous le verrez ci-dessous :
person_id | lname | fname | timestamp | content | note_timestamp |
|---|---|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01 | Cool, une application de mini-blogging ! | 2019-01-06 22:17:54 |
| 2 | Farrell | Doug | 2018-08-08 21:16:01 | Cela pourrait être utile | 2019-01-08 22:17:54 |
| 3 | Farrell | Doug | 2018-08-08 21:16:01 | Eh bien, en quelque sorte utile | 2019-03-06 22:17:54 |
| 4 | Brockman | Kent | 2018-08-08 21:16:01 | Je vais faire des observations vraiment profondes | 2019-01-07 22:17:54 |
| 5 | Brockman | Kent | 2018-08-08 21:16:01 | Peut-être qu'ils seront plus évidents que je ne le pensais | 2019-02-06 22:17:54 |
| 6 | Pâques | Lapin | 2018-08-08 21:16:01 | Quelqu'un a-t-il vu mes œufs de Pâques ? | 2019-01-07 22:47:54 |
| 7 | Pâques | Lapin | 2018-08-08 21:16:01 | Je suis vraiment en retard pour les livrer ! | 2019-04-06 22:17:54 |
Le tableau ci-dessus fonctionnerait réellement. Toutes les données sont représentées, et une seule personne est associée à une collection de notes différentes.
Avantages
Conceptuellement, la structure du tableau ci-dessus a l'avantage d'être relativement simple à comprendre. Vous pourriez même faire valoir que les données pourraient être conservées dans un fichier plat au lieu d'une base de données.
En raison de la structure bidimensionnelle du tableau, vous pouvez stocker et utiliser ces données dans une feuille de calcul. Les feuilles de calcul ont été un peu utilisées comme stockage de données.
Inconvénients
Bien que la structure de table ci-dessus fonctionne, elle présente de réels inconvénients.
Afin de représenter l'ensemble des notes, toutes les données de chaque personne sont répétées pour chaque note unique, les données de la personne sont donc redondantes. Ce n'est pas si grave pour vos données personnelles car il n'y a pas beaucoup de colonnes. Mais imaginez si une personne avait beaucoup plus de colonnes. Même avec de grands disques durs, cela peut devenir un problème de stockage si vous traitez des millions de lignes de données.
Avoir des données redondantes comme celles-ci peut entraîner des problèmes de maintenance au fil du temps. Par exemple, que se passerait-il si le lapin de Pâques décidait qu'un changement de nom était une bonne idée. Pour ce faire, chaque enregistrement contenant le nom du lapin de Pâques devrait être mis à jour afin de maintenir la cohérence des données. Ce type de travail sur la base de données peut entraîner une incohérence des données, en particulier si le travail est effectué par une personne exécutant une requête SQL à la main.
Nommer les colonnes devient gênant. Dans le tableau ci-dessus, il y a un timestamp colonne utilisée pour suivre l'heure de création et de mise à jour d'une personne dans la table. Vous souhaitez également disposer d'une fonctionnalité similaire pour l'heure de création et de mise à jour d'une note, mais parce que timestamp est déjà utilisé, un nom artificiel de note_timestamp est utilisé.
Et si vous vouliez ajouter des relations un-à-plusieurs supplémentaires à la person table? Par exemple, pour inclure les enfants ou les numéros de téléphone d'une personne. Chaque personne peut avoir plusieurs enfants et plusieurs numéros de téléphone. Cela pourrait être fait relativement facilement aux Python People dictionnaire ci-dessus en ajoutant children et phone_numbers clés avec de nouvelles listes contenant les données.
Cependant, représenter ces nouvelles relations un-à-plusieurs dans votre person table de base de données ci-dessus devient beaucoup plus difficile. Chaque nouvelle relation un-à-plusieurs augmente considérablement le nombre de lignes nécessaires pour la représenter pour chaque entrée unique dans les données enfant. De plus, les problèmes associés à la redondance des données deviennent plus importants et plus difficiles à gérer.
Enfin, les données que vous obtiendriez de la structure de table ci-dessus ne seraient pas très Pythonic :ce serait juste une grande liste de listes. SQLAlchemy ne serait pas en mesure de vous aider beaucoup car la relation n'existe pas.
Approche de base de données relationnelle
Sur la base de ce que vous avez vu ci-dessus, il devient clair qu'essayer de représenter même un ensemble de données modérément complexe dans une seule table devient assez rapidement ingérable. Dans ces conditions, quelle alternative offre une base de données ? C'est là que le R partie du SGBD bases de données entre en jeu. La représentation des relations supprime les inconvénients décrits ci-dessus.
Au lieu d'essayer de représenter des données hiérarchiques dans une seule table, les données sont divisées en plusieurs tables, avec un mécanisme pour les relier les unes aux autres. Les tableaux sont répartis le long des lignes de collecte, donc pour vos People dictionnaire ci-dessus, cela signifie qu'il y aura un tableau représentant les personnes et un autre représentant les notes. Cela ramène votre person d'origine tableau, qui ressemble à ceci :
person_id | lname | fname | timestamp |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Pâques | Lapin | 2018-08-08 21:16:01.886834 |
Pour représenter les nouvelles informations de note, vous allez créer un nouveau tableau appelé notes . (Rappelez-vous notre convention de dénomination de table au singulier.) La table ressemble à ceci :
note_id | person_id | content | timestamp |
|---|---|---|---|
| 1 | 1 | Cool, une application de mini-blogging ! | 2019-01-06 22:17:54 |
| 2 | 1 | Cela pourrait être utile | 2019-01-08 22:17:54 |
| 3 | 1 | Eh bien, en quelque sorte utile | 2019-03-06 22:17:54 |
| 4 | 2 | Je vais faire des observations vraiment profondes | 2019-01-07 22:17:54 |
| 5 | 2 | Peut-être qu'ils seront plus évidents que je ne le pensais | 2019-02-06 22:17:54 |
| 6 | 3 | Quelqu'un a-t-il vu mes œufs de Pâques ? | 2019-01-07 22:47:54 |
| 7 | 3 | Je suis vraiment en retard pour les livrer ! | 2019-04-06 22:17:54 |
Notez que, comme la person tableau, la notes table a un identifiant unique appelé note_id , qui est la clé primaire de la notes table. Une chose qui n'est pas évidente est l'inclusion du person_id valeur dans le tableau. A quoi ça sert ? C'est ce qui crée la relation avec la person table. Alors que note_id est la clé primaire de la table, person_id est ce qu'on appelle une clé étrangère.
La clé étrangère donne chaque entrée dans la notes table la clé primaire de la person l'enregistrement auquel il est associé. Grâce à cela, SQLAlchemy peut rassembler toutes les notes associées à chaque personne en connectant le person.person_id clé primaire de note.person_id clé étrangère, création d'une relation.
Avantages
En divisant l'ensemble de données en deux tables et en introduisant le concept de clé étrangère, vous avez rendu les données un peu plus complexes à penser, vous avez résolu les inconvénients d'une représentation de table unique. SQLAlchemy vous aidera à encoder assez facilement la complexité accrue.
Les données ne sont plus redondantes dans la base de données. Il n'y a qu'une seule entrée de personne pour chaque personne que vous souhaitez stocker dans la base de données. Cela résout immédiatement le problème de stockage et simplifie considérablement les problèmes de maintenance.
Si le lapin de Pâques voulait toujours changer de nom, vous n'auriez qu'à changer une seule ligne dans la person table, et tout autre élément lié à cette ligne (comme la notes table) profiterait immédiatement du changement.
La dénomination des colonnes est plus cohérente et significative. Étant donné que les données de personne et de note existent dans des tables distinctes, l'horodatage de création et de mise à jour peut être nommé de manière cohérente dans les deux tables, car il n'y a pas de conflit de noms entre les tables.
De plus, vous n'auriez plus besoin de créer des permutations de chaque ligne pour les nouvelles relations un-à-plusieurs que vous pourriez vouloir représenter. Emmenez nos children et phone_numbers exemple de tout à l'heure. L'implémentation de ceci nécessiterait child et phone_number les tables. Chaque table contiendrait une clé étrangère de person_id le rapportant à la person tableau.
En utilisant SQLAlchemy, les données que vous obtiendriez des tables ci-dessus seraient plus immédiatement utiles, car ce que vous obtiendriez est un objet pour chaque ligne de personne. Cet objet a des attributs nommés équivalents aux colonnes de la table. L'un de ces attributs est une liste Python contenant les objets de note associés.
Inconvénients
Là où l'approche par force brute était plus simple à comprendre, le concept de clés étrangères et de relations rend la réflexion sur les données un peu plus abstraite. Cette abstraction doit être pensée pour chaque relation que vous établissez entre les tables.
Utiliser des relations signifie s'engager à utiliser un système de base de données. Il s'agit d'un autre outil à installer, apprendre et maintenir au-delà de l'application qui utilise réellement les données.
Modèles SQLAlchemy
Pour utiliser les deux tables ci-dessus et la relation entre elles, vous devrez créer des modèles SQLAlchemy qui connaissent les deux tables et la relation entre elles. Voici le SQLAlchemy Person modèle de la partie 2, mis à jour pour inclure une relation avec une collection de notes :
1class Person(db.Model):
2 __tablename__ = 'person'
3 person_id = db.Column(db.Integer, primary_key=True)
4 lname = db.Column(db.String(32))
5 fname = db.Column(db.String(32))
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
9 notes = db.relationship(
10 'Note',
11 backref='person',
12 cascade='all, delete, delete-orphan',
13 single_parent=True,
14 order_by='desc(Note.timestamp)'
15 )
Les lignes 1 à 8 de la classe Python ci-dessus ressemblent exactement à ce que vous avez créé auparavant dans la partie 2. Les lignes 9 à 16 créent un nouvel attribut dans Person classe appelée notes . Cette nouvelle notes attributs est défini dans les lignes de code suivantes :
-
Ligne 9 : Comme les autres attributs de la classe, cette ligne crée un nouvel attribut appelé
noteset le définit égal à une instance d'un objet appelédb.relationship. Cet objet crée la relation que vous ajoutez à laPersonclass et est créé avec tous les paramètres définis dans les lignes qui suivent. -
Ligne 10 : Le paramètre de chaîne
'Note'définit la classe SQLAlchemy que laPersonclasse sera liée à. LaNotela classe n'est pas encore définie, c'est pourquoi c'est une chaîne ici. Il s'agit d'une référence directe et aide à gérer les problèmes que l'ordre des définitions pourrait causer lorsque quelque chose est nécessaire et n'est défini que plus tard dans le code. La'Note'chaîne autorise laPersonclass pour trouver laNoteclasse au moment de l'exécution, qui est après les deuxPersonetNoteont été définis. -
Ligne 11 : Le
backref='person'paramètre est plus délicat. Il crée ce qu'on appelle une référence vers l'arrière dansNoteobjets. Chaque instance d'uneNotel'objet contiendra un attribut appeléperson. Lapersonl'attribut fait référence à l'objet parent qu'uneNoteparticulière l'instance est associée. Avoir une référence à l'objet parent (persondans ce cas) dans l'enfant peut être très utile si votre code itère sur des notes et doit inclure des informations sur le parent. Cela se produit étonnamment souvent dans le code de rendu d'affichage. -
Ligne 12 : La
cascade='all, delete, delete-orphan'le paramètre détermine comment traiter les instances d'objet de note lorsque des modifications sont apportées au parentPersonexemple. Par exemple, lorsqu'unePersonobjet est supprimé, SQLAlchemy créera le SQL nécessaire pour supprimer laPersonde la base de données. De plus, ce paramètre lui indique de supprimer également toutes lesNoteinstances qui lui sont associées. Vous pouvez en savoir plus sur ces options dans la documentation de SQLAlchemy. -
Ligne 13 : Le
single_parent=Truele paramètre est obligatoire sidelete-orphanfait partie de lacascadeprécédente paramètre. Cela indique à SQLAlchemy de ne pas autoriser lesNoteorphelins instances (uneNotesans parentPersonobjet) existe parce que chaqueNotea un seul parent. -
Ligne 14 : Le
order_by='desc(Note.timestamp)'le paramètre indique à SQLAlchemy comment trier laNoteinstances associées à unePerson. Lorsqu'unePersonl'objet est récupéré, par défaut lesnotesla liste d'attributs contiendraNoteobjets dans un ordre inconnu. Le SQLAlchemydesc(...)triera les notes par ordre décroissant de la plus récente à la plus ancienne. Si cette ligne était plutôtorder_by='Note.timestamp', SQLAlchemy utiliserait par défaut leasc(...)et trier les notes par ordre croissant, de la plus ancienne à la plus récente.
Maintenant que votre Person le modèle a les nouvelles notes , et cela représente la relation un-à-plusieurs avec Note objets, vous devrez définir un modèle SQLAlchemy pour une Note :
1class Note(db.Model):
2 __tablename__ = 'note'
3 note_id = db.Column(db.Integer, primary_key=True)
4 person_id = db.Column(db.Integer, db.ForeignKey('person.person_id'))
5 content = db.Column(db.String, nullable=False)
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
La Note class définit les attributs composant une note comme on le voit dans notre exemple notes table de base de données ci-dessus. Les attributs sont définis ici :
-
Ligne 1 crée la
Noteclasse, héritant dedb.Model, exactement comme vous l'avez fait auparavant lors de la création de laPersonclasse. -
Ligne 2 indique à la classe quelle table de base de données utiliser pour stocker
Noteobjets. -
Ligne 3 crée le
note_idattribut, en le définissant comme une valeur entière et comme clé primaire pour laNoteobjet. -
Ligne 4 crée le
person_idattribut, et le définit comme la clé étrangère, reliant laNoteclasse à laPersonclasse en utilisant leperson.person_idclé primaire. Ceci, et lesPerson.notesattribut, sont comment SQLAlchemy sait quoi faire lors de l'interaction avecPersonetNoteobjets. -
Ligne 5 crée le
content, qui contient le texte réel de la note. Lenullable=Falseindique que vous pouvez créer de nouvelles notes sans contenu. -
Ligne 6 crée le
timestampattribut, et exactement comme lePersonclass, cela contient l'heure de création ou de mise à jour pour uneNoteparticulière exemple.
Initialiser la base de données
Maintenant que vous avez mis à jour la Person et créé la Note modèles, vous les utiliserez pour reconstruire la base de données de test people.db . Vous ferez cela en mettant à jour le build_database.py code de la partie 2. Voici à quoi ressemblera le code :
1import os
2from datetime import datetime
3from config import db
4from models import Person, Note
5
6# Data to initialize database with
7PEOPLE = [
8 {
9 "fname": "Doug",
10 "lname": "Farrell",
11 "notes": [
12 ("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
13 ("This could be useful", "2019-01-08 22:17:54"),
14 ("Well, sort of useful", "2019-03-06 22:17:54"),
15 ],
16 },
17 {
18 "fname": "Kent",
19 "lname": "Brockman",
20 "notes": [
21 (
22 "I'm going to make really profound observations",
23 "2019-01-07 22:17:54",
24 ),
25 (
26 "Maybe they'll be more obvious than I thought",
27 "2019-02-06 22:17:54",
28 ),
29 ],
30 },
31 {
32 "fname": "Bunny",
33 "lname": "Easter",
34 "notes": [
35 ("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
36 ("I'm really late delivering these!", "2019-04-06 22:17:54"),
37 ],
38 },
39]
40
41# Delete database file if it exists currently
42if os.path.exists("people.db"):
43 os.remove("people.db")
44
45# Create the database
46db.create_all()
47
48# Iterate over the PEOPLE structure and populate the database
49for person in PEOPLE:
50 p = Person(lname=person.get("lname"), fname=person.get("fname"))
51
52 # Add the notes for the person
53 for note in person.get("notes"):
54 content, timestamp = note
55 p.notes.append(
56 Note(
57 content=content,
58 timestamp=datetime.strptime(timestamp, "%Y-%m-%d %H:%M:%S"),
59 )
60 )
61 db.session.add(p)
62
63db.session.commit()
Le code ci-dessus provient de la partie 2, avec quelques modifications pour créer la relation un-à-plusieurs entre Person et Note . Voici les lignes mises à jour ou ajoutées au code :
-
Ligne 4 a été mis à jour pour importer la
Noteclasse définie précédemment. -
Lignes 7 à 39 contenir le
PEOPLEmis à jour dictionnaire contenant nos données personnelles, ainsi que la liste des notes associées à chaque personne. Ces données seront insérées dans la base de données. -
Lignes 49 à 61 parcourir les
PEOPLEdictionnaire, obtenant chaquepersontour à tour et l'utiliser pour créer unePersonobjet. -
Ligne 53 itère sur
person.noteslist, obtenant chaquenotestour à tour. -
Ligne 54 déballe le
contentettimestampde chaquenotestuple. -
Ligne 55 à 60 crée une
Noteobjet et l'ajoute à la collection de notes de la personne en utilisantp.notes.append(). -
Ligne 61 ajoute la
Personobjetpà la session de base de données. -
Ligne 63 valide toute l'activité de la session dans la base de données. C'est à ce stade que toutes les données sont écrites dans la
personetnotetables danspeople.dbfichier de base de données.
Vous pouvez voir que travailler avec les notes collection dans la Person instance d'objet p est comme travailler avec n'importe quelle autre liste en Python. SQLAlchemy prend en charge les informations de relation un-à-plusieurs sous-jacentes lorsque le db.session.commit() l'appel est passé.
Par exemple, tout comme une Person l'instance a son champ de clé primaire person_id initialisé par SQLAlchemy lors de sa validation dans la base de données, instances de Note verront leurs champs de clé primaire initialisés. De plus, la Note clé étrangère person_id sera également initialisé avec la valeur de la clé primaire de la Person instance à laquelle il est associé.
Voici un exemple d'instance d'une Person objet avant le db.session.commit() dans une sorte de pseudo-code :
Person (
person_id = None
lname = 'Farrell'
fname = 'Doug'
timestamp = None
notes = [
Note (
note_id = None
person_id = None
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Voici l'exemple Person objet après le db.session.commit() :
Person (
person_id = 1
lname = 'Farrell'
fname = 'Doug'
timestamp = '2019-02-02 21:27:10.336'
notes = [
Note (
note_id = 1
person_id = 1
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = 2
person_id = 1
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = 3
person_id = 1
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
La différence importante entre les deux est que la clé primaire de la Person et Note objets a été initialisé. Le moteur de base de données s'en est occupé lorsque les objets ont été créés grâce à la fonction d'auto-incrémentation des clés primaires abordée dans la partie 2.
De plus, le person_id clé étrangère dans tous les Note instances a été initialisé pour référencer son parent. Cela se produit en raison de l'ordre dans lequel la Person et Note les objets sont créés dans la base de données.
SQLAlchemy est conscient de la relation entre Person et Note objets. Lorsqu'une Person l'objet est dédié à la person table de base de données, SQLAlchemy obtient le person_id valeur de la clé primaire. Cette valeur est utilisée pour initialiser la valeur de clé étrangère de person_id dans une Note objet avant qu'il ne soit validé dans la base de données.
SQLAlchemy s'occupe de ce travail de maintenance de la base de données en raison des informations que vous avez transmises lors de la Person.notes l'attribut a été initialisé avec le db.relationship(...) objet.
De plus, le Person.timestamp l'attribut a été initialisé avec l'horodatage actuel.
Exécution de build_database.py programme à partir de la ligne de commande (dans l'environnement virtuel recréera la base de données avec les nouveaux ajouts, la préparant à être utilisée avec l'application Web. Cette ligne de commande reconstruira la base de données :
$ python build_database.py
Le build_database.py Le programme utilitaire n'affiche aucun message s'il s'exécute correctement. S'il lève une exception, une erreur sera imprimée à l'écran.
Mettre à jour l'API REST
Vous avez mis à jour les modèles SQLAlchemy et les avez utilisés pour mettre à jour people.db base de données. Il est maintenant temps de mettre à jour l'API REST pour permettre l'accès aux nouvelles informations sur les notes. Voici l'API REST que vous avez créée dans la partie 2 :
| Action | Verbe HTTP | Chemin de l'URL | Description |
|---|---|---|---|
| Créer | POST | /api/people | URL pour créer une nouvelle personne |
| Lire | GET | /api/people | URL pour lire une collection de personnes |
| Lire | GET | /api/people/{person_id} | URL pour lire une seule personne par person_id |
| Mettre à jour | PUT | /api/people/{person_id} | URL pour mettre à jour une personne existante par person_id |
| Supprimer | DELETE | /api/people/{person_id} | URL pour supprimer une personne existante par person_id |
L'API REST ci-dessus fournit des chemins d'URL HTTP vers des collections d'objets et vers les objets eux-mêmes. Vous pouvez obtenir une liste de personnes ou interagir avec une seule personne à partir de cette liste de personnes. Ce style de chemin affine ce qui est renvoyé de gauche à droite, devenant plus granulaire au fur et à mesure.
Vous continuerez ce modèle de gauche à droite pour obtenir plus de précision et accéder aux collections de notes. Voici l'API REST étendue que vous allez créer afin de fournir des notes à l'application Web du mini-blog :
| Action | Verbe HTTP | Chemin de l'URL | Description |
|---|---|---|---|
| Créer | POST | /api/people/{person_id}/notes | URL pour créer une nouvelle note |
| Lire | GET | /api/people/{person_id}/notes/{note_id} | URL pour lire la note d'une seule personne |
| Mettre à jour | PUT | api/people/{person_id}/notes/{note_id} | URL pour mettre à jour la note unique d'une seule personne |
| Supprimer | DELETE | api/people/{person_id}/notes/{note_id} | URL pour supprimer la note unique d'une seule personne |
| Lire | GET | /api/notes | URL pour obtenir toutes les notes de toutes les personnes triées par note.timestamp |
Il existe deux variantes dans les notes partie de l'API REST par rapport à la convention utilisée dans le people rubrique :
-
Il n'y a pas d'URL définie pour obtenir toutes les
notesassocié à une personne, seulement une URL pour obtenir une seule note. Cela aurait rendu l'API REST complète d'une certaine manière, mais l'application Web que vous créerez plus tard n'a pas besoin de cette fonctionnalité. Par conséquent, il a été laissé de côté. -
Il y a l'inclusion de la dernière URL
/api/notes. Il s'agit d'une méthode pratique créée pour l'application Web. It will be used in the mini-blog on the home page to show all the notes in the system. There isn’t a way to get this information readily using the REST API pathing style as designed, so this shortcut has been added.
As in Part 2, the REST API is configured in the swagger.yml fichier.
Remarque :
The idea of designing a REST API with a path that gets more and more granular as you move from left to right is very useful. Thinking this way can help clarify the relationships between different parts of a database. Just be aware that there are realistic limits to how far down a hierarchical structure this kind of design should be taken.
For example, what if the Note object had a collection of its own, something like comments on the notes. Using the current design ideas, this would lead to a URL that went something like this:/api/people/{person_id}/notes/{note_id}/comments/{comment_id}
There is no practical limit to this kind of design, but there is one for usefulness. In actual use in real applications, a long, multilevel URL like that one is hardly ever needed. A more common pattern is to get a list of intervening objects (like notes) and then use a separate API entry point to get a single comment for an application use case.
Implement the API
With the updated REST API defined in the swagger.yml file, you’ll need to update the implementation provided by the Python modules. This means updating existing module files, like models.py and people.py , and creating a new module file called notes.py to implement support for Notes in the extended REST API.
Update Response JSON
The purpose of the REST API is to get useful JSON data out of the database. Now that you’ve updated the SQLAlchemy Person and created the Note models, you’ll need to update the Marshmallow schema models as well. As you may recall from Part 2, Marshmallow is the module that translates the SQLAlchemy objects into Python objects suitable for creating JSON strings.
The updated and newly created Marshmallow schemas are in the models.py module, which are explained below, and look like this:
1class PersonSchema(ma.ModelSchema):
2 class Meta:
3 model = Person
4 sqla_session = db.session
5 notes = fields.Nested('PersonNoteSchema', default=[], many=True)
6
7class PersonNoteSchema(ma.ModelSchema):
8 """
9 This class exists to get around a recursion issue
10 """
11 note_id = fields.Int()
12 person_id = fields.Int()
13 content = fields.Str()
14 timestamp = fields.Str()
15
16class NoteSchema(ma.ModelSchema):
17 class Meta:
18 model = Note
19 sqla_session = db.session
20 person = fields.Nested('NotePersonSchema', default=None)
21
22class NotePersonSchema(ma.ModelSchema):
23 """
24 This class exists to get around a recursion issue
25 """
26 person_id = fields.Int()
27 lname = fields.Str()
28 fname = fields.Str()
29 timestamp = fields.Str()
There are some interesting things going on in the above definitions. The PersonSchema class has one new entry:the notes attribute defined in line 5. This defines it as a nested relationship to the PersonNoteSchema . It will default to an empty list if nothing is present in the SQLAlchemy notes relationship. The many=True parameter indicates that this is a one-to-many relationship, so Marshmallow will serialize all the related notes .
The PersonNoteSchema class defines what a Note object looks like as Marshmallow serializes the notes liste. The NoteSchema defines what a SQLAlchemy Note object looks like in terms of Marshmallow. Notice that it has a person attribute. This attribute comes from the SQLAlchemy db.relationship(...) definition parameter backref='person' . The person Marshmallow definition is nested, but because it doesn’t have the many=True parameter, there is only a single person connected.
The NotePersonSchema class defines what is nested in the NoteSchema.person attribute.
Remarque :
You might be wondering why the PersonSchema class has its own unique PersonNoteSchema class to define the notes collection attribute. By the same token, the NoteSchema class has its own unique NotePersonSchema class to define the person attribute. You may be wondering whether the PersonSchema class could be defined this way:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
notes = fields.Nested('NoteSchema', default=[], many=True)
Additionally, couldn’t the NoteSchema class be defined using the PersonSchema to define the person attribute? A class definition like this would each refer to the other, and this causes a recursion error in Marshmallow as it will cycle from PersonSchema to NoteSchema until it runs out of stack space. Using the unique schema references breaks the recursion and allows this kind of nesting to work.
People
Now that you’ve got the schemas in place to work with the one-to-many relationship between Person and Note , you need to update the person.py and create the note.py modules in order to implement a working REST API.
The people.py module needs two changes. The first is to import the Note class, along with the Person class at the top of the module. Then only read_one(person_id) needs to change in order to handle the relationship. That function will look like this:
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: Id of person to find
7 :return: person matching id
8 """
9 # Build the initial query
10 person = (
11 Person.query.filter(Person.person_id == person_id)
12 .outerjoin(Note)
13 .one_or_none()
14 )
15
16 # Did we find a person?
17 if person is not None:
18
19 # Serialize the data for the response
20 person_schema = PersonSchema()
21 data = person_schema.dump(person).data
22 return data
23
24 # Otherwise, nope, didn't find that person
25 else:
26 abort(404, f"Person not found for Id: {person_id}")
The only difference is line 12:.outerjoin(Note) . An outer join (left outer join in SQL terms) is necessary for the case where a user of the application has created a new person object, which has no notes related to it. The outer join ensures that the SQL query will return a person object, even if there are no notes rows to join with.
At the start of this article, you saw how person and note data could be represented in a single, flat table, and all of the disadvantages of that approach. You also saw the advantages of breaking that data up into two tables, person and notes , with a relationship between them.
Until now, we’ve been working with the data as two distinct, but related, items in the database. But now that you’re actually going to use the data, what we essentially want is for the data to be joined back together. This is what a database join does. It combines data from two tables together using the primary key to foreign key relationship.
A join is kind of a boolean and operation because it only returns data if there is data in both tables to combine. If, for example, a person row exists but has no related notes row, then there is nothing to join, so nothing is returned. This isn’t what you want for read_one(person_id) .
This is where the outer join comes in handy. It’s a kind of boolean or opération. It returns person data even if there is no associated notes data to combine with. This is the behavior you want for read_one(person_id) to handle the case of a newly created Person object that has no notes yet.
You can see the complete people.py in the article repository.
Notes
You’ll create a notes.py module to implement all the Python code associated with the new note related REST API definitions. In many ways, it works like the people.py module, except it must handle both a person_id and a note_id as defined in the swagger.yml configuration file. As an example, here is read_one(person_id, note_id) :
1def read_one(person_id, note_id):
2 """
3 This function responds to a request for
4 /api/people/{person_id}/notes/{note_id}
5 with one matching note for the associated person
6
7 :param person_id: Id of person the note is related to
8 :param note_id: Id of the note
9 :return: json string of note contents
10 """
11 # Query the database for the note
12 note = (
13 Note.query.join(Person, Person.person_id == Note.person_id)
14 .filter(Person.person_id == person_id)
15 .filter(Note.note_id == note_id)
16 .one_or_none()
17 )
18
19 # Was a note found?
20 if note is not None:
21 note_schema = NoteSchema()
22 data = note_schema.dump(note).data
23 return data
24
25 # Otherwise, nope, didn't find that note
26 else:
27 abort(404, f"Note not found for Id: {note_id}")
The interesting parts of the above code are lines 12 to 17:
- Line 13 begins a query against the
NoteSQLAlchemy objects and joins to the relatedPersonSQLAlchemy object comparingperson_idfrom bothPersonandNote. - Line 14 filters the result down to the
Noteobjects that has aPerson.person_idequal to the passed inperson_idparameter. - Line 15 filters the result further to the
Noteobject that has aNote.note_idequal to the passed innote_idparameter. - Line 16 returns the
Noteobject if found, orNoneif nothing matching the parameters is found.
You can check out the complete notes.py .
Updated Swagger UI
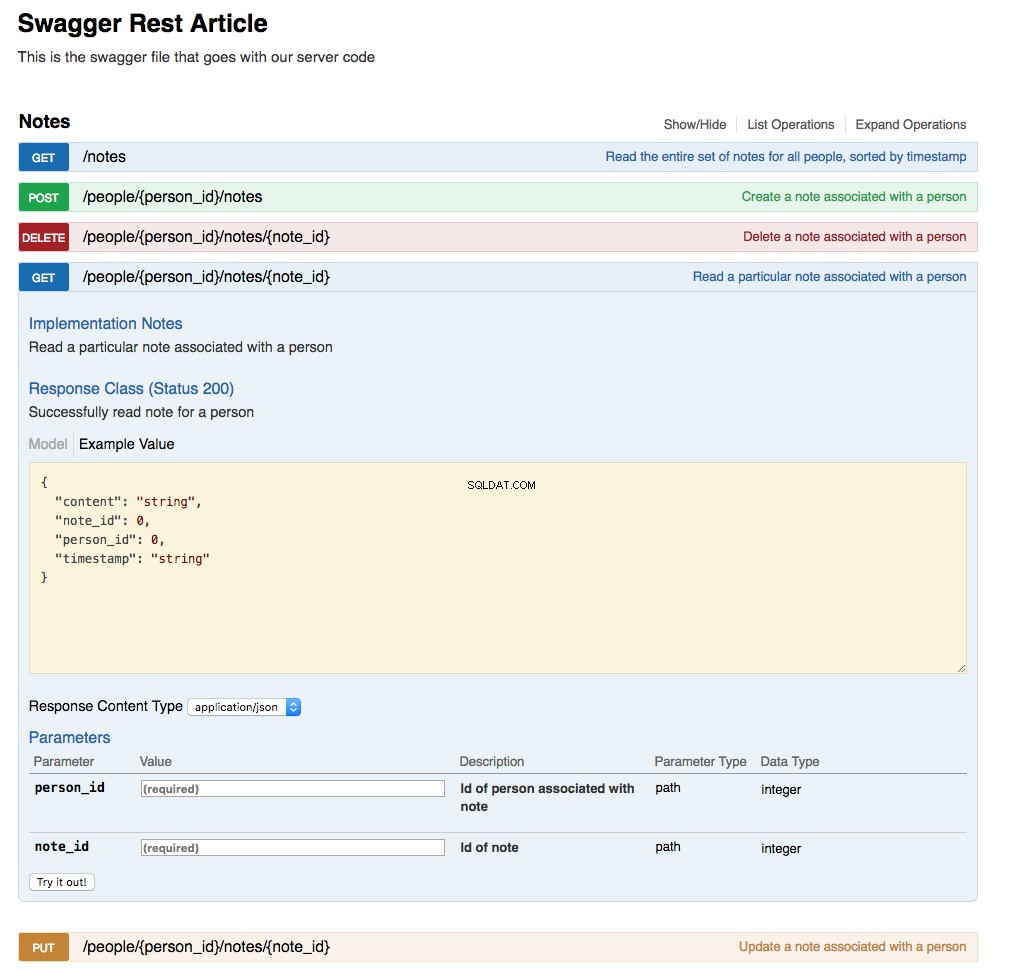
The Swagger UI has been updated by the action of updating the swagger.yml file and creating the URL endpoint implementations. Below is a screenshot of the updated UI showing the Notes section with the GET /api/people/{person_id}/notes/{note_id} expanded:
Mini-Blogging Web Application
The web application has been substantially changed to show its new purpose as a mini-blogging application. It has three pages:
-
The home page (
localhost:5000/) , which shows all of the blog messages (notes) sorted from newest to oldest -
The people page (
localhost:5000/people) , which shows all the people in the system, sorted by last name, and also allows the user to create a new person and update or delete an existing one -
The notes page (
localhost:5000/people/{person_id}/notes) , which shows all the notes associated with a person, sorted from newest to oldest, and also allows the user to create a new note and update or delete an existing one
Navigation
There are two buttons on every page of the application:
- The Home button will navigate to the home screen.
- The People button navigates to the
/peoplescreen, showing all people in the database.
These two buttons are present on every screen in the application as a way to get back to a starting point.
Home Page
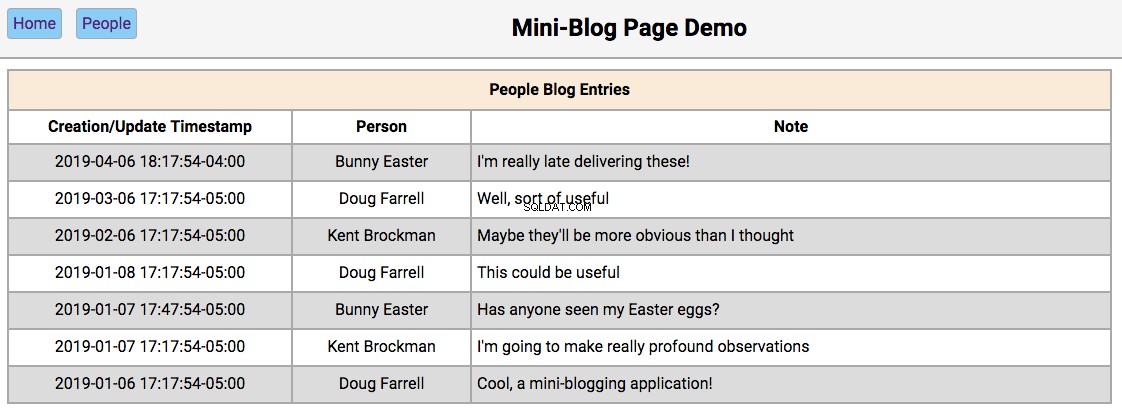
Below is a screenshot of the home page showing the initialized database contents:
The functionality of this page works like this:
-
Double-clicking on a person’s name will take the user to the
/people/{person_id}page, with the editor section filled in with the person’s first and last names and the update and reset buttons enabled. -
Double-clicking on a person’s note will take the user to the
/people/{person_id}/notes/{note_id}page, with the editor section filled in with the note’s contents and the Update and Reset buttons enabled.
People Page
Below is a screenshot of the people page showing the people in the initialized database:
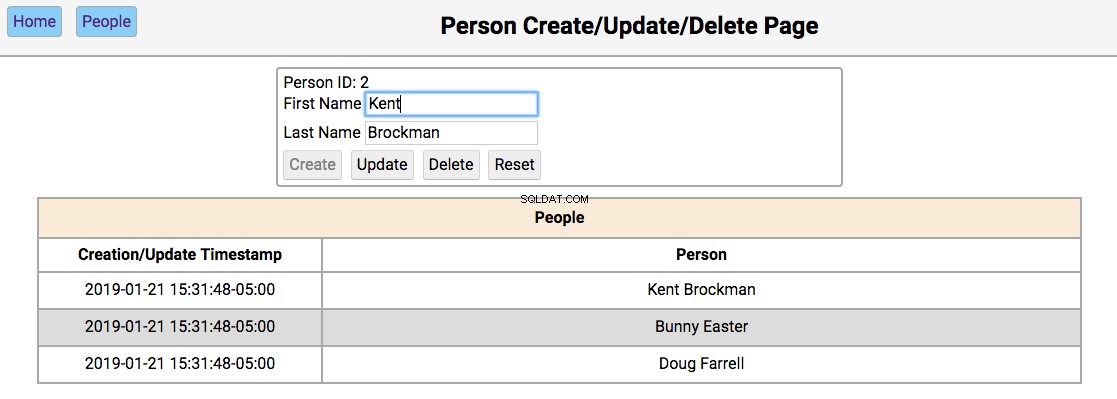
The functionality of this page works like this:
-
Single-clicking on a person’s name will populate the editor section of the page with the person’s first and last name, disabling the Create button, and enabling the Update and Delete buttons.
-
Double clicking on a person’s name will navigate to the notes pages for that person.
The functionality of the editor works like this:
-
If the first and last name fields are empty, the Create and Reset buttons are enabled. Entering a new name in the fields and clicking Create will create a new person and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the first and last name fields have data, the user navigated here by double-clicking the person’s name from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the first or last name and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the person from the database and re-render the table.
Notes Page
Below is a screenshot of the notes page showing the notes for a person in the initialized database:
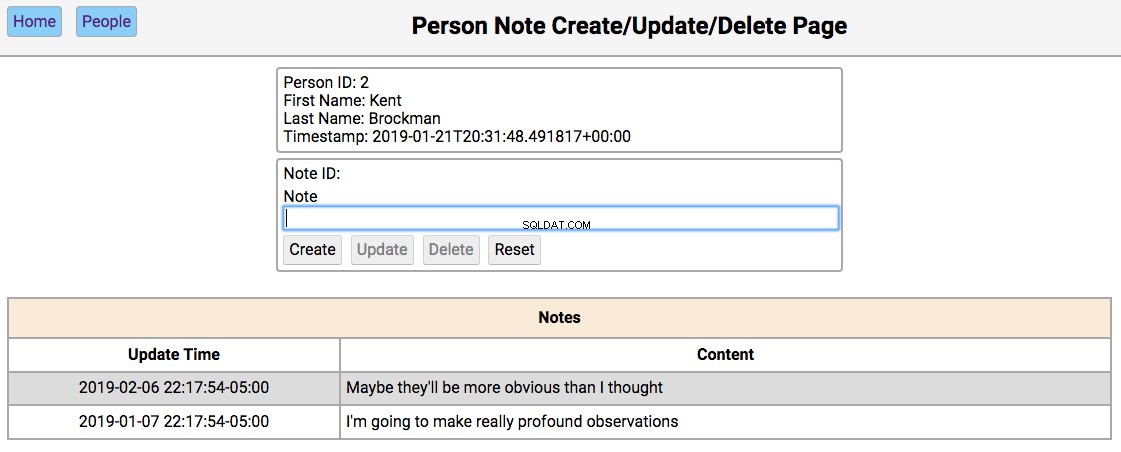
The functionality of this page works like this:
-
Single-clicking on a note will populate the editor section of the page with the notes content, disabling the Create button, and enabling the Update and Delete buttons.
-
All other functionality of this page is in the editor section.
The functionality of the editor works like this:
-
If the note content field is empty, then the Create and Reset buttons are enabled. Entering a new note in the field and clicking Create will create a new note and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the note field has data, the user navigated here by double-clicking the person’s note from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the note and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the note from the database and re-render the table.
Web Application
This article is primarily focused on how to use SQLAlchemy to create relationships in the database, and how to extend the REST API to take advantage of those relationships. As such, the code for the web application didn’t get much attention. When you look at the web application code, keep an eye out for the following features:
-
Each page of the application is a fully formed single page web application.
-
Each page of the application is driven by JavaScript following an MVC (Model/View/Controller) style of responsibility delegation.
-
The HTML that creates the pages takes advantage of the Jinja2 inheritance functionality.
-
The hardcoded JavaScript table creation has been replaced by using the Handlebars.js templating engine.
-
The timestamp formating in all of the tables is provided by Moment.js.
You can find the following code in the repository for this article:
- The HTML for the web application
- The CSS for the web application
- The JavaScript for the web application
All of the example code for this article is available in the GitHub repository for this article. This contains all of the code related to this article, including all of the web application code.
Conclusion
Congratulations are in order for what you’ve learned in this article! Knowing how to build and use database relationships gives you a powerful tool to solve many difficult problems. There are other relationship besides the one-to-many example from this article. Other common ones are one-to-one, many-to-many, and many-to-one. All of them have a place in your toolbelt, and SQLAlchemy can help you tackle them all!
For more information about databases, you can check out these tutorials. You can also set up Flask to use SQLAlchemy. You can check out Model-View-Controller (MVC) more information about the pattern used in the web application JavaScript code.
In Part 4 of this series, you’ll focus on the HTML, CSS, and JavaScript files used to create the web application.
« Part 2:Database PersistencePart 3:Database RelationshipsPart 4:Simple Web Applications »