[ Partie 1 | Partie 2 | Partie 3 ]
Dans l'esprit des récentes diatribes de Grant Fritchey et des efforts d'Erin Stellato depuis je pense avant notre rencontre, je veux prendre le train en marche pour claironner et promouvoir l'idée d'abandonner la trace en faveur des événements prolongés. Quand quelqu'un dit tracer , la plupart des gens pensent immédiatement Profiler . Alors que Profiler est son propre cauchemar, aujourd'hui, je voulais parler de la trace par défaut de SQL Server.
Dans notre environnement, il est activé sur les plus de 200 serveurs de production, et il collecte beaucoup de déchets que nous n'allons jamais étudier. Tellement de déchets, en fait, que des événements importants que nous pourrions trouver utiles pour le dépannage du déploiement des fichiers de trace avant que nous n'en ayons jamais l'occasion. J'ai donc commencé à envisager la possibilité de le désactiver, car :
- ce n'est pas gratuit (la surcharge de l'observateur de l'activité de trace elle-même, les E/S impliquées dans l'écriture dans les fichiers de trace et l'espace qu'ils consomment);
- sur la plupart des serveurs, il n'est jamais consulté; sur d'autres, rarement; et,
- c'est facile à réactiver pour un dépannage spécifique et isolé.
Quelques autres éléments affectent la valeur de la trace par défaut. Il n'est en aucun cas configurable - vous ne pouvez pas modifier les événements qu'il collecte, vous ne pouvez pas ajouter de filtres et vous ne pouvez pas contrôler le nombre de fichiers qu'il conserve (5), leur taille (20 Mo chacun) , ou où ils sont stockés (SERVERPROPERTY('ErrorLogFileName') ). Nous sommes donc complètement à la merci de la charge de travail - sur un serveur donné, nous ne pouvons pas prédire jusqu'où les données peuvent remonter (événements avec des TextData plus grands les valeurs, par exemple, peuvent occuper beaucoup plus d'espace et repousser les événements plus anciens plus rapidement). Parfois, cela peut remonter d'une semaine, d'autres fois, cela peut remonter à quelques minutes.
Analyse de l'état actuel
J'ai exécuté le code suivant sur 224 instances de production, juste pour comprendre quel type de bruit remplit la trace par défaut dans notre environnement. C'est probablement plus compliqué que nécessaire, et n'est même pas aussi complexe que la requête finale que j'ai utilisée, mais c'est un bon point de départ pour analyser la répartition des types d'événements de haut niveau qui sont actuellement capturés :
;WITH filesrc ([path]) AS
(
SELECT REVERSE(SUBSTRING(p, CHARINDEX(N'\', p), 260)) + N'log.trc'
FROM (SELECT REVERSE([path]) FROM sys.traces WHERE is_default = 1) s(p)
),
tracedata AS
(
SELECT Context = CASE
WHEN DDL = 1 THEN
CASE WHEN LEFT(ObjectName,8) = N'_WA_SYS_'
THEN 'AutoStat: ' + DBType
WHEN LEFT(ObjectName,2) IN (N'PK', N'UQ', N'IX') AND ObjectName LIKE N'%[_#]%'
THEN UPPER(LEFT(ObjectName,2)) + ': tempdb'
WHEN ObjectType = 17747 AND ObjectName LIKE N'TELEMETRY%'
THEN 'Telemetry'
ELSE 'Other DDL in ' + DBType END
WHEN EventClass = 116 THEN
CASE WHEN TextData LIKE N'%checkdb%' THEN 'DBCC CHECKDB'
-- several more of these ...
ELSE UPPER(CONVERT(nchar(32), TextData)) END
ELSE DBType END,
EventName = CASE WHEN DDL = 1 THEN 'DDL' ELSE EventName END,
EventSubClass,
EventClass,
StartTime
FROM
(
SELECT DDL = CASE WHEN t.EventClass IN (46,47,164) THEN 1 ELSE 0 END,
TextData = LOWER(CONVERT(nvarchar(512), t.TextData)),
EventName = e.[name],
t.EventClass,
t.EventSubClass,
ObjectName = UPPER(t.ObjectName),
t.ObjectType,
t.StartTime,
DBType = CASE WHEN t.DatabaseID = 2 OR t.ObjectName LIKE N'#%' THEN 'tempdb'
WHEN t.DatabaseID IN (1,3,4) THEN 'System database'
WHEN t.DatabaseID IS NOT NULL THEN 'User database' ELSE '?' END
FROM filesrc CROSS APPLY sys.fn_trace_gettable(filesrc.[path], DEFAULT) AS t
LEFT OUTER JOIN sys.trace_events AS e ON t.EventClass = e.trace_event_id
) AS src WHERE (EventSubClass IS NULL)
OR (EventSubClass = CASE WHEN DDL = 1 THEN 1 ELSE EventSubClass END) -- ddl_phase
)
SELECT [Instance] = @@SERVERNAME,
EventName,
Context,
EventCount = COUNT(*),
FirstSeen = MIN(StartTime),
LastSeen = MAX(StartTime)
INTO #t FROM tracedata
GROUP BY GROUPING SETS ((), (EventName, Context)); (Le prédicat EventSubClass est là pour empêcher le double comptage des événements DDL.Pour une carte des valeurs EventClass, je les ai répertoriées dans cette réponse sur Stack Exchange.)
Et les résultats ne sont pas jolis (résultats typiques d'un serveur aléatoire). Ce qui suit ne représente pas le résultat exact de cette requête, mais j'ai passé du temps à agréger les résultats dans un format plus digeste, pour voir quelle quantité de données était utile et quelle était la quantité de bruit (cliquez pour agrandir) :
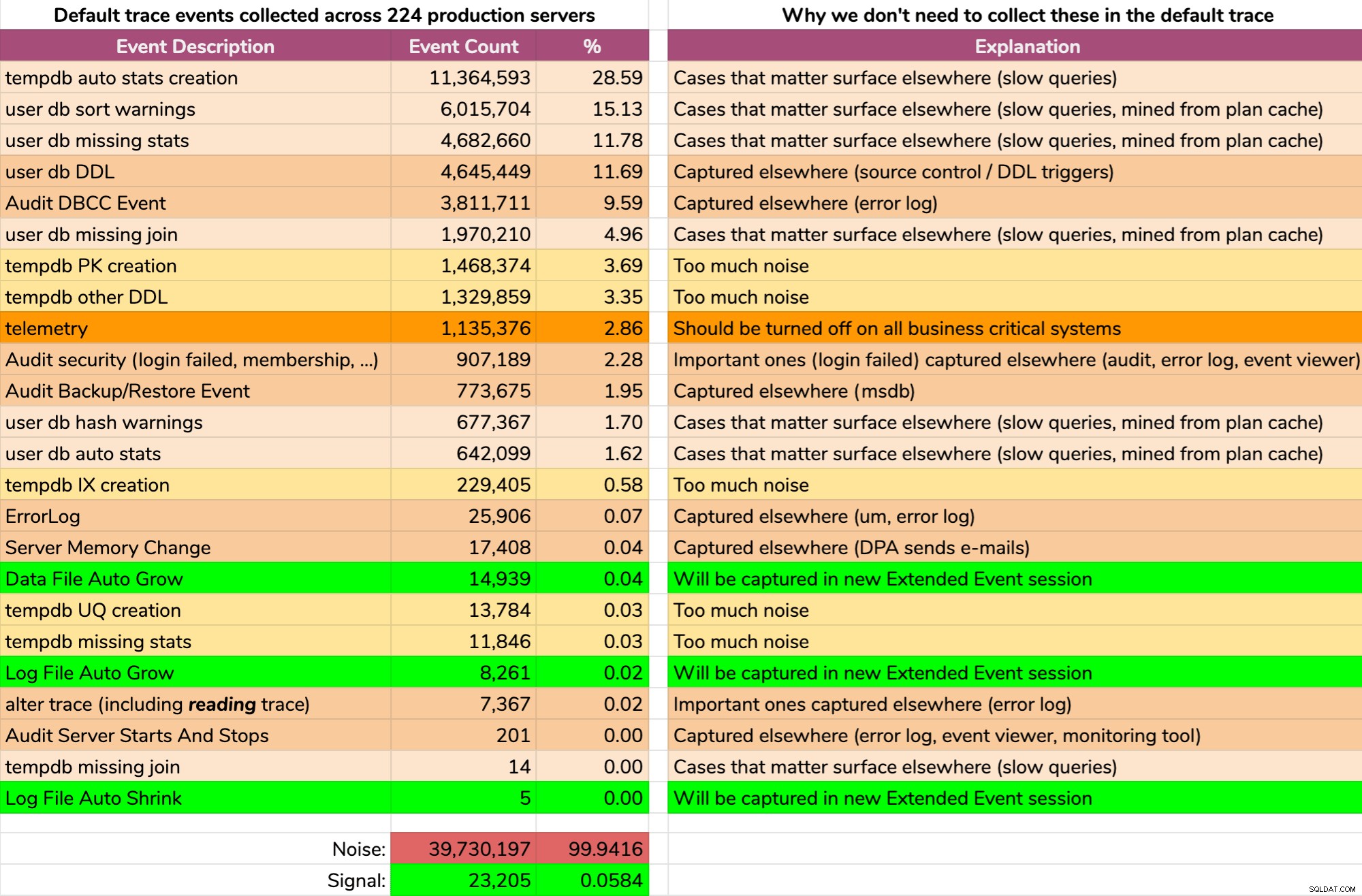
Presque tous les bruits (99,94 %). La seule chose utile dont nous ayons jamais eu besoin à partir de la trace par défaut était les événements de croissance et de réduction des fichiers, car c'était la seule chose que nous ne capturions pas ailleurs d'une manière ou d'une autre. Mais même cela, nous ne pouvons pas toujours nous y fier, car les données disparaissent très rapidement.
Une autre façon de découper les données :l'événement le plus ancien par instance. Certaines instances avaient tellement de bruit qu'elles ne pouvaient pas conserver les données de trace par défaut pendant plus de quelques minutes ! J'ai flouté les noms des serveurs mais ce sont des données réelles (ce sont les 20 serveurs avec l'historique le plus court - cliquez pour agrandir) :
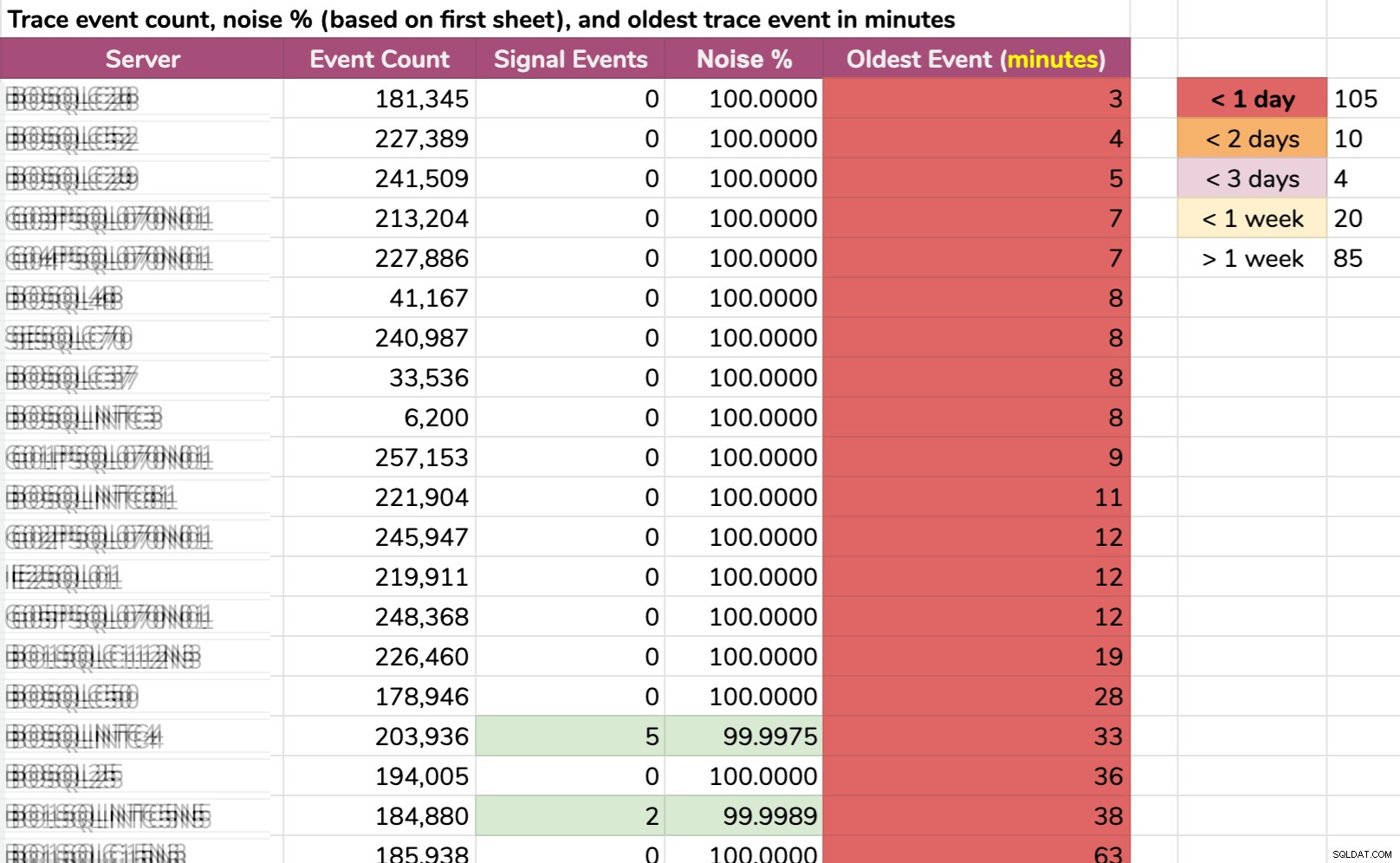
Même si la trace collectait seulement informations pertinentes et que quelque chose d'intéressant s'est produit, nous devions agir rapidement pour les attraper, selon le serveur. Si c'est arrivé :
- Il y a 20 minutes , alors il aurait déjà disparu sur 15 instances .
- cette fois hier , il disparaîtrait sur 105 instances .
- il y a deux jours , il disparaîtrait sur 115 instances .
- il y a plus d'une semaine , il disparaîtrait sur 139 instances .
Nous avions aussi une poignée de serveurs à l'autre bout, mais ils ne sont pas intéressants dans ce contexte; ces serveurs sont ainsi simplement parce que rien d'intéressant ne s'y passe (par exemple, ils ne sont pas occupés ou ne font pas partie d'une charge de travail critique).
Du côté positif…
L'examen de la trace par défaut a révélé des erreurs de configuration sur quelques-uns de nos serveurs :
- Plusieurs serveurs avaient encore la télémétrie activée . Je suis tout à fait d'aider Microsoft dans certains environnements, mais pas à n'importe quel frais généraux sur les systèmes critiques de l'entreprise.
- Certaines tâches de synchronisation en arrière-plan ajoutaient des membres à des rôles à l'aveuglette , encore et encore, sans vérifier s'ils occupaient déjà ces rôles. Ce n'est pas nocif en soi, d'autant plus que ces événements ne rempliront plus la trace par défaut, mais ils rempliront probablement également les audits de bruit, et il y a probablement d'autres opérations de réapplication aveugle qui se déroulent dans le même schéma.
- Quelqu'un avait activé la réduction automatique quelque part (bon sang !), c'était donc quelque chose que je voulais traquer et empêcher qu'il ne se reproduise (le nouveau XE capturera également ces événements).
Cela a conduit à des tâches de suivi pour résoudre ces problèmes et/ou ajouter des conditions à l'automatisation existante déjà en place. Ainsi, nous pouvons empêcher la récurrence sans compter sur le fait d'avoir la chance de les rencontrer lors d'un futur examen de trace par défaut, avant leur déploiement.
…mais le problème demeure
Sinon, tout est constitué d'informations sur lesquelles nous ne pouvons pas agir ou, comme décrit dans le graphique ci-dessus, d'événements que nous capturons déjà ailleurs. Et encore une fois, les seules données qui m'intéressent à partir de la trace par défaut que nous ne capturons pas déjà par d'autres moyens sont les événements liés à la croissance et à la réduction des fichiers (même si la trace par défaut ne capture que la variété automatique).
Mais le plus gros problème n'est pas vraiment le volume de bruit. Je peux gérer de gros fichiers de trace massifs avec beaucoup de déchets, puisque les clauses WHERE ont été inventées exactement dans ce but. Le vrai problème est que des événements importants disparaissaient trop rapidement.
La réponse
La réponse, du moins dans notre scénario, était simple :désactivez la trace par défaut, car elle ne vaut pas la peine d'être exécutée si elle n'est pas fiable.
Mais vu la quantité de bruit ci-dessus, par quoi devrait-il le remplacer ? Rien ?
Vous voudrez peut-être une session d'événements étendus qui capture tout la trace par défaut capturée. Si oui, Jonathan Kehayias vous a couvert. Cela vous donnerait les mêmes informations, mais avec un contrôle sur des éléments tels que la conservation, l'endroit où les données sont stockées et, à mesure que vous vous sentez plus à l'aise, la possibilité de supprimer progressivement certains des événements les plus bruyants ou les moins utiles.
Mon plan était un peu plus agressif, et est rapidement devenu un processus "simple" pour effectuer ce qui suit sur tous les serveurs de l'environnement (via CMS) :
- développez une session d'événements étendus qui ne capture que les événements de modification de fichier (à la fois manuels et automatiques)
- désactiver la trace par défaut
- créer une vue pour faciliter l'utilisation des données cibles par nos équipes
Notez que je ne vous suggère pas de désactiver aveuglément la trace par défaut , expliquant simplement pourquoi j'ai choisi de le faire dans notre environnement. Dans les prochains articles de cette série, je montrerai la nouvelle session d'événements étendus, la vue qui expose les données sous-jacentes, le code que j'ai utilisé pour déployer ces modifications sur tous les serveurs et les effets secondaires potentiels que vous devez garder à l'esprit.
[ Partie 1 | Partie 2 | Partie 3 ]



