Selon Wikipedia, "Une insertion en bloc est un processus ou une méthode fourni par un système de gestion de base de données pour charger plusieurs lignes de données dans une table de base de données." Si nous ajustons cette explication conformément à l'instruction BULK INSERT, l'insertion en bloc permet d'importer des fichiers de données externes dans SQL Server. Supposons que notre organisation dispose d'un fichier CSV de 1 500 000 lignes et que nous souhaitions importer ce fichier dans une table particulière de SQL Server, afin que nous puissions facilement utiliser l'instruction BULK INSERT dans SQL Server. Certes, nous pouvons trouver plusieurs méthodologies d'importation pour gérer ce processus d'importation de fichiers CSV, par ex. nous pouvons utiliser bcp (b ulk c copier p programme), Assistant d'importation et d'exportation SQL Server ou package SQL Server Integration Service. Cependant, l'instruction BULK INSERT est beaucoup plus rapide et robuste que l'utilisation d'autres méthodologies. Un autre avantage de l'instruction d'insertion en masse est qu'elle offre plusieurs paramètres qui aident à déterminer les paramètres du processus d'insertion en masse.
Dans un premier temps, nous commencerons par un exemple très basique, puis nous passerons en revue divers scénarios sophistiqués.
Préparation
Avant de commencer les exemples, nous avons besoin d'un exemple de fichier CSV. Par conséquent, nous allons télécharger un exemple de fichier CSV à partir du site Web E for Excel, où vous pouvez trouver divers exemples de fichiers CSV avec un numéro de ligne différent. Vous trouverez le lien à la fin de l'article. Dans nos scénarios, nous utiliserons 1 500 000 enregistrements de ventes. Téléchargez un fichier zip puis décompressez le fichier CSV et placez-le sur votre lecteur local.

Importer le fichier CSV dans la table SQL Server
Scénario-1 :le fichier de destination et le fichier CSV ont un nombre égal de colonnes
Dans ce premier scénario, nous allons importer le fichier CSV dans la table de destination sous la forme la plus simple. J'ai placé mon exemple de fichier CSV sur le lecteur C :et nous allons maintenant créer une table dans laquelle nous importerons les données du fichier CSV.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
L'instruction BULK INSERT suivante importe le fichier CSV dans la table Sales.
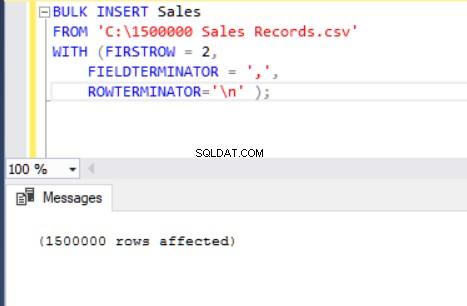
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
Nous allons maintenant expliquer les paramètres de l'instruction d'insertion en masse ci-dessus.
Le paramètre FIRSTROW spécifie le point de départ de l'instruction d'insertion. Dans l'exemple ci-dessous, nous voulons ignorer les en-têtes de colonne, nous définissons donc ce paramètre sur 2.

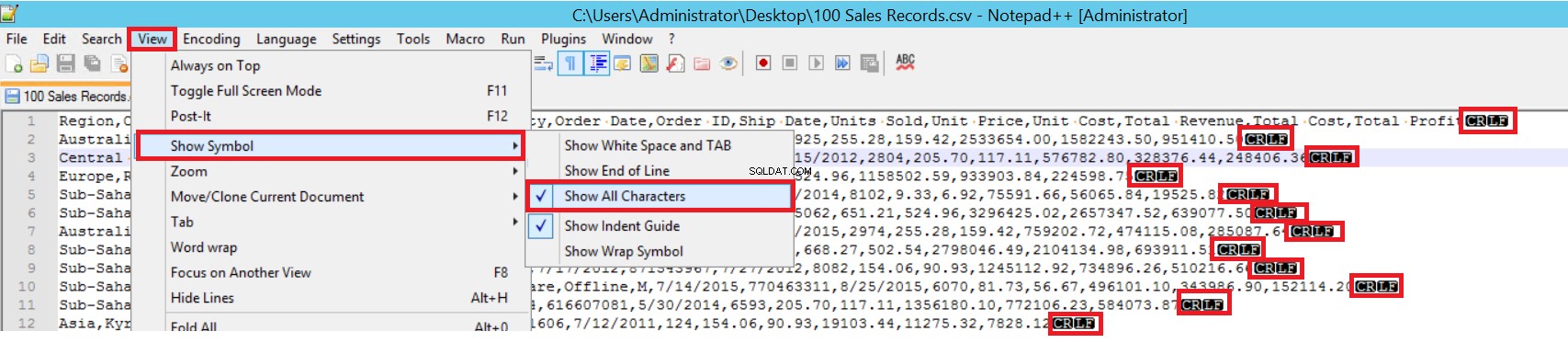
FIELDTERMINATOR définit le caractère qui sépare les champs les uns des autres. SQL Server détecte chaque champ de cette manière. ROWTERMINATOR ne diffère pas beaucoup de FIELDTERMINATOR. Il définit le caractère de séparation des lignes. Dans l'exemple de fichier CSV, fieldterminator est très clair et il s'agit d'une virgule (,). Mais comment détecter un fieldterminator ? Ouvrez le fichier CSV dans Notepad ++, puis accédez à Affichage-> Afficher le symbole-> Afficher toutes les chartes, puis recherchez les caractères CRLF à la fin de chaque champ.
CR =retour chariot et LF =saut de ligne. Ils sont utilisés pour marquer un saut de ligne dans un fichier texte et il est indiqué par le caractère "\n" dans l'instruction d'insertion en bloc.
Une autre méthode d'importation d'un fichier CSV dans une table à l'aide d'une insertion en bloc consiste à utiliser le paramètre FORMAT. Veuillez noter que le paramètre FORMAT est disponible uniquement dans SQL Server 2017 et les versions ultérieures.
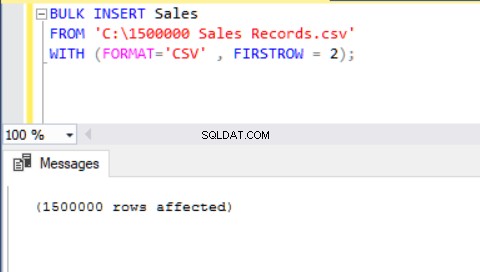
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Nous allons maintenant analyser un autre scénario.
Scénario-2 :La table de destination comporte plus de colonnes que le fichier CSV
Dans ce scénario, nous allons ajouter une clé primaire à la table Sales et ce cas rompt les mappages de colonnes d'égalité. Maintenant, nous allons créer la table Sales avec une clé primaire, essayer d'importer le fichier CSV via la commande d'insertion en bloc, puis nous obtiendrons une erreur.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
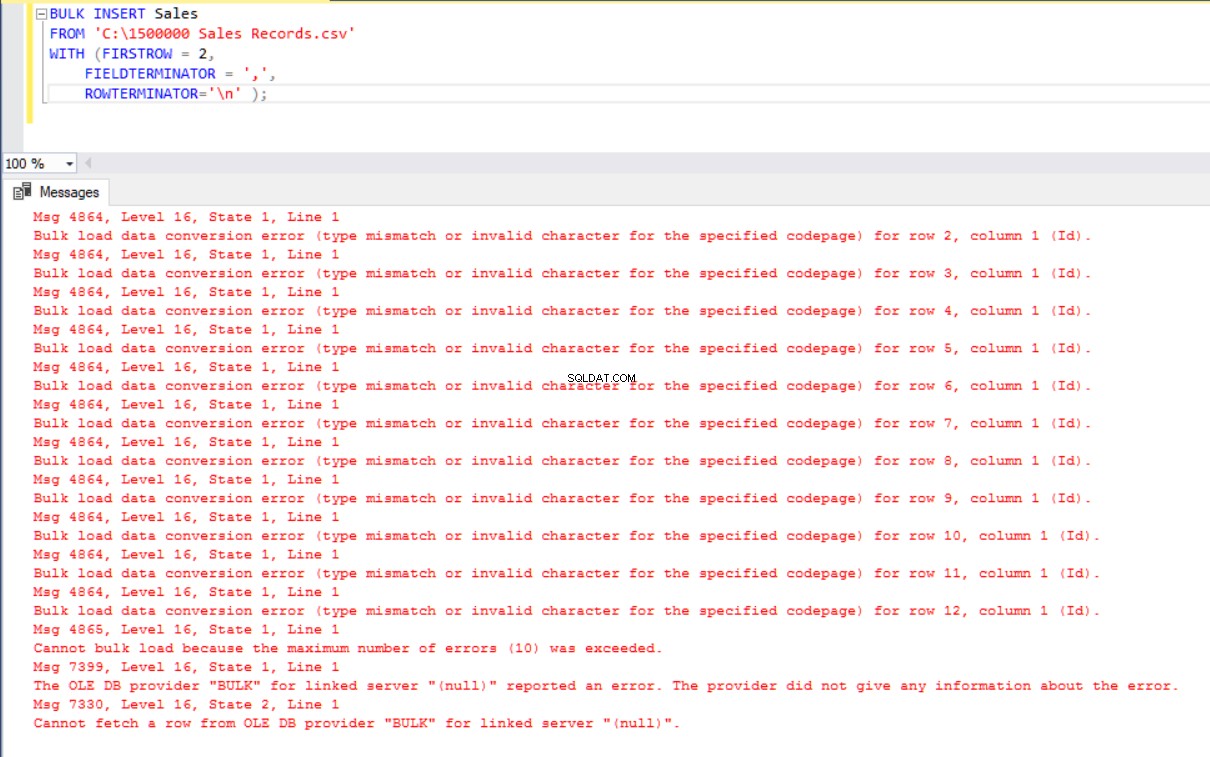
Afin de surmonter cette erreur, nous allons créer une vue de la table Sales avec des colonnes de mappage dans le fichier CSV et importer les données CSV via cette vue dans la table Sales.
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Scénario-3 :Comment séparer et charger un fichier CSV dans un petit lot ?
SQL Server acquiert un verrou sur la table de destination lors de l'opération d'insertion en bloc. Par défaut, si vous ne définissez pas le paramètre BATCHSIZE, SQL Server ouvre une transaction et insère l'intégralité des données CSV dans cette transaction. Toutefois, si vous définissez le paramètre BATCHSIZE, SQL Server divise les données CSV en fonction de cette valeur de paramètre. Dans l'exemple suivant, nous diviserons l'ensemble des données CSV en plusieurs ensembles de 300 000 lignes chacun. Ainsi les données seront importées 5 fois.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 );
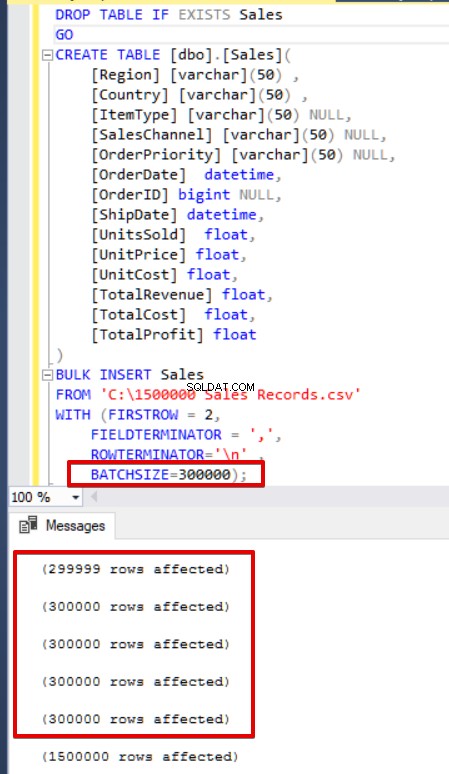
Si votre instruction d'insertion en bloc n'inclut pas le paramètre de taille de lot (BATCHSIZE), une erreur se produit et SQL Server annulera l'intégralité du processus d'insertion en bloc. D'autre part, si vous définissez le paramètre de taille de lot sur l'instruction d'insertion en bloc, SQL Server annulera uniquement cette partie divisée où l'erreur s'est produite. Il n'y a pas de valeur optimale ou optimale pour ce paramètre, car cette valeur de paramètre peut être modifiée en fonction des exigences de votre système de base de données.
Scénario-4 :Comment annuler le processus d'importation en cas d'erreur ?
Dans certains scénarios de copie en bloc, si une erreur se produit, nous pouvons soit annuler le processus de copie en bloc, soit poursuivre le processus. Le paramètre MAXERRORS nous permet de spécifier le nombre maximum d'erreurs. Si le processus d'insertion en bloc atteint cette valeur d'erreur maximale, l'opération d'importation en bloc sera annulée et restaurée. La valeur par défaut de ce paramètre est 10.
Dans l'exemple suivant, nous allons intentionnellement corrompre le type de données dans 3 lignes du fichier CSV et définir le paramètre MAXERRORS sur 2. Par conséquent, toute l'opération d'insertion en masse sera annulée car le numéro d'erreur dépasse le paramètre d'erreur max.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2);
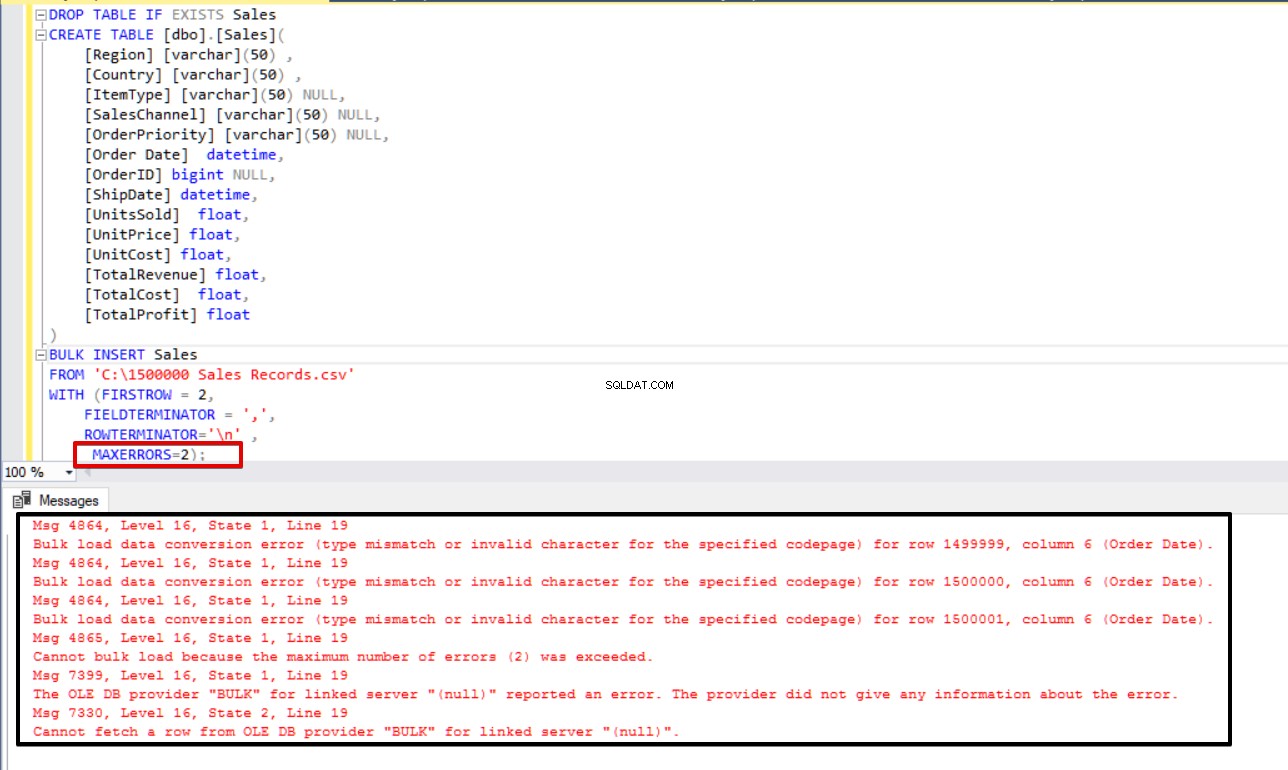
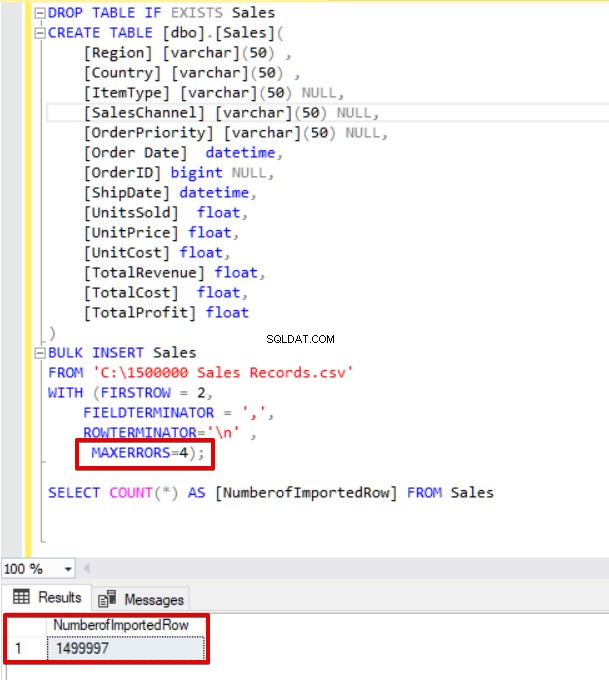
Nous allons maintenant changer le paramètre d'erreur max à 4. Par conséquent, l'instruction d'insertion en bloc ignorera ces lignes et insérera les lignes structurées de données appropriées, et terminera le processus d'insertion en bloc.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
De plus, si nous utilisons à la fois la taille du lot et les paramètres d'erreur maximale, le processus de copie en bloc n'annulera pas toute l'opération d'insertion, il n'annulera que la partie divisée.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
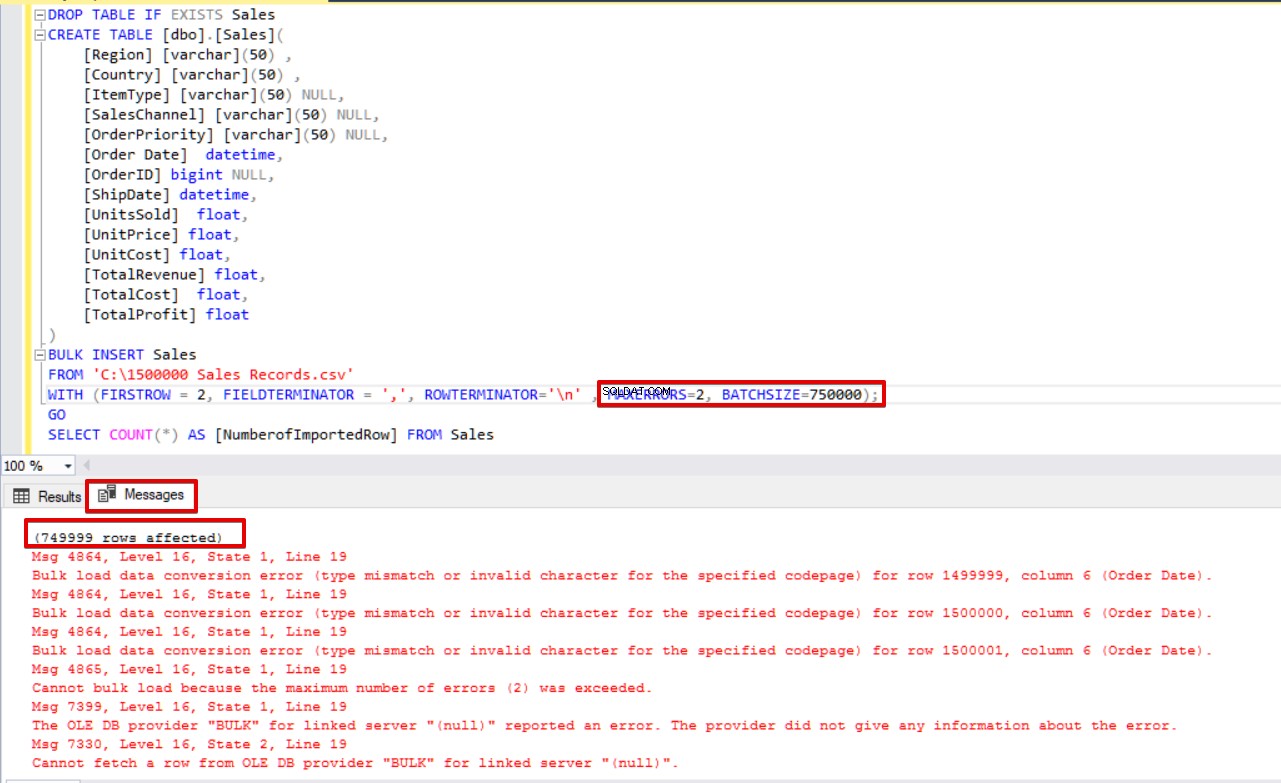
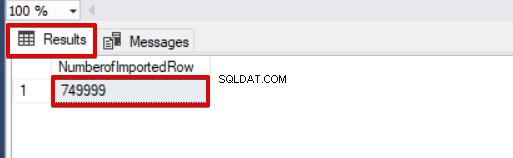
Dans cette première partie de cette série d'articles, nous avons abordé les bases de l'utilisation de l'opération d'insertion en bloc dans SQL Server et analysé plusieurs scénarios proches des problèmes réels.
Insertion groupée SQL Server – Partie 2
Liens utiles :
Insertion en masse
E pour Excel - Exemples de fichiers CSV / ensembles de données pour les tests (jusqu'à 1,5 million d'enregistrements)
Télécharger le Bloc-notes++
Outil utile :
dbForge Data Pump - un complément SSMS pour remplir les bases de données SQL avec des données sources externes et migrer les données entre les systèmes.