Contexte
L'une des premières choses que je regarde lorsque je résous un problème de performances est les statistiques d'attente via le DMV sys.dm_os_wait_stats. Pour voir ce que SQL Server attend, j'utilise la requête de l'ensemble actuel de requêtes de diagnostic SQL Server de Glenn Berry. En fonction de la sortie, je commence à creuser dans des domaines spécifiques au sein de SQL Server.
Par exemple, si je vois des attentes CXPACKET élevées, je vérifie le nombre de cœurs sur le serveur, le nombre de nœuds NUMA et les valeurs du degré maximal de parallélisme et du seuil de coût pour le parallélisme. Ce sont des informations de base que j'utilise pour comprendre la configuration. Avant même d'envisager d'apporter des modifications, j'en rassemble plus données quantitatives, car un système avec CXPACKET attend n'a pas nécessairement un réglage incorrect pour le degré maximum de parallélisme.
De même, un système qui a des attentes élevées pour les types d'attente liés aux E/S tels que PAGEIOLATCH_XX, WRITELOG et IO_COMPLETION n'a pas nécessairement un sous-système de stockage inférieur. Lorsque je vois les types d'attente liés aux E/S comme les attentes les plus fréquentes, je souhaite immédiatement en savoir plus sur le stockage sous-jacent. S'agit-il d'un stockage en attachement direct ou d'un SAN ? Quel est le niveau RAID, combien de disques existent dans la matrice et quelle est la vitesse des disques ? Je veux également savoir si d'autres fichiers ou bases de données partagent le stockage. Et bien qu'il soit important de comprendre la configuration, une prochaine étape logique consiste à examiner les statistiques des fichiers virtuels via le DMV sys.dm_io_virtual_file_stats.
Introduit dans SQL Server 2005, ce DMV remplace la fonction fn_virtualfilestats que ceux d'entre vous qui ont exécuté sur SQL Server 2000 et les versions antérieures connaissent et aiment probablement. Le DMV contient des informations d'E/S cumulatives pour chaque fichier de base de données, mais les données sont réinitialisées au redémarrage de l'instance, lorsqu'une base de données est fermée, mise hors ligne, détachée et rattachée, etc. performances - il s'agit d'un instantané qui est une agrégation de données d'E/S depuis le dernier effacement par l'un des événements susmentionnés. Même si les données ne sont pas ponctuelles, elles peuvent toujours être utiles. Si les temps d'attente les plus élevés pour une instance sont liés aux E/S, mais que le temps d'attente moyen est inférieur à 10 ms, le stockage n'est probablement pas un problème, mais la corrélation de la sortie avec ce que vous voyez dans sys.dm_io_virtual_stats vaut toujours la peine de confirmer latences. De plus, même si vous constatez des latences élevées dans sys.dm_io_virtual_stats, vous n'avez toujours pas prouvé que le stockage est un problème.
La configuration
Pour consulter les statistiques des fichiers virtuels, j'ai configuré deux copies de la base de données AdventureWorks2012, que vous pouvez télécharger à partir de Codeplex. Pour la première copie, ci-après connue sous le nom d'EX_AdventureWorks2012, j'ai exécuté le script de Jonathan Kehayias pour étendre les tables Sales.SalesOrderHeader et Sales.SalesOrderDetail à 1,2 million et 4,9 millions de lignes, respectivement. Pour la deuxième base de données, BIG_AdventureWorks2012, j'ai utilisé le script de mon article de partitionnement précédent pour créer une copie de la table Sales.SalesOrderHeader avec 123 millions de lignes. Les deux bases de données ont été stockées sur un lecteur USB externe (Seagate Slim 500 Go), avec tempdb sur mon disque local (SSD).
Avant de tester, j'ai créé quatre procédures stockées personnalisées dans chaque base de données (Create_Custom_SPs.zip), qui serviraient de charge de travail "normale". Mon processus de test était le suivant pour chaque base de données :
- Redémarrez l'instance.
- Capturez les statistiques des fichiers virtuels.
- Exécutez la charge de travail "normale" pendant deux minutes (procédures appelées à plusieurs reprises via un script PowerShell).
- Capturez les statistiques des fichiers virtuels.
- Reconstruire tous les index pour la ou les tables SalesOrder appropriées.
- Capturez les statistiques des fichiers virtuels.
Les données
Pour capturer les statistiques des fichiers virtuels, j'ai créé une table pour conserver les informations historiques, puis j'ai utilisé une variante de la requête de Jimmy May à partir de son script DMV All-Stars pour l'instantané :
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; J'ai redémarré l'instance, puis j'ai immédiatement capturé les statistiques du fichier. Lorsque j'ai filtré la sortie pour afficher uniquement les fichiers de base de données EX_AdventureWorks2012 et tempdb, seules les données tempdb ont été capturées car aucune donnée n'avait été demandée à partir de la base de données EX_AdventureWorks2012 :

Sortie de la capture initiale de sys.dm_os_virtual_file_stats
J'ai ensuite exécuté la charge de travail "normale" pendant deux minutes (le nombre d'exécutions de chaque procédure stockée variait légèrement), et après avoir terminé les statistiques de fichier capturées à nouveau :

Sortie de sys.dm_os_virtual_file_stats après une charge de travail normale
Nous constatons une latence de 57 ms pour le fichier de données EX_AdventureWorks2012. Pas idéal, mais au fil du temps avec ma charge de travail normale, cela s'égaliserait probablement. Il y a une latence minimale pour tempdb, ce qui est attendu car la charge de travail que j'ai exécutée ne génère pas beaucoup d'activité tempdb. Ensuite, j'ai reconstruit tous les index des tables Sales.SalesOrderHeaderEnlarged et Sales.SalesOrderDetailEnlarged :
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
Les reconstructions ont pris moins d'une minute et notez le pic de latence de lecture pour le fichier de données EX_AdventureWorks2012, et les pics de latence d'écriture pour les données EX_AdventureWorks2012 et fichiers journaux :

Sortie de sys.dm_os_virtual_file_stats après la reconstruction de l'index
Selon cet instantané des statistiques de fichiers, la latence est horrible; plus de 600 ms pour les écritures ! Si je voyais cette valeur pour un système de production, il serait facile de suspecter immédiatement des problèmes de stockage. Cependant, il convient également de noter que AvgBPerWrite a également augmenté et que les écritures de blocs plus volumineux prennent plus de temps à se terminer. L'augmentation AvgBPerWrite est attendue pour la tâche de reconstruction d'index.
Comprenez qu'en examinant ces données, vous n'obtenez pas une image complète. Une meilleure façon d'examiner les latences à l'aide des statistiques de fichiers virtuels consiste à prendre des instantanés, puis à calculer la latence pour la période écoulée. Par exemple, le script ci-dessous utilise deux instantanés (actuel et précédent), puis calcule le nombre de lectures et d'écritures au cours de cette période, la différence entre les valeurs io_stall_read_ms et io_stall_write_ms, puis divise le delta io_stall_read_ms par le nombre de lectures et le delta io_stall_write_ms par nombre d'écritures. Avec cette méthode, nous calculons le temps pendant lequel SQL Server a attendu les E/S pour les lectures ou les écritures, puis nous le divisons par le nombre de lectures ou d'écritures pour déterminer la latence.
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
Lorsque nous exécutons ceci pour calculer la latence lors de la reconstruction de l'index, nous obtenons ce qui suit :

Latence calculée à partir de sys.dm_io_virtual_file_stats lors de la reconstruction de l'index pour EX_AdventureWorks2012
Nous pouvons maintenant voir que la latence réelle pendant cette période était élevée – ce à quoi nous nous attendions. Et si nous revenions ensuite à notre charge de travail normale et l'exécutions pendant quelques heures, les valeurs moyennes calculées à partir des statistiques de fichiers virtuels diminueraient avec le temps. En fait, si nous examinons les données PerfMon qui ont été capturées pendant le test (puis traitées via PAL), nous constatons des pics significatifs dans Avg. Disque sec/Lecture et Moy. Disk sec/Write qui correspond à l'heure à laquelle la reconstruction de l'index était en cours d'exécution. Mais à d'autres moments, les valeurs de latence sont bien inférieures aux valeurs acceptables :
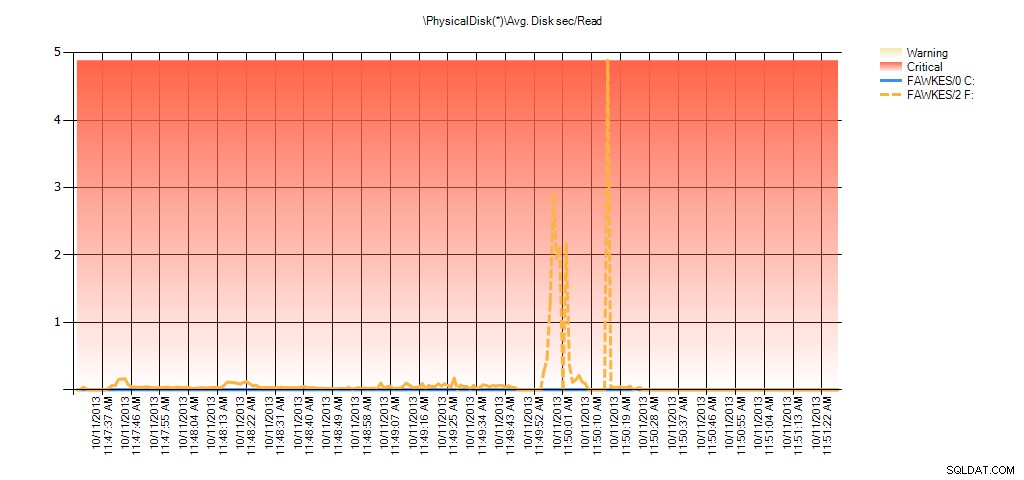
Résumé de Avg Disk Sec/Read from PAL for EX_AdventureWorks2012 pendant les tests
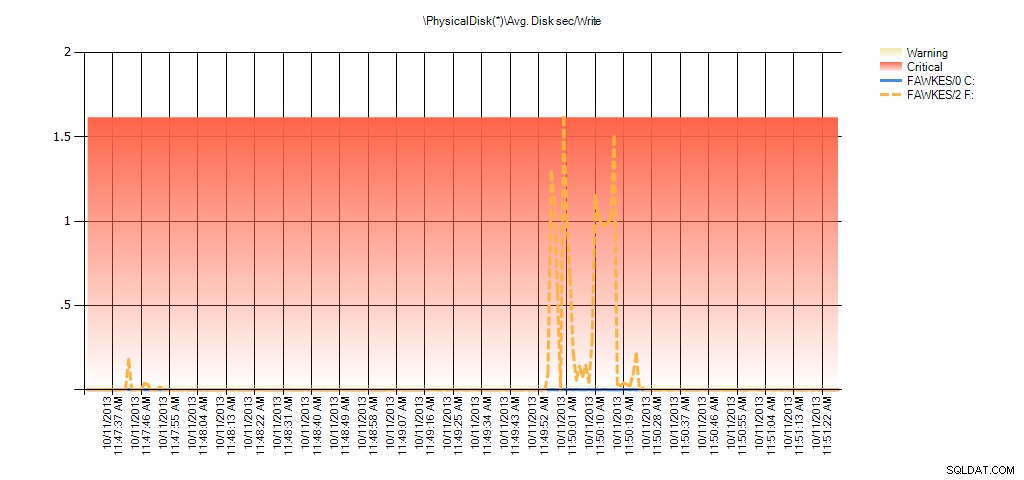
Résumé de Avg Disk Sec/Write from PAL for EX_AdventureWorks2012 pendant les tests
Vous pouvez voir le même comportement pour la base de données BIG_AdventureWorks 2012. Voici les informations de latence basées sur l'instantané des statistiques du fichier virtuel avant la reconstruction de l'index et après :

Latence calculée à partir de sys.dm_io_virtual_file_stats lors de la reconstruction de l'index pour BIG_AdventureWorks2012
Et les données de l'Analyseur de performances montrent les mêmes pics lors de la reconstruction :
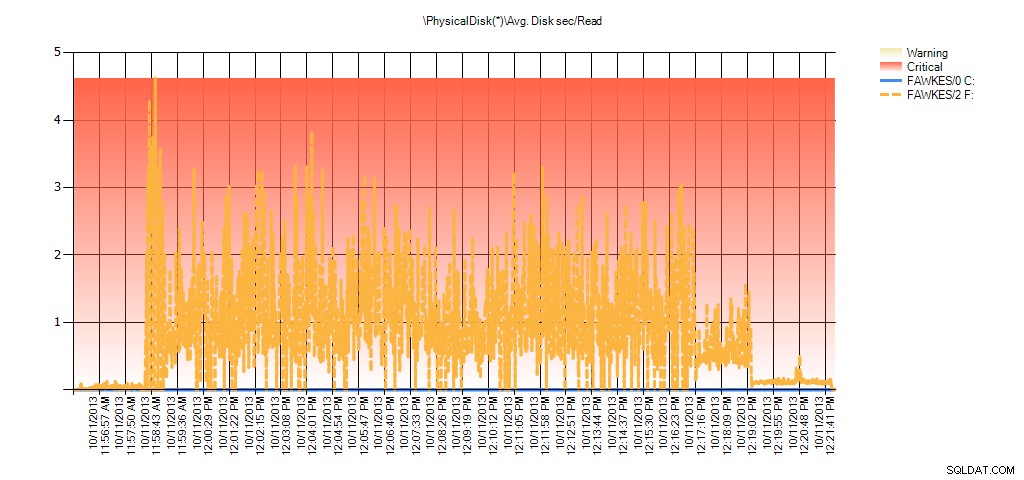
Résumé de Avg Disk Sec/Read from PAL pour BIG_AdventureWorks2012 lors des tests
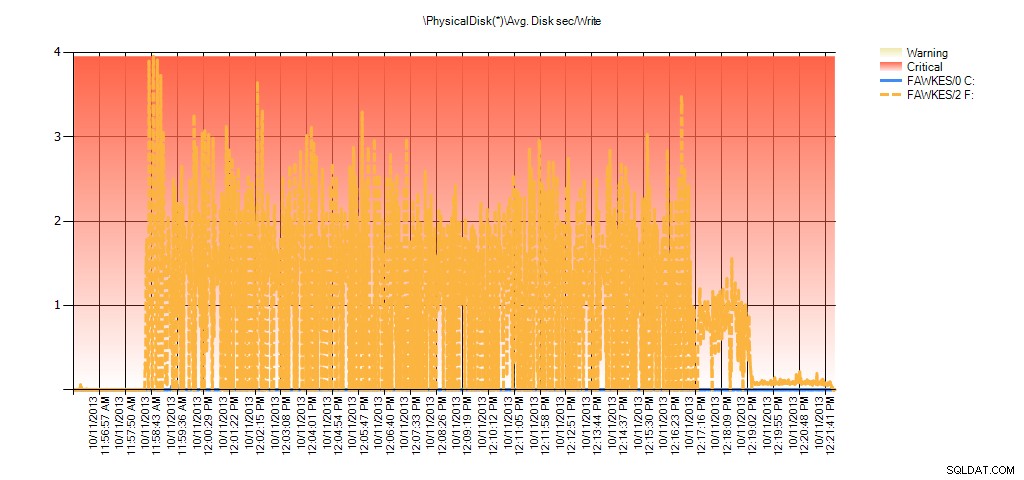
Résumé de Avg Disk Sec/Write from PAL pour BIG_AdventureWorks2012 lors des tests
Conclusion
Les statistiques de fichiers virtuels constituent un excellent point de départ lorsque vous souhaitez comprendre les performances d'E/S d'une instance SQL Server. Si vous voyez des attentes liées aux E/S lorsque vous consultez les statistiques d'attente, la prochaine étape logique consiste à consulter sys.dm_io_virtual_file_stats. Cependant, comprenez que les données que vous consultez sont un agrégat depuis le dernier effacement des statistiques par l'un des événements associés (redémarrage de l'instance, mise hors ligne de la base de données, etc.). Si vous constatez de faibles latences, le sous-système d'E/S suit la charge de performances. Cependant, si vous constatez des latences élevées, il n'est pas certain que le stockage est un problème. Pour vraiment savoir ce qui se passe, vous pouvez commencer à capturer les statistiques des fichiers, comme indiqué ici, ou vous pouvez simplement utiliser l'Analyseur de performances pour examiner la latence en temps réel. Il est très facile de créer un ensemble de collecteurs de données dans PerfMon qui capture les compteurs de disque physique Moy. Disque Sec/Lecture et Moy. Disk Sec/Read pour tous les disques qui hébergent des fichiers de base de données. Programmez le collecteur de données pour qu'il démarre et s'arrête régulièrement, et échantillonnez tous les n secondes (par exemple 15), et une fois que vous avez capturé les données PerfMon pendant une durée appropriée, exécutez-les via PAL pour examiner la latence dans le temps.
Si vous constatez que la latence des E/S se produit pendant votre charge de travail normale, et pas seulement pendant les tâches de maintenance qui pilotent les E/S, vous toujours ne peut pas indiquer que le stockage est le problème sous-jacent. La latence de stockage peut exister pour diverses raisons, telles que :
- SQL Server doit lire trop de données en raison de plans de requête inefficaces ou d'index manquants
- Trop peu de mémoire est allouée à l'instance et les mêmes données sont lues à plusieurs reprises sur le disque car elles ne peuvent pas rester en mémoire
- Les conversions implicites entraînent des analyses d'index ou de table
- Les requêtes exécutent SELECT * lorsque toutes les colonnes ne sont pas requises
- Les problèmes d'enregistrement transférés dans les tas entraînent des E/S supplémentaires
- Les faibles densités de pages dues à la fragmentation de l'index, aux fractionnements de pages ou à des paramètres de facteur de remplissage incorrects entraînent des E/S supplémentaires
Quelle que soit la cause première, ce qu'il est essentiel de comprendre à propos des performances, en particulier en ce qui concerne les E/S, c'est qu'il existe rarement un seul point de données que vous pouvez utiliser pour identifier le problème. Trouver le vrai problème nécessite plusieurs faits qui, une fois reconstitués, vous aident à découvrir le problème.
Enfin, notez que dans certains cas la latence de stockage peut être tout à fait acceptable. Avant d'exiger un stockage plus rapide ou des modifications du code, passez en revue les modèles de charge de travail et le contrat de niveau de service (SLA) pour la base de données. Dans le cas d'un entrepôt de données qui fournit des rapports aux utilisateurs, le SLA pour les requêtes n'est probablement pas les mêmes valeurs inférieures à la seconde que vous attendez d'un système OLTP à volume élevé. Dans la solution DW, des latences d'E/S supérieures à une seconde peuvent être parfaitement acceptables et attendues. Comprenez les attentes de l'entreprise et de ses utilisateurs, puis déterminez les mesures à prendre, le cas échéant. Et si des modifications sont nécessaires, rassemblez les données quantitatives dont vous avez besoin pour étayer votre argumentation, à savoir les statistiques d'attente, les statistiques de fichiers virtuels et les latences de l'Analyseur de performances.