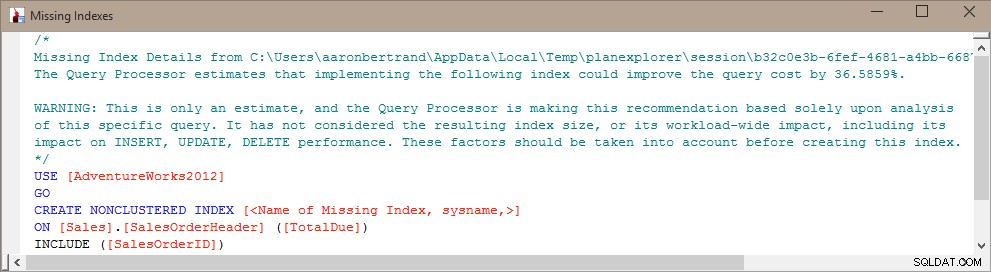
Kevin Kline (@kekline) et moi avons récemment organisé un webinaire sur le réglage des requêtes (enfin, un dans une série, en fait), et l'une des choses qui est apparue est la tendance des gens à créer tout index manquant que SQL Server leur dit sera une bonne chose™ . Ils peuvent en savoir plus sur ces index manquants à partir du Database Engine Tuning Advisor (DTA), des DMV d'index manquants ou d'un plan d'exécution affiché dans Management Studio ou Plan Explorer (qui ne font que relayer les informations depuis exactement le même endroit) :
Le problème avec la création aveugle de cet index est que SQL Server a décidé qu'il est utile pour une requête particulière (ou quelques requêtes), mais ignore complètement et unilatéralement le reste de la charge de travail. Comme nous le savons tous, les index ne sont pas "gratuits" - vous payez pour les index à la fois dans le stockage brut ainsi que pour la maintenance requise sur les opérations DML. Cela n'a guère de sens, dans une charge de travail lourde en écriture, d'ajouter un index qui aide à rendre une seule requête légèrement plus efficace, surtout si cette requête n'est pas exécutée fréquemment. Il peut être très important dans ces cas de comprendre votre charge de travail globale et de trouver un bon équilibre entre rendre vos requêtes efficaces et ne pas payer trop cher pour cela en termes de maintenance de l'index.
Donc, une idée que j'ai eue était de "mélanger" les informations des DMV d'index manquants, les statistiques d'utilisation de l'index DMV et des informations sur les plans de requête, pour déterminer quel type d'équilibre existe actuellement et comment l'ajout de l'index pourrait se dérouler globalement.
Index manquants
Tout d'abord, nous pouvons examiner les index manquants suggérés actuellement par SQL Server :
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
Cela montre la ou les tables et colonnes qui auraient été utiles dans un index, combien de compilations/recherches/analyses auraient été utilisées et quand le dernier événement de ce type s'est produit pour chaque index potentiel. Vous pouvez également inclure des colonnes comme s.avg_total_user_cost et s.avg_user_impact si vous souhaitez utiliser ces chiffres pour établir des priorités.
Planifier les opérations
Examinons ensuite les opérations utilisées dans tous les plans que nous avons mis en cache par rapport aux objets qui ont été identifiés par nos index manquants.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; Un ami sur dba.SE, Mikael Eriksson, a suggéré les deux requêtes suivantes qui, sur un système plus grand, fonctionneront bien mieux que la requête XML / UNION que j'ai bricolée ci-dessus, vous pouvez donc les expérimenter en premier. Son commentaire final était qu'il "a découvert sans surprise que moins de XML est une bonne chose pour les performances. :)" En effet.
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
Maintenant dans le #planops table, vous avez un tas de valeurs pour plan_handle afin que vous puissiez aller enquêter sur chacun des plans individuels en jeu contre les objets qui ont été identifiés comme manquant d'indice utile. Nous n'allons pas l'utiliser pour cela pour le moment, mais vous pouvez facilement le croiser avec :
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Vous pouvez maintenant cliquer sur l'un des plans de sortie pour voir ce qu'ils font actuellement sur vos objets. Notez que certains des plans seront répétés, car un plan peut avoir plusieurs opérateurs qui référencent différents index sur la même table.
Statistiques d'utilisation de l'index
Ensuite, examinons les statistiques d'utilisation de l'index, afin que nous puissions voir la quantité d'activité réelle en cours sur nos tables candidates (et, en particulier, les mises à jour).
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
Ne vous inquiétez pas si très peu ou pas de plans dans le cache affichent des mises à jour pour un index particulier, même si les statistiques d'utilisation de l'index montrent que ces index ont été mis à jour. Cela signifie simplement que les plans de mise à jour ne sont pas actuellement en cache, ce qui peut être dû à diverses raisons - par exemple, il peut s'agir d'une charge de travail très lourde en lecture et ils ont été dépassés, ou ils sont tous célibataires. utiliser et optimize for ad hoc workloads est activé.
Tout mettre ensemble
La requête suivante vous montrera, pour chaque index manquant suggéré, le nombre de lectures qu'un index aurait pu assister, le nombre d'écritures et de lectures qui ont actuellement été capturées par rapport aux index existants, le rapport de ceux-ci, le nombre de plans associés à cet objet, et le nombre total d'utilisations compte pour ces plans :
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
Si votre rapport écriture:lecture à ces index est déjà> 1 (ou> 10!), Je pense que cela donne une raison de faire une pause avant de créer aveuglément un index qui ne pourrait qu'augmenter ce rapport. Le nombre de potential_read_ops montré, cependant, peut compenser cela à mesure que le nombre devient plus grand. Si le potential_read_ops nombre est très petit, vous voudrez probablement ignorer complètement la recommandation avant même de prendre la peine d'étudier les autres métriques - vous pouvez donc ajouter un WHERE clause pour filtrer certaines de ces recommandations.
Quelques remarques :
- Il s'agit d'opérations de lecture et d'écriture, et non de lectures et d'écritures mesurées individuellement sur des pages de 8 Ko.
- Le ratio et les comparaisons sont largement pédagogiques ; il se pourrait très bien que 10 000 000 d'opérations d'écriture affectent toutes une seule ligne, tandis que 10 opérations de lecture auraient pu avoir beaucoup plus d'impact. Il s'agit simplement d'une indication approximative et suppose que les opérations de lecture et d'écriture ont à peu près la même pondération.
- Vous pouvez également utiliser de légères variations sur certaines de ces requêtes pour savoir - en dehors des index manquants recommandés par SQL Server - combien de vos index actuels sont inutiles. Il y a beaucoup d'idées à ce sujet en ligne, y compris ce post de Paul Randal (@PaulRandal).
J'espère que cela donne quelques idées pour mieux comprendre le comportement de votre système avant de décider d'ajouter un index qu'un outil vous a demandé de créer. J'aurais pu créer cela comme une requête massive, mais je pense que les parties individuelles vous donneront des terriers de lapin à enquêter, si vous le souhaitez.
Autres remarques
Vous pouvez également étendre cela pour capturer les métriques de taille actuelles, la largeur de la table et le nombre de lignes actuelles (ainsi que toutes les prédictions sur la croissance future) ; cela peut vous donner une bonne idée de l'espace occupé par un nouvel index, ce qui peut être un problème en fonction de votre environnement. Je traiterai peut-être cela dans un prochain article.
Bien sûr, vous devez garder à l'esprit que ces mesures ne sont utiles que si votre temps de disponibilité l'exige. Les DMV sont effacées après un redémarrage (et parfois dans d'autres scénarios moins perturbateurs), donc si vous pensez que ces informations seront utiles sur une plus longue période, vous pouvez envisager de prendre des instantanés périodiques.