Auteur invité :Monica Rathbun (@SQLEspresso)
Parfois, les problèmes de performances matérielles, comme la latence des E/S de disque, se résument à une charge de travail non optimisée plutôt qu'à un matériel sous-performant. De nombreux administrateurs de base de données, moi y compris, veulent immédiatement blâmer le stockage pour la lenteur. Avant d'aller dépenser une tonne d'argent sur du nouveau matériel, vous devriez toujours examiner votre charge de travail pour les E/S inutiles.
Éléments à examiner
| Élément | Impact E/S | Solutions possibles |
|---|---|---|
| Index inutilisés | Écritures supplémentaires | Supprimer / Désactiver l'index |
| Index manquants | Lectures supplémentaires | Ajouter un index / Index de couverture |
| Conversions implicites | Lectures et écritures supplémentaires | Covert ou Cast Field à la source avant d'évaluer la valeur |
| Fonctions | Lectures et écritures supplémentaires | Supprimez-les, convertissez les données avant l'évaluation |
| ETL | Lectures et écritures supplémentaires | Utiliser SSIS, la réplication, la capture de données modifiées, les groupes de disponibilité |
| Trier et regrouper par | Lectures et écritures supplémentaires | Supprimez-les si possible |
Index inutilisés
Nous connaissons tous la puissance d'un index. Avoir les index appropriés peut faire des années-lumière de différence dans la vitesse des requêtes. Cependant, combien d'entre nous maintenons continuellement nos index au-delà des reconstructions d'index et des réorganisations ? Il est important d'exécuter régulièrement un script d'index pour évaluer quels index sont réellement utilisés. J'utilise personnellement les requêtes de diagnostic de Glenn Berry pour ce faire.
Vous serez surpris de constater que certains de vos index n'ont pas du tout été lus. Ces index sollicitent les ressources, en particulier sur une table hautement transactionnelle. Lorsque vous examinez les résultats, faites attention aux index qui ont un nombre élevé d'écritures combiné à un faible nombre de lectures. Dans cet exemple, vous pouvez voir que je gaspille des écritures. L'index non clusterisé a été écrit 11 millions de fois, mais seulement lu deux fois.

Je commence par désactiver les index qui entrent dans cette catégorie, puis je les supprime après avoir confirmé qu'aucun problème n'est survenu. Faire cet exercice régulièrement peut réduire considérablement les écritures d'E/S inutiles sur votre système, mais gardez à l'esprit que les statistiques d'utilisation sur vos index ne sont aussi bonnes que le dernier redémarrage, alors assurez-vous d'avoir collecté des données pendant un cycle d'activité complet avant d'annuler un index comme "inutile".
Index manquants
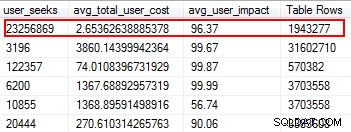
Les index manquants sont l'une des choses les plus faciles à corriger; après tout, lorsque vous exécutez un plan d'exécution, il vous indiquera si des index n'ont pas été trouvés, mais cela aurait été utile. Mais attendez, j'espère que vous n'êtes pas en train d'ajouter arbitrairement des index basés sur cette suggestion. Cela peut créer des index en double et des index qui peuvent avoir une utilisation minimale et donc gaspiller des E/S. Encore une fois, pour en revenir aux scripts de Glenn, il nous donne un excellent outil pour évaluer l'utilité d'un index en fournissant les recherches d'utilisateurs, l'impact de l'utilisateur et le nombre de lignes. Faites attention à ceux qui ont des lectures élevées avec un faible coût et un faible impact. C'est un excellent point de départ et cela vous aidera à réduire les E/S de lecture.
Conversions implicites
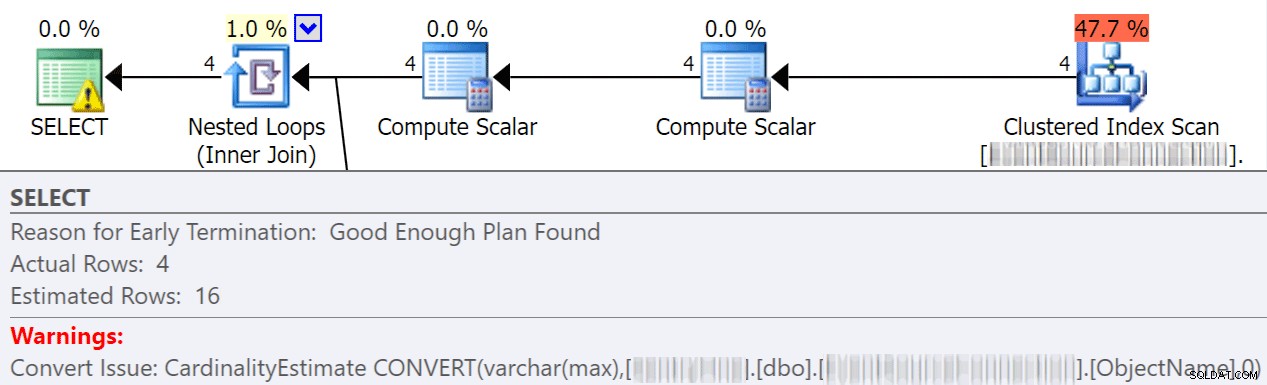
Les conversions implicites se produisent souvent lorsqu'une requête compare deux colonnes ou plus avec des types de données différents. Dans l'exemple ci-dessous, le système doit effectuer des E/S supplémentaires afin de comparer une colonne varchar(max) à une colonne nvarchar(4000), ce qui conduit à une conversion implicite et finalement à une analyse au lieu d'une recherche. En corrigeant les tables pour qu'elles aient des types de données correspondants, ou en convertissant simplement cette valeur avant l'évaluation, vous pouvez réduire considérablement les E/S et améliorer la cardinalité (les lignes estimées auxquelles l'optimiseur doit s'attendre).
dbo.table1 t1 JOIN dbo.table2 t2 ON t1.ObjectName = t2.TableName
Jonathan Kehayias donne beaucoup plus de détails dans cet excellent article :" Combien coûtent les conversions implicites côté colonne ?"
Fonctions
L'une des choses les plus évitables et les plus faciles à résoudre que j'ai rencontrées et qui permet d'économiser sur les dépenses d'E/S consiste à supprimer des fonctions des clauses where. Un exemple parfait est une comparaison de dates, comme indiqué ci-dessous.
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField)) AND (CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))
Que ce soit sur une instruction JOIN ou dans une clause WHERE, cela entraîne la conversion de chaque colonne avant son évaluation. En convertissant simplement ces colonnes avant l'évaluation en une table temporaire, vous pouvez éliminer une tonne d'E/S inutiles.
Ou, mieux encore, n'effectuez aucune conversion (pour ce cas précis, Aaron Bertrand parle ici d'éviter les fonctions dans la clause where, et notez que cela peut toujours être mauvais même si convert to date est sargable).
ETL
Prenez le temps d'examiner comment vos données sont chargées. Est-ce que vous tronquez et rechargez des tables ? Pouvez-vous implémenter la réplication, un réplica AG en lecture seule ou l'envoi de journaux à la place ? Toutes les tables écrites sont-elles réellement lues ? Comment chargez-vous les données ? Est-ce via des procédures stockées ou SSIS ? Examiner des choses comme celle-ci peut réduire considérablement les E/S.
Dans mon environnement, j'ai constaté que nous tronquions 48 tables par jour avec plus de 120 millions de lignes chaque matin. En plus de cela, nous chargeions 9,6 millions de lignes par heure. Vous pouvez imaginer combien d'E/S inutiles cela a créé. Dans mon cas, la mise en œuvre de la réplication transactionnelle était ma solution de choix. Une fois mis en œuvre, nous avons eu beaucoup moins de plaintes d'utilisateurs concernant des ralentissements pendant nos temps de chargement, qui avaient initialement été attribués à la lenteur du stockage.
Trier par et regrouper par
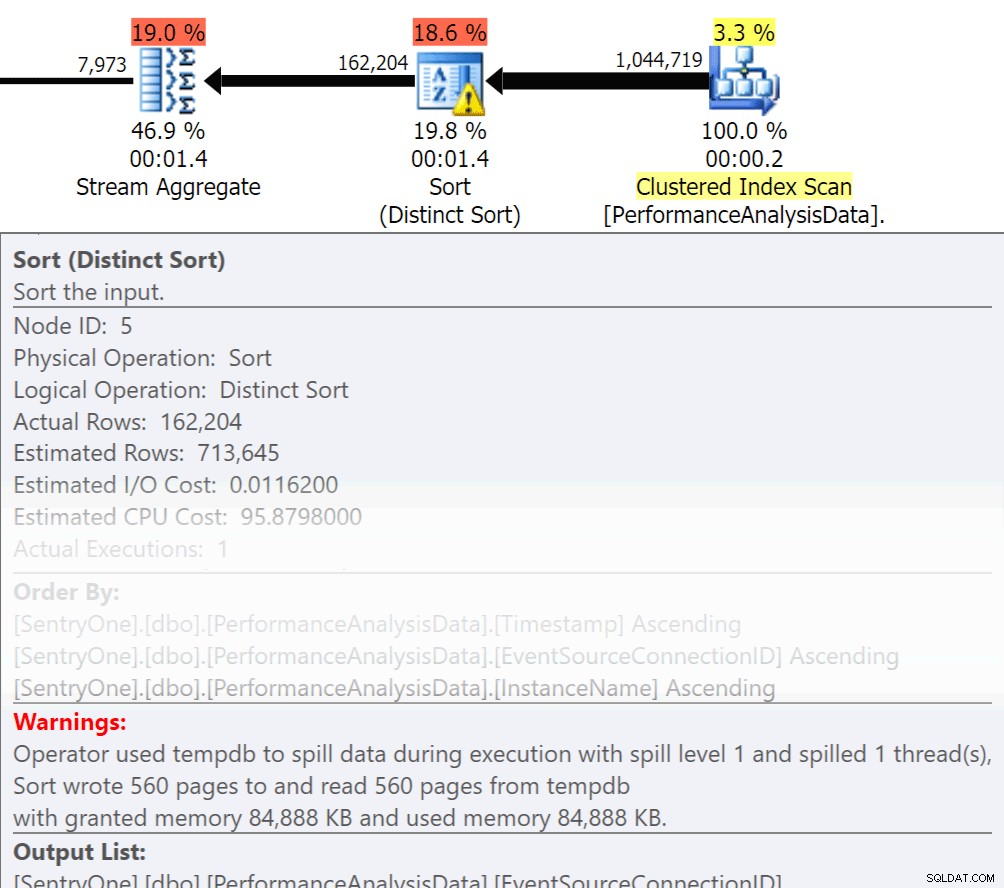 Demandez-vous si ces données doivent être renvoyées dans l'ordre ? Avons-nous vraiment besoin de regrouper dans la procédure, ou pouvons-nous gérer cela dans un rapport ou une application ? Les opérations Trier par et Grouper par peuvent entraîner le débordement des lectures sur le disque, ce qui entraîne des E/S disque supplémentaires. Si ces actions sont justifiées, assurez-vous que vous disposez d'index de prise en charge et de statistiques actualisées sur les colonnes triées ou regroupées. Cela aidera l'optimiseur lors de la création du plan. Puisque nous utilisons parfois Order By et Group By dans les tables temporaires. assurez-vous que la création automatique de statistiques est activée pour TEMPDB ainsi que pour vos bases de données utilisateur. Plus les statistiques sont à jour, meilleure est la cardinalité que l'optimiseur peut obtenir, ce qui se traduit par de meilleurs plans, moins de débordements et moins d'E/S.
Demandez-vous si ces données doivent être renvoyées dans l'ordre ? Avons-nous vraiment besoin de regrouper dans la procédure, ou pouvons-nous gérer cela dans un rapport ou une application ? Les opérations Trier par et Grouper par peuvent entraîner le débordement des lectures sur le disque, ce qui entraîne des E/S disque supplémentaires. Si ces actions sont justifiées, assurez-vous que vous disposez d'index de prise en charge et de statistiques actualisées sur les colonnes triées ou regroupées. Cela aidera l'optimiseur lors de la création du plan. Puisque nous utilisons parfois Order By et Group By dans les tables temporaires. assurez-vous que la création automatique de statistiques est activée pour TEMPDB ainsi que pour vos bases de données utilisateur. Plus les statistiques sont à jour, meilleure est la cardinalité que l'optimiseur peut obtenir, ce qui se traduit par de meilleurs plans, moins de débordements et moins d'E/S.
Désormais, Group By a définitivement sa place lorsqu'il s'agit d'agréger des données au lieu de renvoyer une tonne de lignes. Mais la clé ici est de réduire les E/S, l'ajout de l'agrégation ajoute aux E/S.
Résumé
Ce ne sont que la pointe de l'iceberg, mais c'est un excellent point de départ pour réduire les E/S. Avant de blâmer le matériel pour vos problèmes de latence, examinez ce que vous pouvez faire pour minimiser la pression sur le disque.
À propos de l'auteur
 Monica Rathbun est actuellement consultante chez Denny Cherry &Associates Consulting et MVP de Microsoft Data Platform. Elle a été DBA solitaire pendant 15 ans, travaillant avec tous les aspects de SQL Server et Oracle. Elle voyage en parlant à SQLSaturdays pour aider d'autres DBA Lone avec des techniques sur la façon dont on peut faire le travail de plusieurs. Monica est le leader du groupe d'utilisateurs SQL Server de Hampton Roads et est un mentor régional du Mid-Atlantic Pass. Vous pouvez toujours trouver Monica sur Twitter (@SQLEspresso) distribuant des conseils et astuces utiles à ses abonnés. Lorsqu'elle n'est pas occupée par le travail, vous la trouverez en train de jouer au chauffeur de taxi pour ses deux filles, allant et venant aux cours de danse.
Monica Rathbun est actuellement consultante chez Denny Cherry &Associates Consulting et MVP de Microsoft Data Platform. Elle a été DBA solitaire pendant 15 ans, travaillant avec tous les aspects de SQL Server et Oracle. Elle voyage en parlant à SQLSaturdays pour aider d'autres DBA Lone avec des techniques sur la façon dont on peut faire le travail de plusieurs. Monica est le leader du groupe d'utilisateurs SQL Server de Hampton Roads et est un mentor régional du Mid-Atlantic Pass. Vous pouvez toujours trouver Monica sur Twitter (@SQLEspresso) distribuant des conseils et astuces utiles à ses abonnés. Lorsqu'elle n'est pas occupée par le travail, vous la trouverez en train de jouer au chauffeur de taxi pour ses deux filles, allant et venant aux cours de danse. 


