Dans mon blog précédent, nous avons discuté de différentes manières de sélectionner ou d'analyser des données à partir d'une seule table. Mais en pratique, récupérer des données à partir d'une seule table ne suffit pas. Cela nécessite de sélectionner des données dans plusieurs tables, puis de les corréler. La corrélation de ces données entre les tables est appelée jointure de tables et peut être effectuée de différentes manières. Comme la jonction de tables nécessite des données d'entrée (par exemple à partir du parcours de table), il ne peut jamais s'agir d'un nœud feuille dans le plan généré.
Ex. considérez un exemple de requête simple comme SELECT * FROM TBL1, TBL2 où TBL1.ID> TBL2.ID ; et supposons que le plan généré est le suivant :
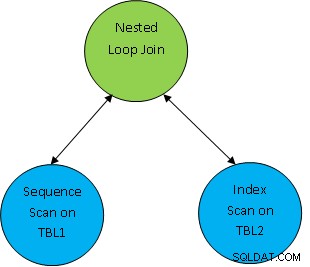
Ainsi, ici, les deux premières tables sont analysées, puis elles sont réunies en tant que selon la condition de corrélation comme TBL.ID> TBL2.ID
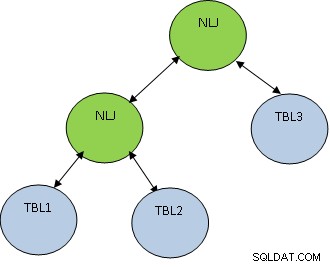
En plus de la méthode de jointure, l'ordre de jointure est également très important. Prenons l'exemple ci-dessous :
SELECT * FROM TBL1, TBL2, TBL3 WHERE TBL1.ID=TBL2.ID AND TBL2.ID=TBL3.ID ;
Considérez que TBL1, TBL2 ET TBL3 ont respectivement 10, 100 et 1000 enregistrements.
La condition TBL1.ID=TBL2.ID ne renvoie que 5 enregistrements, alors que TBL2.ID=TBL3.ID renvoie 100 enregistrements, il est donc préférable de joindre TBL1 et TBL2 en premier afin qu'un nombre moindre d'enregistrements obtienne rejoint avec TBL3. Le plan sera comme indiqué ci-dessous :
PostgreSQL prend en charge les types de jointures ci-dessous :
- Joindre en boucle imbriquée
- Hash Join
- Fusionner la jointure
Chacune de ces méthodes Join est également utile en fonction de la requête et d'autres paramètres, par ex. requête, données de table, clause de jointure, sélectivité, mémoire, etc. Ces méthodes de jointure sont implémentées par la plupart des bases de données relationnelles.
Créons un tableau de pré-configuration et remplissons-le avec des données, qui seront fréquemment utilisées pour mieux expliquer ces méthodes d'analyse.
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZEDans tous nos exemples suivants, nous considérons le paramètre de configuration par défaut, sauf indication contraire spécifique.
Jointure de boucle imbriquée
Nested Loop Join (NLJ) est l'algorithme de jointure le plus simple dans lequel chaque enregistrement de relation externe est mis en correspondance avec chaque enregistrement de relation interne. La jointure entre la relation A et B avec la condition A.ID Nested Loop Join (NLJ) est la méthode de jointure la plus courante et peut être utilisée sur presque tous les ensembles de données avec n'importe quel type de clause de jointure. Étant donné que cet algorithme analyse tous les tuples de relation interne et externe, il est considéré comme l'opération de jointure la plus coûteuse. Conformément au tableau et aux données ci-dessus, la requête suivante entraînera une jointure de boucle imbriquée comme indiqué ci-dessous : Étant donné que la clause de jointure est "<", la seule méthode de jointure possible ici est Nested Loop Join. Remarquez ici un nouveau type de nœud tel que Materialise ; ce nœud agit comme un cache de résultat intermédiaire, c'est-à-dire qu'au lieu de récupérer tous les tuples d'une relation plusieurs fois, le résultat récupéré pour la première fois est stocké en mémoire et lors de la prochaine requête pour obtenir le tuple sera servi à partir de la mémoire au lieu de récupérer à nouveau les pages de relation . Dans le cas où tous les tuples ne peuvent pas tenir en mémoire, les tuples de débordement vont dans un fichier temporaire. Il est surtout utile en cas de Nested Loop Join et dans une certaine mesure en cas de Merge Join car ils reposent sur une nouvelle analyse de la relation interne. Materialise Node n'est pas seulement limité à la mise en cache du résultat de la relation, mais il peut mettre en cache les résultats de n'importe quel nœud ci-dessous dans l'arborescence du plan. CONSEIL :dans le cas où la clause de jointure est "=" et que la jointure de boucle imbriquée est choisie entre une relation, il est vraiment important de rechercher si une méthode de jointure plus efficace telle que la jointure par hachage ou par fusion peut être choisie par configuration de réglage (par exemple work_mem mais sans s'y limiter) ou en ajoutant un index, etc. Certaines des requêtes peuvent ne pas avoir de clause de jointure, dans ce cas également, le seul choix de jointure est Nested Loop Join. Par exemple. considérez les requêtes ci-dessous selon les données de pré-configuration : La jointure dans l'exemple ci-dessus est juste un produit cartésien des deux tables. Cet algorithme fonctionne en deux phases : La jointure entre la relation A et B avec la condition A.ID =B.ID peut être représentée comme ci-dessous : Conformément au tableau et aux données de pré-configuration ci-dessus, la requête suivante entraînera une jointure par hachage comme indiqué ci-dessous : Ici, la table de hachage est créée sur la table blogtable2 car il s'agit de la plus petite table, de sorte que la mémoire minimale requise pour la table de hachage et la table de hachage entière peut tenir en mémoire. Merge Join est un algorithme dans lequel chaque enregistrement de relation externe est mis en correspondance avec chaque enregistrement de relation interne jusqu'à ce qu'il y ait une possibilité de correspondance de clause de jointure. Cet algorithme de jointure n'est utilisé que si les deux relations sont triées et que l'opérateur de clause de jointure est "=". La jointure entre la relation A et B avec la condition A.ID =B.ID peut être représentée comme ci-dessous : L'exemple de requête qui a abouti à une jointure par hachage, comme indiqué ci-dessus, peut entraîner une jointure par fusion si l'index est créé sur les deux tables. En effet, les données de la table peuvent être récupérées dans un ordre trié grâce à l'index, qui est l'un des principaux critères de la méthode Merge Join : Ainsi, comme nous le voyons, les deux tables utilisent un balayage d'index au lieu d'un balayage séquentiel à cause duquel les deux tables émettront des enregistrements triés. PostgreSQL prend en charge diverses configurations liées au planificateur, qui peuvent être utilisées pour suggérer à l'optimiseur de requête de ne pas sélectionner un type particulier de méthodes de jointure. Si la méthode de jointure choisie par l'optimiseur n'est pas optimale, ces paramètres de configuration peuvent être désactivés pour forcer l'optimiseur de requête à choisir un autre type de méthodes de jointure. Tous ces paramètres de configuration sont « activés » par défaut. Vous trouverez ci-dessous les paramètres de configuration du planificateur spécifiques aux méthodes de jointure. Il existe de nombreux paramètres de configuration liés au plan utilisés à diverses fins. Dans ce blog, limitez-le aux seules méthodes de jointure. Ces paramètres peuvent être modifiés à partir d'une session particulière. Donc, au cas où nous voudrions expérimenter le plan à partir d'une session particulière, ces paramètres de configuration peuvent être manipulés et les autres sessions continueront à fonctionner telles quelles. Maintenant, considérez les exemples ci-dessus de jointure par fusion et de jointure par hachage. Sans index, l'optimiseur de requête a sélectionné une jointure par hachage pour la requête ci-dessous, comme indiqué ci-dessous, mais après avoir utilisé la configuration, il passe à la jointure par fusion même sans index : Initialement Hash Join est choisi car les données des tables ne sont pas triées. Afin de choisir le plan de jointure par fusion, il doit d'abord trier tous les enregistrements extraits des deux tables, puis appliquer la jointure par fusion. Ainsi, le coût du tri sera supplémentaire et donc le coût global augmentera. Donc, dans ce cas, le coût total (y compris l'augmentation) est peut-être supérieur au coût total de Hash Join, donc Hash Join est choisi. Une fois que le paramètre de configuration enable_hashjoin est défini sur "off", cela signifie que l'optimiseur de requête attribue directement un coût pour la jointure par hachage en tant que coût de désactivation (=1.0e10, c'est-à-dire 10000000000,00). Le coût de toute jointure possible sera moindre que cela. Ainsi, le même résultat de requête dans Merge Join après que enable_hashjoin soit passé à "off", car même en incluant le coût de tri, le coût total de la jointure de fusion est inférieur au coût de désactivation. Considérons maintenant l'exemple ci-dessous : Comme nous pouvons le voir ci-dessus, même si le paramètre de configuration lié à la jointure de boucle imbriquée est modifié sur "off", il choisit toujours la jointure de boucle imbriquée car il n'y a pas d'autre possibilité d'obtenir un autre type de méthode de jointure. choisi. En termes plus simples, étant donné que Nested Loop Join est la seule jointure possible, alors quel qu'en soit le coût, ce sera toujours le gagnant (comme j'avais l'habitude d'être le vainqueur de la course de 100 m si je courais seul… :-)). Notez également la différence de coût entre le premier et le deuxième plan. Le premier plan indique le coût réel de Nested Loop Join, mais le second indique le coût de désactivation de celui-ci. Tous les types de méthodes de jointure PostgreSQL sont utiles et sont sélectionnés en fonction de la nature de la requête, des données, de la clause de jointure, etc. Dans le cas où la requête ne fonctionne pas comme prévu, c'est-à-dire que les méthodes de jointure ne le sont pas sélectionné comme prévu, l'utilisateur peut jouer avec les différents paramètres de configuration du plan disponibles et voir s'il manque quelque chose.For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows)Hash Join
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Fusionner la jointure
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows)Configuration
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)Conclusion