J'ai longtemps été un partisan du choix du type de données correct. J'ai parlé de quelques exemples dans un précédent article de blog "Bad Habits", mais ce week-end au SQL Saturday #162 (Cambridge, UK), le sujet de l'utilisation de DATETIME par défaut est venu. Dans une conversation après ma présentation T-SQL :Bad Habits and Best Practices, un utilisateur a déclaré qu'il n'utilisait que DATETIME même s'ils n'ont besoin que d'une granularité à la minute ou au jour près, les colonnes de date/heure de leur entreprise sont toujours du même type de données. J'ai suggéré que cela pourrait être du gaspillage et que la cohérence n'en valait peut-être pas la peine, mais aujourd'hui, j'ai décidé de prouver ma théorie.
TL;Version DR
Mes tests ci-dessous révèlent qu'il existe certainement des scénarios dans lesquels vous voudrez peut-être envisager d'utiliser un type de données plus fin au lieu de vous en tenir à DATETIME partout. Mais il est important de voir où mes tests pointaient dans l'autre sens, et il est également important de tester ces scénarios par rapport à votre schéma, dans votre environnement, avec du matériel et des données aussi fidèles que possible à la production. Vos résultats peuvent varier, et le seront presque certainement.
Les tableaux de destination
Considérons le cas où la granularité n'a d'importance que pour la journée (nous ne nous soucions pas des heures, des minutes, des secondes). Pour cela, nous pourrions choisir DATETIME (comme l'utilisateur l'a proposé), ou SMALLDATETIME , ou DATE sur SQL Server 2008+. Il existe également deux types de données différents que je voulais prendre en compte :
- Données qui seraient insérées à peu près séquentiellement en temps réel (par exemple, des événements qui se produisent actuellement) ;
- Données qui seraient insérées de manière aléatoire (par exemple, les dates de naissance des nouveaux membres).
J'ai commencé avec 2 tables comme celles-ci, puis j'en ai créé 4 autres (2 pour SMALLDATETIME, 2 pour DATE) :
CREATE TABLE dbo.BirthDatesRandom_Datetime( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL); CREATE TABLE dbo.EventsSequential_Datetime( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL); CREATE INDEX d ON dbo.BirthDatesRandom_Datetime(dt);CREATE INDEX d ON dbo.EventsSequential_Datetime(dt); -- Ensuite, répétez pour DATE et SMALLDATETIME.
Et mon objectif était de tester les performances d'insertion par lots de ces deux manières différentes, ainsi que l'impact sur la taille et la fragmentation globales du stockage, et enfin les performances des requêtes de plage.
Exemple de données
Pour générer des exemples de données, j'ai utilisé l'une de mes techniques pratiques pour générer quelque chose de significatif à partir de quelque chose qui ne l'est pas :les vues de catalogue. Sur mon système, cela a renvoyé 971 valeurs de date/heure distinctes (1 000 000 lignes au total) en environ 12 secondes :
;WITH y AS ( SELECT TOP (1000000) d =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20120101')) FROM ( SELECT s1.[object_id] % 1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) AS x(x) ORDER BY NEWID()) SELECT DISTINCT d FROM y;
J'ai mis ces millions de lignes dans une table afin de pouvoir simuler des insertions séquentielles/aléatoires en utilisant différentes méthodes d'accès pour exactement les mêmes données à partir de trois fenêtres de session différentes :
CREATE TABLE dbo.Staging( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL);;WITH Staging_Data AS ( SELECT TOP (1000000) dt =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20110101')) FROM ( SELECT s1.[object_id] % 1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) AS sd(x) ORDER BY NEWID())INSERT dbo.Staging(source_date) SELECT dt FROM y ORDER BY dt;
Ce processus a pris un peu plus de temps (20 secondes). Ensuite, j'ai créé une deuxième table pour stocker les mêmes données mais distribuées de manière aléatoire (afin que je puisse répéter la même distribution sur toutes les insertions).
CREATE TABLE dbo.Staging_Random( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL); INSERT dbo.Staging_Random(source_date) SELECT source_date FROM dbo.Staging ORDER BY NEWID();
Requêtes pour remplir les tables
Ensuite, j'ai écrit un ensemble de requêtes pour remplir les autres tables avec ces données, en utilisant trois fenêtres de requête pour simuler au moins un peu de concurrence :
WAITFOR TIME '13:53';GO DECLARE @d DATETIME2 =SYSDATETIME(); INSERT dbo.{table_name}(dt) -- selon la méthode / le type de données SELECT source_date FROM dbo.Staging[_Random] -- selon la destination WHERE ID % 3 =<0,1,2> -- selon la fenêtre de requête ORDER PAR ID ; SELECT DATEDIFF(MILLISECOND, @d, SYSDATETIME()); Comme dans mon dernier message, j'ai pré-développé la base de données pour empêcher tout type d'événements de croissance automatique de fichiers de données d'interférer avec les résultats. Je me rends compte qu'il n'est pas tout à fait réaliste d'effectuer des insertions d'un million de lignes en une seule passe, car je ne peux pas empêcher l'activité du journal pour une transaction aussi importante d'interférer, mais cela devrait le faire de manière cohérente dans chaque méthode. Étant donné que le matériel avec lequel je teste est complètement différent du matériel que vous utilisez, les résultats absolus ne devraient pas être une conclusion clé, juste une comparaison relative.
(Dans un futur test, je vais également essayer cela avec de vrais lots provenant de fichiers journaux avec des données relativement mélangées, et en utilisant des morceaux de la table source dans des boucles - je pense que ce seraient également des expériences intéressantes. Et bien sûr en ajoutant compression dans le mix.)
Les résultats :
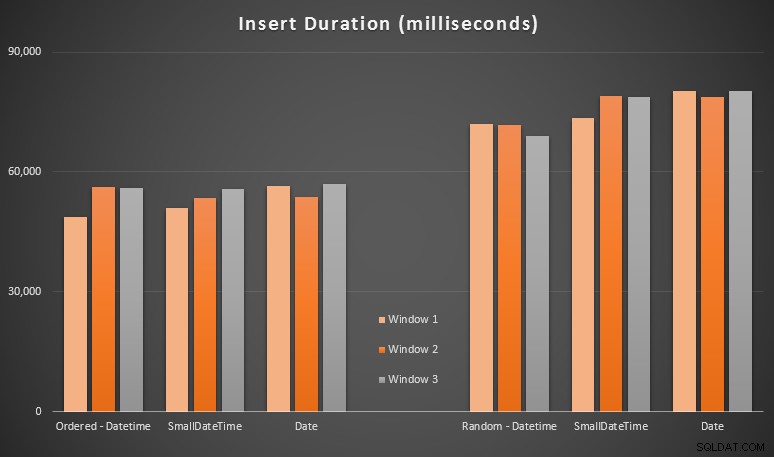
Ces résultats n'étaient pas si surprenants pour moi - l'insertion dans un ordre aléatoire a conduit à des temps d'exécution plus longs que l'insertion séquentielle, quelque chose que nous pouvons tous ramener à nos racines pour comprendre comment fonctionnent les index dans SQL Server et comment davantage de "mauvais" fractionnements de page peuvent se produire dans ce scénario (je n'ai pas surveillé spécifiquement les fractionnements de page dans cet exercice, mais c'est quelque chose que je prendrai en compte dans les tests futurs).
J'ai remarqué que, du côté aléatoire, les conversions implicites sur les données entrantes pouvaient avoir un impact sur les délais, car elles semblaient un peu plus élevées que le DATETIME -> DATETIME natif inserts. J'ai donc décidé de créer deux nouvelles tables contenant des données source :une utilisant DATE et un en utilisant SMALLDATETIME . Cela simulerait, dans une certaine mesure, la conversion correcte de votre type de données avant de le transmettre à l'instruction d'insertion, de sorte qu'une conversion implicite n'est pas requise lors de l'insertion. Voici les nouveaux tableaux et comment ils ont été remplis :
CREATE TABLE dbo.Staging_Random_SmallDatetime( ID INT IDENTITY(1,1) PRIMARY KEY, source_date SMALLDATETIME NOT NULL); CREATE TABLE dbo.Staging_Random_Date( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATE NOT NULL); INSERT dbo.Staging_Random_SmallDatetime(source_date) SELECT CONVERT(SMALLDATETIME, source_date) FROM dbo.Staging_Random ORDER BY ID ; INSERT dbo.Staging_Random_Date(source_date) SELECT CONVERT(DATE, source_date) FROM dbo.Staging_Random ORDER BY ID ;
Cela n'a pas eu l'effet que j'espérais - les délais étaient similaires dans tous les cas. C'était donc une chasse aux oies sauvages.
Espace utilisé et fragmentation
J'ai exécuté la requête suivante pour déterminer combien de pages étaient réservées pour chaque table :
SELECT nom ='dbo.' + OBJECT_NAME([object_id]), pages =SUM(reserved_page_count)FROM sys.dm_db_partition_stats GROUP BY OBJECT_NAME([object_id])ORDER BY pages ;
Les résultats :
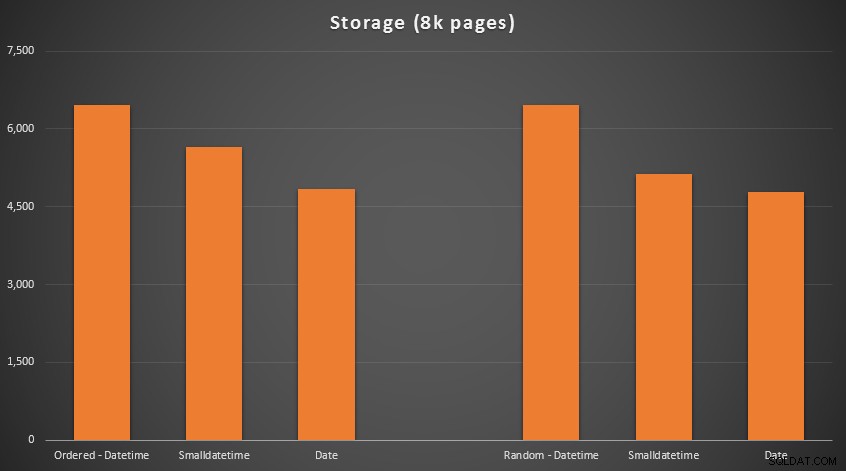
Pas de science-fusée ici; utilisez un type de données plus petit, vous devez utiliser moins de pages. Passer de DATETIME au DATE systématiquement réduit de 25 % le nombre de pages utilisées, tandis que SMALLDATETIME réduit l'exigence de 13 à 20 %.
Maintenant, pour la fragmentation et la densité des pages sur les index non clusterisés (il y avait très peu de différence pour les index clusterisés) :
SELECT '{table_name}', index_id avg_page_space_used_in_percent, avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats ( DB_ID(), OBJECT_ID('{table_name}'), NULL, NULL, 'DETAILED' ) WHERE index_level =0 AND index_id =2;
Résultats :
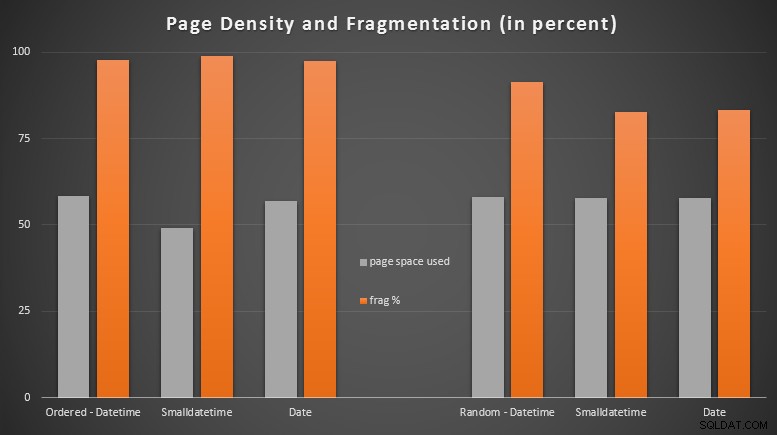
J'ai été assez surpris de voir les données commandées devenir presque complètement fragmentées, tandis que les données insérées au hasard se sont en fait retrouvées avec une utilisation de la page légèrement meilleure. J'ai noté que cela justifie une enquête plus approfondie en dehors de la portée de ces tests spécifiques, mais c'est peut-être quelque chose que vous voudrez vérifier si vous avez des index non clusterisés qui reposent sur des insertions en grande partie séquentielles.
[Une reconstruction en ligne des index non clusterisés sur les 6 tables s'est exécutée en 7 secondes, ramenant la densité des pages à 99,5 % et ramenant la fragmentation à moins de 1 %. Mais je ne l'ai pas exécuté avant d'avoir effectué les tests de requête ci-dessous…]
Test de requête de plage
Enfin, je voulais voir l'impact sur les runtimes pour les requêtes de plage de dates simples sur les différents index, à la fois avec la fragmentation inhérente causée par l'activité d'écriture de type OLTP, et sur un index propre qui est reconstruit. La requête elle-même est assez simple :
SELECT TOP (200000) dt FROM dbo.{table_name} WHERE dt>='20110101' ORDER BY dt;
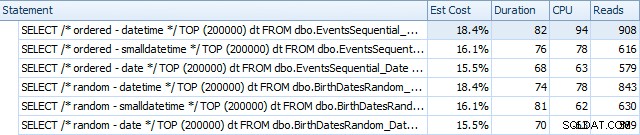
Voici les résultats avant la reconstruction des index, à l'aide de SQL Sentry Plan Explorer :
Et ils diffèrent légèrement après les reconstructions :
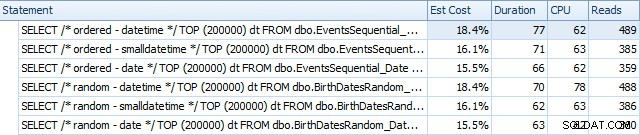
Essentiellement, nous constatons une durée et des lectures légèrement plus élevées pour les versions DATETIME, mais très peu de différence de CPU. Et les différences entre SMALLDATETIME et DATE sont négligeables en comparaison. Toutes les requêtes avaient des plans de requête simplistes comme celui-ci :

(La recherche est, bien sûr, un balayage de distance ordonné.)
Conclusion
Bien qu'il soit vrai que ces tests sont assez fabriqués et auraient pu bénéficier de plus de permutations, ils montrent à peu près ce que je m'attendais à voir :les impacts les plus importants sur ce choix spécifique concernent l'espace occupé par l'index non clusterisé (où le choix d'un type de données plus fin bénéficiera certainement), et sur le temps nécessaire pour effectuer des insertions dans un ordre arbitraire plutôt que séquentiel (où DATETIME n'a qu'un bord marginal).
J'aimerais entendre vos idées sur la façon de mettre des choix de types de données comme ceux-ci à travers des tests plus approfondis et punitifs. Je prévois d'entrer dans plus de détails dans les prochains articles.