Nous faisons tous des erreurs et nous pouvons tous apprendre des erreurs des autres. Dans cet article, nous examinerons de nombreuses ressources en ligne pour éviter une mauvaise conception de base de données qui peut entraîner de nombreux problèmes et coûter du temps et de l'argent. Et dans un prochain article, nous vous dirons où trouver des conseils et des bonnes pratiques.
Erreurs de conception de base de données et erreurs à éviter
Il existe de nombreuses ressources en ligne pour aider les concepteurs de bases de données à éviter les erreurs et erreurs courantes. De toute évidence, cet article n'est pas une liste exhaustive de tous les articles disponibles. Au lieu de cela, nous avons examiné et commenté diverses sources afin que vous puissiez trouver celle qui vous convient le mieux.
Notre recommandation
S'il n'y a qu'un seul article parmi ces ressources que vous allez lire, ce devrait être "Comment obtenir une conception de base de données horriblement erronée" de Robert Sheldon
Commençons par le blog DATAVERSITY qui fournit un large éventail de ressources assez bonnes :
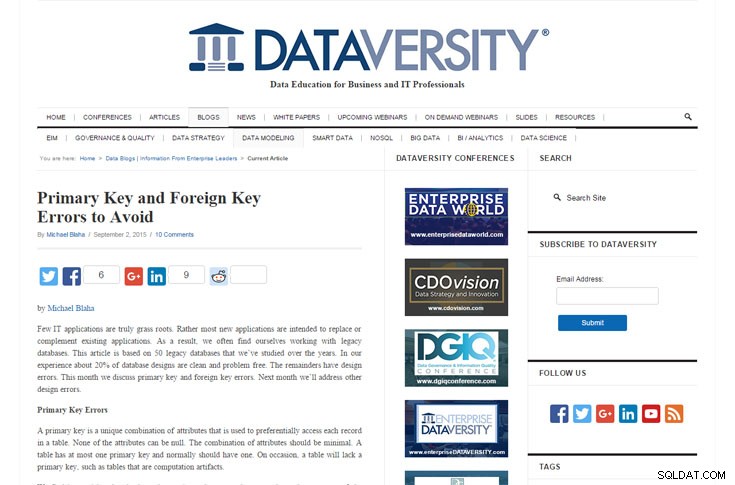
Erreurs de clé primaire et de clé étrangère à éviter
par Michael Blaha | Blogue DATAVERSITY | 2 septembre 2015
Plus d'erreurs de conception de base de données – Confusion avec les relations plusieurs-à-plusieurs
par Michael Blaha | Blogue DATAVERSITY | 30 septembre 2015
Erreurs diverses de conception de la base de données
par Michael Blaha | Blogue DATAVERSITY | 26 octobre 2015
Michael Blaha a contribué une belle série de trois articles. Chaque article aborde différents pièges de la modélisation de base de données et de la conception physique ; les sujets incluent les clés, les relations et les erreurs générales. De plus, il y a des discussions avec Michael concernant certains points. Si vous recherchez des pièges autour des clés et des relations, ce serait un bon point de départ.
M. Blaha déclare qu'"environ 20 % des bases de données violent les règles de la clé primaire". Ouah! Cela signifie qu'environ 20 % des développeurs de bases de données n'ont pas correctement créé les clés primaires. Si cette statistique est vraie, alors elle montre vraiment l'importance des outils de modélisation de données qui "encouragent" fortement ou même obligent les modélisateurs à définir des clés primaires.
M. Blaha partage également l'heuristique selon laquelle "environ 50 % des bases de données" ont des problèmes de clé étrangère (selon son expérience avec les bases de données héritées qu'il a étudiées). Il nous rappelle d'éviter les liens informels entre les tables en incorporant la valeur d'une table dans une autre plutôt qu'en utilisant une clé étrangère.
J'ai vu ce problème plusieurs fois. J'admets qu'un lien informel peut être requis par la fonctionnalité à implémenter, mais le plus souvent, il se produit par simple paresse. Par exemple, nous pouvons vouloir montrer l'identifiant d'utilisateur de quelqu'un qui a modifié quelque chose, donc nous stockons l'identifiant d'utilisateur directement dans la table. Mais que se passe-t-il si cet utilisateur change son ID utilisateur ? Alors ce lien informel est rompu. Cela est souvent dû à une mauvaise conception et modélisation.
Concevoir votre base de données :5 erreurs à éviter
par Henrique Netzka | Blogue DATAVERSITY | 2 novembre 2015
J'ai été un peu déçu par cet article, car il contenait quelques éléments assez spécifiques (stocker le protocole dans un CLOB) et quelques éléments très généraux (pensez à la localisation). Globalement, l'article est bien, mais s'agit-il vraiment du top 5 des erreurs à éviter ? À mon avis, plusieurs autres erreurs courantes devraient figurer sur la liste.
Cependant, sur une note positive, c'est l'un des rares articles qui mentionne la mondialisation et la localisation de manière significative. Je travaille dans un environnement très multilingue et j'ai vu plusieurs implémentations horribles de la localisation, j'étais donc heureux de trouver ce problème mentionné. Les colonnes de langue et les colonnes de fuseau horaire peuvent sembler évidentes, mais elles apparaissent très rarement dans les modèles de base de données.
Cela étant dit, j'ai pensé qu'il serait intéressant de créer un modèle incluant des traductions pouvant être modifiées par les utilisateurs finaux (par opposition à l'utilisation de ressources groupées). Il y a quelque temps, j'ai écrit sur un modèle de base de données d'enquête en ligne. Ici, j'ai modélisé une traduction simplifiée des questions et des choix de réponse :
En supposant que nous devons permettre aux utilisateurs finaux de conserver les traductions, la méthode préférée serait d'ajouter des tables de traduction pour les questions et les réponses :
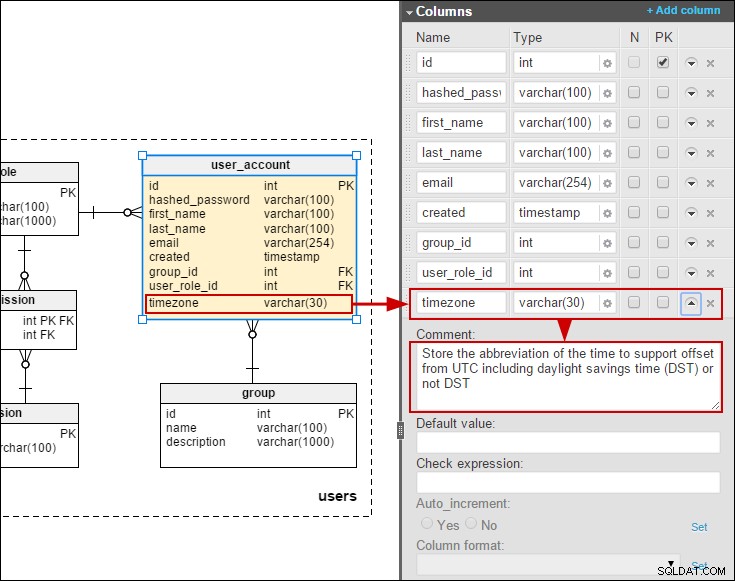
J'ai également ajouté un fuseau horaire au user_account table afin que nous puissions stocker les dates/heures dans l'heure locale des utilisateurs :
7 erreurs courantes de conception de base de données
par Grzegorz Kaczor | Blog Vertabélo | 17 juillet 2015
Je vais faire une petite auto-promotion ici. Nous nous efforçons de publier régulièrement des articles intéressants et engageants ici.
Cet article particulier souligne plusieurs domaines de préoccupation importants, tels que la dénomination, l'indexation, les considérations de volume et les pistes d'audit. L'article aborde même des problèmes liés à des systèmes DBM spécifiques, comme les limitations d'Oracle sur les noms de table. J'aime vraiment les beaux exemples clairs, même s'ils illustrent comment les concepteurs font des erreurs et des erreurs.
Évidemment, il n'est pas possible de répertorier toutes les erreurs de conception, et celles répertoriées peuvent ne pas être vos erreurs les plus courantes. Lorsque nous écrivons sur des erreurs courantes, ce sont celles que nous avons commises ou trouvées dans le travail des autres sur lesquelles nous nous appuyons. Une liste complète des erreurs, classées en termes de fréquence, serait impossible à compiler par une seule personne. Néanmoins, je pense que cet article fournit plusieurs informations utiles sur les pièges potentiels. C'est une belle ressource solide dans l'ensemble.
Alors que M. Kaczor fait plusieurs remarques intéressantes dans son article, j'ai trouvé ses commentaires sur « ne pas tenir compte du volume ou du trafic possible » assez intéressants. En particulier, la recommandation de séparer les données fréquemment utilisées des données historiques est particulièrement pertinente. C'est une solution que nous utilisons fréquemment dans nos applications de messagerie; nous devons avoir un historique consultable de tous les messages, mais les messages les plus susceptibles d'être consultés sont ceux qui ont été publiés au cours des derniers jours. Ainsi, séparer les données "actives" ou récentes auxquelles on accède fréquemment (un volume de données beaucoup plus petit) des données historiques à long terme (la grande masse de données) est généralement une très bonne technique.
Erreurs courantes de conception de base de données
par Troy Blake | Blog DBA senior | 11 juillet 2015
L'article de Troy Blake est une autre bonne ressource, même si j'ai peut-être renommé cet article "Common SQL Server Design Mistakes".
Par exemple, nous avons le commentaire :"les procédures stockées sont votre meilleur ami lorsqu'il s'agit d'utiliser efficacement SQL Server". C'est bien, mais est-ce une erreur générale courante, ou est-ce plus spécifique à SQL Server ? Je devrais opter pour que cela soit un peu spécifique à SQL Server, car il y a des inconvénients à utiliser des procédures stockées, comme se retrouver avec des procédures stockées spécifiques au fournisseur et donc le verrouillage du fournisseur. Je ne suis donc pas fan de l'inclusion de "Ne pas utiliser de procédures stockées" dans cette liste.
Cependant, du côté positif, je pense que l'auteur a identifié certaines erreurs très courantes, comme une mauvaise planification, une conception de système de mauvaise qualité, une documentation limitée, des normes de dénomination faibles et un manque de tests.
Je classerais donc cela comme une référence très utile pour les praticiens de SQL Server et une référence utile pour les autres.
Sept erreurs de modélisation des données
par Kurt Cagle | LinkedIn | 12 juin 2015
J'ai vraiment aimé lire la liste des erreurs de modélisation de base de données de M. Cagle. Celles-ci proviennent de la vision des choses d'un architecte de base de données ; il identifie clairement les erreurs de modélisation de niveau supérieur qui doivent être évitées. Avec cette vue agrandie, vous pouvez annuler un gâchis de modélisation potentiel.
Certains des types mentionnés dans l'article peuvent être trouvés ailleurs, mais quelques-uns d'entre eux sont uniques :devenir abstrait trop tôt ou mélanger des modèles conceptuels, logiques et physiques. Ceux-ci ne sont pas souvent mentionnés par d'autres auteurs, probablement parce qu'ils se concentrent sur le processus de modélisation des données plutôt que sur la vue globale du système.
En particulier, l'exemple de "Getting Too Abstract Too Early" décrit un processus de réflexion intéressant consistant à créer des exemples d'"histoires" et à tester quelles relations sont importantes dans ce domaine. Cela concentre la réflexion sur les relations entre les objets modélisés. Cela se traduit par des questions telles que quelles sont les relations importantes dans ce domaine ?
Sur la base de cette compréhension, nous créons le modèle autour des relations plutôt que de commencer par des éléments de domaine individuels et de construire les relations au-dessus d'eux. Alors que beaucoup d'entre nous pourraient utiliser cette approche, parmi ces ressources, aucun autre auteur ne l'a commentée. J'ai trouvé cette description et les exemples assez intéressants.
Comment obtenir une conception de base de données horriblement erronée
par Robert Sheldon | Conversation simple | 6 mars 2015
S'il n'y a qu'un seul article parmi ces ressources que vous allez lire, ce devrait être celui de Robert Sheldon
Ce que j'aime vraiment dans cet article, c'est que pour chacune des erreurs mentionnées, il y a des conseils pour bien faire les choses. La plupart d'entre eux visent à éviter l'échec plutôt qu'à le corriger, mais je pense toujours qu'ils sont très utiles. Il y a très peu de théorie ici; principalement des réponses directes pour éviter les erreurs lors de la modélisation des données. Il existe quelques points spécifiques à SQL Server, mais la plupart du temps, SQL Server est utilisé pour fournir des exemples d'évitement d'erreurs ou de solutions à l'échec.
La portée de l'article est également assez large :il couvre le fait de négliger de planifier, de ne pas se soucier de la documentation, d'utiliser des conventions de nommage moche, d'avoir des problèmes de normalisation (trop ou trop peu), d'échouer sur les clés et les contraintes, de ne pas correctement indexer et d'effectuer tests inadéquats.
En particulier, j'ai aimé les conseils pratiques concernant l'intégrité des données - quand utiliser les contraintes de vérification et quand définir les clés étrangères. De plus, M. Sheldon décrit également la situation où les équipes s'en remettent à l'application pour faire respecter l'intégrité. Il va droit au but lorsqu'il déclare qu'une base de données peut être consultée de multiples façons et par de nombreuses applications. Il conclut que « les données doivent être protégées là où elles résident :dans la base de données ». C'est tellement vrai qu'il peut être répété aux équipes de développement et aux responsables pour expliquer l'importance de mettre en place des contrôles d'intégrité dans le modèle de données.
C'est mon genre d'article, et vous pouvez dire que d'autres sont d'accord sur la base des nombreux commentaires qui l'approuvent. Alors, les meilleures notes ici; c'est une ressource très précieuse.
Dix erreurs courantes de conception de base de données
par Louis Davidson | Conversation simple | 26 février 2007
J'ai trouvé cet article assez bon, car il couvrait beaucoup d'erreurs de conception courantes. Il y avait des analogies significatives, des exemples, des modèles et même des citations classiques de William Shakespeare et J.R.R. Tolkien.
Quelques erreurs ont été expliquées plus en détail que d'autres, avec de longs exemples et des extraits SQL que j'ai trouvés un peu encombrants. Mais c'est une question de goût.
Encore une fois, nous avons quelques rubriques spécifiques à SQL Server. Par exemple, le fait de ne pas utiliser de procédures stockées pour accéder aux données est bon pour SQL, mais les SP ne sont pas toujours une bonne idée lorsque l'objectif est la prise en charge sur plusieurs SGBD. De plus, nous sommes avertis de ne pas essayer de coder des objets T-SQL génériques. Comme je travaille rarement avec SQL Server ou Sybase, je n'ai pas trouvé cette astuce pertinente.
La liste est assez similaire à celle de Robert Sheldon, mais si vous travaillez principalement sur SQL Server, vous trouverez quelques pépites d'informations supplémentaires.
Cinq erreurs de conception de base de données simples à éviter
par Anith Sen Larson | Conversation simple | 16 octobre 2009
Cet article donne quelques exemples significatifs pour chacune des erreurs de conception simples qu'il couvre. D'autre part, il se concentre plutôt sur des types d'erreurs similaires :tables de recherche communes, tables d'entités-attributs-valeurs et fractionnement d'attributs.
Les observations sont bonnes, et l'article a même des références, qui ont tendance à être rares. Pourtant, j'aimerais voir des erreurs de conception de base de données plus générales. Ces erreurs semblaient plutôt spécifiques, mais, comme je l'ai déjà écrit, les erreurs sur lesquelles nous écrivons sont généralement celles avec lesquelles nous avons une expérience personnelle.
Un élément que j'ai aimé était une règle empirique spécifique pour décider quand utiliser une contrainte de vérification par rapport à une table séparée avec une contrainte de clé étrangère. Plusieurs auteurs proposent des recommandations similaires, mais M. Larson les décompose en « must », « consider » et « strong case » – en admettant que « le design est un mélange d'art et de science et qu'il implique donc des compromis ». Je trouve cela très vrai.
Top 10 des erreurs de conception de bases de données physiques les plus courantes
par Craig Mullins | Données et technologie aujourd'hui | 5 août 2013
Comme son nom l'indique, « Top Ten Most Common Database Design Mistakes » est légèrement plus orienté vers la conception physique que vers la conception logique et conceptuelle. Aucune des erreurs mentionnées par l'auteur de Craig Mullins ne se démarque vraiment ou n'est unique, donc je recommanderais cette information aux personnes travaillant du côté DBA physique.
De plus, les descriptions sont un peu courtes, il est donc parfois difficile de voir pourquoi une erreur particulière va causer des problèmes. Il n'y a rien de mal en soi avec de courtes descriptions, mais elles ne vous donnent pas beaucoup à penser. Et aucun exemple n'est présenté.
Il y a un point intéressant soulevé concernant l'échec du partage des données. Ce point est parfois mentionné dans d'autres articles, mais pas comme une erreur de conception. Cependant, je vois ce problème assez fréquemment avec des bases de données "recréées" sur la base d'exigences très similaires, mais par une nouvelle équipe ou pour un nouveau produit
.Il arrive souvent que l'équipe produit se rende compte plus tard qu'elle aurait aimé utiliser des données qui étaient déjà présentes dans le « père » de leur base de données actuelle. En réalité, cependant, ils auraient dû améliorer le parent plutôt que de créer une nouvelle progéniture. Les applications sont destinées à partager des données ; une bonne conception peut permettre à une base de données d'être réutilisée plus souvent.
Faites-vous ces 5 erreurs de conception de base de données ?
par Thomas Larock | Le blog de Thomas Larock | 2 janvier 2012
Vous pourriez trouver quelques points intéressants en répondant à la question de Thomas Larock :Faites-vous ces 5 erreurs de conception de base de données ?
Cet article est plutôt axé sur les clés (clés étrangères, clés de substitution et clés générées). Pourtant, il a un point important :il ne faut pas supposer que les fonctionnalités du SGBD sont les mêmes sur tous les systèmes. Je pense que c'est un très bon point. C'est aussi celui qui ne se trouve pas dans la plupart des autres articles, peut-être parce que de nombreux auteurs se concentrent sur et travaillent principalement avec un seul SGBD.
Concevoir une base de données :7 choses que vous ne voulez pas faire
par Thomas Larock | Le blog de Thomas Larock | 16 janvier 2013
M. Larock a recyclé quelques-unes de ses « 5 erreurs de conception de base de données » lors de la rédaction de « 7 choses que vous ne voulez pas faire », mais il y a d'autres bons points ici.
Fait intéressant, certains des points soulevés par M. Larock ne se retrouvent pas dans de nombreuses autres sources. Vous obtenez quelques observations plutôt uniques, comme "n'avoir aucune attente de performance". C'est une erreur grave et qui, d'après mon expérience, se produit assez souvent. Même lors du développement du code d'application, c'est souvent après la création du modèle de données, de la base de données et de l'application elle-même que les gens commencent à réfléchir aux exigences non fonctionnelles (lorsque des tests non fonctionnels doivent être créés) et commencent à définir les attentes de performance. .
À l'inverse, il y a quelques points que je n'inclurais pas dans ma propre liste des dix meilleurs, comme « devenir gros, juste au cas où ». Je vois le point, mais ce n'est pas si élevé sur ma liste lors de la création d'un modèle de données. Il n'y a pas de spécificité pour un système DBM particulier, c'est donc un bonus.
Pour conclure, bon nombre de ces points pourraient être résumés sous le point :"ne pas comprendre les exigences", qui figure vraiment dans ma liste des 10 erreurs les plus fréquentes.
Comment éviter 8 erreurs courantes de développement de base de données
par Base36 | 6 décembre 2012
J'étais assez intéressé par la lecture de cet article. Cependant, j'ai été un peu déçu. Il n'y a pas beaucoup de discussions sur l'évitement, et le point de l'article semble vraiment être "ce sont des erreurs de base de données courantes" et "pourquoi ce sont des erreurs" ; les descriptions de la façon d'éviter l'erreur sont moins importantes.
De plus, certaines des erreurs du Top 8 de l'article sont en fait contestées. L'utilisation abusive de la clé primaire en est un exemple. Base36 nous indique qu'ils doivent être générés par le système et non basés sur les données d'application de la ligne. Bien que je sois d'accord avec cela jusqu'à un certain point, je ne suis pas convaincu que tous Les PK doivent toujours être généré ; c'est un peu trop catégorique.
D'un autre côté, l'erreur de "Hard Delete" est intéressante et n'est pas souvent mentionnée ailleurs. Les suppressions réversibles causent d'autres problèmes, mais il est vrai que le simple fait de marquer une ligne comme inactive a ses avantages lorsque vous essayez de déterminer où sont allées ces données qui se trouvaient dans le système hier. La recherche dans les journaux de transactions n'est pas mon idée d'une façon agréable de passer une journée.
Les sept péchés capitaux de la conception de bases de données
par Jason Tiret | Journal des systèmes d'entreprise | 16 février 2010
J'étais plein d'espoir quand j'ai commencé à lire l'article de Jason Tiret, "Seven Deadly Sins of Database Design". J'étais donc heureux de constater qu'il ne se contentait pas de recycler les erreurs que l'on retrouve dans de nombreux autres articles. Au contraire, il offrait un "péché" que je n'avais pas trouvé dans d'autres listes :essayer d'effectuer toute la conception de la base de données "à l'avance" et ne pas mettre à jour le modèle une fois la base de données en production, lorsque des modifications sont apportées à la base de données. (Ou, comme le dit Jason, "Ne pas traiter le modèle de données comme un organisme vivant et respirant").
J'ai vu cette erreur plusieurs fois. La plupart des gens ne réalisent leur erreur que lorsqu'ils doivent mettre à jour un modèle qui ne correspond plus à la base de données réelle. Bien sûr, le résultat est un modèle inutile. Comme l'indique l'article, "les modifications doivent retrouver leur chemin vers le modèle".
D'autre part, la majorité des éléments de la liste de Jason sont assez bien connus. Les descriptions sont bonnes, mais il n'y a pas beaucoup d'exemples. Plus d'exemples et de détails seraient utiles.
Les erreurs de conception de base de données les plus courantes
par Brian Prince | eWeek.com | 19 mars 2008

L'article "Les erreurs de conception de base de données les plus courantes" est en fait une série de diapositives d'une présentation. Il y a quelques réflexions intéressantes, mais certains des objets uniques sont peut-être un peu ésotériques. J'ai à l'esprit des points tels que "Apprenez à connaître RAID" et l'implication des parties prenantes.
En général, je ne mettrais pas cela sur votre liste de lecture à moins que vous ne vous concentriez sur des problèmes généraux (planification, dénomination, normalisation, index) et des détails physiques.
10 erreurs de conception courantes
par davidm | Blogs SQL Server – SQLTeam.com | 12 septembre 2005
Certains des points de « Dix erreurs de conception courantes » sont intéressants et relativement nouveaux. Cependant, certaines de ces erreurs sont assez controversées, telles que "l'utilisation de NULL" et la dénormalisation.
Je conviens que la création de toutes les colonnes comme nullables est une erreur, mais définir une colonne comme nullable peut être nécessaire pour une fonction métier particulière. Peut-elle donc être considérée comme une erreur générique ? Je ne pense pas.
Un autre point que je conteste est la dénormalisation. Ce n'est pas toujours une erreur de conception. Par exemple, la dénormalisation peut être nécessaire pour des raisons de performances.
Cet article manque aussi largement de détails et d'exemples. Les conversations entre DBA et programmeur ou gestionnaire sont amusantes, mais j'aurais préféré des exemples plus concrets et des justifications détaillées pour ces erreurs courantes.
OTLT et EAV :les deux grosses erreurs de conception que font tous les débutants
par Tony Andrews | Tony Andrews sur Oracle et les bases de données | 21 octobre 2004
L'article de M. Andrews nous rappelle les erreurs "One True Lookup Table" (OTLT) et Entity-Attribute-Value (EAV) qui sont mentionnées dans d'autres articles. Un point intéressant à propos de cette présentation est qu'elle se concentre sur ces deux erreurs, donc les descriptions et les exemples sont précis. En outre, une explication possible de la raison pour laquelle certains concepteurs implémentent OTLT et EAV est donnée.
Pour vous rappeler, la table OTLT ressemble généralement à ceci, avec des entrées de plusieurs domaines jetées dans la même table :
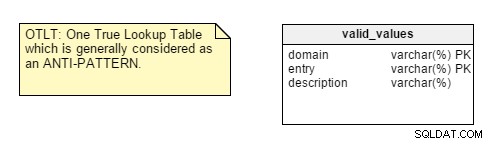
Comme d'habitude, il y a une discussion pour savoir si OTLT est une solution viable et un bon modèle de conception. Je dois dire que je me range du côté du groupe anti-OTLT; ces tableaux présentent de nombreux problèmes. Nous pourrions utiliser l'analogie de l'utilisation d'un seul énumérateur pour représenter toutes les valeurs possibles de toutes les constantes possibles. Je n'ai jamais vu ça jusqu'à présent.
Erreurs courantes dans la base de données
par John Paul Ashenfelter | Dr Dobb's | 01 janvier 2002
L'article de M. Ashenfelter répertorie 15 erreurs courantes dans les bases de données. Il y a même quelques erreurs qui ne sont pas fréquemment mentionnées dans d'autres articles. Malheureusement, les descriptions sont relativement courtes et il n'y a pas d'exemples. Le mérite de cet article est que la liste couvre beaucoup de terrain et peut être utilisée comme une "liste de contrôle" des erreurs à éviter. Bien que je ne puisse pas les classer parmi les erreurs de base de données les plus importantes, elles sont certainement parmi les plus courantes.
Sur une note positive, c'est l'un des rares articles qui mentionne la nécessité de gérer l'internationalisation des formats de données comme la date, la devise et l'adresse. Un exemple serait bien ici. Cela pourrait être aussi simple que "assurez-vous que State est une colonne nullable ; dans de nombreux pays, il n'y a pas d'état associé à une adresse ».
Plus tôt dans cet article, j'ai mentionné d'autres préoccupations et certaines approches pour se préparer à la mondialisation de votre base de données, comme les fuseaux horaires et les traductions (localisation). Le fait qu'aucun autre article ne mentionne le souci des formats de devise et de date est troublant. Nos bases de données sont-elles préparées pour l'utilisation globale de nos applications ?
Mentions honorables
Évidemment, il existe d'autres articles qui décrivent les erreurs et les erreurs courantes de conception de base de données, mais nous voulions vous donner un aperçu général des différentes ressources. Vous pouvez trouver des informations supplémentaires dans des articles tels que :
10 erreurs courantes de conception de base de données | Blogue de la classe MIS | 29 janvier 2012
10 erreurs courantes dans la conception de bases de données | IDG.se | 24 juin 2010
Ressources en ligne :par où commencer ? Où aller ?
Comme mentionné précédemment, cette liste n'est certainement pas destinée à être un examen exhaustif de chaque article en ligne décrivant les erreurs et les erreurs de conception de base de données. Au lieu de cela, nous avons identifié plusieurs sources qui sont particulièrement utiles ou qui ont un objectif spécifique que vous pourriez trouver utile.
N'hésitez pas à recommander des articles supplémentaires.