Cet article donne un guide étape par étape pour utiliser les capacités d'apprentissage automatique avec 2UDA. Dans cet article, nous utiliserons un exemple d'animaux pour prédire s'il s'agit de mammifères, d'oiseaux, de poissons ou d'insectes.
Versions logicielles
Nous allons utiliser 2UDA version 11.6-1 pour implémenter le modèle Machine Learning. 2UDA version 11.6-1 combine :
- PostgreSQL 11.6
- Orange 3.23.0
Vous pouvez trouver la dernière version de 2UDA ici.
Étape 1 :Charger l'ensemble de données d'entraînement dans PostgreSQL
L'exemple d'ensemble de données utilisé pour former notre modèle est disponible dans le référentiel officiel Orange GitHub ici.
Suivez ces étapes pour charger les données d'apprentissage dans les tables PostgreSQL :
- Connectez-vous à PostgreSQL via psql, OmniDB ou tout autre outil que vous connaissez.
- Créer un tableau pour stocker nos données d'entraînement . Ici, il est nommé training_data.
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Insérez des données d'entraînement dans le tableau via la requête COPY. Avant d'exécuter la requête COPY, assurez-vous que PostgreSQL a requis les autorisations de lecture sur le fichier de données, sinon l'opération COPY échouera.
REMARQUE : Assurez-vous de saisir une tabulation espace entre guillemets simples après le délimiteur mot-clé.
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
Veuillez trouver la capture d'écran de l'ensemble de données d'entraînement ci-dessous
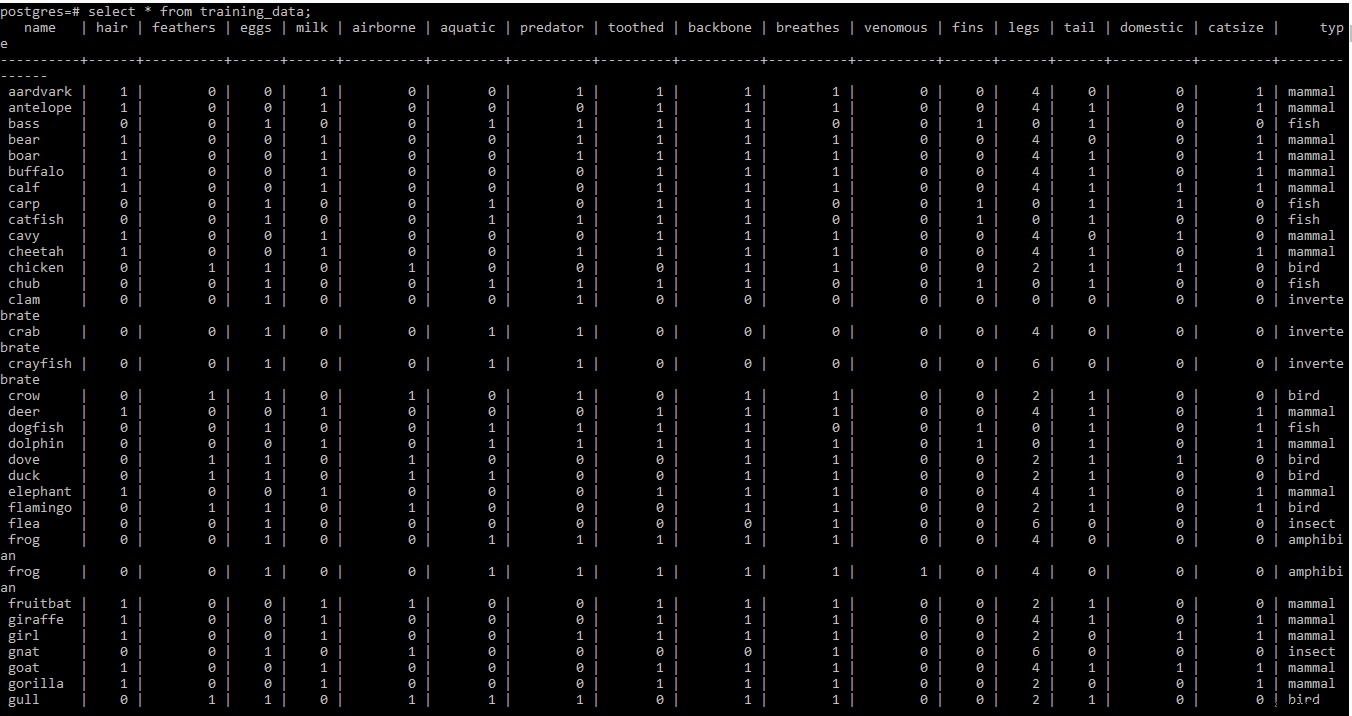
REMARQUE : Lignes 2 et 3 de l'ensemble de données d'entraînement dans le .tab fichier contient des méta-informations. Comme il n'est pas nécessaire à ce stade, il a été supprimé du fichier.
Étape 2 :Créer un flux de travail avec Orange
- Allez sur le bureau et double-cliquez sur l'icône orange.
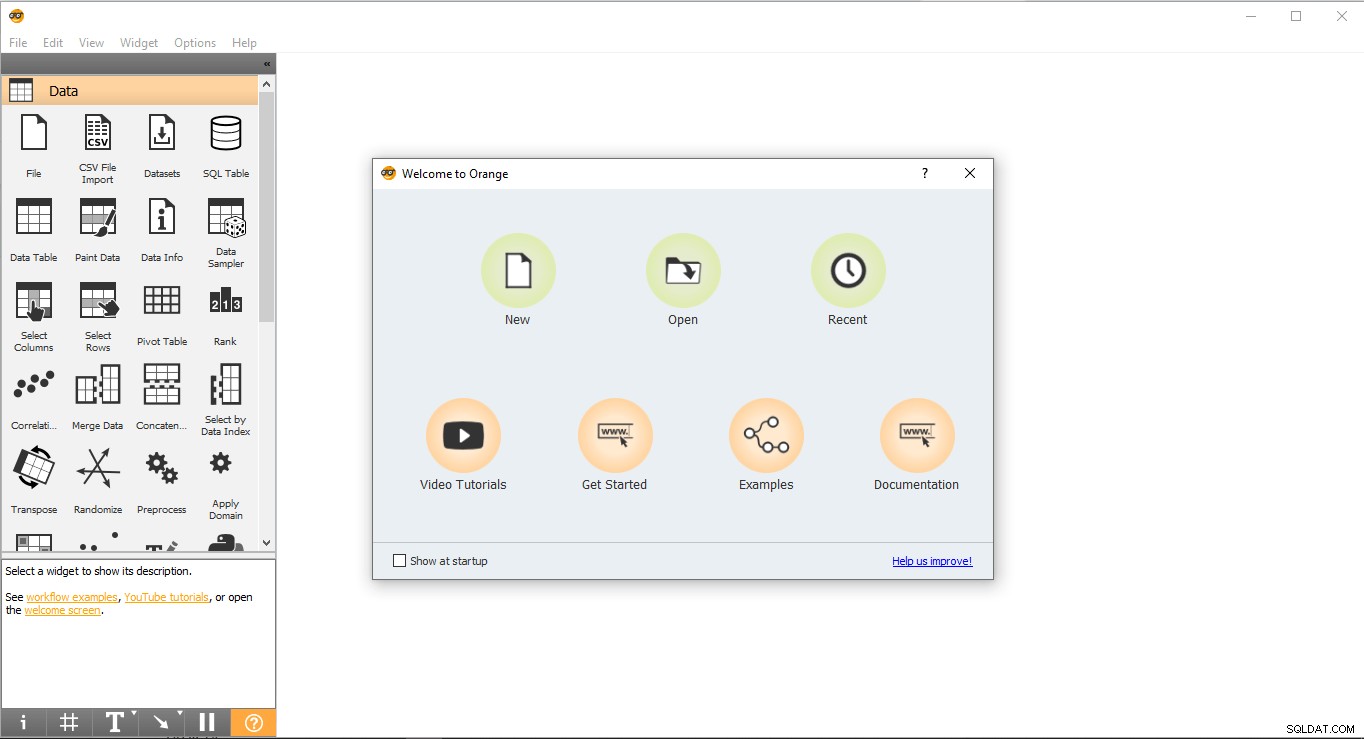
- Voici à quoi ressemble la page de démarrage. Sélectionnez Nouveau option et cela créera un projet vide.

Vous êtes maintenant prêt à appliquer le modèle Machine Learning sur l'ensemble de données.
Étape 3 :Sélectionnez le modèle de machine learning pour entraîner les données
Pour cet article, k-nearest voisins (KNN) Le modèle d'apprentissage automatique est utilisé pour former les données. Une fois le processus de formation des données terminé, à l'étape suivante, les données de test sont transmises à la prédiction widget pour vérifier l'exactitude des prédictions.
Étape 4 :Importer les données d'entraînement de PostgreSQL vers Orange
Cet ensemble de données d'entraînement sera utilisé pour entraîner le modèle d'apprentissage automatique.
- Glisser et déposer la table SQL widget depuis les Données menu.
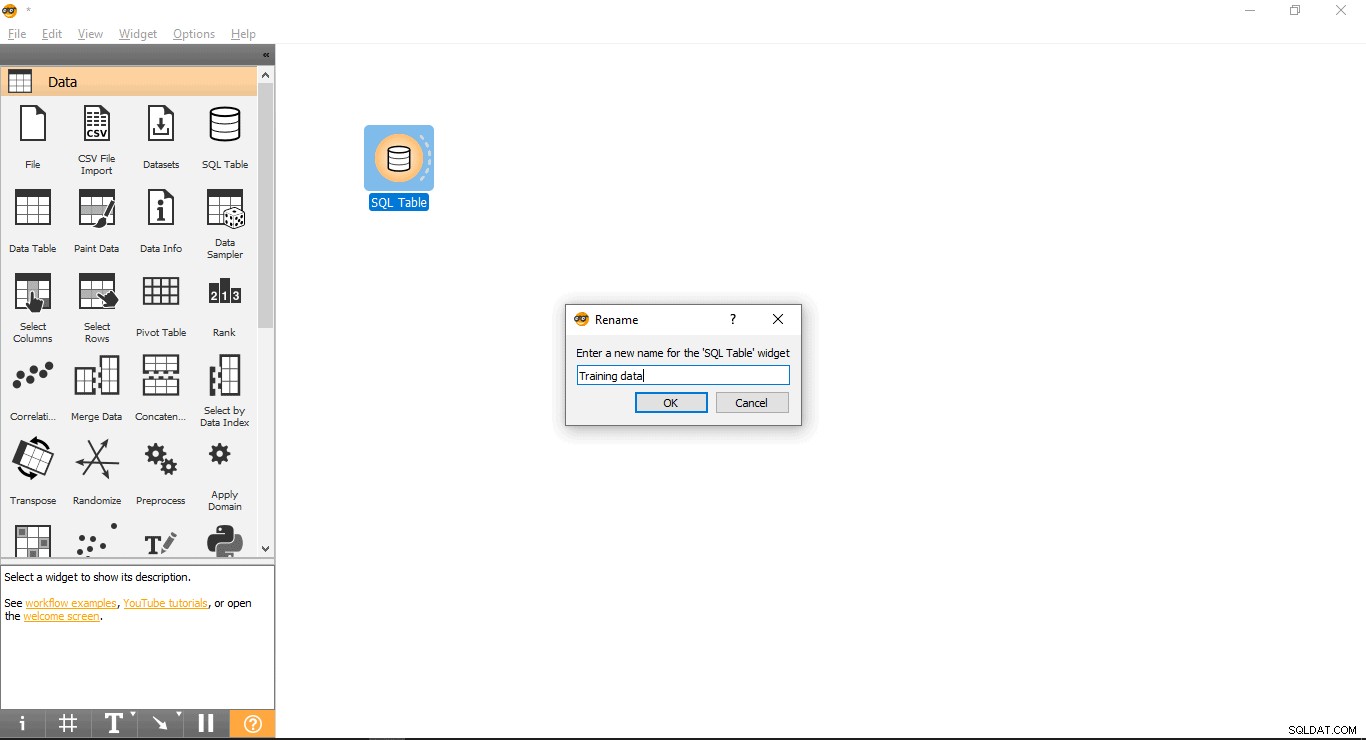
- Renommer le widget (facultatif)
- Cliquez avec le bouton droit sur la table SQL widget.
- Sélectionnez Renommer .
- Connectez-vous à PostgreSQL pour charger l'ensemble de données d'entraînement :
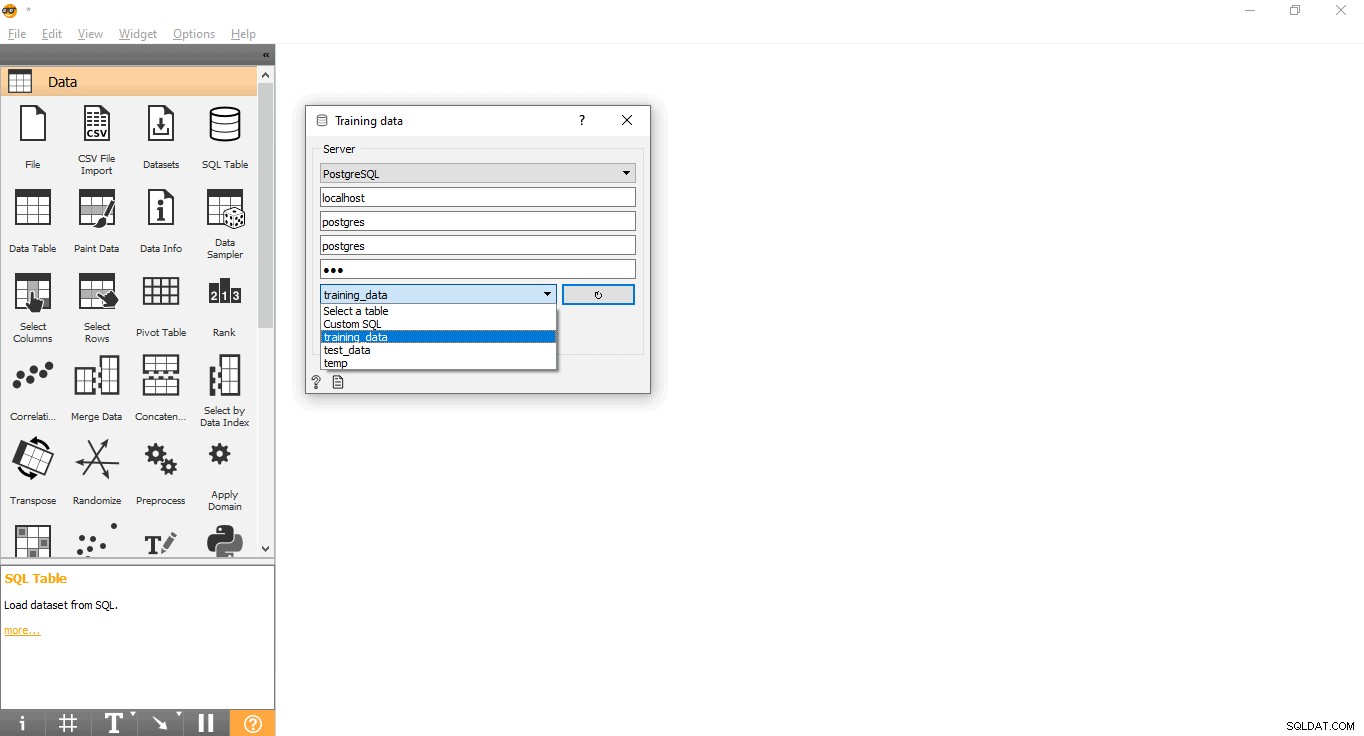
- Double-cliquez sur les données d'entraînement widget.
- Entrez les informations d'identification pour vous connecter à la base de données PostgreSQL.
- Appuyez sur le bouton de rechargement pour charger toutes les tables disponibles à partir de la base de données donnée.
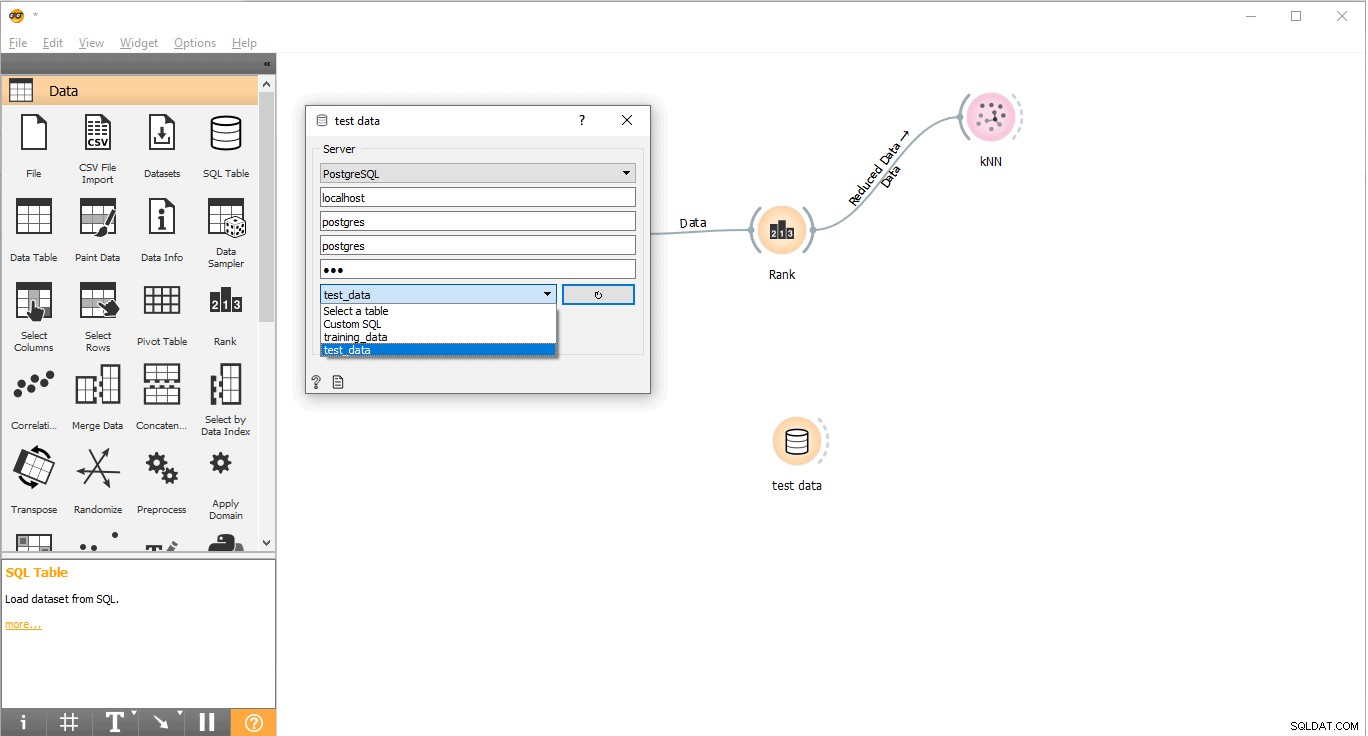
- Sélectionnez la table training_data dans le menu déroulant et fermez la fenêtre contextuelle.
Étape 5 :Ajouter une colonne cible
Cette étape est importante car le modèle Machine Learning tentera de prédire les données pour cette variable/colonne cible :
- Glisser et déposer Sélectionner les colonnes widget à partir des données menu.
- Double-cliquez sur Sélectionner des colonnes widget.
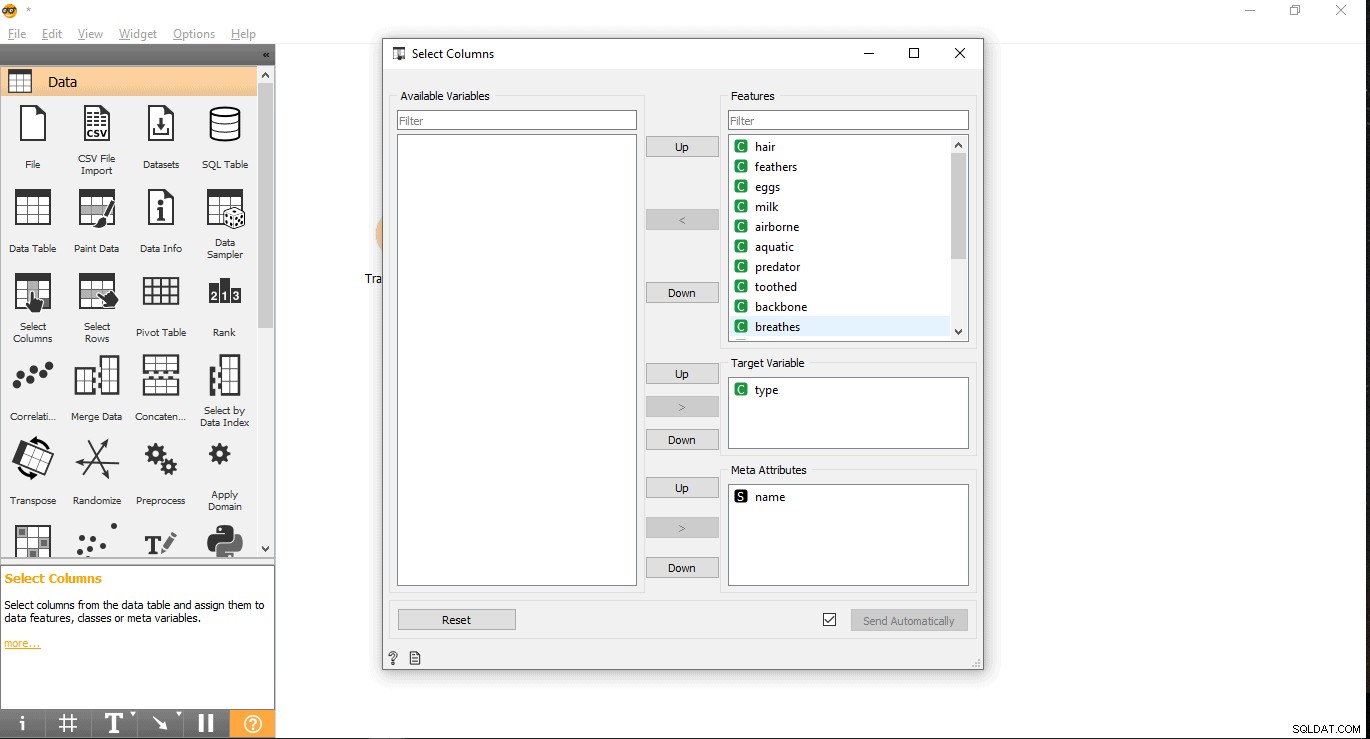
- Recherchez votre colonne cible sous le libellé Fonctionnalités. Ici, le type est utilisé comme variable cible car nous devons voir de quel type est un animal donné.
- Glissez-la et déposez-la sous Variable cible boîte de dialogue et fermez la fenêtre contextuelle.
Étape 6 :Classement des colonnes
Vous pouvez classer ou noter les variables/colonnes d'entraînement en fonction de leur corrélation avec la colonne cible.
- Glisser et déposer Classement widget à partir des données menu.
- Tracer une ligne de lien à partir de Sélectionner des colonnes widget au classement widget .
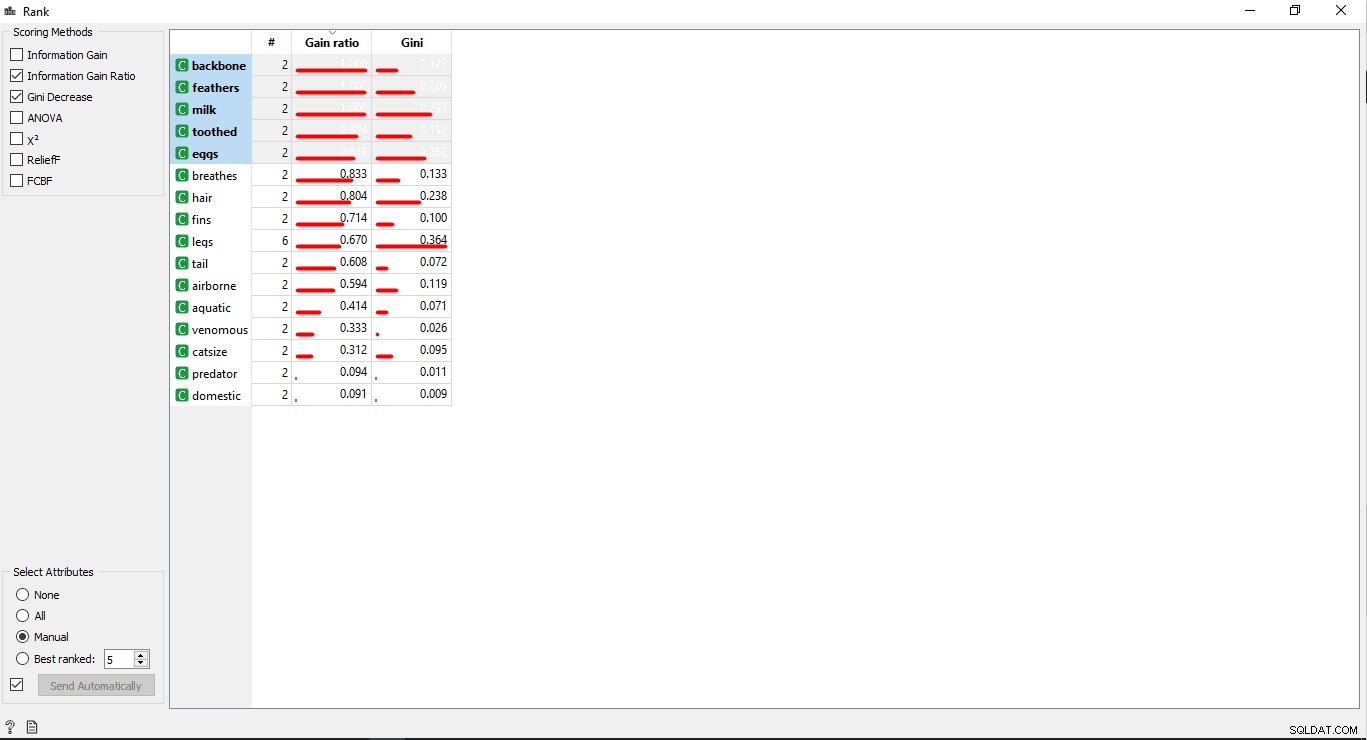
- Double-cliquez sur le Rang widget pour voir les colonnes les plus liées dans le tableau des données d'entraînement. Il sélectionnera les 5 premières colonnes par défaut.
Étape 7 :Entraînement aux données
Dans cette étape, le modèle d'apprentissage automatique (KNN) sera formé avec l'ensemble de données de formation. Veuillez suivre les étapes suivantes :
- Glisser et déposer KNN widget du modèle menu.
- Tracer une ligne de lien à partir du classement widget à KNN widget.
Étape 8 :Charger l'ensemble de données de test dans PostgreSQL
Un jeu de données de test distinct est créé pour effectuer des prédictions. Veuillez suivre les étapes pour charger l'ensemble de données de test dans la table PostgreSQL.
- Créer un tableau pour stocker nos données de test . Ici, il est nommé test_data.
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Insérez les données de test dans le tableau de test via COPIER requête. Avant d'exécuter COPIER Veuillez vous assurer que PostgreSQL a requis les autorisations de lecture sur le fichier de données, sinon l'opération COPY échouera.
REMARQUE : Assurez-vous de saisir une tabulation espace entre guillemets simples après le délimiteur mot-clé. Un point d'interrogation est intentionnellement placé dans le type colonne de l'ensemble de données de test, car nous devons déterminer le type d'un animal donné avec notre modèle d'apprentissage automatique.
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
Veuillez trouver la capture d'écran de l'ensemble de données de test ci-dessous

Étape 9 :Importez les données de test de PostgreSQL vers Orange
Veuillez suivre les étapes suivantes pour appliquer les prédictions.
- Glisser et déposer la table SQL widget à partir des données menu.
- Renommer le widget (facultatif)
- Cliquez avec le bouton droit sur la table SQL widget.
- Sélectionnez Renommer .
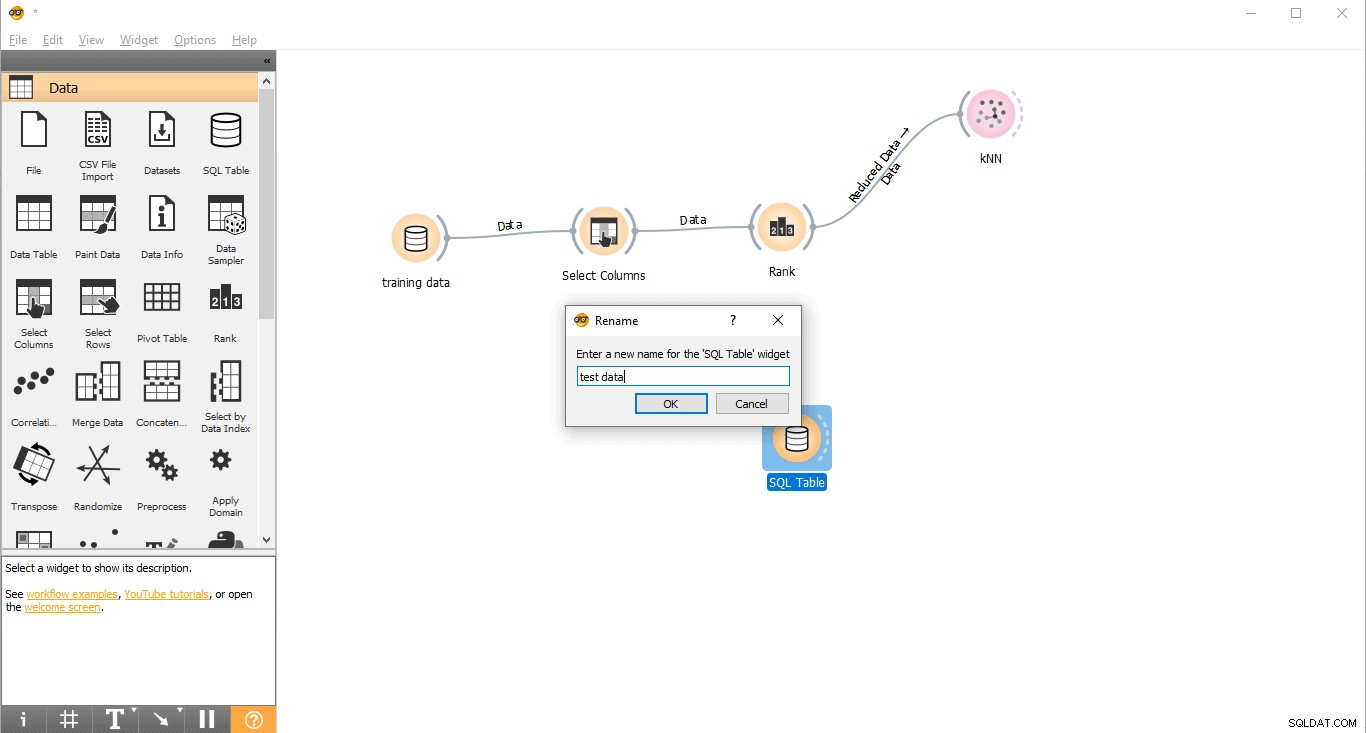
- Connectez-vous à PostgreSQL pour charger les données de test.
- Double-cliquez sur Données de test widget.
- Connectez-le avec des données de test table de PostgreSQL.
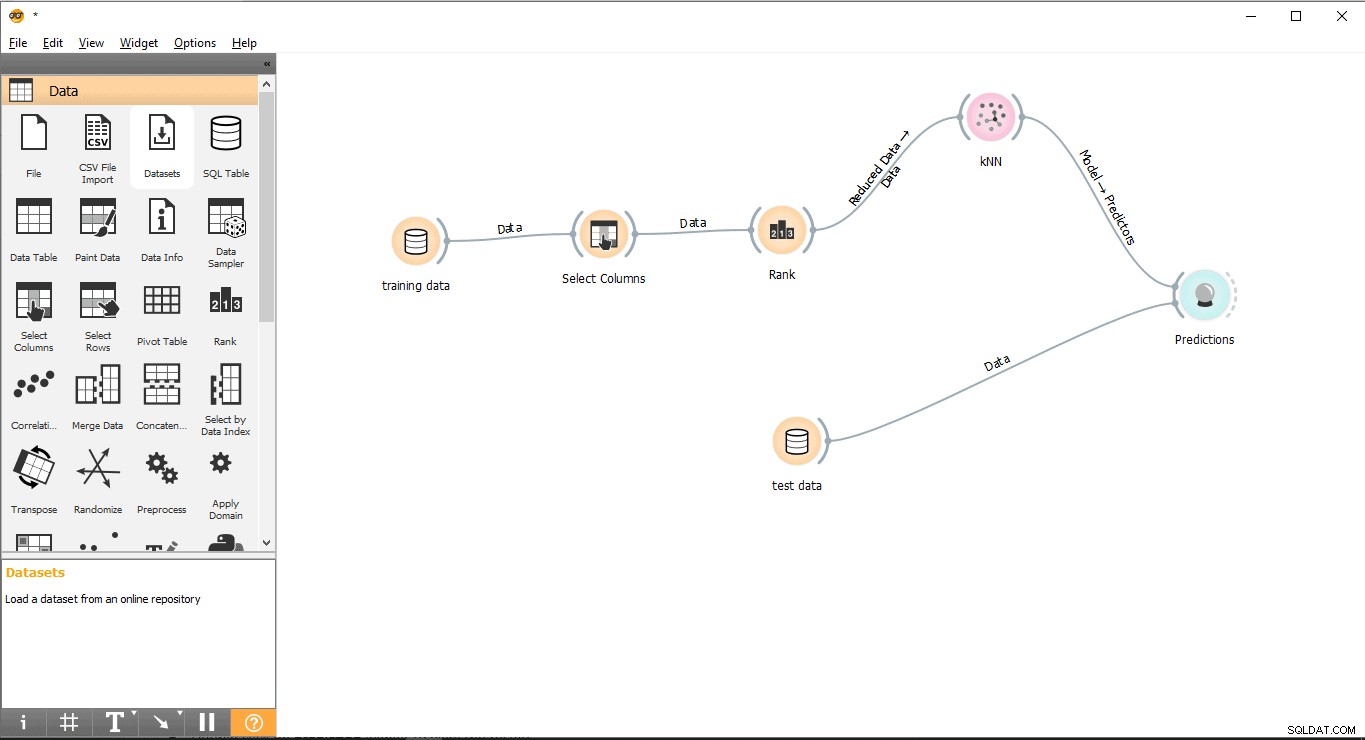
Nous sommes maintenant prêts à effectuer des prédictions.
Étape 10 : prédictions
Prédiction le widget essaiera de prédire les données de test en fonction des données d'entraînement de KNN .
- Glisser et déposer Prédiction widget du Évaluer menu.
- Dessiner une ligne de lien sous forme de données de test widget à Prédiction widget.
- Tracer une ligne de liaison à partir de KNN widget à Prédiction widget.
Étape 11 :Résultats
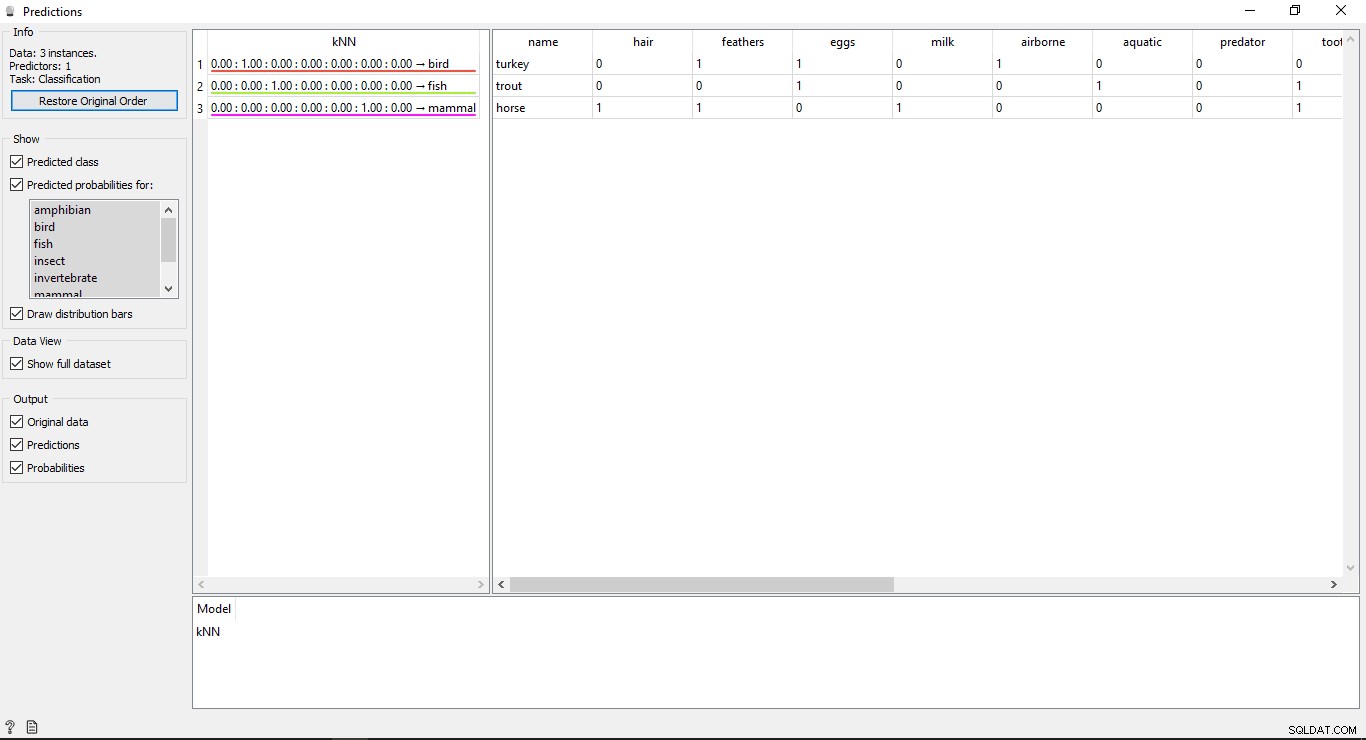
Double-cliquez sur Prédiction widget pour afficher les résultats.
Comprendre les résultats
Vous verrez 2 tableaux principaux dans la fenêtre de prédiction. Le tableau de gauche montre les résultats prédits, tandis que le tableau de droite montre les données de test d'origine, qui ont été fournies pour les prédictions.
Depuis le KNN modèle a été utilisé pour entraîner les données, vous verrez donc une colonne nommée KNN qui liste les résultats.
Comme nous le savons :
- Cheval est un mammifère
- Truite est un poisson
- Turquie est un oiseau
KNN est donc capable de déterminer correctement tous les types.
Précision des prévisions
Si vous voyez le tableau sur le côté gauche de la sortie du widget de prédiction, il contient des nombres avant le type prédit, c'est-à-dire 1,00. 0,00 Ces nombres indiquent la précision du type prédit.
Nous avons utilisé 7 types d'animaux dans l'ensemble de données d'entraînement, il affiche donc un nombre total de 7 colonnes avec des valeurs de précision, chaque colonne représentant 1 type d'animal. Vous pouvez vérifier quelle colonne représente quel type d'animal en consultant la liste disponible sur le côté gauche de votre écran sous Probabilités prédites pour étiqueter. Si vous regardez la première ligne qui indique Turquie est un oiseau . Nous pouvons voir que sa précision est de 1,00 (100 % à partir de la 2e colonne). Il en va de même pour les autres exemples Truite est un poisson et sa précision est de 1,00 (100 % à partir de la 3e colonne).
Dans cet article, nous avons utilisé l'algorithme des k plus proches voisins (KNN) pour implémenter le modèle d'apprentissage automatique. Dans le prochain blog, nous utiliserons la Support Vector Machine (SVM).
Pour toute question ou commentaire, veuillez nous contacter en utilisant le formulaire de contact ici.