La base de données est un élément essentiel et vital de toute entreprise ou organisation. Les tendances croissantes prédisent que 82 % des entreprises s'attendent à ce que le nombre de bases de données augmente au cours des 12 prochains mois. Un défi majeur de chaque DBA est de découvrir comment faire face à la croissance massive des données, et cela va être un objectif des plus importants. Comment pouvez-vous augmenter les performances de la base de données, réduire les coûts et éliminer les temps d'arrêt pour offrir à vos utilisateurs la meilleure expérience possible ? La compression des données est-elle une option ? Commençons et voyons comment certaines des fonctionnalités existantes peuvent être utiles pour gérer de telles situations.
Dans cet article, nous allons apprendre comment la solution de compression des données peut nous aider à optimiser la solution de gestion des données. Dans ce guide, nous aborderons les sujets suivants :
- Un aperçu de la compression
- Avantages de la compression
- Un aperçu des techniques de compression des données
- Discussion sur les différents types de compression de données
- Faits sur la compression des données
- Considérations relatives à la mise en œuvre
- et plus…
Compression
La compression est une technique et, par conséquent, une opération sensible aux ressources, mais avec des compromis matériels. Il faut penser à déployer la compression des données pour les bénéfices suivants :
- Gestion efficace de l'espace
- Technique efficace de réduction des coûts
- Facilité de gestion des sauvegardes de base de données
- Utilisation efficace de la bande passante N/O
- Récupération ou restauration sûre et plus rapide
- Meilleures performances :réduit l'empreinte mémoire du système
Remarque : Si SQL Server est limité par le processeur ou la mémoire, la compression peut ne pas convenir à votre environnement.
La compression des données s'applique à :
- Tas
- Index clusterisés
- Index non clusterisés
- Partitions
- Vues indexées
Remarque : Les objets volumineux ne sont pas compressés (par exemple, LOB et BLOB)
Idéal pour les applications suivantes :
- Tableaux de journaux
- Tableaux d'audit
- Tableaux de faits
- Rapport
Présentation
La compression des données est une technologie qui existe depuis SQL Server 2008. L'idée de la compression des données est que vous pouvez choisir de manière sélective des tables, des index ou des partitions dans une base de données. Les E/S continuent d'être un goulot d'étranglement dans le déplacement des informations entre l'entrée et la sortie de la base de données. La compression des données tire parti de ce type et contribue à augmenter l'efficacité d'une base de données. Comme nous savons que les vitesses du réseau sont beaucoup plus lentes que la vitesse de traitement, il est possible de trouver des gains d'efficacité en utilisant la puissance de traitement pour compresser les données dans une base de données, afin qu'elles se déplacent plus rapidement. Et puis utilisez à nouveau la puissance de traitement pour décompresser les données à l'autre bout. En général, la compression des données réduit l'espace occupé par les données. La technique de compression des données est disponible pour chaque base de données et est prise en charge par toutes les éditions de SQL Server 2016 SP1. Auparavant, il n'était disponible que sur les éditions SQL Server Enterprise ou Developer, pas sur Standard ou Express.
Prise en charge des fonctionnalités

Types de compression de données
Il existe deux types de compression de données disponibles dans SQL Server, au niveau de la ligne et au niveau de la page.
La compression au niveau des lignes fonctionne en arrière-plan et convertit tous les types de données de longueur fixe en types de longueur variable. L'hypothèse ici est que souvent les données sont stockées dans un type de longueur fixe, tel que char 100, et elles ne remplissent pas réellement les 100 caractères entiers pour chaque enregistrement. De petits gains peuvent être obtenus en supprimant cet espace supplémentaire de la table. Bien sûr, si vos tables de données n'utilisent pas de champs texte et numériques de longueur fixe, ou si elles le font et que vous stockez réellement le nombre entièrement autorisé de caractères et de chiffres, alors les gains de compression sous le schéma au niveau de la ligne seront minimes. au mieux.
Le concept de compression est étendu à tous les types de données de longueur fixe, y compris char, int et float. SQL Server permet d'économiser de l'espace en stockant les données comme s'il s'agissait d'un type de taille variable; les données apparaîtront et se comporteront comme une longueur fixe.
Par exemple, si vous stockez la valeur de 100 dans un int colonne, le serveur SQL n'a pas besoin d'utiliser tous les 32 bits, à la place, il utilise simplement 8 bits (1 octet).
La compression au niveau de la page amène les choses à un autre niveau. Tout d'abord, il applique automatiquement la compression au niveau des lignes sur les champs de données de longueur fixe, de sorte que vous obtenez automatiquement ces gains par défaut. Ensuite, en plus de cela, il applique quelque chose appelé compression de préfixe et une autre technique appelée compression de dictionnaire.
Compression de lignes
La compression de ligne est un niveau interne de compression qui stocke les chaînes de caractères fixes en utilisant un format de longueur variable en ne stockant pas les caractères vides. Les étapes suivantes sont effectuées dans la compression au niveau de la ligne.
- Tous les types de données numériques comme int , flotter , décimal, et l'argent sont convertis en types de données de longueur variable. Par exemple, 125 stocké dans la colonne et le type de données de la colonne est un entier. Ensuite, nous savons que 4 octets sont utilisés pour stocker la valeur entière. Mais 125 peut être stocké dans 1 octet car 1 octet peut stocker des valeurs de 0 à 255. Ainsi, 125 peut être stocké sous la forme d'un minuscule int , de sorte que 3 octets peuvent être enregistrés.
- Char et Nchar les types de données sont stockés sous forme de types de données de longueur variable. Par exemple, "SQL" est stocké dans un char (20) colonne de type. Mais après compression, seuls 3 octets seront utilisés. Après la compression des données, aucun caractère blanc n'est stocké avec ce type de données.
- Les métadonnées de l'enregistrement sont réduites.
- Les valeurs NULL et 0 sont optimisées et aucun espace n'est utilisé.
Compression de pages
La compression de page est un niveau avancé de compression de données. Par défaut, une compression de page implémente également la compression au niveau des lignes. La compression de page est classée en deux types
- Compression des préfixes et
- Compression du dictionnaire.
Compression de préfixe
Dans la compression de préfixe pour chaque page, pour chaque colonne de la page, une valeur commune est extraite de toutes les lignes et stockée sous l'en-tête de chaque colonne. Désormais, dans chaque ligne, une référence à cette valeur est stockée à la place de la valeur commune.
Compression du dictionnaire
La compression de dictionnaire est similaire à la compression de préfixe, mais les valeurs communes sont extraites de toutes les colonnes et stockées dans la deuxième ligne après l'en-tête. La compression du dictionnaire recherche les correspondances de valeurs exactes dans toutes les colonnes et lignes de chaque page.
Nous pouvons effectuer une compression au niveau des lignes et des pages pour les objets de base de données suivants.
- Une table stockée dans un tas.
- Une table entière stockée sous la forme d'un index clusterisé.
- Vue indexée.
- Index non clusterisé.
- Index et tables partitionnés.
Remarque : Nous pouvons effectuer la compression des données soit au moment de la création comme CREATE TABLE, CREATE INDEX ou après la création en utilisant la commande ALTER avec l'option REBUILD comme ALTER TABLE …. RECONSTRUIRE AVEC.
Démo
Les WideWorldImporters La base de données est utilisée tout au long de la démonstration. En outre, un DW en temps réel la base de données est prise en compte pour l'opération de compression.
Passons en revue les étapes en détail :
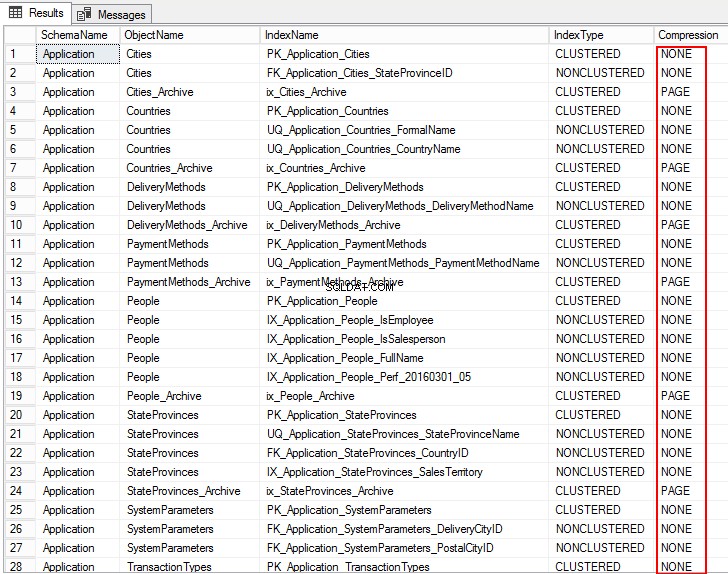
1. Pour afficher les paramètres de compression des objets de la base de données, exécutez le T-SQL suivant :
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
La sortie suivante montre le type de compression comme PAGE, ROW, et pour plusieurs tables c'est NONE. Cela signifie qu'il n'est pas configuré pour la compression.
2. Pour estimer la compression, exécutez la procédure stockée système suivante sp_estimate_data_compression_savings . Dans ce cas, la procédure stockée est exécutée sur les tables PurchaseOrderLines.
3. Découvrons le paramètre de compression PurchaseOrderLines en exécutant le T-SQL suivant :
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
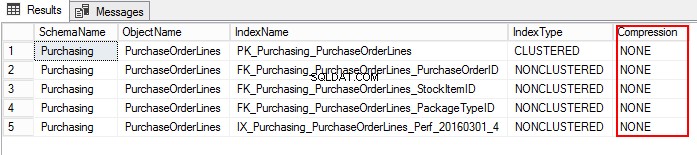
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

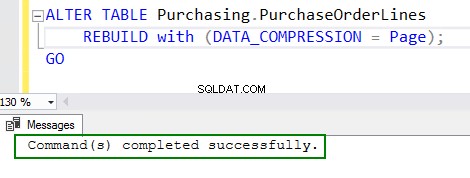
4. Activez la compression en exécutant la commande ALTER table :
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
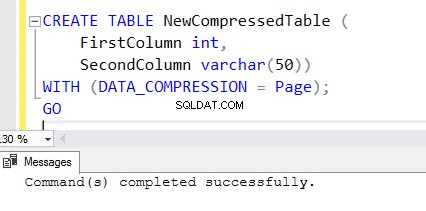
5. Pour créer une nouvelle table avec la fonctionnalité de compression activée, ajoutez la clause WITH à la fin de l'instruction CREATE TABLE. Vous pouvez voir l'instruction CREATE TABLE ci-dessous utilisée pour créer NewCompressedTable .
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
Faits sur la compression des données
Passons en revue certaines des informations réelles sur la compression
- La compression ne peut pas être appliquée aux tables système
- Une table ne peut pas être activée pour la compression lorsque la taille de la ligne dépasse 8 060 octets.
- Les données compressées sont mises en cache dans le pool de mémoire tampon ; cela signifie des temps de réponse plus rapides
- L'activation de la compression peut entraîner la modification des plans de requête, car les données sont stockées en utilisant un nombre de pages et un nombre de lignes par page différents.
- Les index non clusterisés n'héritent pas de la propriété de compression
- Lorsqu'un index clusterisé est créé sur un tas, l'index clusterisé hérite de l'état de compression du tas, sauf si un autre état de compression est spécifié.
- Les compressions de niveau ROW et PAGE peuvent être activées et désactivées, hors ligne ou en ligne.
- Si le paramètre de tas est modifié, tous les index non clusterisés doivent être reconstruits.
- L'espace disque requis pour activer ou désactiver la compression des lignes ou des pages est le même que pour créer ou reconstruire un index.
- Lorsque des partitions sont fractionnées à l'aide de l'instruction ALTER PARTITION, les deux partitions héritent de l'attribut de compression de données de la partition d'origine.
- Lorsque deux partitions sont fusionnées, la partition résultante hérite de l'attribut de compression de données de la partition de destination.
- Pour changer de partition, la propriété de compression des données de la partition doit correspondre à la propriété de compression de la table.
- Les tables et index Columnstore sont toujours stockés avec la compression Columnstore.
- La compression des données est incompatible avec les colonnes éparses, de sorte que le tableau ne peut pas être compressé.
Scénario en temps réel
Passons en revue la technique de compression des données et comprenons les paramètres clés de la compression des données.
Pour vérifier l'espace utilisé par chaque table, exécutez le T-SQL suivant. La sortie de la requête nous donne des informations détaillées sur l'utilisation de chaque table. Ce serait le facteur décisif pour la mise en œuvre de la compression des données.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
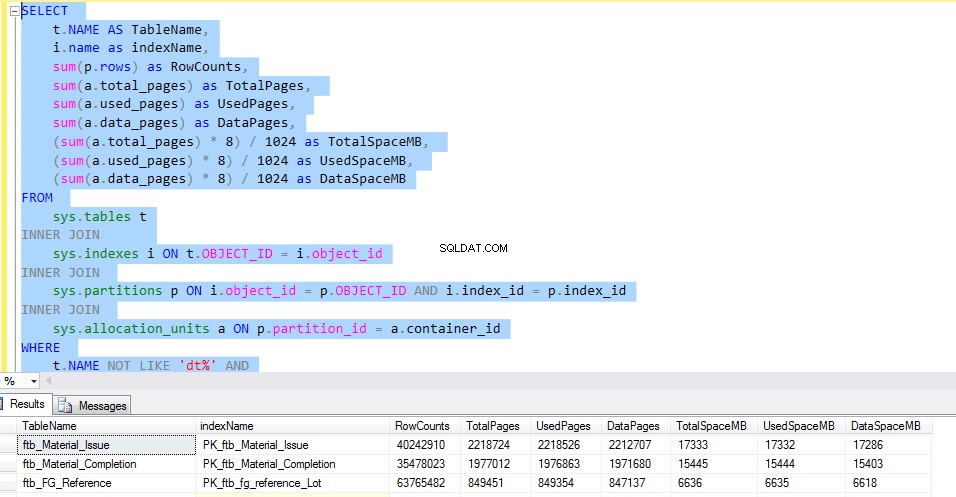
Considérons le ftb_material_Issue table de faits. La table de faits a des types de données numériques BIGINT.
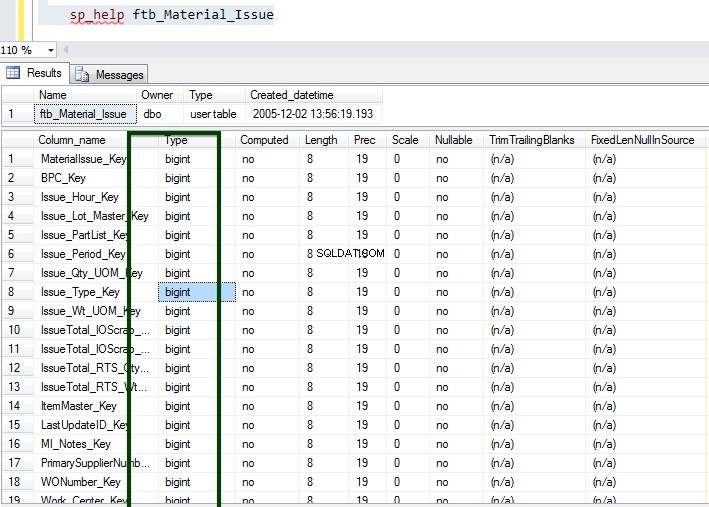
Maintenant, exécutez la procédure stockée sp_spaceused pour comprendre les détails de la table. Vous pouvez en savoir plus sur la commande sp_spaceused ici.
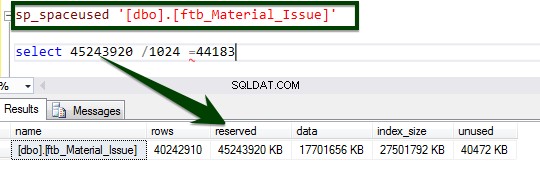
Activez la compression au niveau de la table en exécutant le T-SQL suivant. Le T-SQL suivant a été exécuté sur le serveur et il a fallu 34 minutes 14 secondes pour compresser la page au niveau de la table.
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
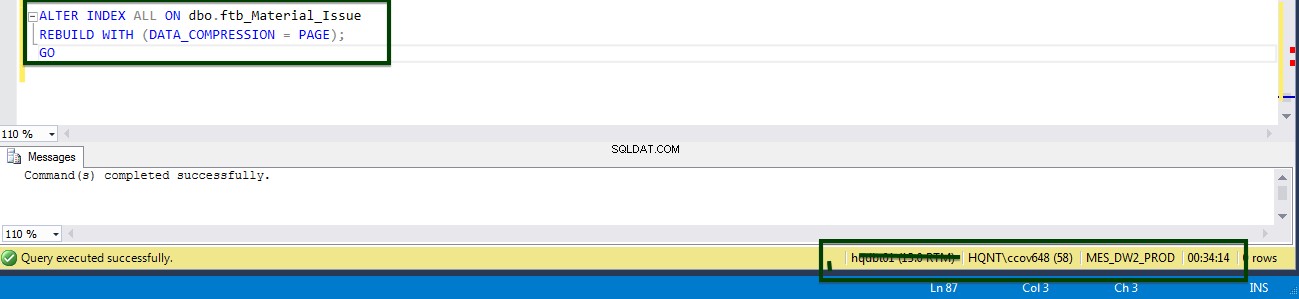
Vous pouvez voir les fluctuations du CPU et des E/S pendant l'exécution de la commande ALTER table.
Maintenant, faisons la comparaison Avant vs Après la compression des données. La taille de la table d'environ ~45 Go est ramenée à ~15 Go.
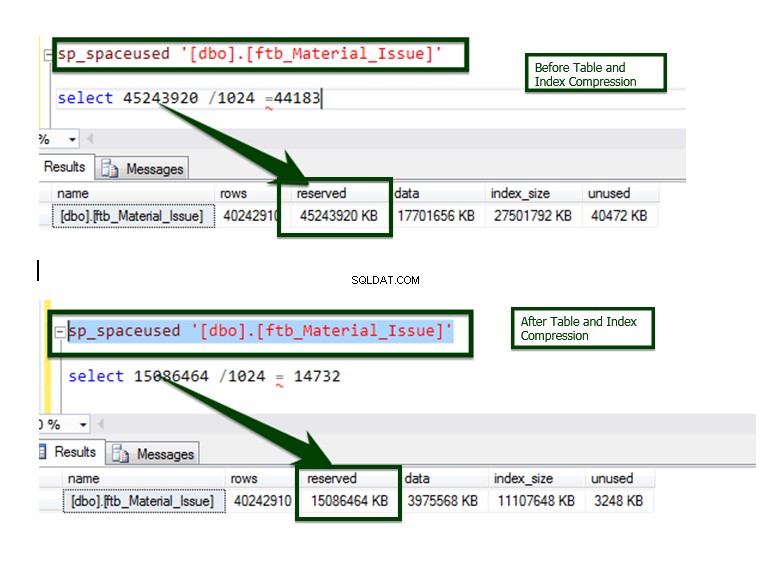
Le processus est mis en œuvre sur la plupart des objets à l'aide d'un script automatisé et voici le résultat final de la comparaison.
Comparaison des données entre Avant et Après l'opération de compression de l'index.

Résumé
La compression des données est une technique très efficace pour réduire la taille des données; les données réduites nécessitent moins de processus d'E/S. L'ajout de la compression à la base de données augmente la charge sur les exigences du processeur. Vous devrez vous assurer que vous disposez de la capacité de traitement disponible pour s'adapter à ces changements de manière efficace. Il est donc préférable de faire d'abord une petite recherche et de voir les types de gains auxquels on peut s'attendre avant d'appliquer les modifications pour permettre la compression des données. C'est très avantageux dans la configuration de la base de données cloud où le coût est impliqué.
Organisez les compressions (ne les faites pas toutes en même temps) et compressez pendant les périodes de faible activité. La compression des données et la compression des sauvegardes coexistent parfaitement et peuvent entraîner des économies d'espace de stockage supplémentaires, alors n'hésitez plus et faites-vous plaisir.
Non seulement la compression réduit la taille des fichiers physiques, mais elle réduit également les E/S de disque, ce qui peut considérablement améliorer les performances de nombreuses applications de base de données, ainsi que les sauvegardes de base de données.
Décider d'implémenter la compression est plus facile si nous connaissons l'infrastructure sous-jacente et les exigences métier. Nous pouvons certainement utiliser la procédure système disponible pour comprendre et estimer les économies de compression. Cette procédure stockée ne fournit aucun détail indiquant comment la compression affectera positivement ou négativement votre système. Il est évident qu'il existe des compromis à toute sorte de compression. Si vous avez les mêmes modèles de données volumineuses, la compression est la clé pour économiser de l'espace. Avec l'augmentation de la puissance du processeur et chaque système lié à des structures à plusieurs cœurs, la compression peut convenir à de nombreux systèmes. Je recommanderais de tester vos systèmes. Testez pour vous assurer que les performances ne sont pas affectées négativement. Si un index comporte de nombreuses mises à jour et suppressions, le coût du processeur pour compresser et décompresser les données peut dépasser les économies d'E/S et de RAM résultant de la compression des données. Toutes les bases de données ou tables ne seront pas automatiquement un bon candidat pour appliquer la compression, il est donc préférable de faire d'abord une petite recherche pour voir les types de gains qui peuvent être attendus avant d'appliquer les modifications pour activer la compression des données sur vos bases de données. Vous devez tester la compression pour voir si elle fonctionne bien dans votre environnement, car elle peut ne pas fonctionner correctement dans les bases de données à insertion intensive.
Références
Éditions et fonctionnalités prises en charge de SQL Server 2016
Compression des données
Implémentation de la compression de lignes
Implémentation de la compression de page