Les index SQL Server sont utilisés pour accélérer la récupération des données et réduire les goulots d'étranglement affectant les ressources critiques. Les index sur une table de base de données servent de technique d'optimisation des performances. Vous vous demandez peut-être comment les index augmentent-ils les performances des requêtes ? Existe-t-il de bons et de mauvais index ? Supposons que vous ayez une table de 50 colonnes, est-ce une bonne idée de créer des index sur chacune des colonnes ? Si nous créons plusieurs index, cela aide-t-il les requêtes SQL à s'exécuter plus rapidement ?
Toutes de bonnes questions, mais avant de plonger dans le vif du sujet, il est essentiel de savoir pourquoi les index peuvent être nécessaires en premier lieu.
Imaginez que vous visitez une bibliothèque municipale qui possède une collection de milliers de livres. Vous cherchez un livre en particulier, mais comment allez-vous le trouver ? Si vous parcouriez chaque livre, dans chaque casier, cela pourrait prendre des jours pour le trouver. Il en va de même pour une base de données lorsque vous recherchez un enregistrement parmi les millions de lignes stockées dans une table.
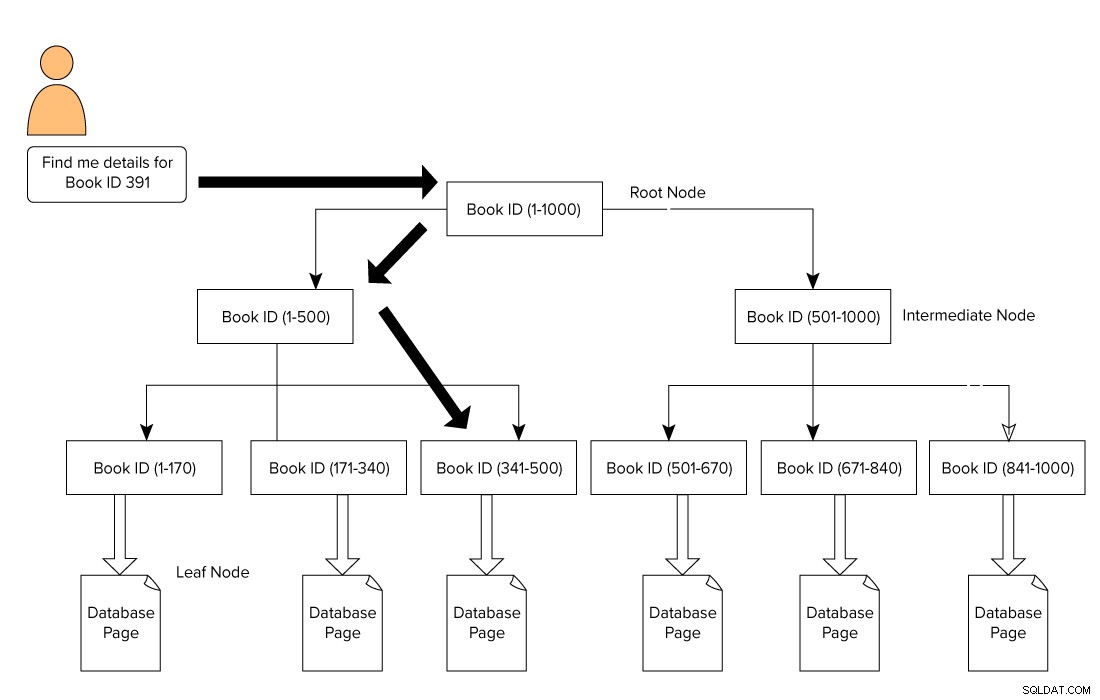
Un index SQL Server prend la forme d'un format B-Tree qui se compose d'un nœud racine en haut et d'un nœud feuille en bas. Pour notre exemple de livres de bibliothèque, un utilisateur émet une requête pour rechercher un livre avec l'ID 391. Dans ce cas, le moteur de requête commence à traverser le nœud racine et se déplace vers le nœud feuille.
Nœud racine – > Nœud intermédiaire – > Nœud feuille.
Le moteur de recherche recherche la page de référence dans le niveau intermédiaire. Dans cet exemple, le premier nœud intermédiaire se compose d'ID de livre de 1 à 500 et le deuxième nœud intermédiaire se compose de 501 à 1000.
Sur la base du nœud intermédiaire, le moteur de requête parcourt le B-Tree pour rechercher le nœud intermédiaire correspondant et le nœud feuille. Ce nœud feuille peut être constitué de données réelles ou pointer vers la page de données réelles en fonction du type d'index. Dans l'image ci-dessous, nous voyons comment parcourir l'index pour rechercher des données à l'aide des index SQL Server. Dans ce cas, SQL Server n'a pas besoin de parcourir chaque page, de la lire et de rechercher un contenu d'ID de livre spécifique.
Impacts des index sur les performances de SQL Server
Dans l'exemple de bibliothèque précédent, nous avons examiné les impacts potentiels sur les performances de l'index. Examinons les performances des requêtes avec et sans index.
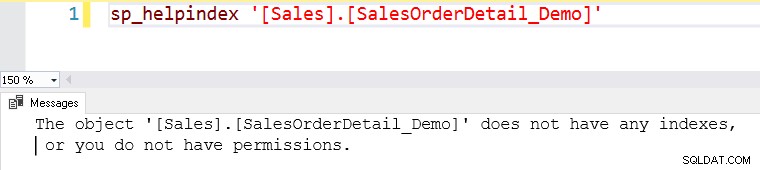
Supposons que nous ayons besoin de données pour le [SalesOrderID] 56958 de la table [SalesOrderDetail_Demo].
SÉLECTIONNER *
À PARTIR DE [AdventureWorks].[Sales].[SalesOrderDetail_Demo]
où SalesOrderID=56958
Cette table ne contient aucun index. Une table sans index est appelée une table de tas dans SQL Server.
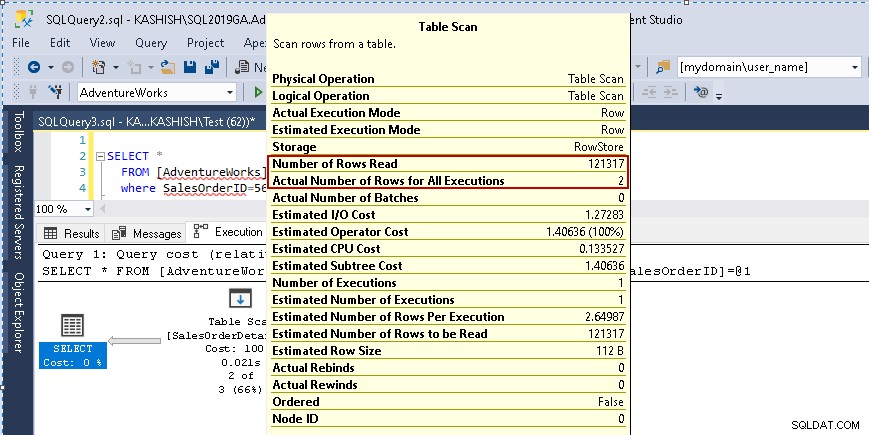
À partir de là, vous souhaiterez exécuter l'instruction select ci-dessus et afficher le plan d'exécution réel. Cette table contient 121317 enregistrements. Il effectue une analyse de table, ce qui signifie qu'il lit toutes les lignes d'une table pour trouver le [SalesOrderID] spécifique.
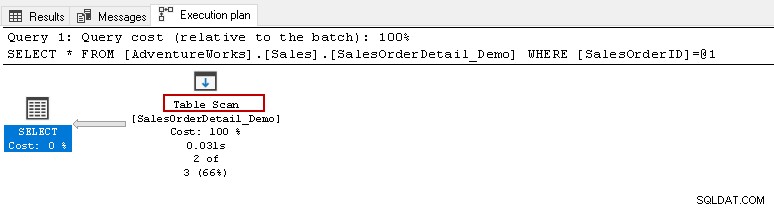
Lorsque vous passez votre curseur sur l'icône Analyse de table, cela montre que le jeu de résultats réel contient 2 lignes, mais à cette fin, il lit toutes les lignes de cette table.
- Nombre de lignes lues :121 317
- Le nombre réel de lignes pour l'exécution :2
Maintenant, pensez à une table avec des millions ou des milliards de lignes. Il n'est pas recommandé de parcourir tous les enregistrements de la table pour filtrer quelques lignes. Dans un système de base de données de traitement de transactions en ligne (OLTP) étendu, il n'utilise pas efficacement les ressources du serveur (CPU, IO, mémoire), par conséquent, l'utilisateur peut être confronté à des problèmes de performances.
Maintenant, exécutons l'instruction select ci-dessus avec la table ayant des index. Cette table comporte un index clusterisé de clé primaire et deux index non clusterisés sur les colonnes [ProductID] et [rowguid]. Nous parlerons plus tard des différents types d'index dans SQL Server.
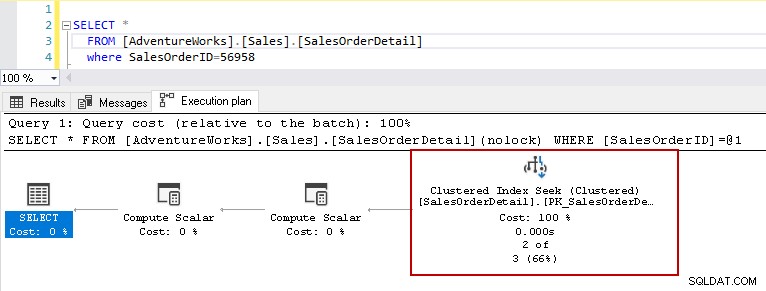
Désormais, si vous réexécutez l'instruction select avec le même prédicat, le plan d'exécution affiche le problème de performances. L'optimiseur de requête décide d'utiliser la recherche d'index clusterisé à la place d'une analyse d'index clusterisé.
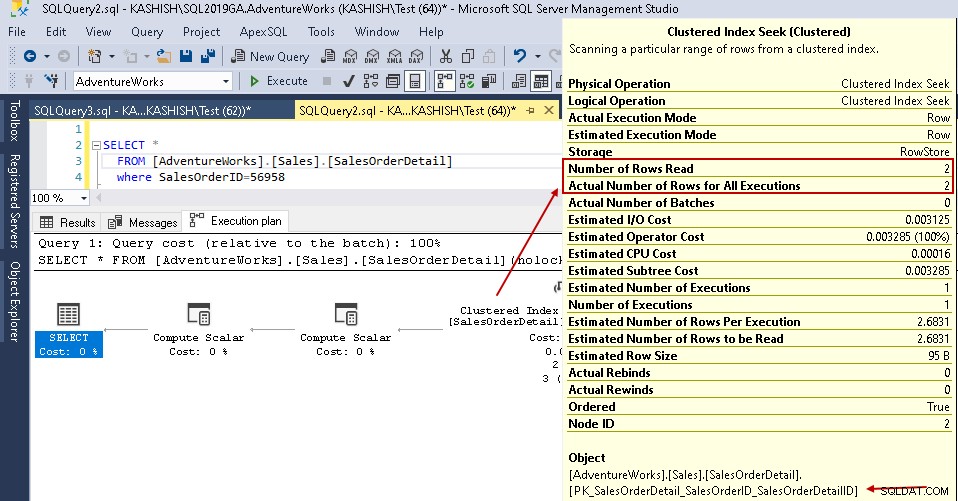
Dans les détails de la recherche d'index clusterisé, il montre que l'optimiseur de requête lit précisément les lignes qu'il a fournies dans la sortie.
Pour vous fournir une analyse comparative, comparons le plan d'exécution avec et sans index SQL Server. Vous pouvez consulter l'article Comment comparer les plans d'exécution des requêtes dans SQL Server 2016 de SQL Shack pour plus d'informations.
Pour cet exemple, examinez les valeurs en surbrillance dans la recherche d'index clusterisé et l'analyse de table :
- Lectures logiques :le moteur de base de données SQL Server lit une page à partir du cache de tampon et provoque une lecture logique. Ci-dessous, nous voyons que les lectures logiques sont réduites de 1715 à 3 une fois que vous avez créé l'index.
- Le coût CPU estimé passe également de 0,133527 à 0,00016
- Le coût estimé des OI passe de 1,27283 à 0,003125
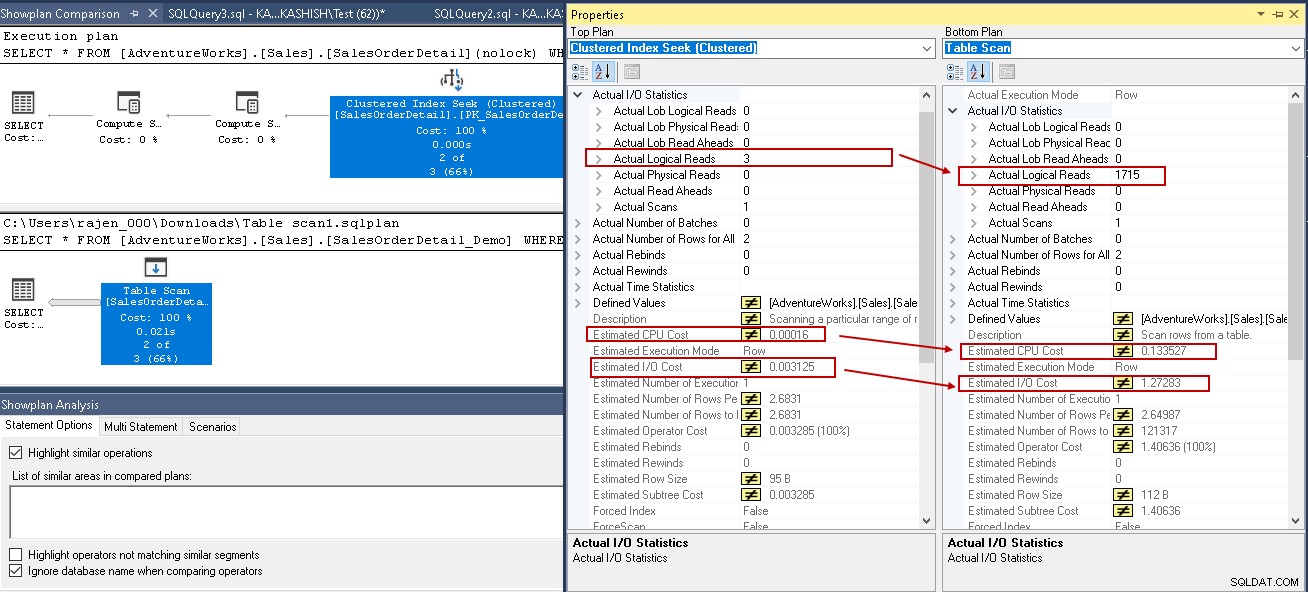
L'image ci-dessous montre une différence entre une analyse de table et une recherche d'index.
Bons index (utiles) et mauvais index dans SQL Server
Comme son nom l'indique, un bon index améliore les performances des requêtes et minimise l'utilisation des ressources. Un index peut-il réduire les performances des requêtes dans SQL Server ? Parfois, nous créons l'index sur une colonne spécifique, mais il n'est jamais utilisé. Supposons que vous ayez un index sur une colonne et que vous effectuiez de nombreuses insertions et mises à jour pour cette colonne. Pour chaque mise à jour, la mise à jour de l'index correspondant est également requise. Si votre charge de travail a plus d'activité d'écriture et que vous avez de nombreux index sur une colonne, cela ralentirait les performances globales de vos requêtes. Un index inutilisé peut également ralentir les performances des instructions select. L'optimiseur de requête utilise des statistiques pour créer un plan d'exécution. Il lit tous les index et leur échantillonnage de données, et sur cette base, il construit un plan d'exécution de requête optimisé. Vous pouvez suivre l'utilisation de votre index à l'aide de la vue de gestion dynamique sys.dm_db_index_usage_stats et surveiller les ressources, telles que l'analyse des utilisateurs, les recherches d'utilisateurs et les recherches d'utilisateurs.
Types d'index SQL Server et considérations
SQL Server possède deux index principaux :les index clusterisés et non clusterisés. Un index clusterisé stocke les données réelles dans le nœud feuille de l'index. Il trie physiquement les données dans les pages de données en fonction de la clé d'index clusterisé. SQL Server autorise un index clusterisé par table. Vous pouvez joindre plusieurs colonnes pour créer une clé d'index clusterisé. Un index non clusterisé est un index logique et sa colonne de clé d'index pointe vers la clé d'index clusterisée.
Nous pouvons également avoir d'autres index dans SQL Server, tels que l'index XML, l'index du magasin de colonnes, l'index spatial, l'index de texte intégral, l'index de hachage, etc.
Vous devez tenir compte des points suivants avant de créer un index dans SQL Server :
- Charge de travail
- La colonne sur laquelle l'index est requis
- Taille du tableau
- Ordre croissant ou décroissant des données de la colonne
- Ordre des colonnes
- Type d'index
- Facteur de remplissage, index de remplissage et ordre de tri TempDB
Avantages, implications et recommandations de l'index SQL Server
Les index dans une base de données peuvent être une arme à double tranchant. Un index SQL Server utile améliore la requête et les performances du système sans affecter les autres requêtes. D'autre part, si vous créez un index sans aucune préparation ni considération, cela peut entraîner des dégradations des performances, ralentir la récupération des données et consommer des ressources plus critiques telles que le processeur, les E/S et la mémoire. Les index augmentent également les tâches de maintenance de votre base de données. En gardant ces facteurs à l'esprit, il est toujours préférable de tester un index approprié dans un environnement de pré-production avec la charge de travail équivalente à la production, puis d'analyser les performances et de décider s'il est préférable de l'implémenter sur une base de données de production. Il existe de nombreuses autres recommandations à prendre en compte. Consultez mes 11 meilleures pratiques d'indexation pour plus d'informations.