L'importance du basculement
Le basculement est l'une des pratiques de base de données les plus importantes pour la gouvernance des bases de données. C'est utile non seulement lors de la gestion de grandes bases de données en production, mais aussi si vous voulez être sûr que votre système est toujours disponible chaque fois que vous y accédez, en particulier au niveau de l'application.
Avant qu'un basculement puisse avoir lieu, vos instances de base de données doivent répondre à certaines exigences. Ces exigences sont en fait très importantes pour la haute disponibilité. L'une des exigences que vos instances de base de données doivent respecter est la redondance. La redondance permet au basculement de se poursuivre, dans lequel la redondance est configurée pour avoir un candidat au basculement qui peut être un nœud de réplique (secondaire) ou à partir d'un pool de répliques agissant comme des nœuds de secours ou de secours à chaud. Le candidat est sélectionné manuellement ou automatiquement en fonction du nœud le plus avancé ou le plus à jour. Habituellement, vous voudriez une réplique de secours à chaud car elle peut éviter à votre base de données d'extraire des index du disque car un secours à chaud remplit souvent les index dans le pool de mémoire tampon de la base de données.
Le basculement est le terme utilisé pour décrire qu'un processus de récupération a eu lieu. Avant le processus de récupération, cela se produit lorsqu'un nœud de base de données principal (ou maître) tombe en panne après une panne, après une catastrophe naturelle, après une panne matérielle ou s'il a subi un partitionnement du réseau ; ce sont les cas les plus courants pour lesquels un basculement peut avoir lieu. Le processus de récupération se déroule généralement automatiquement, puis recherche le secondaire (réplique) le plus souhaité et le plus à jour, comme indiqué précédemment.
Basculement avancé
Bien que le processus de récupération lors d'un basculement soit automatique, il existe certaines occasions où il n'est pas nécessaire d'automatiser le processus et un processus manuel doit prendre le relais. La complexité est souvent la principale considération associée aux technologies qui composent l'ensemble de votre base de données ; le basculement automatique peut également être associé à un basculement manuel.
Dans la plupart des considérations quotidiennes liées à la gestion des bases de données, la majorité des préoccupations concernant le basculement automatique ne sont vraiment pas anodines. Il est souvent pratique d'implémenter et de configurer un basculement automatique en cas de problème. Bien que cela semble prometteur car il couvre les complexités, il y a les mécanismes de basculement avancés et cela implique des événements "pré" et des événements "post" qui sont liés comme des crochets dans un logiciel ou une technologie de basculement.
Ces événements avant et après proposent soit des vérifications, soit certaines actions à effectuer avant de pouvoir enfin procéder au basculement, et une fois le basculement effectué, quelques nettoyages pour s'assurer que le basculement est enfin réussi une. Heureusement, il existe des outils disponibles qui permettent non seulement le basculement automatique, mais également la capacité d'appliquer des hooks pré et post-script.
Dans ce blog, nous utiliserons le basculement automatique de ClusterControl (CC) et expliquerons comment utiliser les hooks pré et post-script et à quel cluster s'appliquent-ils.
Basculement de réplication ClusterControl
Le mécanisme de basculement ClusterControl est efficacement applicable sur la réplication asynchrone qui s'applique aux variantes MySQL (MySQL/Percona Server/MariaDB). Il s'applique également aux clusters PostgreSQL/TimescaleDB - ClusterControl prend en charge la réplication en continu. Les clusters MongoDB et Galera ont leur propre mécanisme de basculement automatique intégré à leur propre technologie de base de données. En savoir plus sur la façon dont le ClusterControl effectue la récupération et le basculement automatiques de la base de données.
Le basculement de ClusterControl ne fonctionne que si la récupération de nœud et de cluster (la récupération automatique est activée). Cela signifie que ces boutons doivent être verts.

La documentation indique que ces options de configuration peuvent également être utilisées pour activer / désactiver les éléments suivants :
| enable_cluster_autorecovery= |
|
| enable_node_autorecovery= |
|
$ systemctl restart cmon
Pour ce blog, nous nous concentrons principalement sur l'utilisation des crochets de script pré/post, ce qui est essentiellement un grand avantage pour le basculement de réplication avancé.
Prise en charge du script de réplication de basculement de cluster avant/après
Comme mentionné précédemment, les variantes de MySQL qui utilisent la réplication asynchrone (y compris semi-synchrone) et la réplication en continu pour PostgreSQL/TimescaleDB prennent en charge ce mécanisme. ClusterControl a les options de configuration suivantes qui peuvent être utilisées pour les hooks pré et post script. Fondamentalement, ces options de configuration peuvent être définies via leurs fichiers de configuration ou via l'interface utilisateur Web (nous traiterons de cela plus tard).
Notre documentation indique que ce sont les options de configuration suivantes qui peuvent modifier le mécanisme de basculement en utilisant les crochets de script pré/post :
| replication_pre_failover_script= |
|
| replication_post_failover_script= |
|
| replication_post_unsuccessful_failover_script= |
|
Techniquement, une fois que vous avez défini les options de configuration suivantes dans votre fichier de configuration /etc/cmon.d/cmon_
$ systemctl restart cmonVous pouvez également définir les options de configuration en accédant à
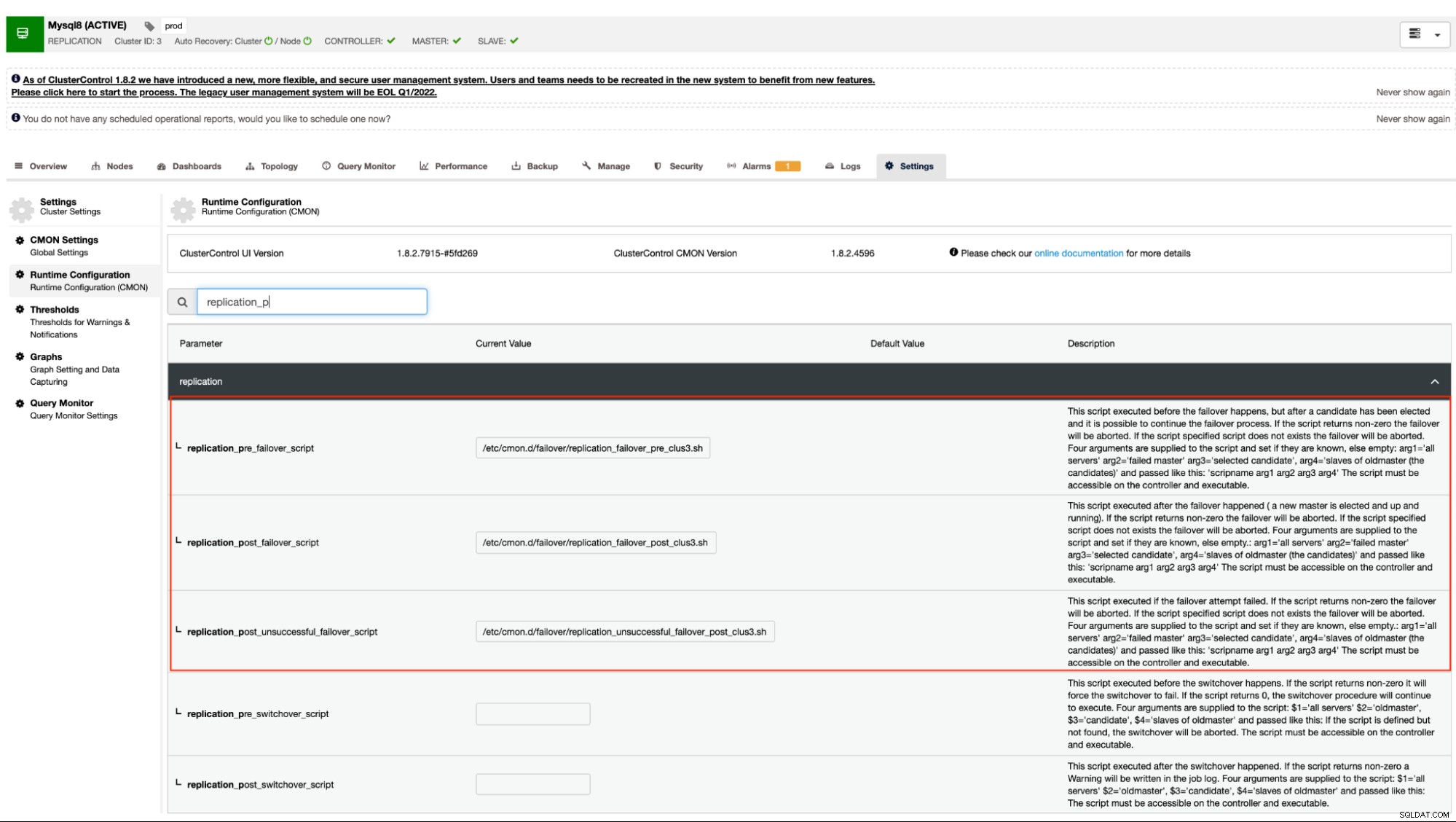
Cette approche nécessiterait toujours un redémarrage du service cmon avant de pouvoir refléter le modifications apportées à ces options de configuration pour les hooks pré/post script.
Exemple de hooks pré/post script
Idéalement, les hooks pré/post script sont dédiés lorsque vous avez besoin d'un basculement avancé pour lequel ClusterControl n'a pas pu gérer la complexité de la configuration de votre base de données. Par exemple, si vous exploitez différents centres de données avec une sécurité renforcée et que vous souhaitez déterminer si l'alerte indiquant que le réseau est inaccessible n'est pas une fausse alarme positive. Il doit vérifier si le primaire et l'esclave peuvent se joindre et vice versa et il peut également atteindre les nœuds de la base de données allant à l'hôte ClusterControl.
Faisons-le dans notre exemple et montrons comment vous pouvez en bénéficier.
Les détails du serveur et les scripts
Dans cet exemple, j'utilise un cluster de réplication MariaDB avec juste un primaire et un réplica. Géré par ClusterControl pour gérer le basculement.
ClusterControl =192.168.40.110
primaire (debnode5) =192.168.30.50
réplica (debnode9) =192.168.30.90
Dans le nœud principal, créez le script comme indiqué ci-dessous,
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"Assurez-vous que /opt/pre_failover.sh est exécutable, c'est-à-dire
$ chmod +x /opt/pre_failover.shUtilisez ensuite ce script pour être impliqué via cron. Dans cet exemple, j'ai créé un fichier /etc/cron.d/ccfailover et j'ai le contenu suivant :
example@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shDans votre réplica, utilisez simplement les étapes suivantes que nous avons effectuées pour le principal, à l'exception du changement de nom d'hôte. Voir ce que j'ai ci-dessous dans ma réplique :
example@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"et assurez-vous que le script invoqué dans notre cron est exécutable,
example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shScripts pré/post ClusterControl
Dans cette démonstration, mon cluster_id est 3. Comme indiqué précédemment dans notre documentation, il faut que ces scripts résident dans notre hôte de contrôleur CC. Donc dans mon /etc/cmon.d/cmon_3.cnf, j'ai ceci :
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.shAlors que le script de basculement "pré" suivant détermine si les deux nœuds ont pu atteindre l'hôte du contrôleur CC. Voir ce qui suit :
[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txt
Démo du basculement
Maintenant, essayons de simuler une panne de réseau sur le nœud principal et voyons comment il réagira. Dans mon nœud principal, je supprime l'interface réseau utilisée pour communiquer avec la réplique et le contrôleur CC.
example@sqldat.com:~# ip link set enp0s8 downLors de la première tentative de basculement, CC a pu exécuter mon pré-script qui se trouve dans /etc/cmon.d/failover/replication_failover_pre_clus3.sh. Voir ci-dessous comment cela fonctionne :
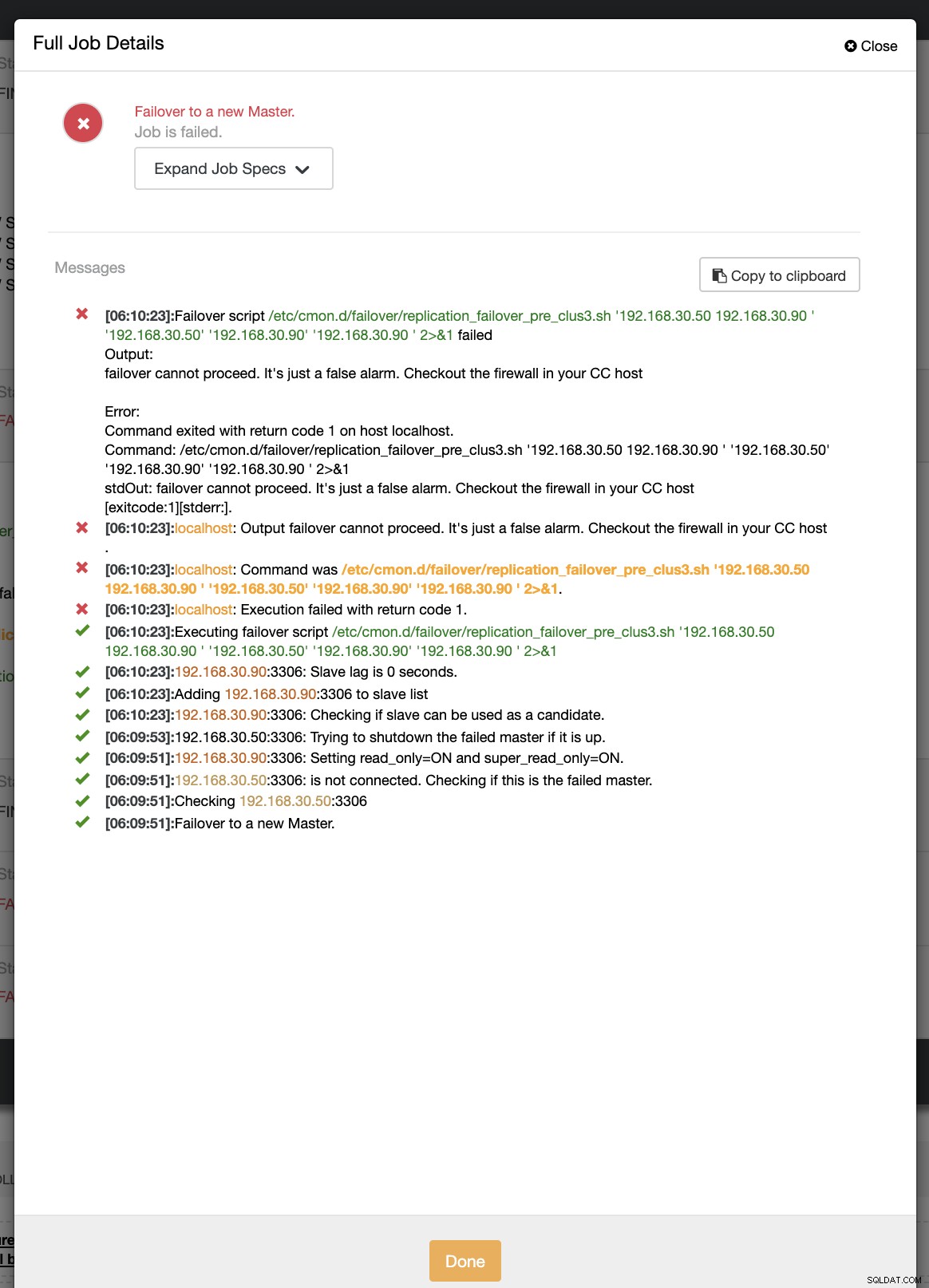
De toute évidence, cela échoue car l'horodatage qui a été enregistré n'est pas encore supérieur à une minute ou il y a quelques secondes à peine, le primaire était encore en mesure de se connecter au contrôleur CC. Évidemment, ce n'est pas l'approche parfaite lorsqu'il s'agit d'un scénario réel. Cependant, ClusterControl a pu invoquer et exécuter le script parfaitement comme prévu. Maintenant, qu'en est-il s'il atteint effectivement plus d'une minute (c'est-à-dire> 60 secondes) ?
Dans notre deuxième tentative de basculement, puisque l'horodatage atteint plus de 60 secondes, il est considéré comme un vrai positif, ce qui signifie que nous devons basculer comme prévu. CC a été capable de l'exécuter parfaitement et même d'exécuter le post-script comme prévu. Cela peut être vu dans le journal des travaux. Voir la capture d'écran ci-dessous :
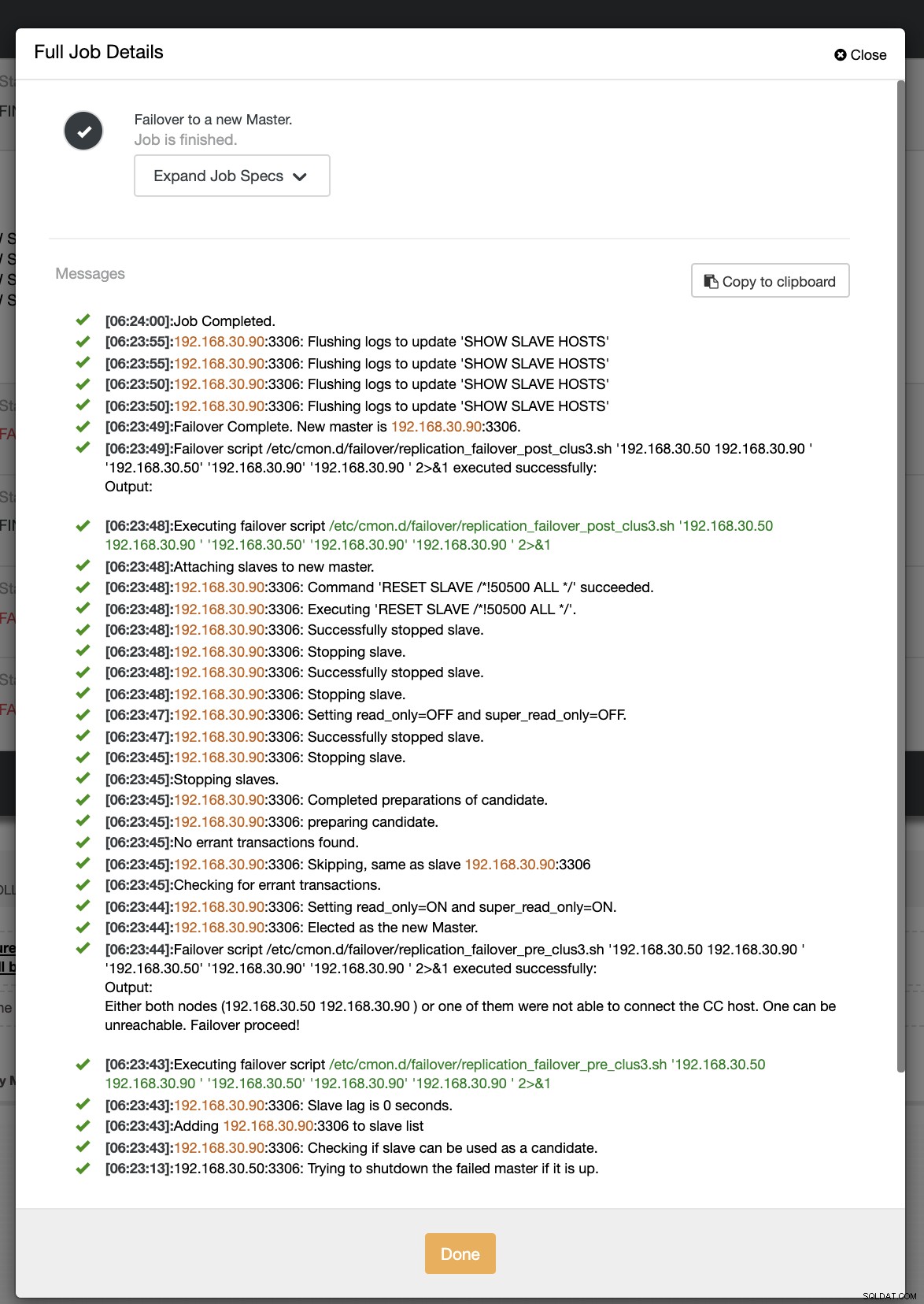
En vérifiant si mon post-script a été exécuté, il a pu créer le journal fichier dans le répertoire CC /tmp comme prévu,
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txtposter le script de basculement sur le cluster 3 avec les arguments :192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90
Maintenant, ma topologie a été modifiée et le basculement a réussi !
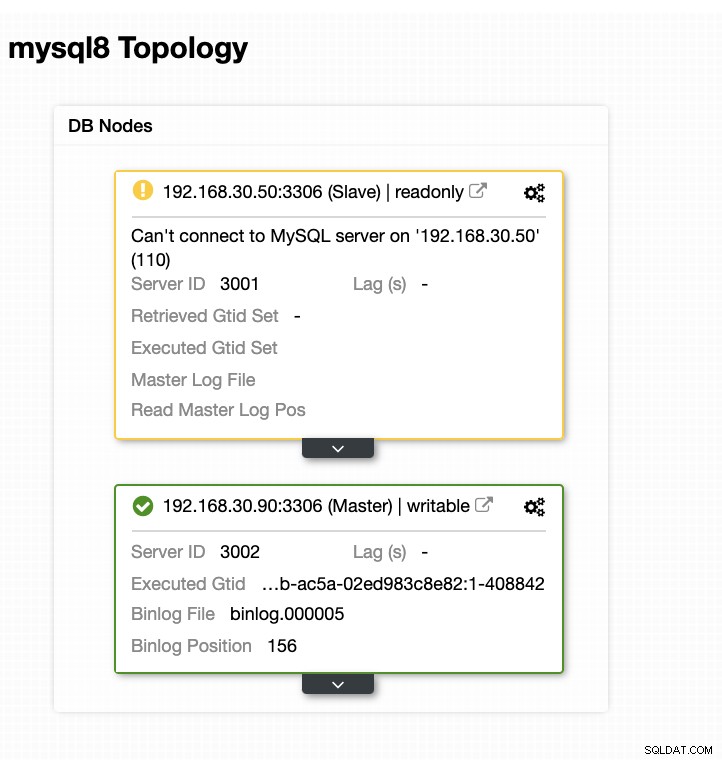
Conclusion
Pour toute configuration de base de données compliquée que vous pourriez avoir, lorsqu'un basculement avancé est requis, les scripts pré/post peuvent être très utiles pour rendre les choses réalisables. Étant donné que ClusterControl prend en charge ces fonctionnalités, nous avons démontré à quel point il est puissant et utile. Même avec ses limites, il existe toujours des moyens de rendre les choses réalisables et utiles, en particulier dans les environnements de production.