Remarque :Cet article présente la migration d'un modèle de base de données relationnelle (RDB) vers un schéma en étoile à l'aide de l'IDE Eclipse pour Voracity (et ses produits inclus), IRI Workbench, après une introduction aux deux architectures. Si vous souhaitez migrer votre RDB ou vos données vers un modèle Data Vault 2.0, un nouvel assistant Workbench fera ses débuts au World Wide Data Vault Consortium en mai 2019 ; abonnez-vous au blog IRI pour obtenir ces instructions étape par étape dès leur publication !
Un entrepôt de données (DW) est un ensemble de données extraites du système opérationnel ou transactionnel d'une entreprise, transformées pour éliminer les incohérences, puis organisées pour prendre en charge une analyse et/ou un reporting rapides. Le DW nécessite un schéma ou une description logique et une représentation graphique de sa base de données opérationnelle. Cet article aborde ces sujets tout en fournissant un guide pratique pour passer d'un schéma de base de données relationnelle conventionnel à un schéma DW populaire appelé schéma en étoile.
Schéma en étoile vs Relationnel
La plupart des structures de données relationnelles sont illustrées dans des diagrammes entité-relation (ER). Un diagramme ER est utilisé dans le développement de modèles conceptuels pour un système de gestion de base de données de traitement des transactions en ligne (OLTP). C'est la source à partir de laquelle la structure de la table est traduite.
Le schéma en étoile, cependant, est la norme largement acceptée pour la structure de table sous-jacente d'un entrepôt de données. Sa forme en étoile simple (lorsqu'elle est représentée par un diagramme en ER) montre la table de faits (contenant des valeurs de transaction ou des mesures) au centre, et des tables de dimension (contenant des valeurs descriptives ou attributives) qui en rayonnent. Généralement, la table de faits est en troisième forme normale (3NF), tandis que les tables dimensionnelles sont dénormalisées.
Les différences fondamentales entre un modèle entité-relationnel (ER) et un modèle en étoile sont :
- Les modèles ER utilisent des structures logiques et physiques pour une conception de base de données normalisée
- Les modèles de dimension utilisent une structure physique pour la conception de base de données dénormalisée
Pour voir comment le logiciel IRI peut dé/normaliser les données grâce au pivotement ligne-colonne, cliquez ici.
Contexte du processus de conversion
Dans cet article, je montre comment convertir des données d'un modèle relationnel en étoile à l'aide de tâches que vous devez définir plus ou moins manuellement, mais que vous pouvez créer et exécuter automatiquement, et modifier facilement.
Ce que vous verrez ici, ce sont les données 4GL et les spécifications de travail d'IRI - exprimées dans des scripts "SortCL" [1] - qui mappent les données dans des tables de dimensions et joignent les données dans la table de faits centrale. SortCL est le programme de manipulation et de cartographie des données de base de la plate-forme ETL et de gestion des données IRI Voracity. Cependant, comprendre la méthodologie et les mappages dans mes tâches SortCL est la clé ici, pas la syntaxe de script.
L'interface graphique Eclipse gratuite, IRI Workbench, fournit un éditeur SortCL sensible à la syntaxe, ainsi que des contours et des boîtes de dialogue graphiques, des diagrammes de flux de travail et de mappage, et des assistants de travail intuitifs, pour créer ou modifier automatiquement ces scripts si vous ne le souhaitez pas. par la main. Pour votre information, l'IRI utilise les mêmes métadonnées et la même interface graphique pour le profilage et la création de diagrammes de bases de données, la génération de données de test, l'exécution d'ETL, la mise en forme de rapports, le masquage d'informations personnelles, la capture de données modifiées, la migration et la réplication de données, le nettoyage et la validation de données, etc.
Workbench utilise une version améliorée du plug-in Data Tools Platform (DTP) pour Eclipse pour se connecter aux bases de données via JDBC et pour activer les opérations SQL et l'échange de métadonnées IRI dans la vue Data Source Explorer (DSE). Dans ce cas, le Workbench prend en charge :
- la création et le remplissage de tables de test (source) Oracle contraintes via SortCL (ou IRI RowGen jobs, selon cet article)
- le mappage des données des tables d'entités dans les tables de dimension via SortCL
- le mappage des éléments factuels sous la forme d'une relation n-aire pour associer la table de dimension principale ; c'est-à-dire effectuer une jointure multi-tables dans SortCL pour créer la table de faits
- Remplissage de toutes les tables cibles (schéma en étoile)
- Diagrammes ER des schémas source et cible
Les types d'entités dans mon modèle relationnel d'origine sont :Dept, Emp, Project, Category, Item, Item_Use et Sale :
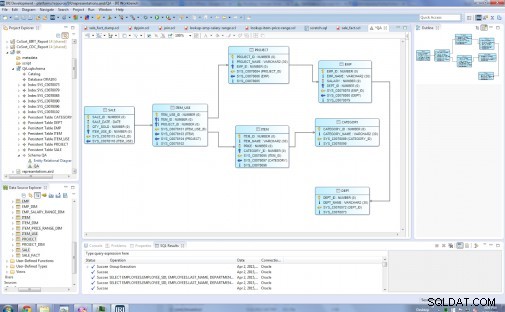
Avant …
Le diagramme suivant montre le modèle Star final avec huit tables de dimension et une table de faits. Les tableaux de dimensions sont : Dept_Dim, Emp_Dim, Emp_Salary_Range_Dim, Project_Dim, Category_Dim, Item_Price_Range_Dim, Item_Dim. La table de faits au centre est Sale_Fact, qui contient les clés de toutes les tables de dimension.

… Après
Étapes de conversion
- Définir et créer la table des faits
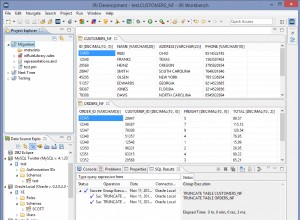
La structure de la table Sale_Fact est présentée dans ce document. La clé primaire est sale_id et le reste des attributs sont des clés étrangères héritées des tables de dimension. J'utilise une base de données Oracle (bien que tout RDB fonctionne) connectée au Workbench DSE (via JDBC) et SortCL pour la transformation et le mappage des données ( via ODBC). J'ai créé mes tables dans des scripts SQL édités dans l'album SQL de DSE et exécutés dans le Workbench.
- Définir et créer les tableaux de dimension
Utilisez la même technique et les mêmes métadonnées liées ci-dessus pour créer ces tables de dimension qui recevront les données relationnelles mappées à partir des tâches SortCL à l'étape suivante : table Category_Dim, Dept to Dept_Dim, Project to Project_Dim, Item to Item_Dim et Emp to Emp_Dim. Vous pouvez exécuter ce programme .SQL avec toute la logique CREATE à la fois pour créer les tables.
- Déplacez les données de la table d'entité d'origine dans les tables de dimension
Définissez et exécutez les tâches SortCL présentées ici pour mapper les données (test créé par RowGen) du schéma relationnel dans les tables de dimension pour le schéma en étoile. Plus précisément, ces scripts chargent les données de la table Category vers la table Category_Dim , Dept vers Dept_Dim, Project vers Project_Dim, Item vers Item_Dim et Emp vers Emp_Dim.
- Remplir la table des faits
Utilisez SortCL pour joindre les données des tables d'entités Sale, Emp, Project, Item_Use, Item, Category d'origine afin de préparer les données pour la nouvelle table Sale_Fact. Utilisez le deuxième script (join job) ici.
Pour améliorer notre exemple, nous utiliserons également SortCL pour introduire de nouvelles données dimensionnelles dans le schéma Star sur lequel ma table Fact s'appuiera également. Vous pouvez voir ces tables supplémentaires dans le diagramme en étoile ci-dessus qui ne figuraient pas dans mon schéma relationnel :Emp_Salary_Range_Dim et Item_Price_Range_Dim. Ces tables sont créées dans le même fichier .SQL pour les tables de faits et les autres tables de dimension.
La table de faits a besoin des données emp_salary_range_id et item_price_range_id de ces tables pour représenter la plage de valeurs dans ces tables de dimension. Lorsque je charge les valeurs de prix dimensionnelles dans l'entrepôt de données, par exemple, je souhaite les affecter à une fourchette de prix :
| Item_Price | Plage_Id | Plage_Name | Range_End |
|---|---|---|---|
| 1 | Faible | 1 | 100 |
| 2 | Moyen | 101 | 500 |
| 3 | Élevé | 501 | 999 |
Le moyen le plus simple d'attribuer des ID de plage dans le script de travail (qui prépare les données pour ma table Sale_Fact) consiste à utiliser une instruction IF-THEN-ELSE dans la section de sortie. Consultez cet article sur le regroupement des valeurs pour l'arrière-plan.
Quoi qu'il en soit, j'ai créé tout ce travail avec le CoSort New Join Job Assistant dans le Workbench. Et une fois que je l'ai exécuté, ma table de faits a été remplie :
 Affichage de la table Sales_Fact dans l'IRI Workbench DSE
Affichage de la table Sales_Fact dans l'IRI Workbench DSE
Conclusion
Le principal avantage de la représentation dimensionnelle des données est de réduire la complexité de la structure d'une base de données. Cela rend la base de données plus facile à comprendre et à écrire des requêtes en minimisant le nombre de tables et, par conséquent, le nombre de jointures requises. Comme mentionné précédemment, les modèles dimensionnels optimisent également les performances des requêtes. Cependant, il a de la faiblesse ainsi que de la force. La structure fixe du Star Schema limite les requêtes. Ainsi, comme cela facilite l'écriture des requêtes les plus courantes, cela limite également la manière dont les données peuvent être analysées.
L'interface graphique IRI Workbench pour Voracity dispose d'un ensemble d'outils puissants et complets qui simplifient l'intégration des données, y compris la création, la maintenance et l'expansion des entrepôts de données. Grâce à cette interface intuitive et facile à utiliser, Voracity facilite la création de processus ETL (extraction, transformation, chargement) rapides et flexibles de bout en bout impliquant des structures de données sur des plates-formes disparates.
Dans les opérations ETL, les données sont extraites de différentes sources, transformées séparément et chargées dans un entrepôt de données et éventuellement dans d'autres cibles. La construction du processus ETL est, potentiellement, l'une des tâches les plus importantes de la construction d'un entrepôt ; c'est complexe et prend du temps. L'approche ETL d'IRI prend en charge ce processus de manière très efficace et indépendante de la base de données, en effectuant l'intégralité de l'intégration et de la mise en scène des données dans le système de fichiers.
[1] Si vous êtes un passionné de syntaxe, notez que les scripts SortCL utilisés dans le produit IRI CoSort ou la plate-forme IRI Voracity prennent en charge la même syntaxe et les mêmes définitions de données que IRI RowGen pour la génération de données de test, IRI NextForm pour la migration de données et IRI FieldShield pour le masquage des données. Tous ces outils sont tous pris en charge dans l'interface graphique d'IRI Workbench, et leurs métadonnées peuvent également être partagées et gérées en équipe pour le contrôle de version, le lignage des travaux/données et la sécurité dans le cloud.
[2] Pour afficher les diagrammes E-R dans IRI Workbench :
- Sélectionnez Nouveau projet IRI et créez un nouveau dossier
- Sélectionnez ce dossier et mettez en surbrillance toutes les tables de base de données applicables dans l'explorateur de sources de données ; puis clic droit IRI, Nouveau diagramme ER
- Un fichier (Schema.QA) sera créé
- Cliquez avec le bouton droit sur ce fichier et sélectionnez Nouvelle représentation, Nouveau diagramme de relation d'entité.
[3] Les éléments du diagramme ER qui illustrent de tels modèles incluent :
- types d'entités définis
- attributs définis
- la relation entre les types d'entités
- image globale ou schéma conceptuel
[4] IRI FACT et SQL*Loader sont respectivement des options d'extraction et de chargement en masse.