Lorsque vous travaillez sur un projet composé de nombreux microservices, il inclura probablement également plusieurs bases de données.
Par exemple, vous pouvez avoir une base de données MySQL et une base de données PostgreSQL, toutes deux exécutées sur des serveurs distincts.
Habituellement, pour joindre les données des deux bases de données, vous devriez introduire un nouveau microservice qui joindrait les données ensemble. Mais cela augmenterait la complexité du système.
Dans ce didacticiel, nous utiliserons Materialise pour joindre MySQL et Postgres dans une vue matérialisée en direct. Nous pourrons ensuite interroger cela directement et obtenir les résultats des deux bases de données en temps réel à l'aide de SQL standard.
Materialise est une base de données de streaming disponible à la source écrite en Rust qui conserve les résultats d'une requête SQL (une vue matérialisée) en mémoire lorsque les données changent.
Le didacticiel comprend un projet de démonstration que vous pouvez commencer à utiliser docker-compose .
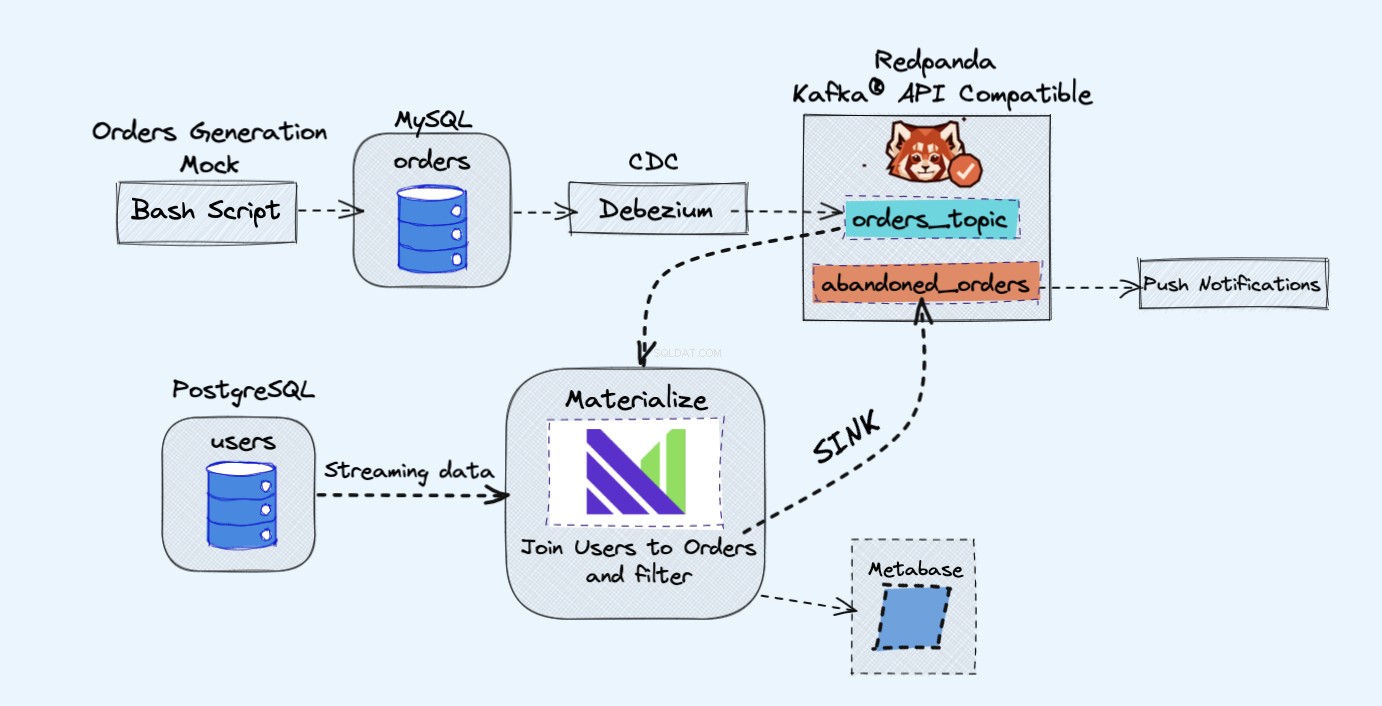
Le projet de démonstration que nous allons utiliser surveillera les commandes sur notre site Web fictif. Il générera des événements qui pourront, plus tard, être utilisés pour envoyer des notifications lorsqu'un panier est abandonné depuis longtemps.
L'architecture du projet de démonstration est la suivante :
Prérequis
Tous les services que nous utiliserons dans la démo fonctionneront dans des conteneurs Docker, de cette façon vous n'aurez pas à installer de services supplémentaires sur votre ordinateur portable ou votre serveur plutôt que Docker et Docker Compose.
Si Docker et Docker Compose ne sont pas déjà installés, vous pouvez suivre les instructions officielles sur la façon de procéder ici :
- Installer Docker
- Installer Docker Compose
Aperçu
Comme le montre le schéma ci-dessus, nous aurons les composants suivants :
- Un service fictif pour générer continuellement des commandes.
- Les commandes seront stockées dans une base de données MySQL .
- Lorsque les écritures de la base de données se produisent, Debezium diffuse les modifications depuis MySQL vers un Redpanda sujet.
- Nous aurons également un Postgres base de données où nous pouvons obtenir nos utilisateurs.
- Nous intégrerons ensuite ce sujet Redpanda dans Materialize directement avec les utilisateurs de la base de données Postgres.
- Dans Materialise, nous allons regrouper nos commandes et nos utilisateurs, effectuer un filtrage et créer une vue matérialisée qui affiche les informations sur le panier abandonné.
- Nous créerons ensuite un récepteur pour envoyer les données du panier abandonné vers un nouveau sujet Redpanda.
- À la fin, nous utiliserons Metabase pour visualiser les données.
- Vous pourriez, plus tard, utiliser les informations de ce nouveau sujet pour envoyer des notifications à vos utilisateurs et leur rappeler qu'ils ont un panier abandonné.
En remarque ici, vous seriez parfaitement bien d'utiliser Kafka au lieu de Redpanda. J'aime juste la simplicité que Redpanda apporte à la table, car vous pouvez exécuter une seule instance Redpanda au lieu de tous les composants Kafka.
Comment lancer la démo
Tout d'abord, commencez par cloner le dépôt :
git clone https://github.com/bobbyiliev/materialize-tutorials.git
Après cela, vous pouvez accéder au répertoire :
cd materialize-tutorials/mz-join-mysql-and-postgresql
Commençons par exécuter d'abord le conteneur Redpanda :
docker-compose up -d redpanda
Créez les images :
docker-compose build
Enfin, démarrez tous les services :
docker-compose up -d
Pour lancer la CLI Materialise, vous pouvez exécuter la commande suivante :
docker-compose run mzcli
Ceci est juste un raccourci vers un conteneur Docker avec postgres-client Pre installé. Si vous avez déjà psql vous pouvez exécuter psql -U materialize -h localhost -p 6875 materialize à la place.
Comment créer une source Materialise Kafka
Maintenant que vous êtes dans la CLI de Materialise, définissons les orders tables dans mysql.shop base de données en tant que sources Redpanda :
CREATE SOURCE orders
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'mysql.shop.orders'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081'
ENVELOPE DEBEZIUM;
Si vous deviez vérifier les colonnes disponibles à partir des orders source en exécutant l'instruction suivante :
SHOW COLUMNS FROM orders;
Vous pourriez voir que, comme Materialise extrait les données du schéma de message du registre Redpanda, il connaît les types de colonnes à utiliser pour chaque attribut :
name | nullable | type
--------------+----------+-----------
id | f | bigint
user_id | t | bigint
order_status | t | integer
price | t | numeric
created_at | f | text
updated_at | t | timestamp
Comment créer des vues matérialisées
Ensuite, nous allons créer notre première vue matérialisée, pour obtenir toutes les données des orders Source du panda rouge :
CREATE MATERIALIZED VIEW orders_view AS
SELECT * FROM orders;
CREATE MATERIALIZED VIEW abandoned_orders AS
SELECT
user_id,
order_status,
SUM(price) as revenue,
COUNT(id) AS total
FROM orders_view
WHERE order_status=0
GROUP BY 1,2;
Vous pouvez maintenant utiliser SELECT * FROM abandoned_orders; pour voir les résultats :
SELECT * FROM abandoned_orders;
Pour plus d'informations sur la création de vues matérialisées, consultez la section Vues matérialisées de la documentation Materialise.
Comment créer une source Postgres
Il existe deux manières de créer une source Postgres dans Materialise :
- Utiliser Debezium comme nous l'avons fait avec la source MySQL.
- Utiliser Postgres Materialise Source, qui vous permet de connecter Materialise directement à Postgres pour ne pas avoir à utiliser Debezium.
Pour cette démo, nous utiliserons Postgres Materialize Source juste comme une démonstration sur la façon de l'utiliser, mais n'hésitez pas à utiliser Debezium à la place.
Pour créer une source de matérialisation Postgres, exécutez l'instruction suivante :
CREATE MATERIALIZED SOURCE "mz_source" FROM POSTGRES
CONNECTION 'user=postgres port=5432 host=postgres dbname=postgres password=postgres'
PUBLICATION 'mz_source';
Un bref aperçu de la déclaration ci-dessus :
MATERIALIZED:matérialise les données de la source PostgreSQL. Toutes les données sont conservées en mémoire et rendent les sources directement sélectionnables.mz_source:Le nom de la source PostgreSQL.CONNECTION:Les paramètres de connexion PostgreSQL.PUBLICATION:La publication PostgreSQL, contenant les tables à streamer vers Materialise.
Une fois que nous avons créé la source PostgreSQL, afin de pouvoir interroger les tables PostgreSQL, nous aurions besoin de créer des vues qui représentent les tables d'origine de la publication en amont.
Dans notre cas, nous n'avons qu'une seule table appelée users donc la déclaration que nous aurions besoin d'exécuter est :
CREATE VIEWS FROM SOURCE mz_source (users);
Pour voir les vues disponibles, exécutez l'instruction suivante :
SHOW FULL VIEWS;
Une fois cela fait, vous pouvez interroger directement les nouvelles vues :
SELECT * FROM users;
Ensuite, allons-y et créons quelques vues supplémentaires.
Comment créer un évier Kafka
Les récepteurs vous permettent d'envoyer des données de Materialise vers une source externe.
Pour cette démo, nous utiliserons Redpanda.
Redpanda est compatible avec l'API Kafka et Materialise peut en traiter les données comme il traiterait les données d'une source Kafka.
Créons une vue matérialisée, qui contiendra toutes les commandes impayées à volume élevé :
CREATE MATERIALIZED VIEW high_value_orders AS
SELECT
users.id,
users.email,
abandoned_orders.revenue,
abandoned_orders.total
FROM users
JOIN abandoned_orders ON abandoned_orders.user_id = users.id
GROUP BY 1,2,3,4
HAVING revenue > 2000;
Comme vous pouvez le voir, ici nous rejoignons en fait les users vue qui ingère les données directement à partir de notre source Postgres, et les abandond_orders vue qui ingère les données du sujet Redpanda, ensemble.
Créons un Sink où nous enverrons les données de la vue matérialisée ci-dessus :
CREATE SINK high_value_orders_sink
FROM high_value_orders
INTO KAFKA BROKER 'redpanda:9092' TOPIC 'high-value-orders-sink'
FORMAT AVRO USING
CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Maintenant, si vous deviez vous connecter au conteneur Redpanda et utiliser le rpk topic consume commande, vous pourrez lire les enregistrements du sujet.
Cependant, pour le moment, nous ne pourrons pas prévisualiser les résultats avec rpk car il est au format AVRO. Redpanda implémentera très probablement cela à l'avenir, mais pour le moment, nous pouvons en fait renvoyer le sujet dans Materialise pour confirmer le format.
Tout d'abord, récupérez le nom du sujet qui a été généré automatiquement :
SELECT topic FROM mz_kafka_sinks;
Sortie :
topic
-----------------------------------------------------------------
high-volume-orders-sink-u12-1637586945-13670686352905873426
Pour plus d'informations sur la façon dont les noms de sujets sont générés, consultez la documentation ici.
Créez ensuite une nouvelle source matérialisée à partir de ce sujet Redpanda :
CREATE MATERIALIZED SOURCE high_volume_orders_test
FROM KAFKA BROKER 'redpanda:9092' TOPIC ' high-volume-orders-sink-u12-1637586945-13670686352905873426'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Assurez-vous de changer le nom du sujet en conséquence !
Enfin, interrogez cette nouvelle vue matérialisée :
SELECT * FROM high_volume_orders_test LIMIT 2;
Maintenant que vous avez les données dans le sujet, vous pouvez faire en sorte que d'autres services s'y connectent et les consomment, puis déclenchent des e-mails ou des alertes par exemple.
Comment connecter la métabase
Pour accéder à l'instance de métabase, visitez https://localhost:3030 si vous exécutez la démo localement ou https://your_server_ip:3030 si vous exécutez la démo sur un serveur. Suivez ensuite les étapes pour terminer la configuration de la métabase.
Assurez-vous de sélectionner Matérialiser comme source des données.
Une fois prêt, vous pourrez visualiser vos données comme vous le feriez avec une base de données PostgreSQL standard.
Comment arrêter la démo
Pour arrêter tous les services, exécutez la commande suivante :
docker-compose down
Conclusion
Comme vous pouvez le constater, il s'agit d'un exemple très simple d'utilisation de Materialise. Vous pouvez utiliser Materialise pour ingérer des données provenant de diverses sources, puis les diffuser vers diverses destinations.
Ressources utiles :
CREATE SOURCE: PostgreSQLCREATE SOURCECREATE VIEWSSELECT