Le regroupement est une fonctionnalité importante qui permet d'organiser et d'organiser les données. Il existe de nombreuses façons de le faire, et l'une des méthodes les plus efficaces est la clause SQL GROUP BY.
Vous pouvez utiliser SQL GROUP BY pour diviser les lignes des résultats en groupes avec une fonction d'agrégation . Il semble facile de faire la somme, la moyenne ou le comptage d'enregistrements avec.
Mais le faites-vous bien ?
« Correct » peut être subjectif. Lorsqu'il s'exécute sans erreurs critiques avec une sortie correcte, il est considéré comme correct. Cependant, cela doit aussi être rapide.
Dans cet article, la vitesse sera également considérée. Vous verrez beaucoup d'analyses de requêtes utilisant des lectures logiques et des plans d'exécution dans tous les points.
Commençons.
1. Filtrer tôt
Si vous ne savez pas quand utiliser WHERE et HAVING, celui-ci est pour vous. Parce que selon la condition que vous fournissez, les deux peuvent donner le même résultat.
Mais ils sont différents.
HAVING filtre les groupes à l'aide des colonnes de la clause SQL GROUP BY. WHERE filtre les lignes avant le regroupement et les agrégations. Ainsi, si vous filtrez à l'aide de la clause HAVING, le regroupement se produit pour tous lignes renvoyées.
Et c'est mauvais.
Pourquoi? La réponse courte est :c'est lent. Prouvons cela avec 2 requêtes. Consultez le code ci-dessous. Avant de l'exécuter dans SQL Server Management Studio, appuyez d'abord sur Ctrl-M.
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
Analyse
Les 2 instructions SELECT ci-dessus renverront les mêmes lignes. Les deux sont corrects dans le retour des commandes de produits par mois au cours de l'année 2012. Mais le premier SELECT a pris 136 ms. pour fonctionner sur mon ordinateur portable, tandis qu'un autre a pris 764 ms. !
Pourquoi ?
Vérifions d'abord les lectures logiques de la figure 1. L'E/S STATISTIQUES a renvoyé ces résultats. Ensuite, je l'ai collé dans StatisticsParser.com pour la sortie formatée.
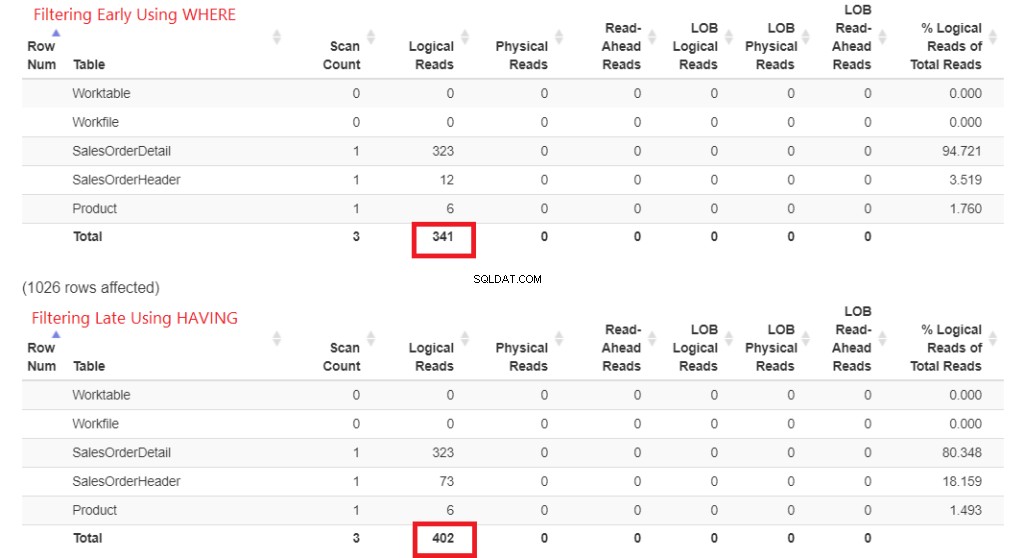
Illustration 1 . Lectures logiques du filtrage précoce à l'aide de WHERE par rapport au filtrage tardif à l'aide de HAVING.
Regardez le nombre total de lectures logiques de chacun. Pour comprendre ces chiffres, plus il a fallu de lectures logiques, plus la requête sera lente. Ainsi, cela prouve qu'utiliser HAVING est plus lent, et filtrer tôt avec WHERE est plus rapide.
Bien sûr, cela ne signifie pas qu'AVOIR est inutile. Une exception est lorsque vous utilisez HAVING avec un agrégat comme HAVING SUM(sod.Linetotal)> 100000 . Vous pouvez combiner une clause WHERE et une clause HAVING dans une seule requête.
Voir le plan d'exécution dans la figure 2.
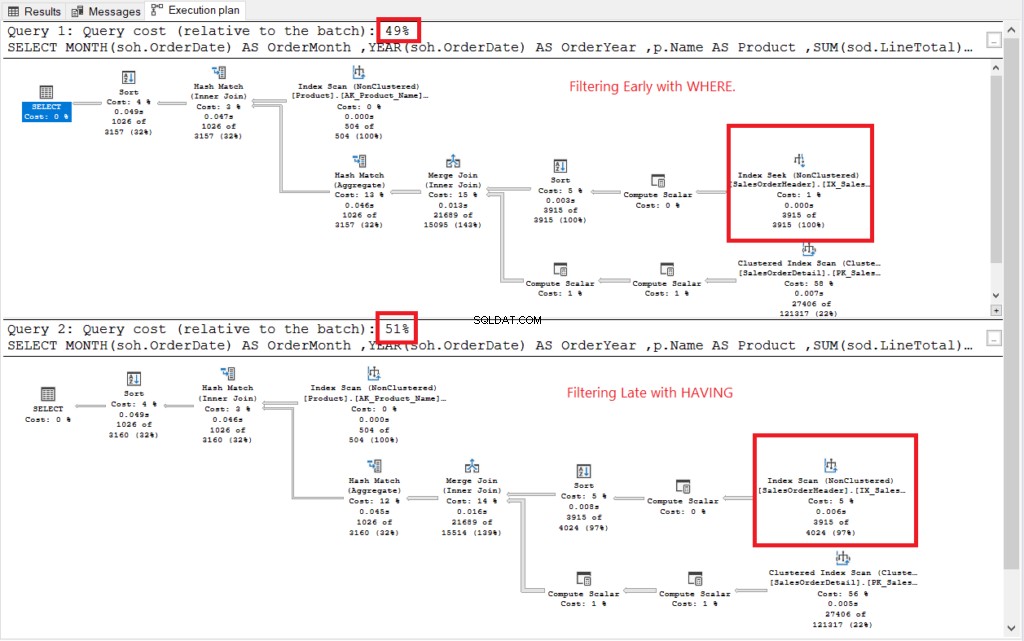
Illustration 2 . Plans d'exécution du filtrage précoce par rapport au filtrage tardif.
Les deux plans d'exécution se ressemblaient, à l'exception de ceux encadrés en rouge. Le filtrage précoce utilisait l'opérateur Index Seek tandis qu'un autre utilisait Index Scan. Les recherches sont plus rapides que les analyses dans les grandes tables.
Non te : Le filtrage précoce coûte moins cher que le filtrage tardif. Ainsi, l'essentiel est de filtrer les lignes tôt pour améliorer les performances.
2. Groupez d'abord, rejoignez plus tard
Rejoindre certaines des tables dont vous aurez besoin plus tard peut également améliorer les performances.
Disons que vous voulez avoir des ventes mensuelles de produits. Vous devez également obtenir le nom, le numéro et la sous-catégorie du produit dans la même requête. Ces colonnes se trouvent dans une autre table. Et ils doivent tous être ajoutés dans la clause GROUP BY pour une exécution réussie. Voici le code.
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
Cela fonctionnera bien. Mais il existe un moyen meilleur et plus rapide. Cela ne vous obligera pas à ajouter les 3 colonnes pour le nom, le numéro et la sous-catégorie du produit dans la clause GROUP BY. Cependant, cela nécessitera un peu plus de frappes. Le voici.
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
Analyse
Pourquoi est-ce plus rapide ? Les jointures à Produit et ProductSubcategory se font plus tard. Les deux ne sont pas impliqués dans la clause GROUP BY. Prouvons cela par des chiffres dans l'OI STATISTIQUES. Voir Figure 4.
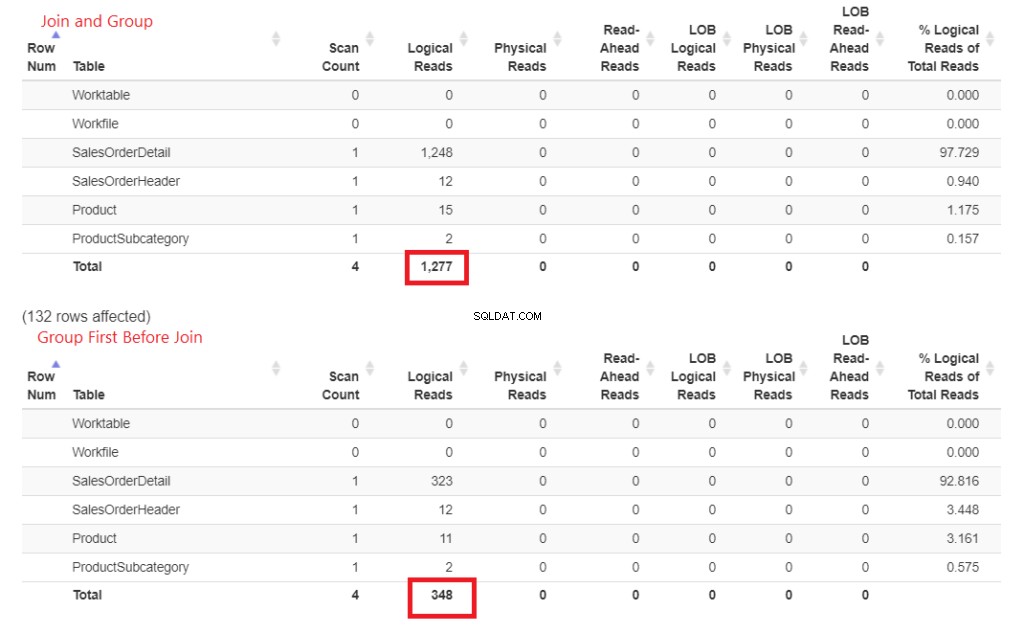
Illustration 3 . Rejoindre tôt puis regrouper a consommé plus de lectures logiques que de faire les jointures plus tard.
Vous voyez ces lectures logiques ? La différence est grande et le gagnant est évident.
Comparons le plan d'exécution des 2 requêtes pour voir la raison derrière les chiffres ci-dessus. Tout d'abord, consultez la figure 4 pour le plan d'exécution de la requête avec toutes les tables jointes lorsqu'elles sont regroupées.
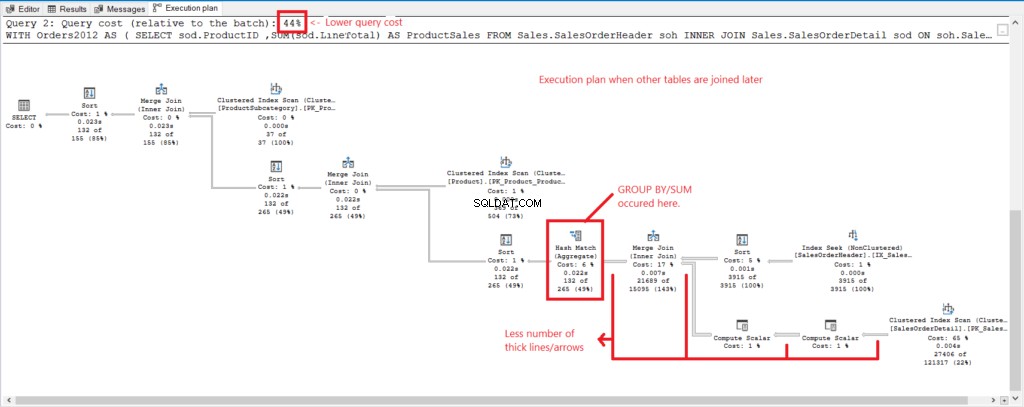
Illustration 4 . Plan d'exécution lorsque toutes les tables sont jointes.
Et nous avons les observations suivantes :
- GROUP BY et SUM ont été effectués tard dans le processus après avoir joint toutes les tables.
- Beaucoup de lignes et de flèches plus épaisses :cela explique les 1 277 lectures logiques.
- Les 2 requêtes combinées représentent 100 % du coût de la requête. Mais le plan de cette requête a un coût de requête plus élevé (56 %).
Maintenant, voici un plan d'exécution lorsque nous nous regroupons en premier et rejoignons le Produit et ProductSubcategory tableaux plus tard. Consultez la figure 5.
Illustration 5 . Plan d'exécution lorsque le groupe est d'abord rejoint plus tard.
Et nous avons les observations suivantes dans la figure 5.
- GROUP BY et SUM se sont terminés plus tôt.
- Moins de lignes épaisses et de flèches :cela explique les 348 lectures logiques uniquement.
- Réduction du coût des requêtes (44 %).
3. Grouper une colonne indexée
Chaque fois que SQL GROUP BY est effectué sur une colonne, cette colonne doit avoir un index. Vous augmenterez la vitesse d'exécution une fois que vous grouperez la colonne avec un index. Modifions la requête précédente et utilisons la date d'expédition au lieu de la date de commande. La colonne de date d'expédition n'a pas d'index dans SalesOrderHeader .
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Appuyez sur Ctrl-M, puis exécutez la requête ci-dessus dans SSMS. Ensuite, créez un index non clusterisé sur la ShipDate colonne. Notez les lectures logiques et le plan d'exécution. Enfin, relancez la requête ci-dessus dans un autre onglet de requête. Notez les différences entre les lectures logiques et les plans d'exécution.
Voici la comparaison des lectures logiques de la figure 6.
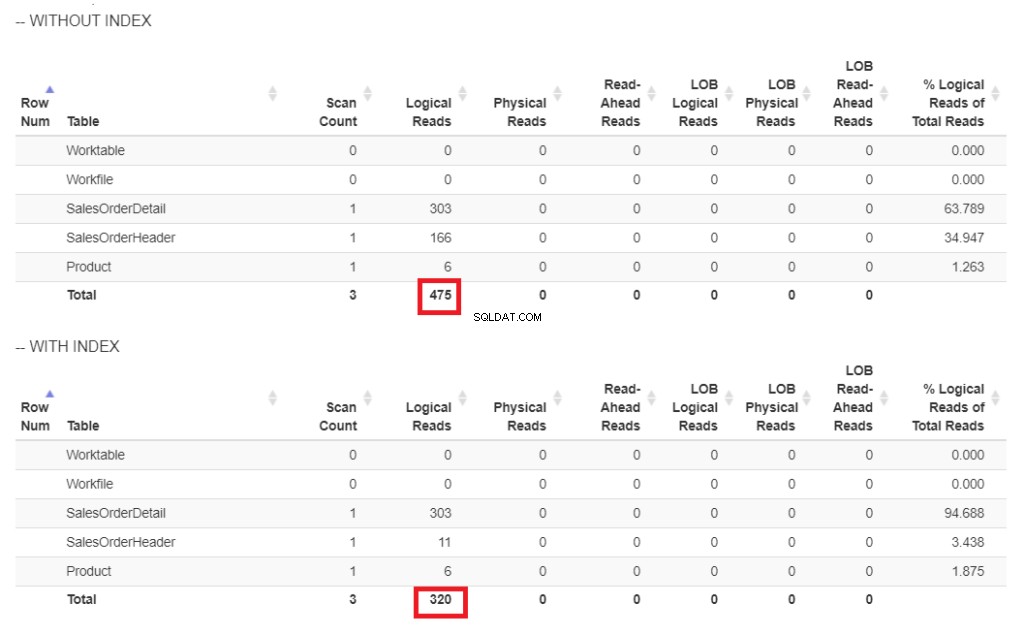
Illustration 6 . Lectures logiques de notre exemple de requête avec et sans index sur ShipDate.
Dans la figure 6, il y a des lectures logiques plus élevées de la requête sans index sur ShipDate .
Passons maintenant au plan d'exécution lorsqu'il n'y a pas d'index sur ShipDate existe dans la figure 7.
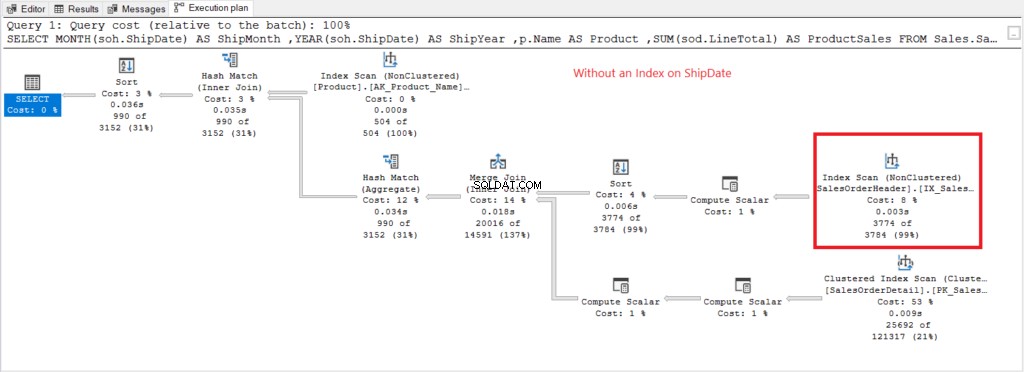
Illustration 7 . Plan d'exécution lors de l'utilisation de GROUP BY sur ShipDate non indexé.
L'analyse de l'index L'opérateur utilisé dans le plan de la figure 7 explique les lectures logiques supérieures (475). Voici un plan d'exécution après avoir indexé la ShipDate colonne.
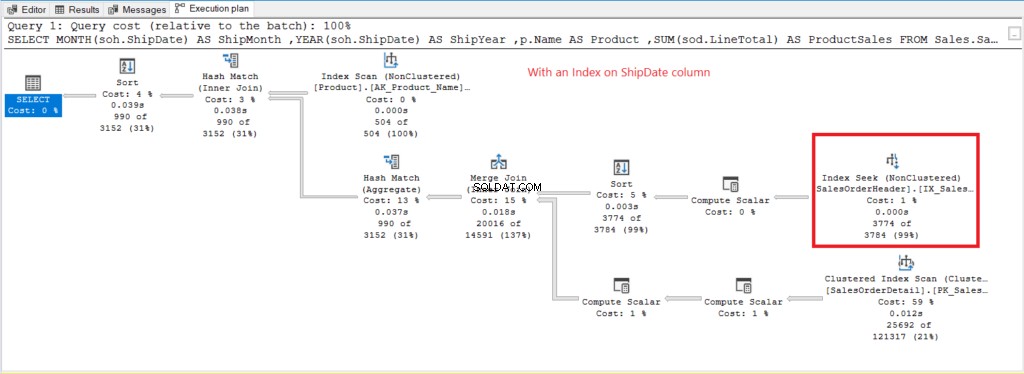
Figure 8 . Plan d'exécution lors de l'utilisation de GROUP BY sur ShipDate indexé.
Au lieu d'Index Scan, un Index Seek est utilisé après l'indexation de la ShipDate colonne. Cela explique les lectures logiques inférieures de la figure 6.
Ainsi, pour améliorer les performances lors de l'utilisation de GROUP BY, envisagez d'indexer les colonnes que vous avez utilisées pour le regroupement.
Points à retenir sur l'utilisation de SQL GROUP BY
SQL GROUP BY est facile à utiliser. Mais vous devez passer à l'étape suivante pour aller au-delà de la synthèse des données pour les rapports. Voici à nouveau les points :
- Filtrer plus tôt . Supprimez les lignes que vous n'avez pas besoin de résumer en utilisant la clause WHERE au lieu de la clause HAVING.
- Groupez d'abord, rejoignez plus tard . Parfois, il y aura des colonnes que vous devrez ajouter en plus des colonnes que vous regroupez. Au lieu de les inclure dans la clause GROUP BY, divisez la requête avec un CTE et joignez d'autres tables plus tard.
- Utiliser GROUP BY avec des colonnes indexées . Cette fonctionnalité de base peut s'avérer utile lorsque la base de données est aussi rapide qu'un escargot.
J'espère que cela vous aidera à améliorer votre jeu en regroupant les résultats.
Si vous aimez cet article, partagez-le sur vos plateformes de médias sociaux préférées.



